 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FheFL: Fully Homomorphic Encryption Friendly Privacy-Preserving Federated Learning with Byzantine Users
Jun 26, 2023
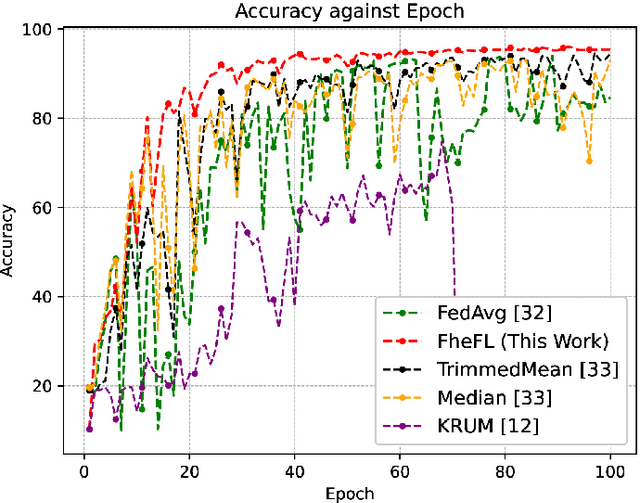
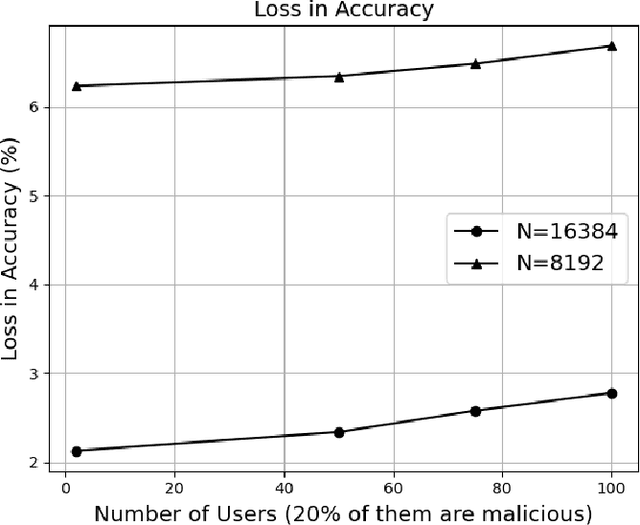
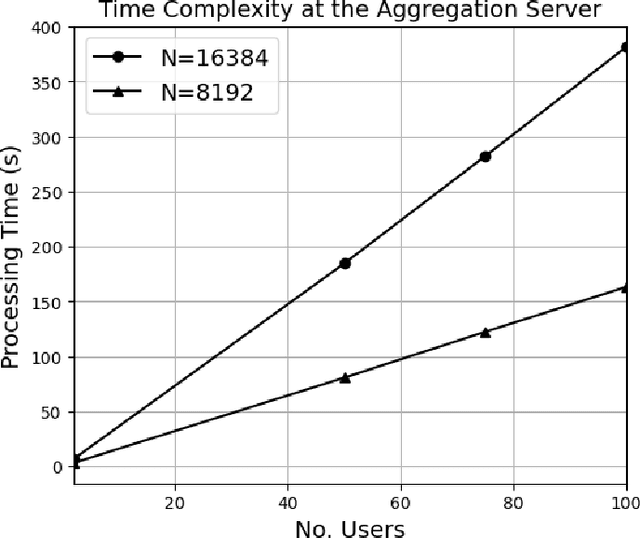
The federated learning (FL) technique was developed to mitigate data privacy issues in the traditional machine learning paradigm. While FL ensures that a user's data always remain with the user, the gradients are shared with the centralized server to build the global model. This results in privacy leakage, where the server can infer private information from the shared gradients. To mitigate this flaw, the next-generation FL architectures proposed encryption and anonymization techniques to protect the model updates from the server. However, this approach creates other challenges, such as malicious users sharing false gradients. Since the gradients are encrypted, the server is unable to identify rogue users. To mitigate both attacks, this paper proposes a novel FL algorithm based on a fully homomorphic encryption (FHE) scheme. We develop a distributed multi-key additive homomorphic encryption scheme that supports model aggregation in FL. We also develop a novel aggregation scheme within the encrypted domain, utilizing users' non-poisoning rates, to effectively address data poisoning attacks while ensuring privacy is preserved by the proposed encryption scheme. Rigorous security, privacy, convergence, and experimental analyses have been provided to show that FheFL is novel, secure, and private, and achieves comparable accuracy at reasonable computational cost.
