 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Manipulating Visually-aware Federated Recommender Systems and Its Countermeasures
May 14, 2023
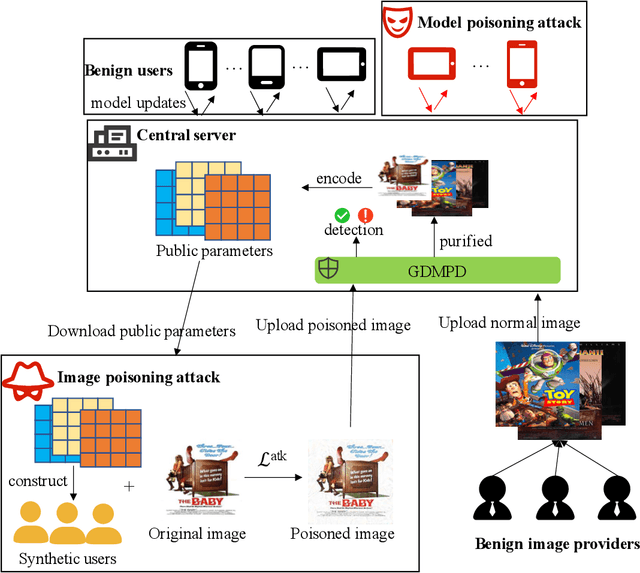

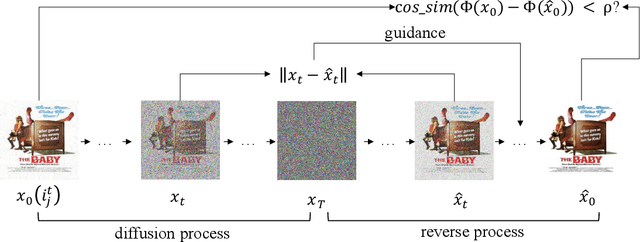

Federated recommender systems (FedRecs) have been widely explored recently due to their ability to protect user data privacy. In FedRecs, a central server collaboratively learns recommendation models by sharing model public parameters with clients, thereby offering a privacy-preserving solution. Unfortunately, the exposure of model parameters leaves a backdoor for adversaries to manipulate FedRecs. Existing works about FedRec security already reveal that items can easily be promoted by malicious users via model poisoning attacks, but all of them mainly focus on FedRecs with only collaborative information (i.e., user-item interactions). We argue that these attacks are effective because of the data sparsity of collaborative signals. In practice, auxiliary information, such as products' visual descriptions, is used to alleviate collaborative filtering data's sparsity. Therefore, when incorporating visual information in FedRecs, all existing model poisoning attacks' effectiveness becomes questionable. In this paper, we conduct extensive experiments to verify that incorporating visual information can beat existing state-of-the-art attacks in reasonable settings. However, since visual information is usually provided by external sources, simply including it will create new security problems. Specifically, we propose a new kind of poisoning attack for visually-aware FedRecs, namely image poisoning attacks, where adversaries can gradually modify the uploaded image to manipulate item ranks during FedRecs' training process. Furthermore, we reveal that the potential collaboration between image poisoning attacks and model poisoning attacks will make visually-aware FedRecs more vulnerable to being manipulated. To safely use visual information, we employ a diffusion model in visually-aware FedRecs to purify each uploaded image and detect the adversarial images.
