 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spatio-Temporal Classification of Lung Ventilation Patterns using 3D EIT Images: A General Approach for Individualized Lung Function Evaluation
Jul 01, 2023
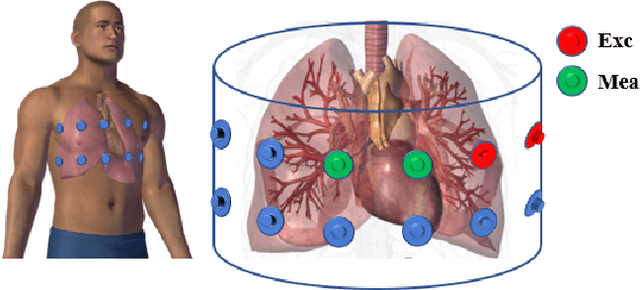
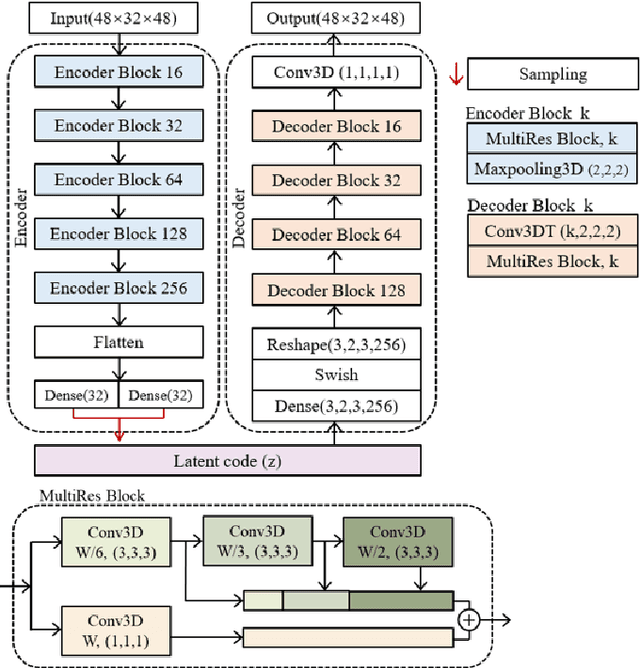
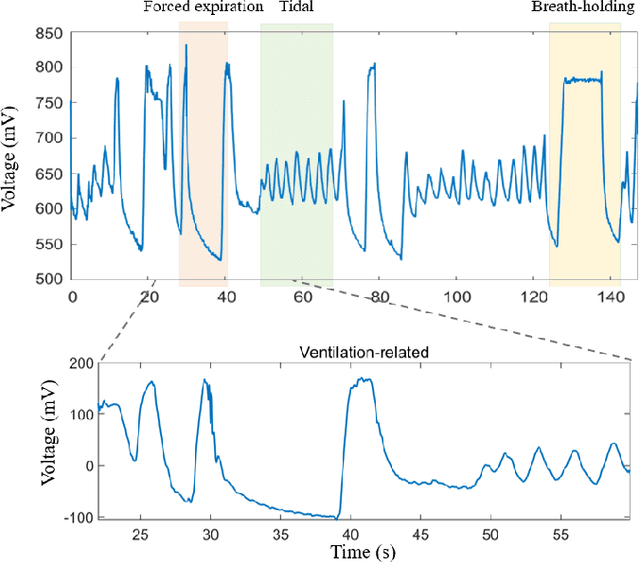
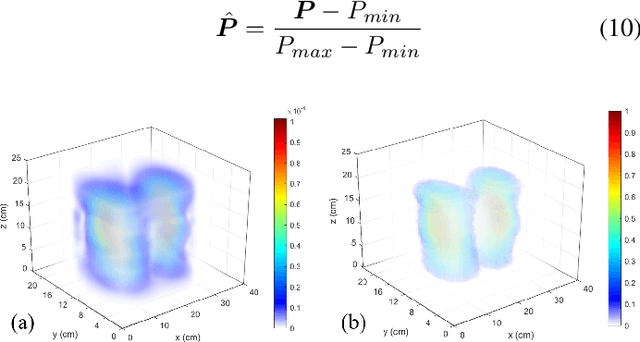
The Pulmonary Function Test (PFT) is an widely utilized and rigorous classification test for lung function evaluation, serving as a comprehensive tool for lung diagnosis. Meanwhile, Electrical Impedance Tomography (EIT) is a rapidly advancing clinical technique that visualizes conductivity distribution induced by ventilation. EIT provides additional spatial and temporal information on lung ventilation beyond traditional PFT. However, relying solely on conventional isolated interpretations of PFT results and EIT images overlooks the continuous dynamic aspects of lung ventilation. This study aims to classify lung ventilation patterns by extracting spatial and temporal features from the 3D EIT image series. The study uses a Variational Autoencoder network with a MultiRes block to compress the spatial distribution in a 3D image into a one-dimensional vector. These vectors are then concatenated to create a feature map for the exhibition of temporal features. A simple convolutional neural network is used for classification. Data collected from 137 subjects were finally used for training. The model is validated by ten-fold and leave-one-out cross-validation first. The accuracy and sensitivity of normal ventilation mode are 0.95 and 1.00, and the f1-score is 0.94. Furthermore, we check the reliability and feasibility of the proposed pipeline by testing it on newly recruited nine subjects. Our results show that the pipeline correctly predicts the ventilation mode of 8 out of 9 subjects. The study demonstrates the potential of using image series for lung ventilation mode classification, providing a feasible method for patient prescreening and presenting an alternative form of PFT.