A pose and shear-based tactile robotic system for object tracking, surface following and object pushing
Jun 26, 2023
Tactile perception is a crucial sensing modality in robotics, particularly in scenarios that require precise manipulation and safe interaction with other objects. Previous research in this area has focused extensively on tactile perception of contact poses as this is an important capability needed for tasks such as traversing an object's surface or edge, manipulating an object, or pushing an object along a predetermined path. Another important capability needed for tasks such as object tracking and manipulation is estimation of post-contact shear but this has received much less attention. Indeed, post-contact shear has often been considered a "nuisance variable" and is removed if possible because it can have an adverse effect on other types of tactile perception such as contact pose estimation. This paper proposes a tactile robotic system that can simultaneously estimate both the contact pose and post-contact shear, and use this information to control its interaction with other objects. Moreover, our new system is capable of interacting with other objects in a smooth and continuous manner, unlike the stepwise, position-controlled systems we have used in the past. We demonstrate the capabilities of our new system using several different controller configurations, on tasks including object tracking, surface following, single-arm object pushing, and dual-arm object pushing.
Structured Dialogue Discourse Parsing
Jun 26, 2023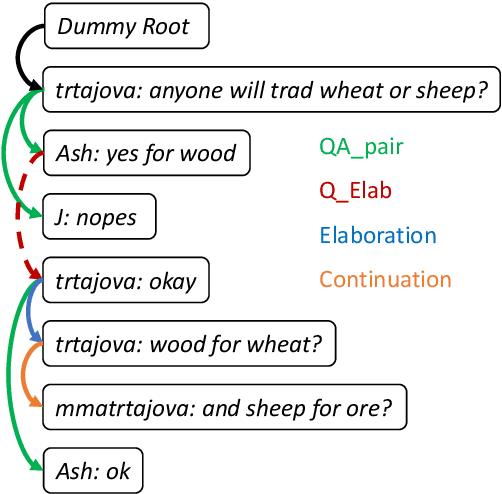

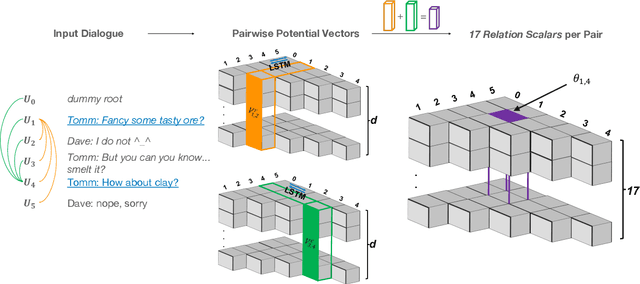
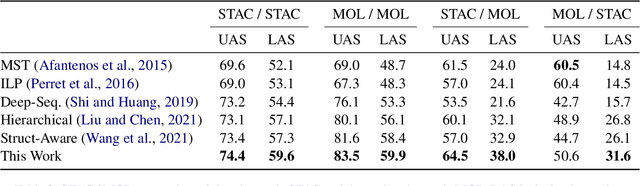
Dialogue discourse parsing aims to uncover the internal structure of a multi-participant conversation by finding all the discourse~\emph{links} and corresponding~\emph{relations}. Previous work either treats this task as a series of independent multiple-choice problems, in which the link existence and relations are decoded separately, or the encoding is restricted to only local interaction, ignoring the holistic structural information. In contrast, we propose a principled method that improves upon previous work from two perspectives: encoding and decoding. From the encoding side, we perform structured encoding on the adjacency matrix followed by the matrix-tree learning algorithm, where all discourse links and relations in the dialogue are jointly optimized based on latent tree-level distribution. From the decoding side, we perform structured inference using the modified Chiu-Liu-Edmonds algorithm, which explicitly generates the labeled multi-root non-projective