Temporal Dynamic Quantization for Diffusion Models
Jun 04, 2023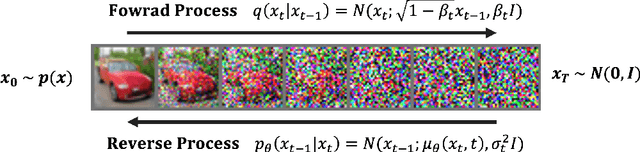
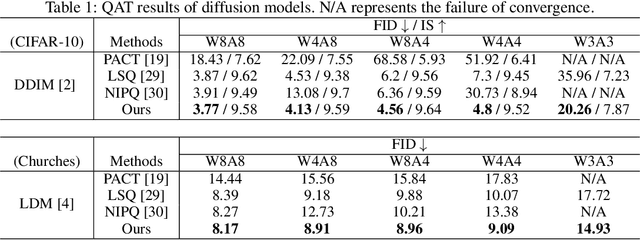
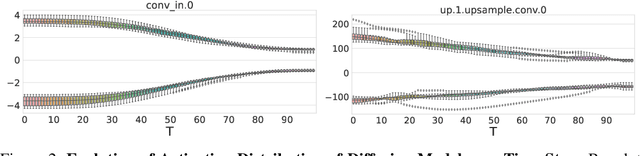
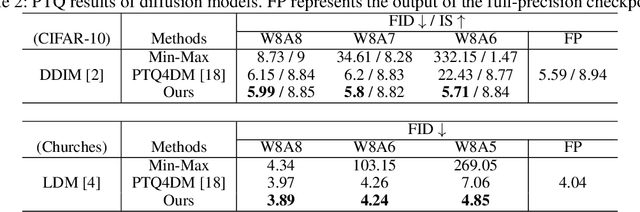
The diffusion model has gained popularity in vision applications due to its remarkable generative performance and versatility. However, high storage and computation demands, resulting from the model size and iterative generation, hinder its use on mobile devices. Existing quantization techniques struggle to maintain performance even in 8-bit precision due to the diffusion model's unique property of temporal variation in activation. We introduce a novel quantization method that dynamically adjusts the quantization interval based on time step information, significantly improving output quality. Unlike conventional dynamic quantization techniques, our approach has no computational overhead during inference and is compatible with both post-training quantization (PTQ) and quantization-aware training (QAT). Our extensive experiments demonstrate substantial improvements in output quality with the quantized diffusion model across various datasets.
Generating High-Quality Emotion Arcs For Low-Resource Languages Using Emotion Lexicons
Jun 03, 2023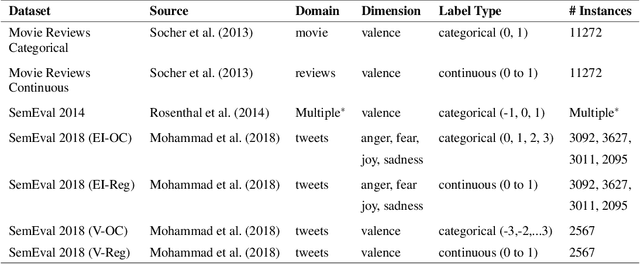
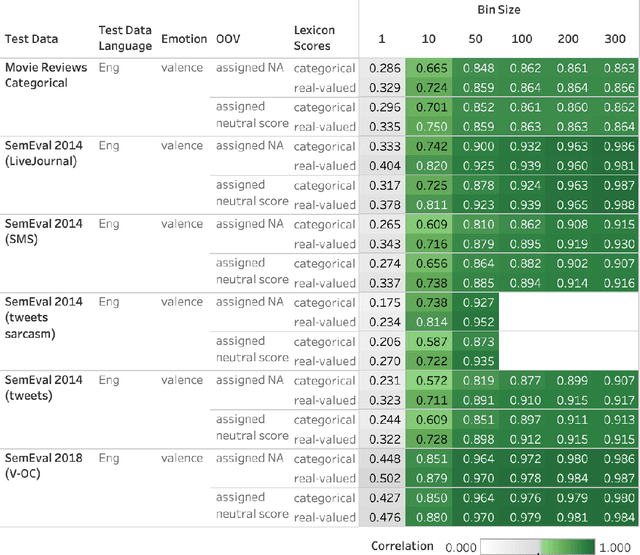

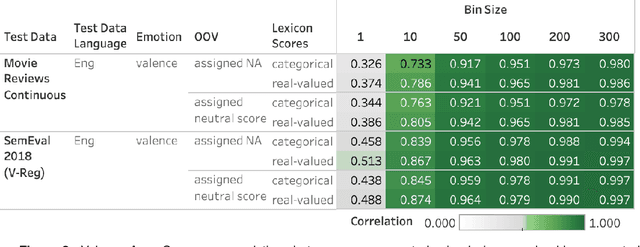
Automatically generated emotion arcs -- that capture how an individual or a population feels over time -- are widely used in industry and research. However, there is little work on evaluating the generated arcs in English (where the emotion resources are available) and no work on generating or evaluating emotion arcs for low-resource languages. Work on generating emotion arcs in low-resource languages such as those indigenous to Africa, the Americas, and Australia is stymied by the lack of emotion-labeled resources and large language models for those languages. Work on evaluating emotion arcs (for any language) is scarce because of the difficulty of establishing the true (gold) emotion arc. Our work, for the first time, systematically and quantitatively evaluates automatically generated emotion arcs. We also compare two common ways of generating emotion arcs: Machine-Learning (ML) models and Lexicon-Only (LexO) methods. By running experiments on 42 diverse datasets in 9 languages, we show that despite being markedly poor at instance level emotion classification, LexO methods are highly accurate at generating emotion arcs when aggregating information from hundreds of instances. (Predicted arcs have correlations ranging from 0.94 to 0.99 with the gold arcs for various emotions.) We also show that for languages with no emotion lexicons, automatic translations of English emotion lexicons can be used to generate high-quality emotion arcs -- correlations above 0.9 with the gold emotion arcs in all six indigenous African languages explored. This opens up avenues for work on emotions in numerous languages from around the world; crucial not only for commerce, public policy, and health research in service of speakers of those languages, but also to draw meaningful conclusions in emotion-pertinent research using information from around the world (thereby avoiding a western-centric bias in research).