Applied Bayesian Structural Health Monitoring: inclinometer data anomaly detection and forecasting
Jul 01, 2023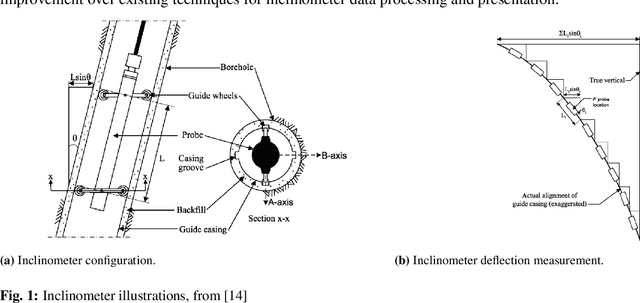
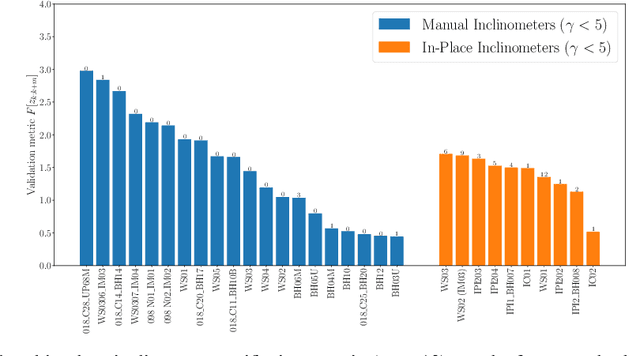
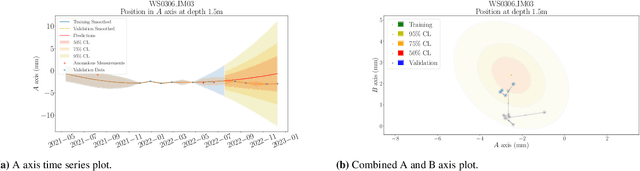
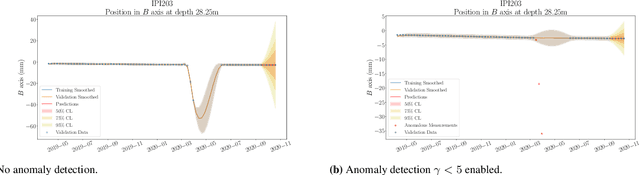
Inclinometer probes are devices that can be used to measure deformations within earthwork slopes. This paper demonstrates a novel application of Bayesian techniques to real-world inclinometer data, providing both anomaly detection and forecasting. Specifically, this paper details an analysis of data collected from inclinometer data across the entire UK rail network. Practitioners have effectively two goals when processing monitoring data. The first is to identify any anomalous or dangerous movements, and the second is to predict potential future adverse scenarios by forecasting. In this paper we apply Uncertainty Quantification (UQ) techniques by implementing a Bayesian approach to anomaly detection and forecasting for inclinometer data. Subsequently, both costs and risks may be minimised by quantifying and evaluating the appropriate uncertainties. This framework may then act as an enabler for enhanced decision making and risk analysis. We show that inclinometer data can be described by a latent autocorrelated Markov process derived from measurements. This can be used as the transition model of a non-linear Bayesian filter. This allows for the prediction of system states. This learnt latent model also allows for the detection of anomalies: observations that are far from their expected value may be considered to have `high surprisal', that is they have a high information content relative to the model encoding represented by the learnt latent model. We successfully apply the forecasting and anomaly detection techniques to a large real-world data set in a computationally efficient manner. Although this paper studies inclinometers in particular, the techniques are broadly applicable to all areas of engineering UQ and Structural Health Monitoring (SHM).