spanning tree that best captures the discourse structure. In addition, unlike in previous work, we do not rely on hand-crafted features; this improves the model's robustness. Experiments show that our method achieves new state-of-the-art, surpassing the previous model by 2.3 on STAC and 1.5 on Molweni (F1 scores). \footnote{Code released at~\url{https://github.com/chijames/structured_dialogue_discourse_parsing}.}
3D-Aware Adversarial Makeup Generation for Facial Privacy Protection
Jun 26, 2023

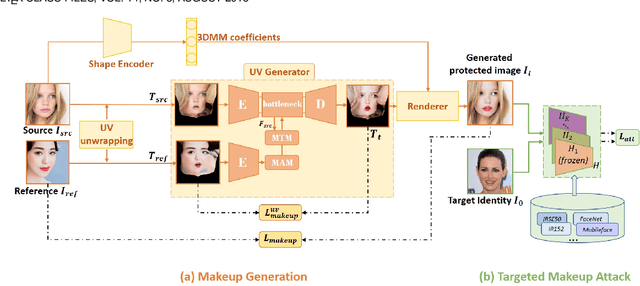
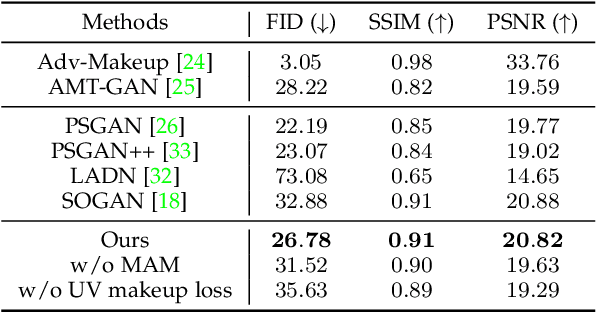
The privacy and security of face data on social media are facing unprecedented challenges as it is vulnerable to unauthorized access and identification. A common practice for solving this problem is to modify the original data so that it could be protected from being recognized by malicious face recognition (FR) systems. However, such ``adversarial examples'' obtained by existing methods usually suffer from low transferability and poor image quality, which severely limits the application of these methods in real-world scenarios. In this paper, we propose a 3D-Aware Adversarial Makeup Generation GAN (3DAM-GAN). which aims to improve the quality and transferability of synthetic makeup for identity information concealing. Specifically, a UV-based generator consisting of a novel Makeup Adjustment Module (MAM) and Makeup Transfer Module (MTM) is designed to render realistic and robust makeup with the aid of symmetric characteristics of human faces. Moreover, a makeup attack mechanism with an ensemble training strategy is proposed to boost the transferability of black-box models. Extensive experiment results on several benchmark datasets demonstrate that 3DAM-GAN could effectively protect faces against various FR models, including both publicly available state-of-the-art models and commercial face verification APIs, such as Face++, Baidu and Aliyun.
Interpretable Sparsification of Brain Graphs: Better Practices and Effective Designs for Graph Neural Networks
Jun 26, 2023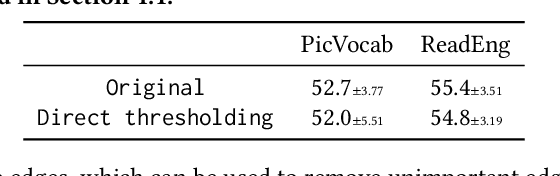
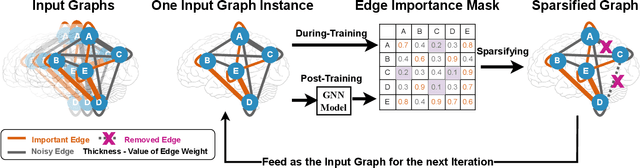
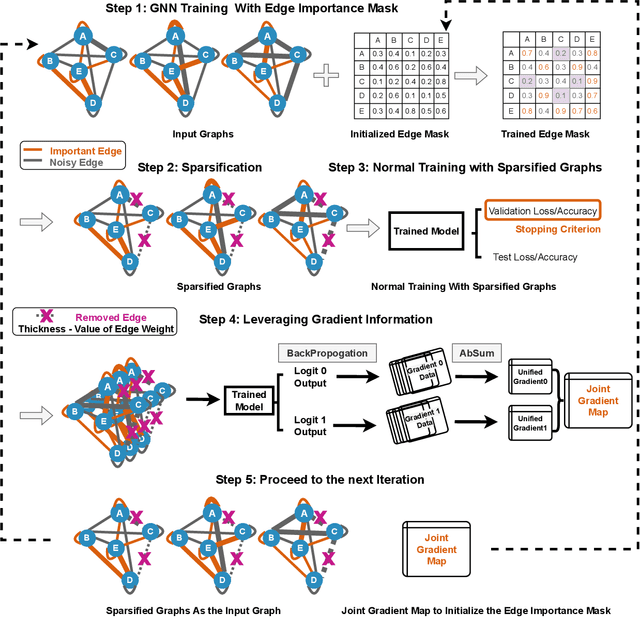
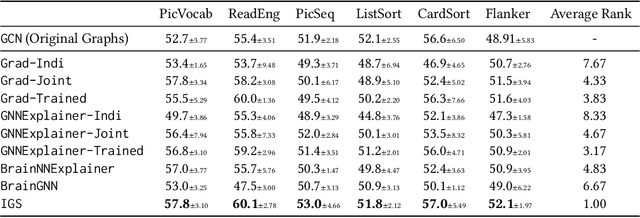
Brain graphs, which model the structural and functional relationships between brain regions, are crucial in neuroscientific and clinical applications involving graph classification. However, dense brain graphs pose computational challenges including high runtime and memory usage and limited interpretability. In this paper, we investigate effective designs in Graph Neural Networks (GNNs) to sparsify brain graphs