Get More for Less in Decentralized Learning Systems
Jun 07, 2023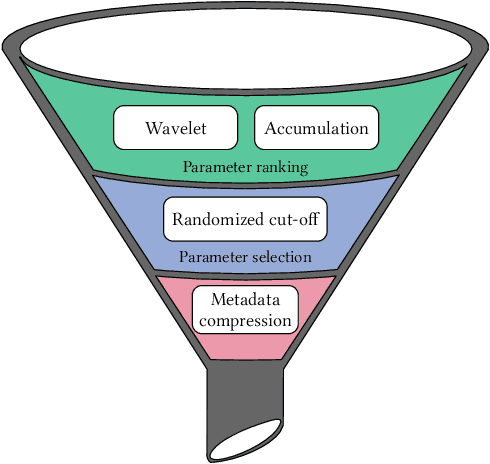
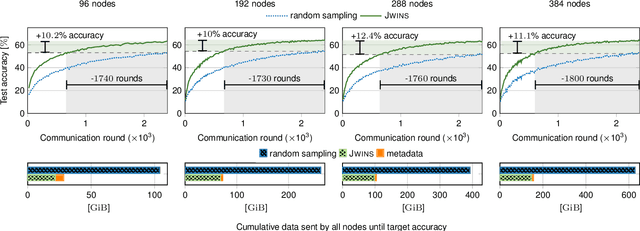
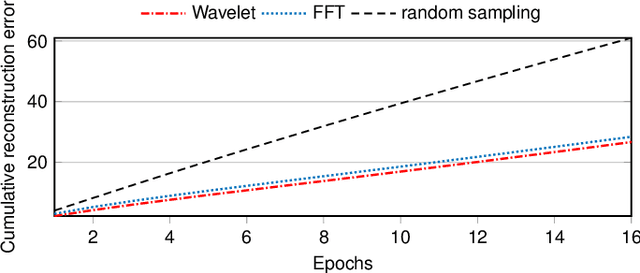
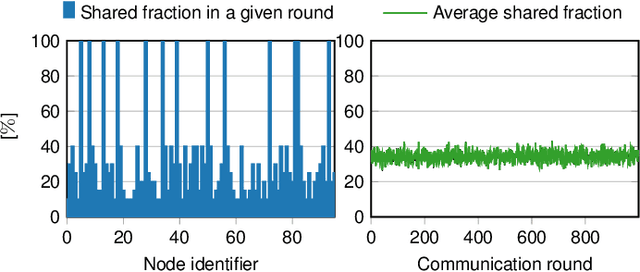
Decentralized learning (DL) systems have been gaining popularity because they avoid raw data sharing by communicating only model parameters, hence preserving data confidentiality. However, the large size of deep neural networks poses a significant challenge for decentralized training, since each node needs to exchange gigabytes of data, overloading the network. In this paper, we address this challenge with JWINS, a communication-efficient and fully decentralized learning system that shares only a subset of parameters through sparsification. JWINS uses wavelet transform to limit the information loss due to sparsification and a randomized communication cut-off that reduces communication usage without damaging the performance of trained models. We demonstrate empirically with 96 DL nodes on non-IID datasets that JWINS can achieve similar accuracies to full-sharing DL while sending up to 64% fewer bytes. Additionally, on low communication budgets, JWINS outperforms the state-of-the-art communication-efficient DL algorithm CHOCO-SGD by up to 4x in terms of network savings and time.
