 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Vision-based Oxy-fuel Torch Control for Robotic Metal Cutting
Jun 30, 2023


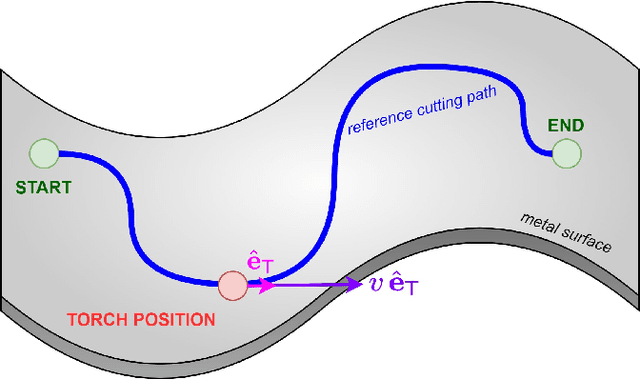

The automation of key processes in metal cutting would substantially benefit many industries such as manufacturing and metal recycling. We present a vision-based control scheme for automated metal cutting with oxy-fuel torches, an established cutting medium in industry. The system consists of a robot equipped with a cutting torch and an eye-in-hand camera observing the scene behind a tinted visor. We develop a vision-based control algorithm to servo the torch's motion by visually observing its effects on the metal surface. As such, the vision system processes the metal surface's heat pool and computes its associated features, specifically pool convexity and intensity, which are then used for control. The operating conditions of the control problem are defined within which the stability is proven. In addition, metal cutting experiments are performed using a physical 1-DOF robot and oxy-fuel cutting equipment. Our results demonstrate the successful cutting of metal plates across three different plate thicknesses, relying purely on visual information without a priori knowledge of the thicknesses.
Approximate, Adapt, Anonymize (3A): a Framework for Privacy Preserving Training Data Release for Machine Learning
Jul 04, 2023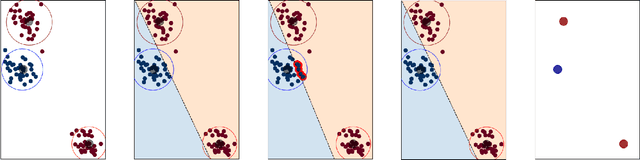

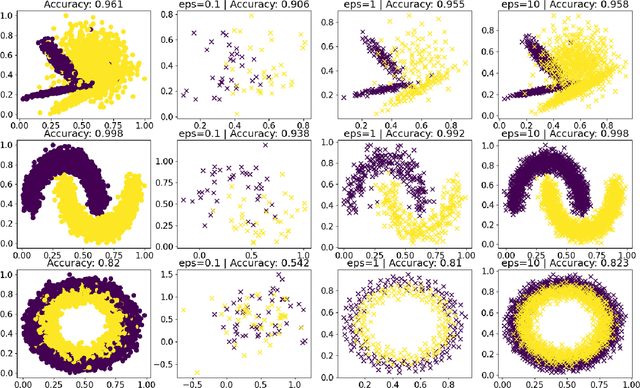
The availability of large amounts of informative data is crucial for successful machine learning. However, in domains with sensitive information, the release of high-utility data which protects the privacy of individuals has proven challenging. Despite progress in differential privacy and generative modeling for privacy-preserving data release in the literature, only a few approaches optimize for machine learning utility: most approaches only take into account statistical metrics on the data itself and fail to explicitly preserve the loss metrics of machine learning models that are to be subsequently trained on the generated data. In this paper, we introduce a data release framework, 3A (Approximate, Adapt, Anonymize), to maximize data utility for machine learning, while preserving differential privacy. We also describe a specific implementation of this framework that leverages mixture models to approximate, kernel-inducing points to adapt, and Gaussian differential privacy to anonymize a dataset, in order to ensure that the resulting data is both privacy-preserving and high utility. We present experimental evidence showing minimal discrepancy between performance metrics of models trained on real versus privatized datasets, when evaluated on held-out real data. We also compare our results with several privacy-preserving synthetic data generation models (such as differentially private generative adversarial networks), and report significant increases in classification performance metrics compared to state-of-the-art models. These favorable comparisons show that the presented framework is a promising direction of research, increasing the utility of low-risk synthetic data release for machine learning.