by eliminating noisy edges. While prior works remove noisy edges based on explainability or task-irrelevant properties, their effectiveness in enhancing performance with sparsified graphs is not guaranteed. Moreover, existing approaches often overlook collective edge removal across multiple graphs. To address these issues, we introduce an iterative framework to analyze different sparsification models. Our findings are as follows: (i) methods prioritizing interpretability may not be suitable for graph sparsification as they can degrade GNNs' performance in graph classification tasks; (ii) simultaneously learning edge selection with GNN training is more beneficial than post-training; (iii) a shared edge selection across graphs outperforms separate selection for each graph; and (iv) task-relevant gradient information aids in edge selection. Based on these insights, we propose a new model, Interpretable Graph Sparsification (IGS), which enhances graph classification performance by up to 5.1% with 55.0% fewer edges. The retained edges identified by IGS provide neuroscientific interpretations and are supported by well-established literature.
Error Feedback Can Accurately Compress Preconditioners
Jun 14, 2023
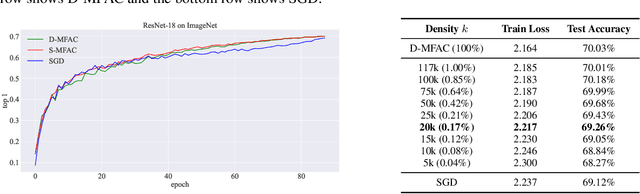

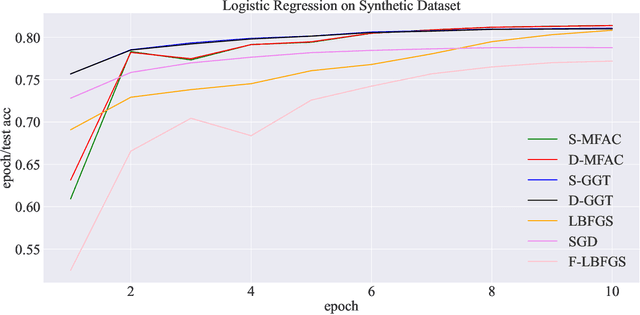
Leveraging second-order information at the scale of deep networks is one of the main lines of approach for improving the performance of current optimizers for deep learning. Yet, existing approaches for accurate full-matrix preconditioning, such as Full-Matrix Adagrad (GGT) or Matrix-Free Approximate Curvature (M-FAC) suffer from massive storage costs when applied even to medium-scale models, as they must store a sliding window of gradients, whose memory requirements are multiplicative in the model dimension. In this paper, we address this issue via an efficient and simple-to-implement error-feedback technique that can be applied to compress preconditioners by up to two orders of magnitude in practice, without loss of convergence. Specifically, our approach compresses the gradient information via sparsification or low-rank compression \emph{before} it is fed into the preconditioner, feeding the compression error back into future iterations. Extensive experiments on deep neural networks for vision show that this approach can compress full-matrix preconditioners by up to two orders of magnitude without impact on accuracy, effectively removing the memory overhead of full-matrix preconditioning for implementations of full-matrix Adagrad (GGT) and natural gradient (M-FAC). Our code is available at https://github.com/IST-DASLab/EFCP.