Influence Maximization with Fairness at Scale (Extended Version)
Jun 06, 2023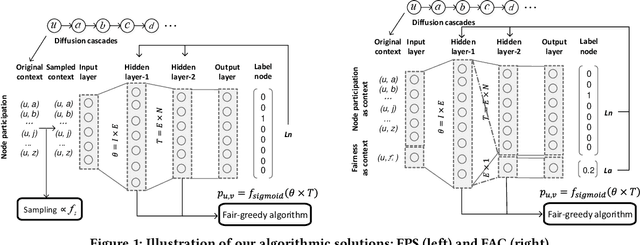
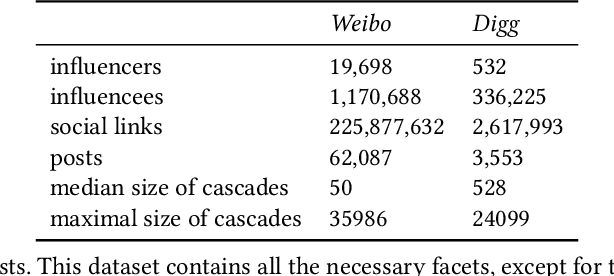
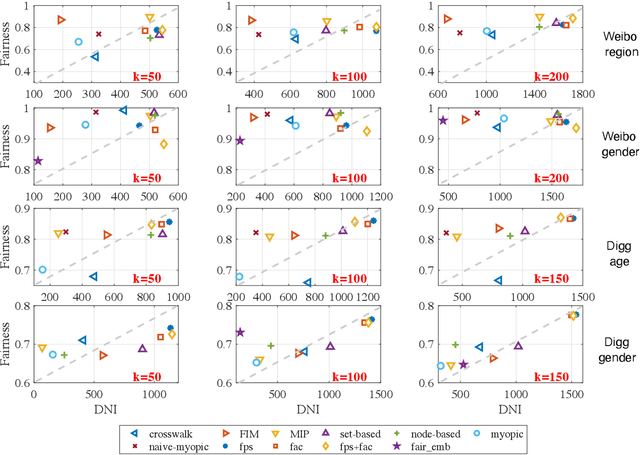
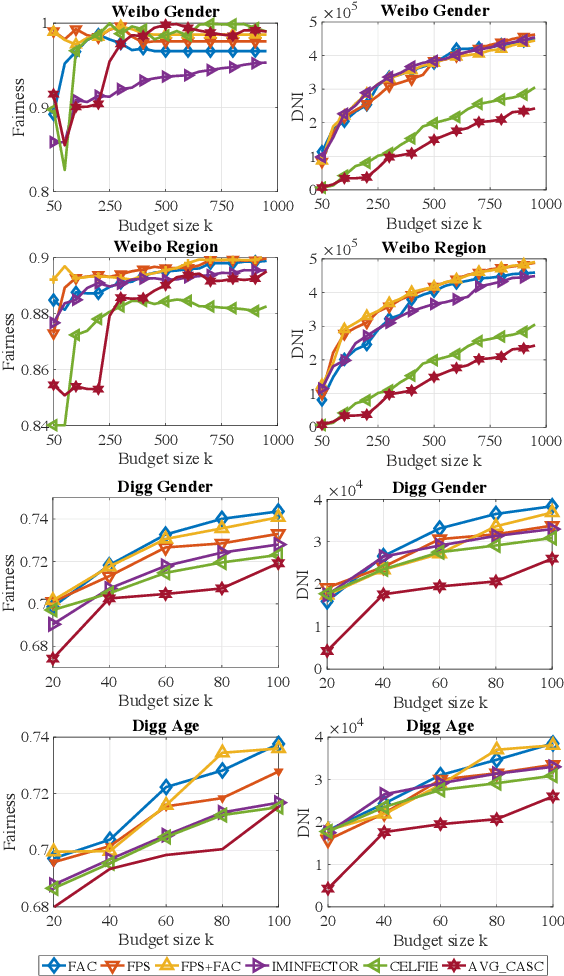
In this paper, we revisit the problem of influence maximization with fairness, which aims to select k influential nodes to maximise the spread of information in a network, while ensuring that selected sensitive user attributes are fairly affected, i.e., are proportionally similar between the original network and the affected users. Recent studies on this problem focused only on extremely small networks, hence the challenge remains on how to achieve a scalable solution, applicable to networks with millions or billions of nodes. We propose an approach that is based on learning node representations for fair spread from diffusion cascades, instead of the social connectivity s.t. we can deal with very large graphs. We propose two data-driven approaches: (a) fairness-based participant sampling (FPS), and (b) fairness as context (FAC). Spread related user features, such as the probability of diffusing information to others, are derived from the historical information cascades, using a deep neural network. The extracted features are then used in selecting influencers that maximize the influence spread, while being also fair with respect to the chosen sensitive attributes. In FPS, fairness and cascade length information are considered independently in the decision-making process, while FAC considers these information facets jointly and considers correlations between them. The proposed algorithms are generic and represent the first policy-driven solutions that can be applied to arbitrary sets of sensitive attributes at scale. We evaluate the performance of our solutions on a real-world public dataset (Sina Weibo) and on a hybrid real-synthethic dataset (Digg), which exhibit all the facets that we exploit, namely diffusion network, diffusion traces, and user profiles. These experiments show that our methods outperform the state-the-art solutions in terms of spread, fairness, and scalability.