Label Aware Speech Representation Learning For Language Identification
Jun 07, 2023
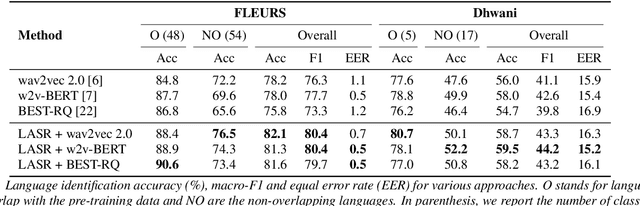
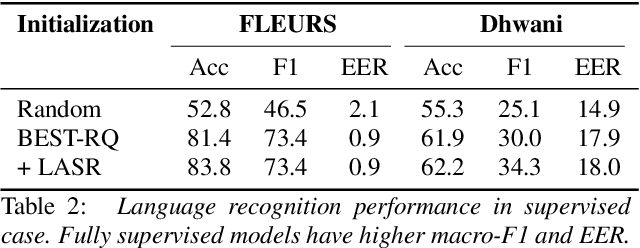
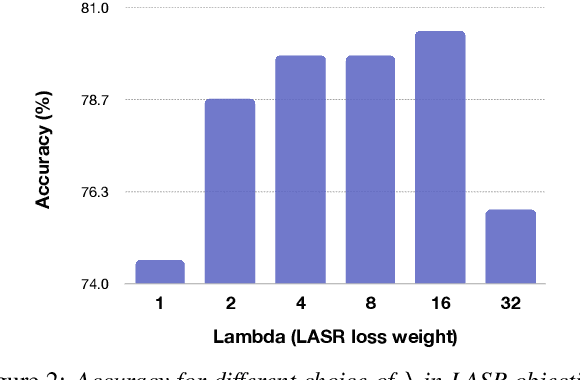
Speech representation learning approaches for non-semantic tasks such as language recognition have either explored supervised embedding extraction methods using a classifier model or self-supervised representation learning approaches using raw data. In this paper, we propose a novel framework of combining self-supervised representation learning with the language label information for the pre-training task. This framework, termed as Label Aware Speech Representation (LASR) learning, uses a triplet based objective function to incorporate language labels along with the self-supervised loss function. The speech representations are further fine-tuned for the downstream task. The language recognition experiments are performed on two public datasets - FLEURS and Dhwani. In these experiments, we illustrate that the proposed LASR framework improves over the state-of-the-art systems on language identification. We also report an analysis of the robustness of LASR approach to noisy/missing labels as well as its application to multi-lingual speech recognition tasks.
Transfer Learning from Pre-trained Language Models Improves End-to-End Speech Summarization
Jun 07, 2023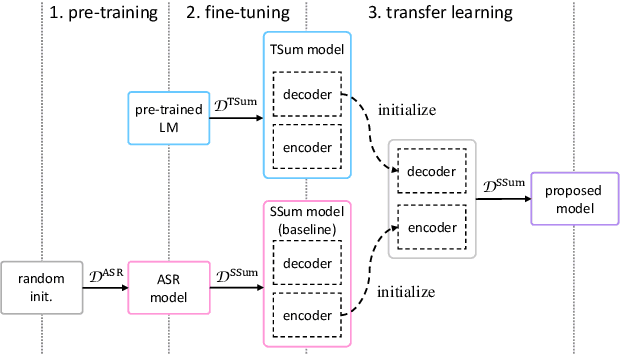
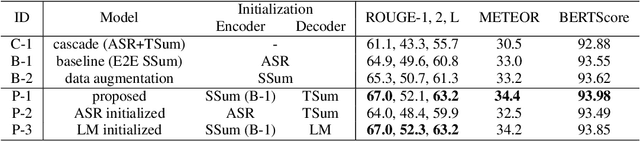
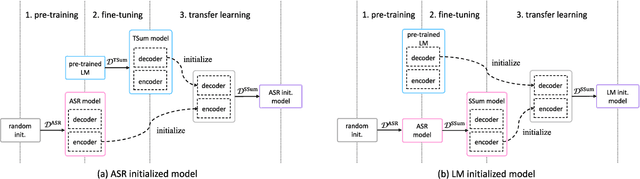

End-to-end speech summarization (E2E SSum) directly summarizes input speech into easy-to-read short sentences with a single model. This approach is promising because it, in contrast to the conventional cascade approach, can utilize full acoustical information and mitigate to the propagation of transcription errors. However, due to the high cost of collecting speech-summary pairs, an E2E SSum model tends to suffer from training data scarcity and output unnatural sentences. To overcome this drawback, we propose for the first time to integrate a pre-trained language model (LM), which is highly capable of generating natural sentences, into the E2E SSum decoder via transfer learning. In addition, to reduce the gap between the independently pre-trained encoder and decoder, we also propose to transfer the baseline E2E SSum encoder instead of the commonly used automatic speech recognition encoder. Experimental results show that the proposed model outperforms baseline and data augmented models.