POP: Prompt Of Prompts for Continual Learning
Jun 14, 2023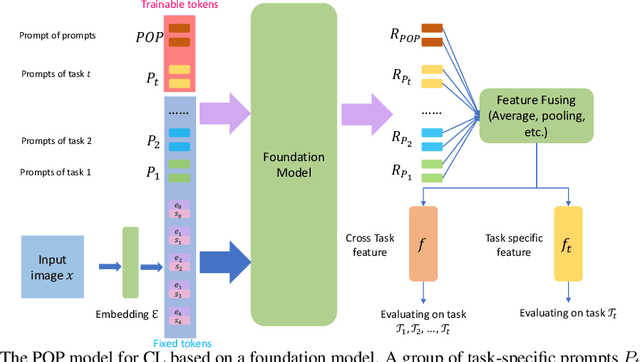
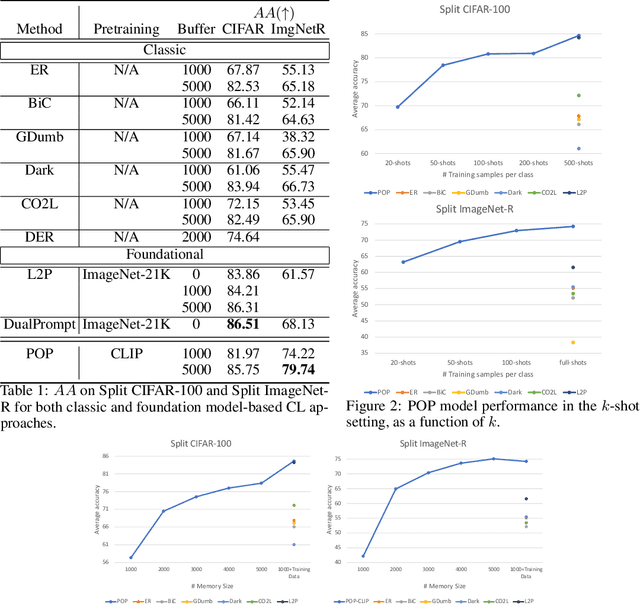
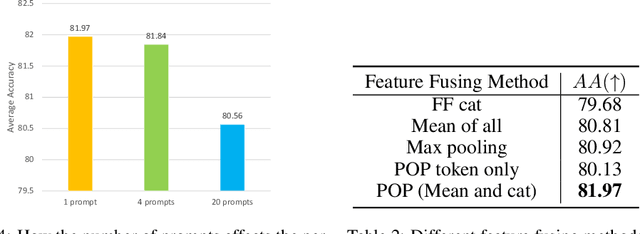
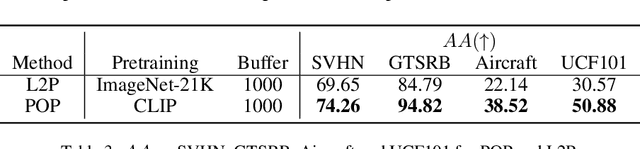
Continual learning (CL) has attracted increasing attention in the recent past. It aims to mimic the human ability to learn new concepts without catastrophic forgetting. While existing CL methods accomplish this to some extent, they are still prone to semantic drift of the learned feature space. Foundation models, which are endowed with a robust feature representation, learned from very large datasets, provide an interesting substrate for the solution of the CL problem. Recent work has also shown that they can be adapted to specific tasks by prompt tuning techniques that leave the generality of the representation mostly unscathed. An open question is, however, how to learn both prompts that are task specific and prompts that are global, i.e. capture cross-task information. In this work, we propose the Prompt Of Prompts (POP) model, which addresses this goal by progressively learning a group of task-specified prompts and a group of global prompts, denoted as POP, to integrate information from the former. We show that a foundation model equipped with POP learning is able to outperform classic CL methods by a significant margin. Moreover, as prompt tuning only requires a small set of training samples, POP is able to perform CL in the few-shot setting, while still outperforming competing methods trained on the entire dataset.