Geo-Tiles for Semantic Segmentation of Earth Observation Imagery
Jun 07, 2023


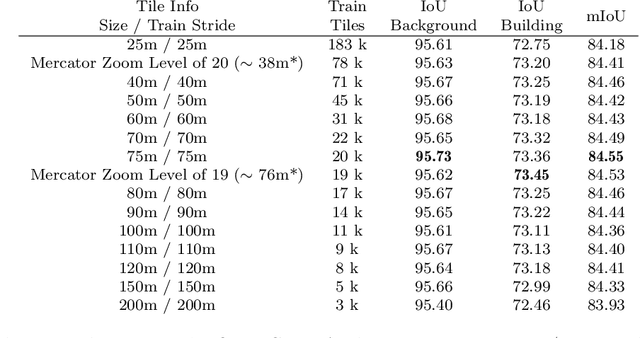
To cope with the high requirements during the computation of semantic segmentations of earth observation imagery, current state-of-the-art pipelines divide the corresponding data into smaller images. Existing methods and benchmark datasets oftentimes rely on pixel-based tiling schemes or on geo-tiling schemes employed by web mapping applications. The selection of subimages (comprising size, location and orientation) is crucial. It affects the available context information of each pixel, defines the number of tiles during training, and influences the degree of information degradation while down- and up-sampling the tile contents to the size required by the segmentation model. We propose a new segmentation pipeline for earth observation imagery relying on a tiling scheme that creates geo-tiles based on the geo-information of the raster data. This approach exhibits several beneficial properties compared to pixel-based or common web mapping approaches. The proposed tiling scheme shows flexible customization properties regarding tile granularity, tile stride and image boundary alignment. This allows us to perform a tile specific data augmentation during training and a substitution of pixel predictions with limited context information using data of overlapping tiles during inference. The generated tiles show a consistent spatial tile extent w.r.t. heterogeneous sensors, varying recording distances and different latitudes. We demonstrate how the proposed tiling system allows to improve the results of current state-of-the-art semantic segmentation models. To foster future research we make the source code publicly available.