Exploiting Observation Bias to Improve Matrix Completion
Jun 07, 2023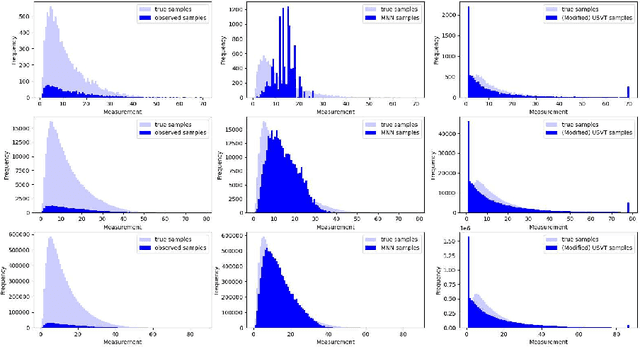

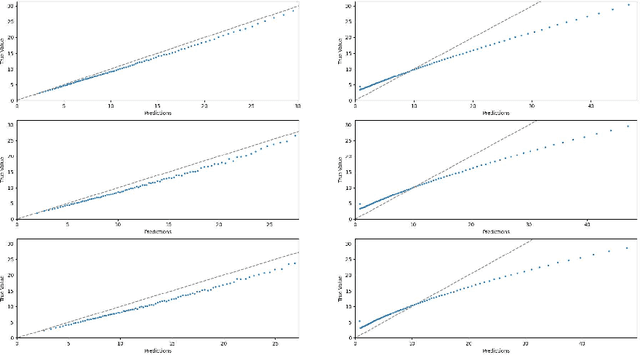

We consider a variant of matrix completion where entries are revealed in a biased manner, adopting a model akin to that introduced by Ma and Chen. Instead of treating this observation bias as a disadvantage, as is typically the case, our goal is to exploit the shared information between the bias and the outcome of interest to improve predictions. Towards this, we propose a simple two-stage algorithm: (i) interpreting the observation pattern as a fully observed noisy matrix, we apply traditional matrix completion methods to the observation pattern to estimate the distances between the latent factors; (ii) we apply supervised learning on the recovered features to impute missing observations. We establish finite-sample error rates that are competitive with the corresponding supervised learning parametric rates, suggesting that our learning performance is comparable to having access to the unobserved covariates. Empirical evaluation using a real-world dataset reflects similar performance gains, with our algorithm's estimates having 30x smaller mean squared error compared to traditional matrix completion methods.