* 10 pages, 3 figures, AAAI Workshop
DsMtGCN: A Direction-sensitive Multi-task framework for Knowledge Graph Completion
Jun 17, 2023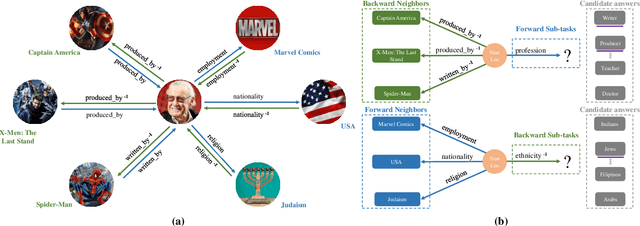
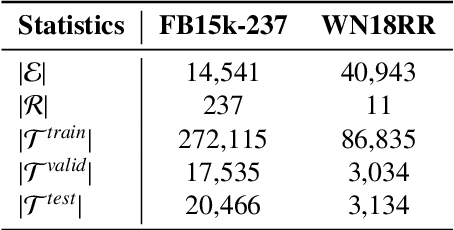
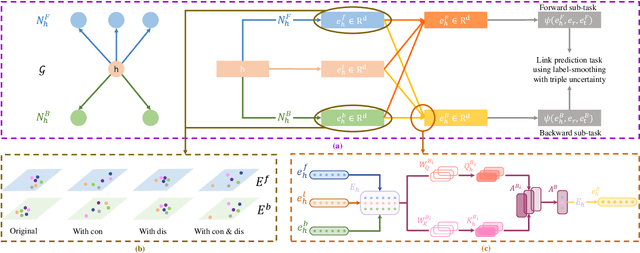
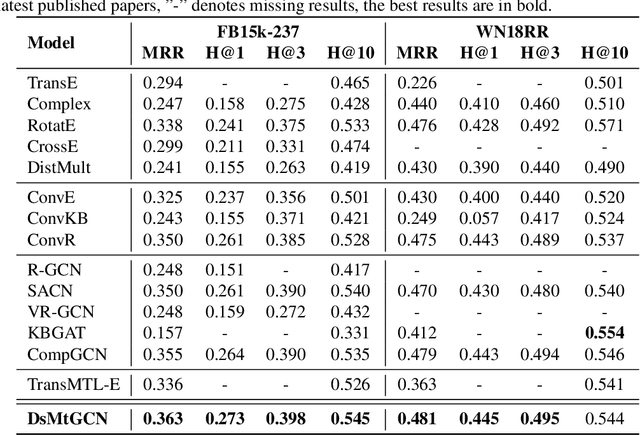
To solve the inherent incompleteness of knowledge graphs (KGs), numbers of knowledge graph completion (KGC) models have been proposed to predict missing links from known triples. Among those, several works have achieved more advanced results via exploiting the structure information on KGs with Graph Convolutional Networks (GCN). However, we observe that entity embeddings aggregated from neighbors in different directions are just simply averaged to complete single-tasks by existing GCN based models, ignoring the specific requirements of forward and backward sub-tasks. In this paper, we propose a Direction-sensitive Multi-task GCN (DsMtGCN) to make full use of the direction information, the multi-head self-attention is applied to specifically combine embeddings in different directions based on various entities and sub-tasks, the geometric constraints are imposed to adjust the distribution of embeddings, and the traditional binary cross-entropy loss is modified to reflect the triple uncertainty. Moreover, the competitive experiments results on several benchmark datasets verify the effectiveness of our model.