Predict to Detect: Prediction-guided 3D Object Detection using Sequential Images
Jun 14, 2023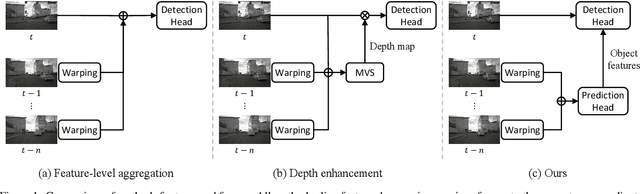
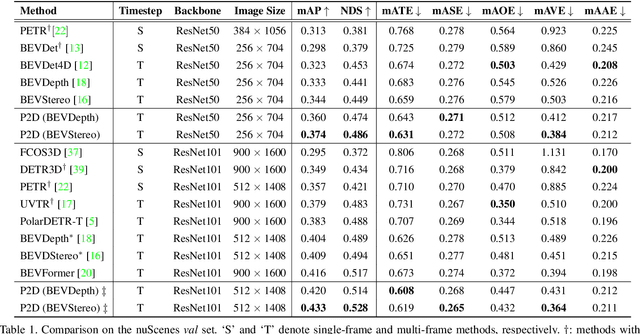
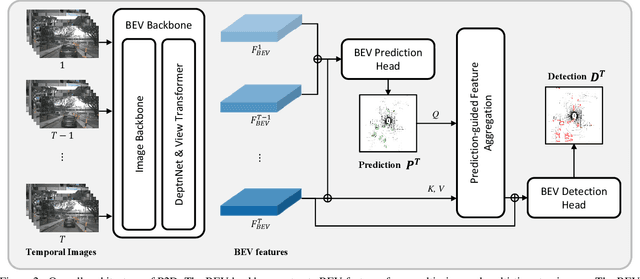

Recent camera-based 3D object detection methods have introduced sequential frames to improve the detection performance hoping that multiple frames would mitigate the large depth estimation error. Despite improved detection performance, prior works rely on naive fusion methods (e.g., concatenation) or are limited to static scenes (e.g., temporal stereo), neglecting the importance of the motion cue of objects. These approaches do not fully exploit the potential of sequential images and show limited performance improvements. To address this limitation, we propose a novel 3D object detection model, P2D (Predict to Detect), that integrates a prediction scheme into a detection framework to explicitly extract and leverage motion features. P2D predicts object information in the current frame using solely past frames to learn temporal motion features. We then introduce a novel temporal feature aggregation method that attentively exploits Bird's-Eye-View (BEV) features based on predicted object information, resulting in accurate 3D object detection. Experimental results demonstrate that P2D improves mAP and NDS by 3.0% and 3.7% compared to the sequential image-based baseline, illustrating that incorporating a prediction scheme can significantly improve detection accuracy.
