 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diffusion Models for Computational Design at the Example of Floor Plans
Jul 05, 2023
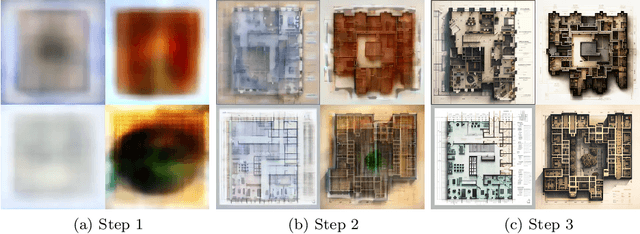
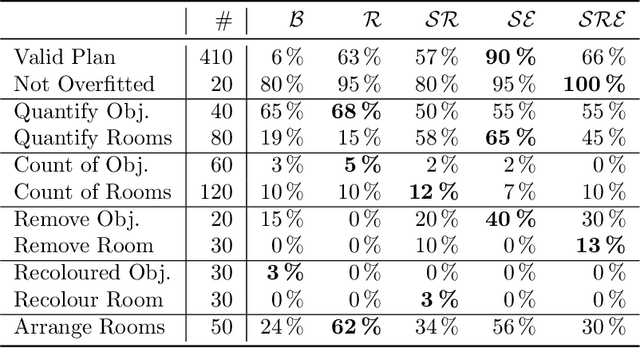
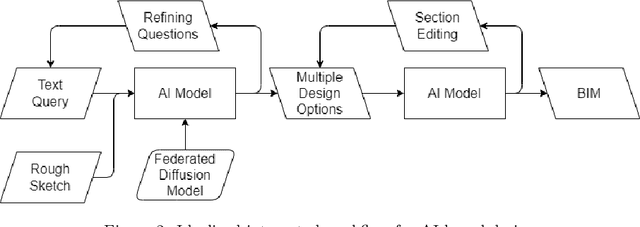
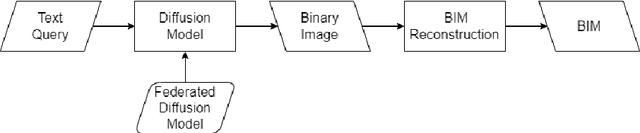
AI Image generators based on diffusion models are widely discussed recently for their capability to create images from simple text prompts. But, for practical use in civil engineering they need to be able to create specific construction plans for given constraints. Within this paper we explore the capabilities of those diffusion-based AI generators for computational design at the example of floor plans and identify their current limitation. We explain how the diffusion-models work and propose new diffusion models with improved semantic encoding. In several experiments we show that we can improve validity of generated floor plans from 6% to 90% and query performance for different examples. We identify short comings and derive future research challenges of those models and discuss the need to combine diffusion models with building information modelling. With this we provide key insights into the current state and future directions for diffusion models in civil engineering.
First Place Solution to the CVPR'2023 AQTC Challenge: A Function-Interaction Centric Approach with Spatiotemporal Visual-Language Alignment
Jun 23, 2023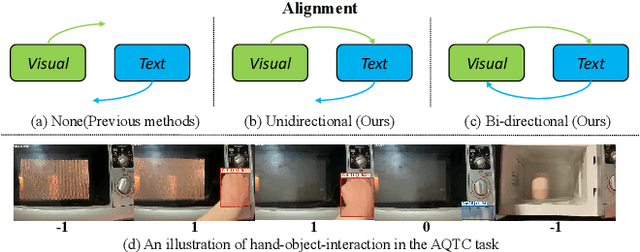

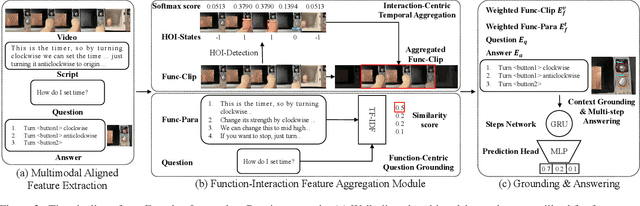

Affordance-Centric Question-driven Task Completion (AQTC) has been proposed to acquire knowledge from videos to furnish users with comprehensive and systematic instructions. However, existing methods have hitherto neglected the necessity of aligning spatiotemporal visual and linguistic signals, as well as the crucial interactional information between humans and objects. To tackle these limitations, we propose to combine large-scale pre-trained vision-language and video-language models, which serve to contribute stable and reliable multimodal data and facilitate effective spatiotemporal visual-textual alignment. Additionally, a novel hand-object-interaction (HOI) aggregation module is proposed which aids in capturing human-object interaction information, thereby further augmenting the capacity to understand the presented scenario. Our method achieved first place in the CVPR'2023 AQTC Challenge, with a Recall@1 score of 78.7\%. The code is available at https://github.com/tomchen-ctj/CVPR23-LOVEU-AQTC.