Mass Spectra Prediction with Structural Motif-based Graph Neural Networks
Jun 28, 2023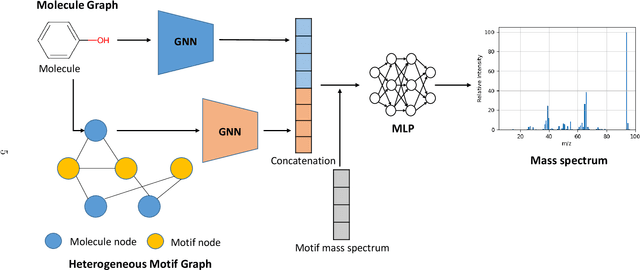
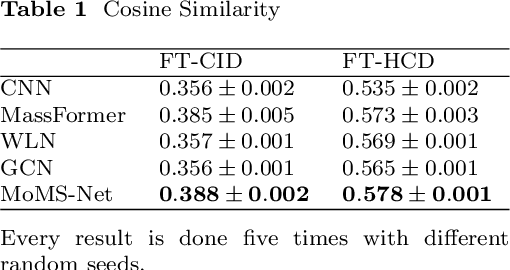
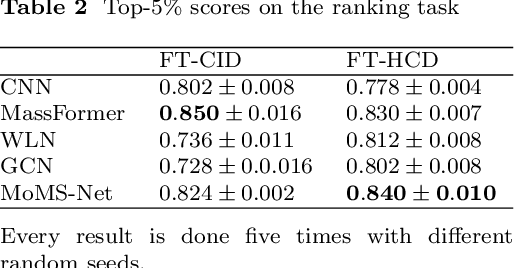
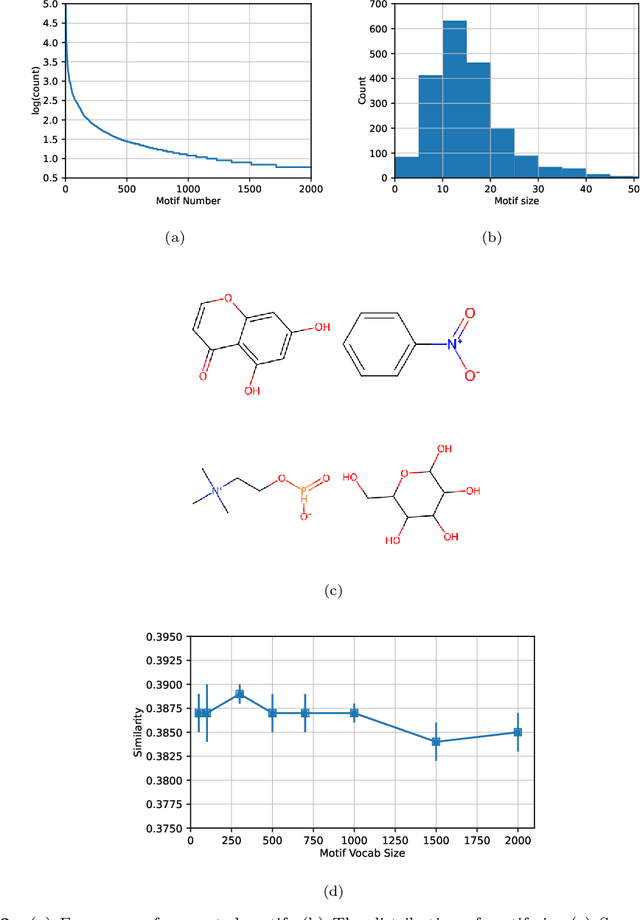
Mass spectra, which are agglomerations of ionized fragments from targeted molecules, play a crucial role across various fields for the identification of molecular structures. A prevalent analysis method involves spectral library searches,where unknown spectra are cross-referenced with a database. The effectiveness of such search-based approaches, however, is restricted by the scope of the existing mass spectra database, underscoring the need to expand the database via mass spectra prediction. In this research, we propose the Motif-based Mass Spectrum Prediction Network (MoMS-Net), a system that predicts mass spectra using the information derived from structural motifs and the implementation of Graph Neural Networks (GNNs). We have tested our model across diverse mass spectra and have observed its superiority over other existing models. MoMS-Net considers substructure at the graph level, which facilitates the incorporation of long-range dependencies while using less memory compared to the graph transformer model.