Active Data Acquisition in Autonomous Driving Simulation
Jun 24, 2023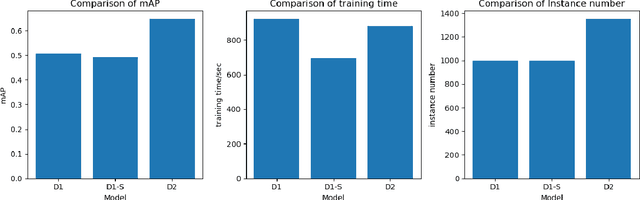

Autonomous driving algorithms rely heavily on learning-based models, which require large datasets for training. However, there is often a large amount of redundant information in these datasets, while collecting and processing these datasets can be time-consuming and expensive. To address this issue, this paper proposes the concept of an active data-collecting strategy. For high-quality data, increasing the collection density can improve the overall quality of the dataset, ultimately achieving similar or even better results than the original dataset with lower labeling costs and smaller dataset sizes. In this paper, we design experiments to verify the quality of the collected dataset and to demonstrate this strategy can significantly reduce labeling costs and dataset size while improving the overall quality of the dataset, leading to better performance of autonomous driving systems. The source code implementing the proposed approach is publicly available on https://github.com/Th1nkMore/carla_dataset_tools.
Large Language Models as Sous Chefs: Revising Recipes with GPT-3
Jun 24, 2023
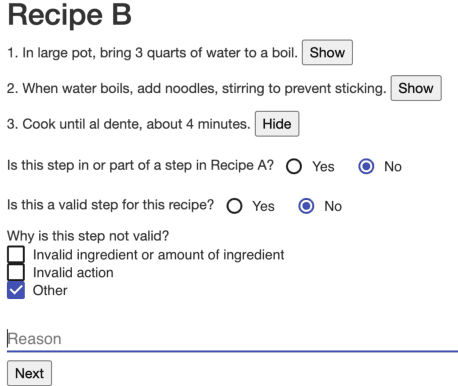

With their remarkably improved text generation and prompting capabilities, large language models can adapt existing written information into forms that are easier to use and understand. In our work, we focus on recipes as an example of complex, diverse, and widely used instructions. We develop a prompt grounded in the original recipe and ingredients list that breaks recipes down into simpler steps. We apply this prompt to recipes from various world cuisines, and experiment with several large language models (LLMs), finding best results with GPT-3.5. We also contribute an Amazon Mechanical Turk task that is carefully designed to reduce fatigue while collecting human judgment of the quality of recipe revisions. We find that annotators usually prefer the revision over the original, demonstrating a promising application of LLMs in serving as digital sous chefs for recipes and beyond. We release our prompt, code, and MTurk template for public use.
Efficient Backdoor Removal Through Natural Gradient Fine-tuning
Jun 30, 2023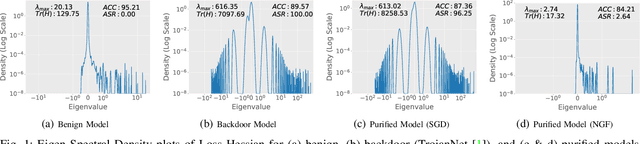
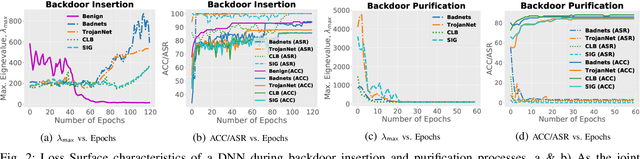

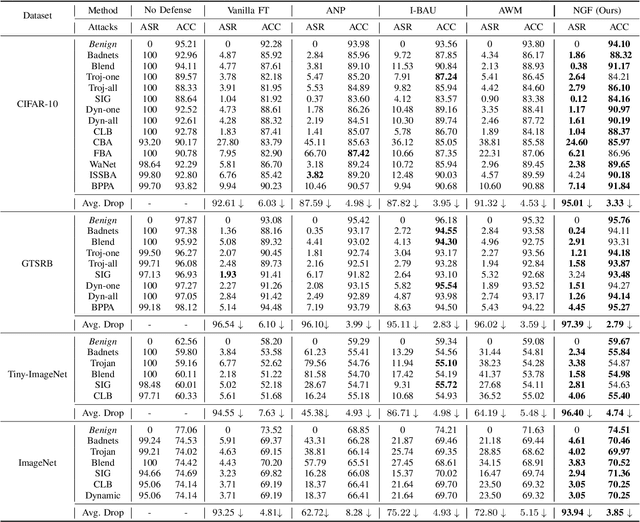
The success of a deep neural network (DNN) heavily relies on the details of the training scheme; e.g., training data, architectures, hyper-parameters, etc. Recent backdoor attacks suggest that an adversary can take advantage of such training details and compromise the integrity of a DNN. Our studies show that a backdoor model is usually optimized to a bad local minima, i.e. sharper minima as compared to a benign model. Intuitively, a backdoor model can be purified by reoptimizing the model to a