FETNet: Feature Erasing and Transferring Network for Scene Text Removal
Jun 16, 2023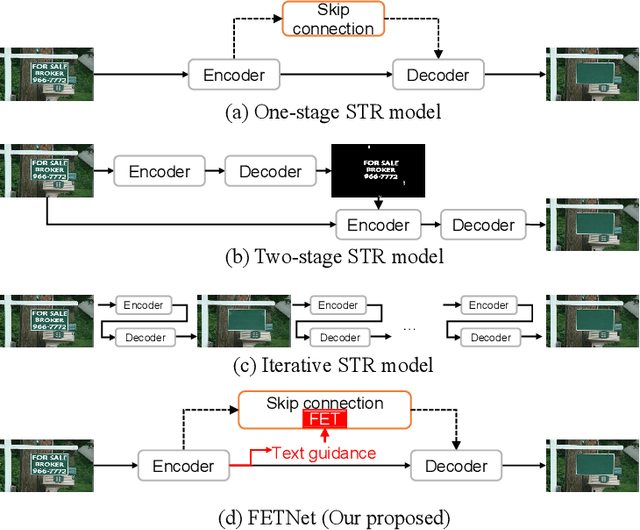
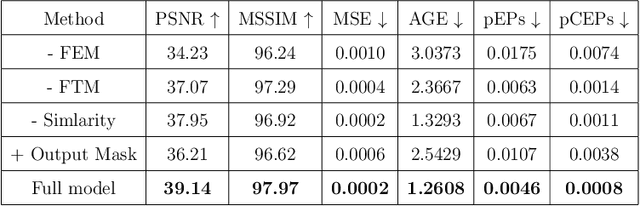
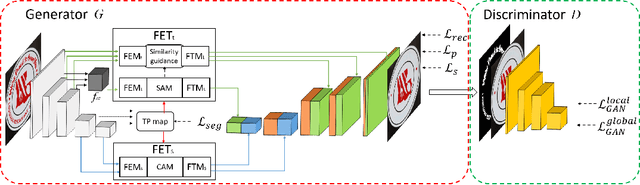

The scene text removal (STR) task aims to remove text regions and recover the background smoothly in images for private information protection. Most existing STR methods adopt encoder-decoder-based CNNs, with direct copies of the features in the skip connections. However, the encoded features contain both text texture and structure information. The insufficient utilization of text features hampers the performance of background reconstruction in text removal regions. To tackle these problems, we propose a novel Feature Erasing and Transferring (FET) mechanism to reconfigure the encoded features for STR in this paper. In FET, a Feature Erasing Module (FEM) is designed to erase text features. An attention module is responsible for generating the feature similarity guidance. The Feature Transferring Module (FTM) is introduced to transfer the corresponding features in different layers based on the attention guidance. With this mechanism, a one-stage, end-to-end trainable network called FETNet is constructed for scene text removal. In addition, to facilitate research on both scene text removal and segmentation tasks, we introduce a novel dataset, Flickr-ST, with multi-category annotations. A sufficient number of experiments and ablation studies are conducted on the public datasets and Flickr-ST. Our proposed method achieves state-of-the-art performance using most metrics, with remarkably higher quality scene text removal results. The source code of our work is available at: \href{https://github.com/GuangtaoLyu/FETNet}{https://github.com/GuangtaoLyu/FETNet.