Point2Point : A Framework for Efficient Deep Learning on Hilbert sorted Point Clouds with applications in Spatio-Temporal Occupancy Prediction
Jun 28, 2023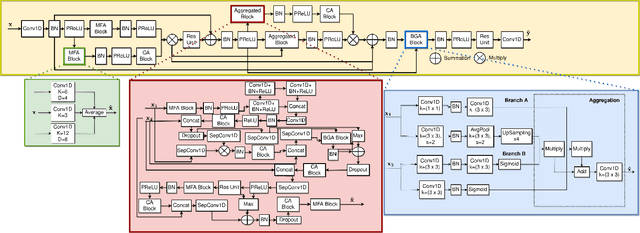

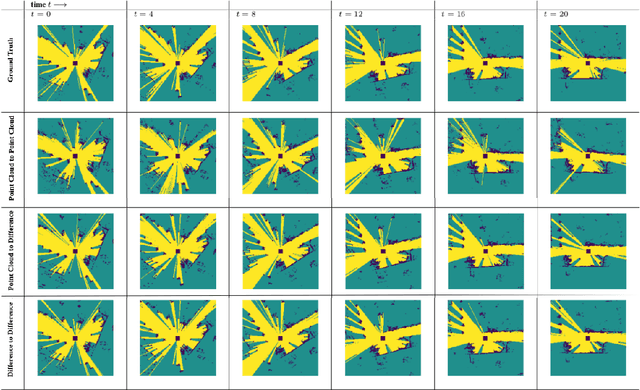
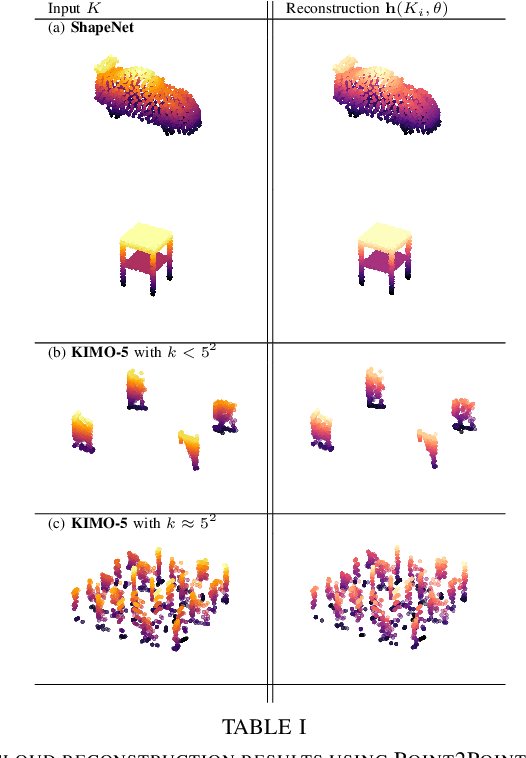
The irregularity and permutation invariance of point cloud data pose challenges for effective learning. Conventional methods for addressing this issue involve converting raw point clouds to intermediate representations such as 3D voxel grids or range images. While such intermediate representations solve the problem of permutation invariance, they can result in significant loss of information. Approaches that do learn on raw point clouds either have trouble in resolving neighborhood relationships between points or are too complicated in their formulation. In this paper, we propose a novel approach to representing point clouds as a locality preserving 1D ordering induced by the Hilbert space-filling curve. We also introduce Point2Point, a neural architecture that can effectively learn on Hilbert-sorted point clouds. We show that Point2Point shows competitive performance on point cloud segmentation and generation tasks. Finally, we show the performance of Point2Point on Spatio-temporal Occupancy prediction from Point clouds.