smoother minima through fine-tuning with a few clean validation data. However, fine-tuning all DNN parameters often requires huge computational costs and often results in sub-par clean test performance. To address this concern, we propose a novel backdoor purification technique, Natural Gradient Fine-tuning (NGF), which focuses on removing the backdoor by fine-tuning only one layer. Specifically, NGF utilizes a loss surface geometry-aware optimizer that can successfully overcome the challenge of reaching a smooth minima under a one-layer optimization scenario. To enhance the generalization performance of our proposed method, we introduce a clean data distribution-aware regularizer based on the knowledge of loss surface curvature matrix, i.e., Fisher Information Matrix. Extensive experiments show that the proposed method achieves state-of-the-art performance on a wide range of backdoor defense benchmarks: four different datasets- CIFAR10, GTSRB, Tiny-ImageNet, and ImageNet; 13 recent backdoor attacks, e.g. Blend, Dynamic, WaNet, ISSBA, etc.
Application of data engineering approaches to address challenges in microbiome data for optimal medical decision-making
Jun 30, 2023The human gut microbiota is known to contribute to numerous physiological functions of the body through their interplay with multiple organs and also implicated in a myriad of pathological conditions. Prolific research work in the past few decades have yielded valuable information regarding the relative taxonomic distribution of the gut microbiota that could enable personalized medicine. Unfortunately, the microbiome data suffers from class imbalance and high dimensionality issues that must be addressed. In this study, we have implemented data engineering algorithms to address the above-mentioned issues inherent to microbiome data. Four standard machine learning classifiers (logistic regression (LR), support vector machines (SVM), random forests (RF), and extreme gradient boosting (XGB) decision trees) were implemented on a previously published dataset of infants with cystic fibrosis exhibiting normal vs abnormal growth patterns. The issue of class imbalance and high dimensionality of the data was addressed through synthetic minority oversampling technique (SMOTE) and principal component analysis (PCA). Classification of host phenotype was performed at multiple levels of taxonomic hierarchy. Our results indicate that ensemble classifiers (RF and XGB decision trees) exhibit superior classification accuracy in predicting the host phenotype. The application of PCA significantly reduced the testing time while maintaining high classification accuracy. The highest classification accuracy was obtained at the levels of species for most classifiers. The prototype employed in the study addresses the issues inherent to microbiome datasets and could be highly beneficial for providing personalized medicine.