* Accepted by Pattern Recognition 2023
SplatFlow: Learning Multi-frame Optical Flow via Splatting
Jun 15, 2023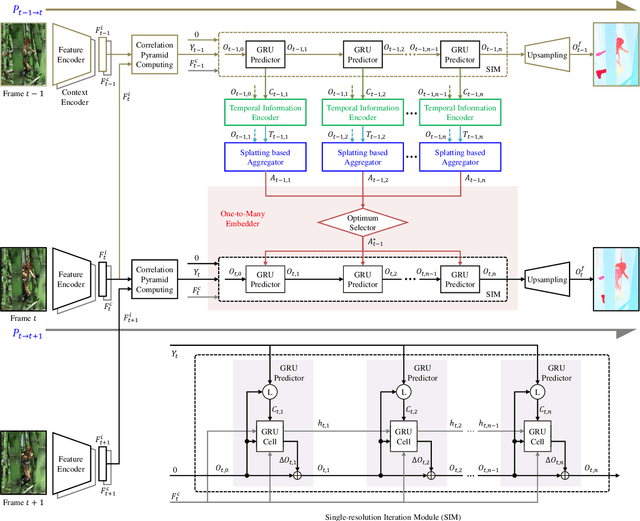
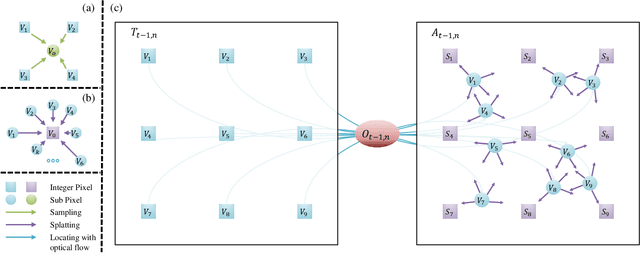
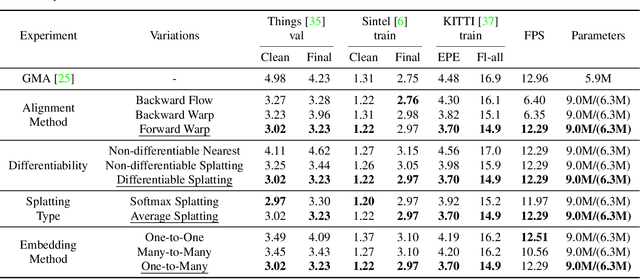
Occlusion problem remains a key challenge in Optical Flow Estimation (OFE) despite the recent significant progress brought by deep learning in the field. Most existing deep learning OFE methods, especially those based on two frames, cannot properly handle occlusions, in part because there is no significant feature similarity in occluded regions. The multi-frame settings have the potential to mitigate the occlusion issue in OFE. However, the problem of Multi-frame OFE (MOFE) remains underexplored, and the limited works are specially designed for pyramid backbones and obtain the aligned temporal information by time-consuming backward flow calculation or non-differentiable forward warping transformation. To address these shortcomings, we propose an efficient MOFE framework named SplatFlow, which is realized by introducing the differentiable splatting transformation to align the temporal information, designing a One-to-Many embedding method to densely guide the current frame's estimation, and further remodelling the existing two-frame backbones. The proposed SplatFlow is very efficient yet more accurate as it is able to handle occlusions properly. Extensive experimental evaluations show that our SplatFlow substantially outperforms all published methods on KITTI2015 and Sintel benchmarks. Especially on Sintel benchmark, SplatFlow achieves errors of 1.12 (clean pass) and 2.07 (final pass), with surprisingly significant 19.4% and 16.2% error reductions from the previous best results submitted, respectively. Code is available at https://github.com/wwsource/SplatFlow.
Deep Learning with Partially Labeled Data for Radio Map Reconstruction
Jun 07, 2023
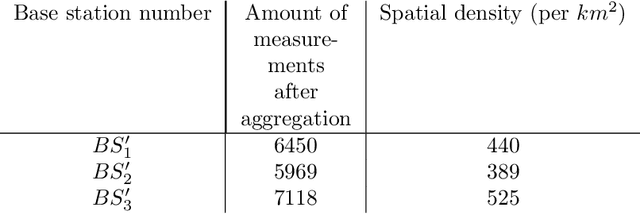
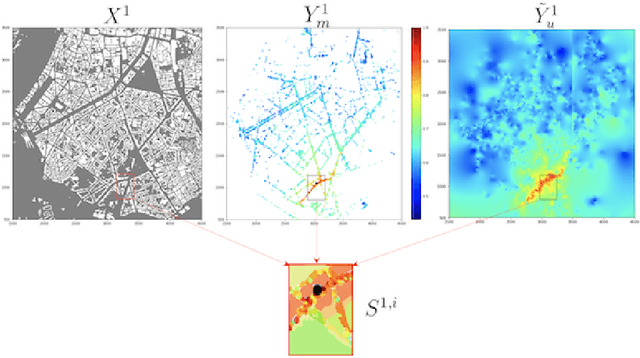

In this paper, we address the problem of Received Signal Strength map reconstruction based on location-dependent radio measurements and utilizing side knowledge about the local region; for example, city plan, terrain height, gateway position. Depending on the quantity of such prior side information, we employ Neural Architecture Search to find an optimized Neural Network model with the best architecture for each of the supposed settings. We demonstrate that using additional side information enhances the final accuracy of the Received Signal Strength map reconstruction on three datasets that correspond to three major cities, particularly in sub-areas near the gateways where larger variations of the average received signal power are typically observed.