Chan-Vese Attention U-Net: An attention mechanism for robust segmentation
Jun 28, 2023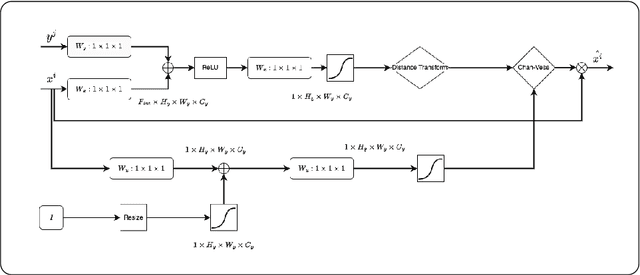
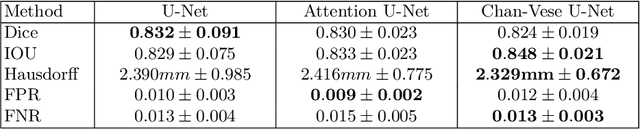
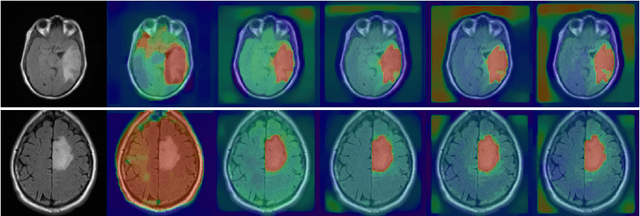
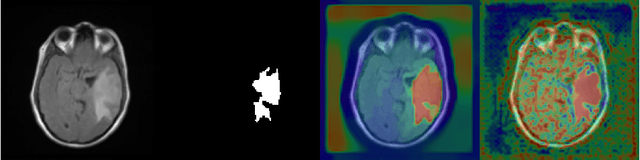
When studying the results of a segmentation algorithm using convolutional neural networks, one wonders about the reliability and consistency of the results. This leads to questioning the possibility of using such an algorithm in applications where there is little room for doubt. We propose in this paper a new attention gate based on the use of Chan-Vese energy minimization to control more precisely the segmentation masks given by a standard CNN architecture such as the U-Net model. This mechanism allows to obtain a constraint on the segmentation based on the resolution of a PDE. The study of the results allows us to observe the spatial information retained by the neural network on the region of interest and obtains competitive results on the binary segmentation. We illustrate the efficiency of this approach for medical image segmentation on a database of MRI brain images.
Bayesian Game Formulation of Power Allocation in Multiple Access Wiretap Channel with Incomplete CSI
Jun 15, 2023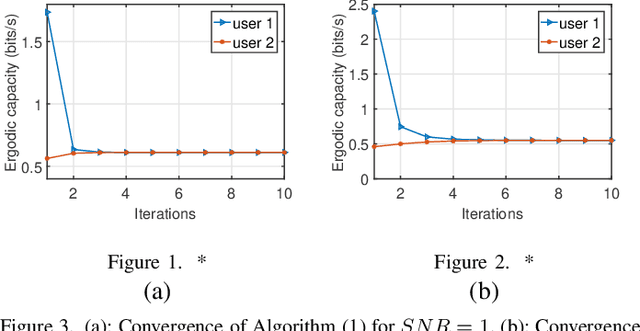
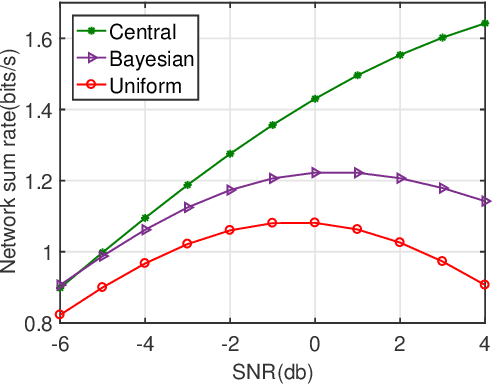
In this paper, we address the problem of distributed power allocation in a $K$ user fading multiple access wiretap channel, where global channel state information is limited, i.e., each user has knowledge of their own channel state with respect to Bob and Eve but only knows the distribution of other users' channel states. We model this problem as a Bayesian game, where each user is assumed to selfishly maximize his average \emph{secrecy capacity} with partial channel state information. In this work, we first prove that there is a unique Bayesian equilibrium in the proposed game. Additionally, the price of anarchy is calculated to measure the efficiency of the equilibrium solution. We also propose a fast convergent iterative algorithm for power allocation. Finally, the results are validated using simulation results.