Learning to Localize with Attention: from sparse mmWave channel estimates from a single BS to high accuracy 3D location
Jun 30, 2023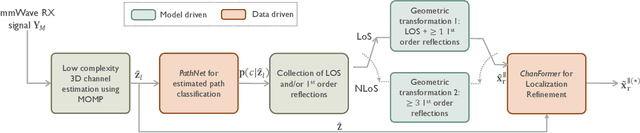
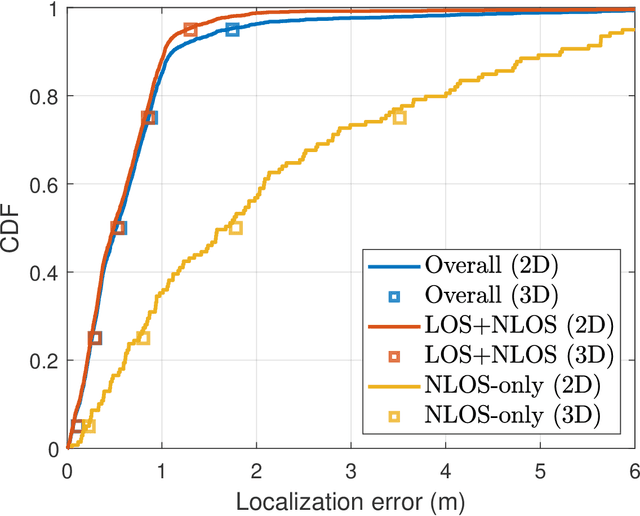
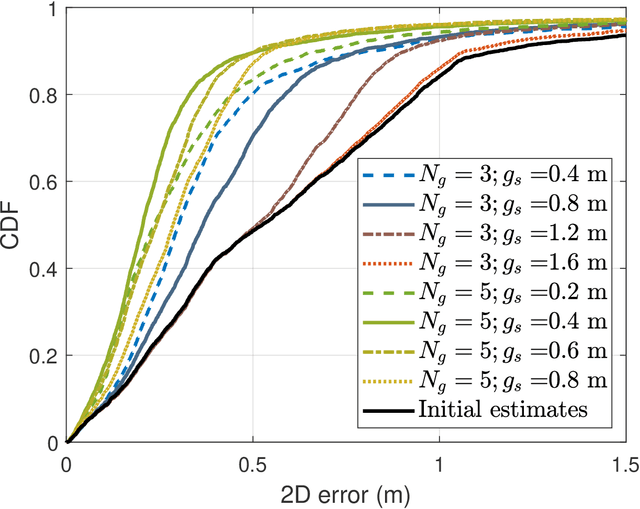
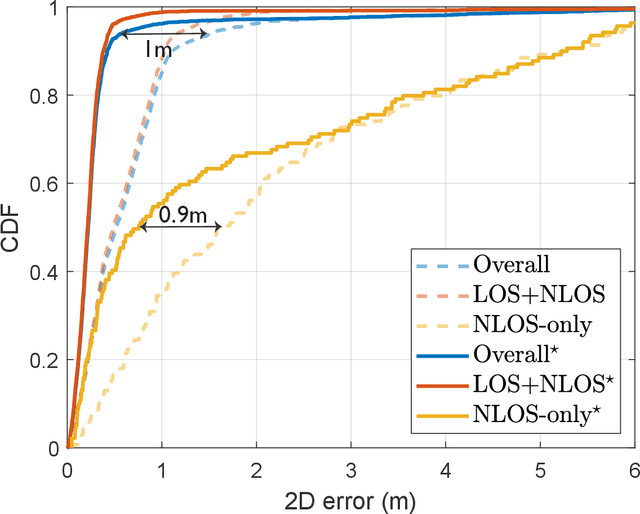
One strategy to obtain user location information in a wireless network operating at millimeter wave (mmWave) is based on the exploitation of the geometric relationships between the channel parameters and the user position. These relationships can be easily built from the LoS path and/or first order reflections, but high resolution channel estimates are required for high accuracy. In this paper, we consider a mmWave MIMO system based on a hybrid architecture, and develop first a low complexity channel estimation strategy based on MOMP suitable for high dimensional channels, as those associated to operating with large planar arrays. Then, a deep neural network (DNN) called PathNet is designed to classify the order of the estimated channel paths, so that only the line-of-sight (LOS) path and first order reflections are selected for localization purposes. Next, a 3D localization strategy exploiting the geometry of the environment is developed to operate in both LOS and non-line-of-sight (NLOS) conditions, while considering the unknown clock offset between the transmitter (TX) and the receiver (RX). Finally, a Transformer based network exploiting attention mechanisms called ChanFormer is proposed to refine the initial position estimate obtained from the geometric system of equations that connects user position and channel parameters. Simulation results obtained with realistic vehicular channels generated by ray tracing indicate that sub-meter accuracy (<= 0.45 m) can be achieved for 95% of the users in LOS channels, and for 50% of the users in NLOS conditions.