Auditing for Human Expertise
Jun 02, 2023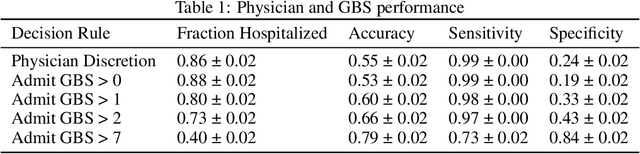
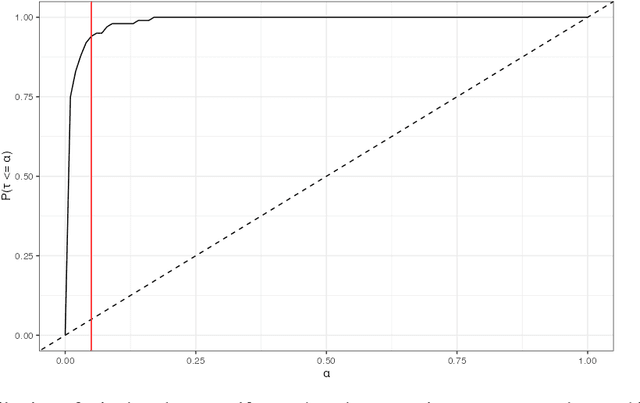

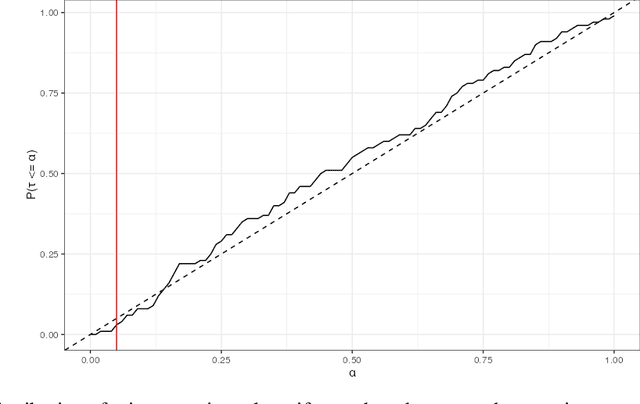
High-stakes prediction tasks (e.g., patient diagnosis) are often handled by trained human experts. A common source of concern about automation in these settings is that experts may exercise intuition that is difficult to model and/or have access to information (e.g., conversations with a patient) that is simply unavailable to a would-be algorithm. This raises a natural question whether human experts add value which could not be captured by an algorithmic predictor. We develop a statistical framework under which we can pose this question as a natural hypothesis test. Indeed, as our framework highlights, detecting human expertise is more subtle than simply comparing the accuracy of expert predictions to those made by a particular learning algorithm. Instead, we propose a simple procedure which tests whether expert predictions are statistically independent from the outcomes of interest after conditioning on the available inputs (`features'). A rejection of our test thus suggests that human experts may add value to any algorithm trained on the available data, and has direct implications for whether human-AI `complementarity' is achievable in a given prediction task. We highlight the utility of our procedure using admissions data collected from the emergency department of a large academic hospital system, where we show that physicians' admit/discharge decisions for patients with acute gastrointestinal bleeding (AGIB) appear to be incorporating information not captured in a standard algorithmic screening tool. This