Metric Learning-Based Timing Synchronization by Using Lightweight Neural Network
Jul 01, 2023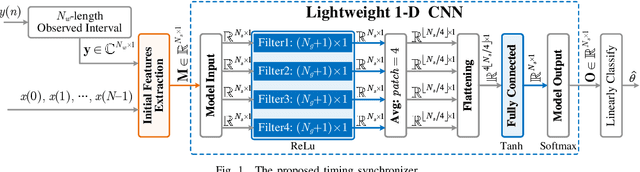
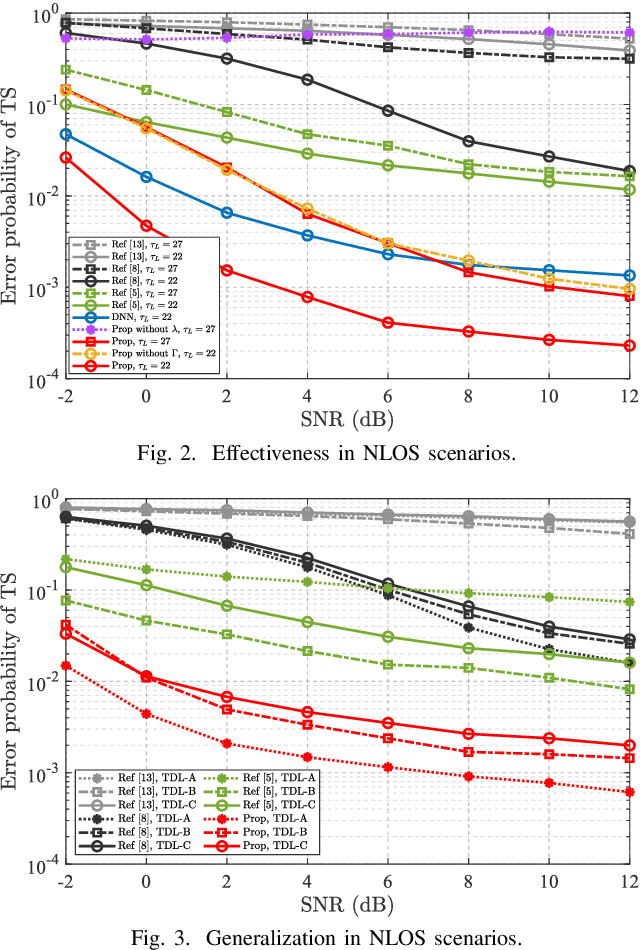
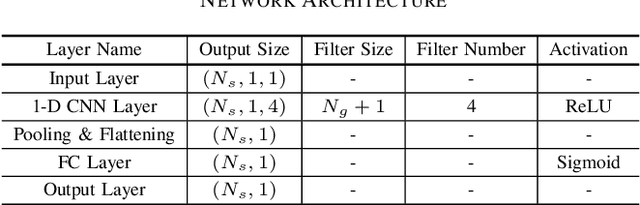

Timing synchronization (TS) is one of the key tasks in orthogonal frequency division multiplexing (OFDM) systems. However, multi-path uncertainty corrupts the TS correctness, making OFDM systems suffer from a severe inter-symbol-interference (ISI). To tackle this issue, we propose a timing-metric learning-based TS method assisted by a lightweight one-dimensional convolutional neural network (1-D CNN). Specifically, the receptive field of 1-D CNN is specifically designed to extract the metric features from the classic synchronizer. Then, to combat the multi-path uncertainty, we employ the varying delays and gains of multi-path (the characteristics of multi-path uncertainty) to design the timing-metric objective, and thus form the training labels. This is typically different from the existing timing-metric objectives with respect to the timing synchronization point. Our method substantively increases the completeness of training data against the multi-path uncertainty due to the complete preservation of metric information. By this mean, the TS correctness is improved against the multi-path uncertainty. Numerical results demonstrate the effectiveness and generalization of the proposed TS method against the multi-path uncertainty.
Artifacts Mapping: Multi-Modal Semantic Mapping for Object Detection and 3D Localization
Jul 03, 2023
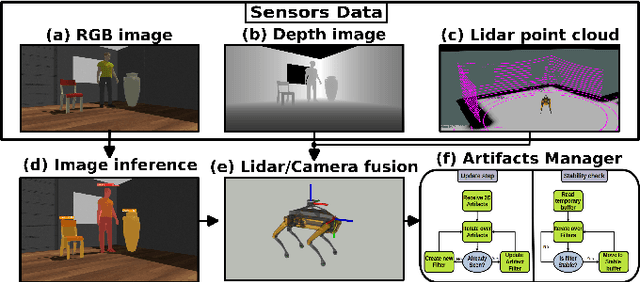

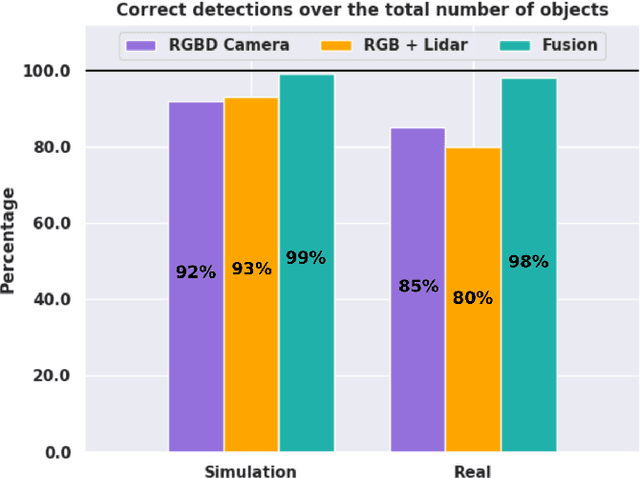
Geometric navigation is nowadays a well-established field of robotics and the research focus is shifting towards higher-level scene understanding, such as Semantic Mapping. When a robot needs to interact with its environment, it must be able to comprehend the contextual information of its surroundings. This work focuses on classifying and localising objects within a map, which is under construction (SLAM) or already built. To further explore this direction, we propose a framework that can autonomously detect and localize predefined objects in a known environment using a multi-modal sensor fusion approach (combining RGB and depth data from an RGB-D camera and a lidar). The framework consists of three key elements: understanding the environment through RGB data, estimating depth through multi-modal sensor fusion, and managing artifacts (i.e., filtering and stabilizing measurements). The experiments show that the proposed framework can accurately detect 98% of the objects in the real sample environment, without post-processing, while 85% and 80% of the objects were mapped using the single RGBD camera or RGB + lidar setup respectively. The comparison with single-sensor (camera or lidar) experiments is performed to show that sensor fusion allows the robot to accurately detect near and far obstacles, which would have been noisy or imprecise in a purely visual or laser-based approach.