is despite the fact that the screening tool is arguably more accurate than physicians' discretionary decisions, highlighting that -- even absent normative concerns about accountability or interpretability -- accuracy is insufficient to justify algorithmic automation.
mmT5: Modular Multilingual Pre-Training Solves Source Language Hallucinations
May 23, 2023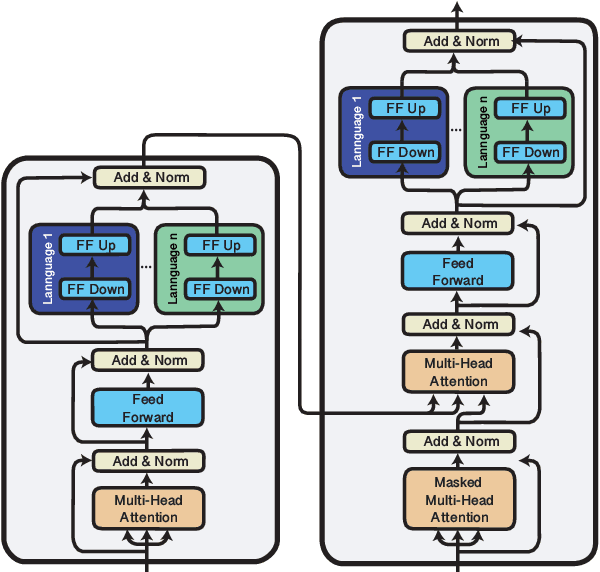
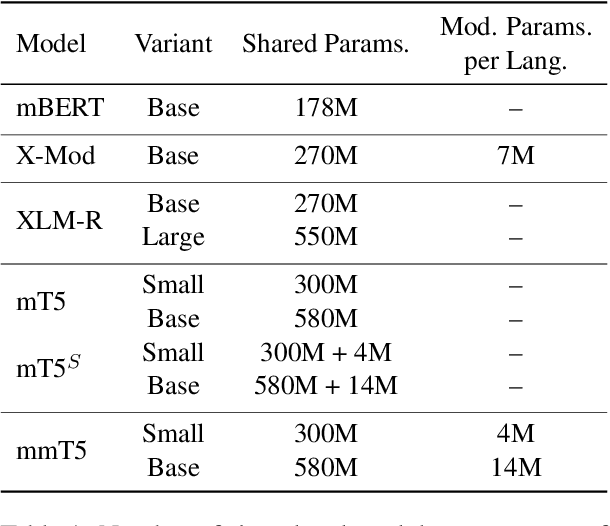
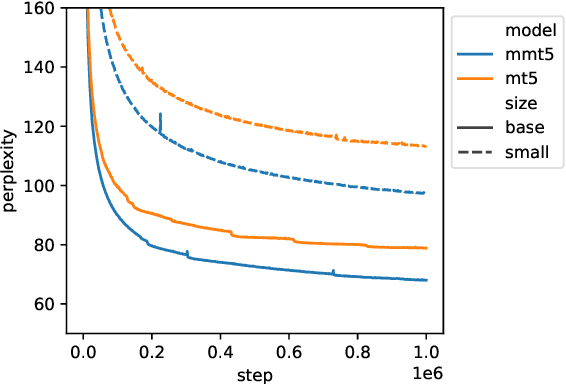
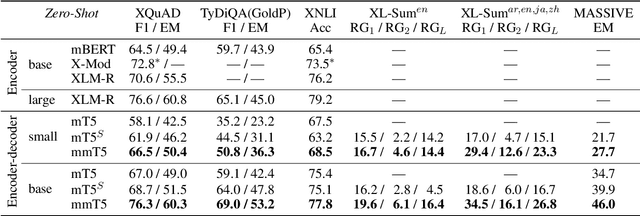
Multilingual sequence-to-sequence models perform poorly with increased language coverage and fail to consistently generate text in the correct target language in few-shot settings. To address these challenges, we propose mmT5, a modular multilingual sequence-to-sequence model. mmT5 utilizes language-specific modules during pre-training, which disentangle language-specific information from language-agnostic information. We identify representation drift during fine-tuning as a key limitation of modular generative models and develop strategies that enable effective zero-shot transfer. Our model outperforms mT5 at the same parameter sizes by a large margin on representative natural language understanding and generation tasks in 40+ languages. Compared to mT5, mmT5 raises the rate of generating text in the correct language under zero-shot settings from 7% to 99%, thereby greatly alleviating the source language hallucination problem.
Web scraping: a promising tool for geographic data acquisition
May 31, 2023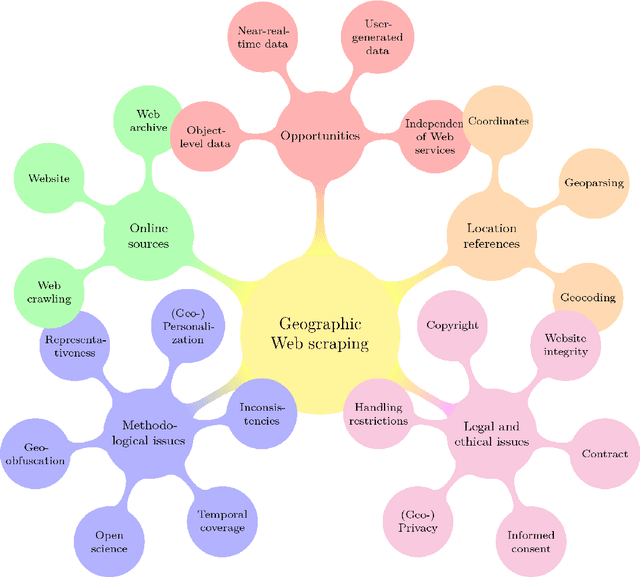
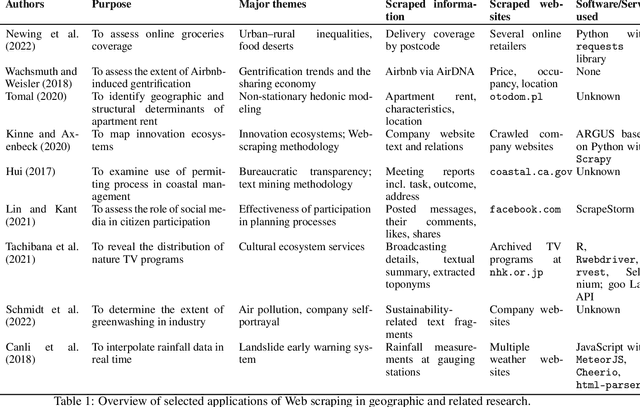
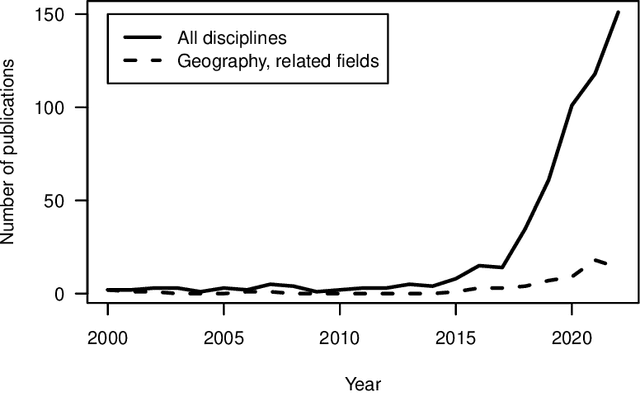
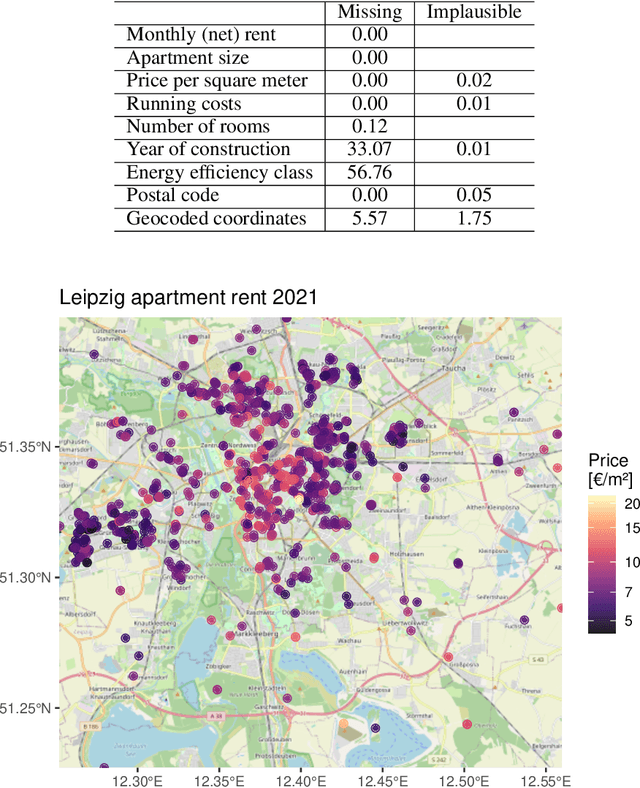
With much of our lives taking place online, researchers are increasingly turning to information from the World Wide Web to gain insights into geographic patterns and processes. Web scraping as an online data acquisition technique allows us to gather intelligence especially on social and economic actions for which the Web serves as a platform. Specific opportunities relate to near-real-time access to object-level geolocated data, which can be captured in a cost-effective way. The studied geographic phenomena include, but are not limited to, the rental market and associated processes such as gentrification, entrepreneurial ecosystems, or spatial planning processes. Since the information retrieved from the Web is not made available for that purpose, Web scraping faces several unique challenges, several of which relate to location. Ethical and legal issues mainly relate to intellectual property rights, informed consent and (geo-) privacy, and website integrity and contract. These issues also effect the practice of open science. In addition, there are technical and statistical challenges that relate to dependability and incompleteness, data inconsistencies and bias, as well as the limited historical coverage. Geospatial analyses furthermore usually require the automated extraction and subsequent resolution of toponyms or addresses (geoparsing, geocoding). A study on apartment rent in Leipzig, Germany is used to illustrate the use of Web scraping and its challenges. We conclude that geographic researchers should embrace Web scraping as a powerful and affordable digital fieldwork tool while paying special attention to its legal, ethical, and methodological challenges.