HODINet: High-Order Discrepant Interaction Network for RGB-D Salient Object Detection
Jul 03, 2023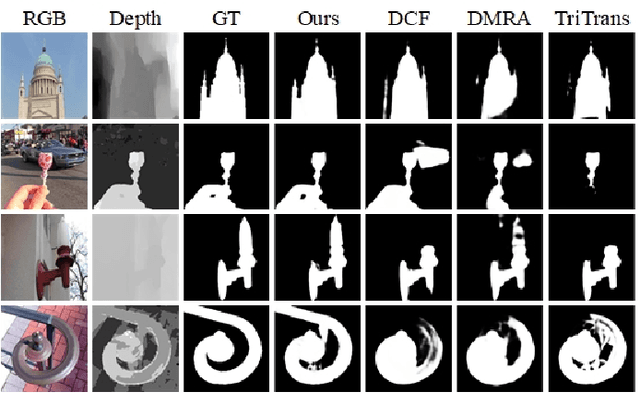
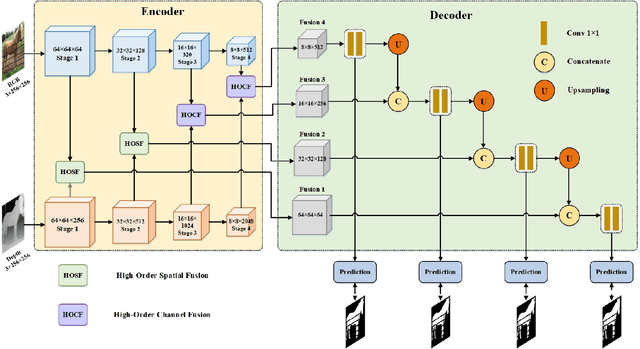
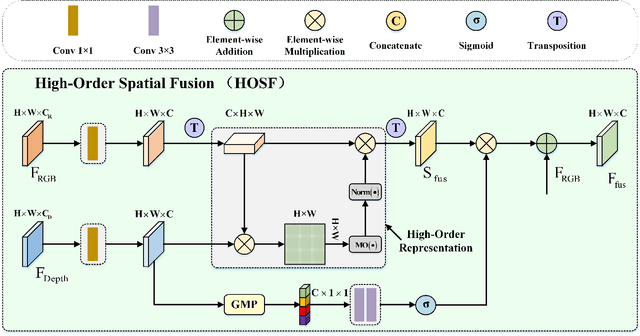
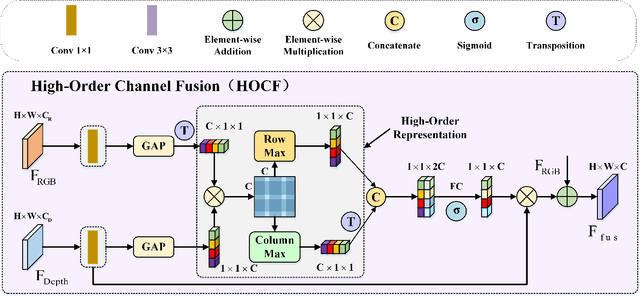
RGB-D salient object detection (SOD) aims to detect the prominent regions by jointly modeling RGB and depth information. Most RGB-D SOD methods apply the same type of backbones and fusion modules to identically learn the multimodality and multistage features. However, these features contribute differently to the final saliency results, which raises two issues: 1) how to model discrepant characteristics of RGB images and depth maps; 2) how to fuse these cross-modality features in different stages. In this paper, we propose a high-order discrepant interaction network (HODINet) for RGB-D SOD. Concretely, we first employ transformer-based and CNN-based architectures as backbones to encode RGB and depth features, respectively. Then, the high-order representations are delicately extracted and embedded into spatial and channel attentions for cross-modality feature fusion in different stages. Specifically, we design a high-order spatial fusion (HOSF) module and a high-order channel fusion (HOCF) module to fuse features of the first two and the last two stages, respectively. Besides, a cascaded pyramid reconstruction network is adopted to progressively decode the fused features in a top-down pathway. Extensive experiments are conducted on seven widely used datasets to demonstrate the effectiveness of the proposed approach. We achieve competitive performance against 24 state-of-the-art methods under four evaluation metrics.