A metric learning approach for endoscopic kidney stone identification
Jul 13, 2023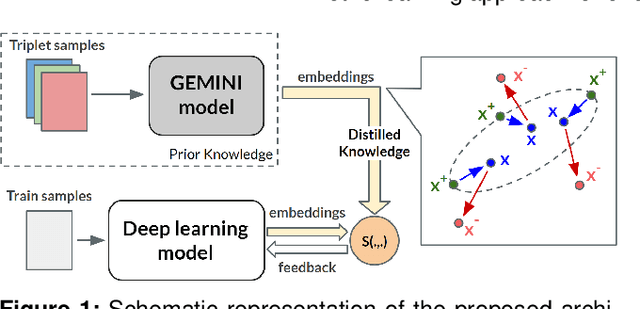
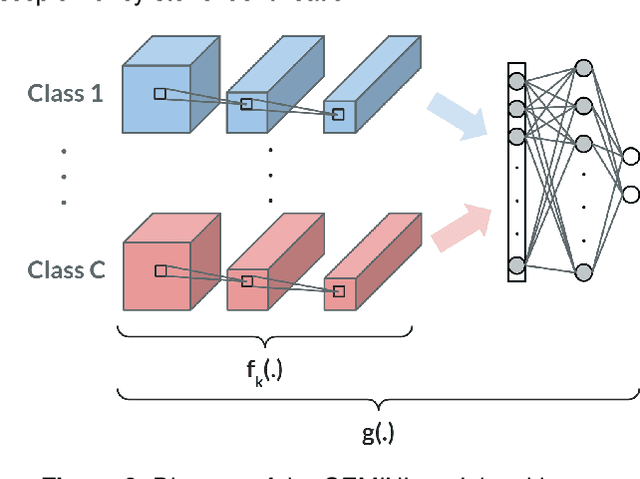
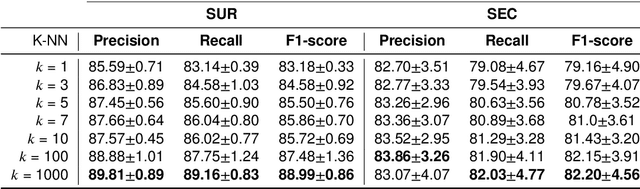
Several Deep Learning (DL) methods have recently been proposed for an automated identification of kidney stones during an ureteroscopy to enable rapid therapeutic decisions. Even if these DL approaches led to promising results, they are mainly appropriate for kidney stone types for which numerous labelled data are available. However, only few labelled images are available for some rare kidney stone types. This contribution exploits Deep Metric Learning (DML) methods i) to handle such classes with few samples, ii) to generalize well to out of distribution samples, and iii) to cope better with new classes which are added to the database. The proposed Guided Deep Metric Learning approach is based on a novel architecture which was designed to learn data representations in an improved way. The solution was inspired by Few-Shot Learning (FSL) and makes use of a teacher-student approach. The teacher model (GEMINI) generates a reduced hypothesis space based on prior knowledge from the labeled data, and is used it as a guide to a student model (i.e., ResNet50) through a Knowledge Distillation scheme. Extensive tests were first performed on two datasets separately used for the recognition, namely a set of images acquired for the surfaces of the kidney stone fragments, and a set of images of the fragment sections. The proposed DML-approach improved the identification accuracy by 10% and 12% in comparison to DL-methods and other DML-approaches, respectively. Moreover, model embeddings from the two dataset types were merged in an organized way through a multi-view scheme to simultaneously exploit the information of surface and section fragments. Test with the resulting mixed model improves the identification accuracy by at least 3% and up to 30% with respect to DL-models and shallow machine learning methods, respectively.
GlobalNER: Incorporating Non-local Information into Named Entity Recognition
Mar 06, 2023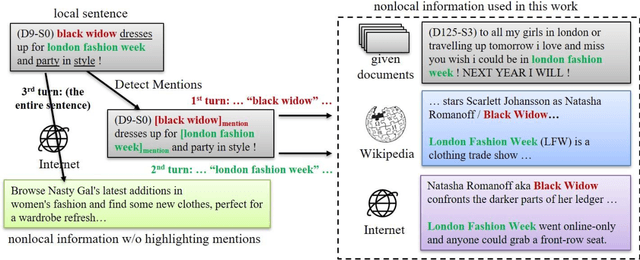
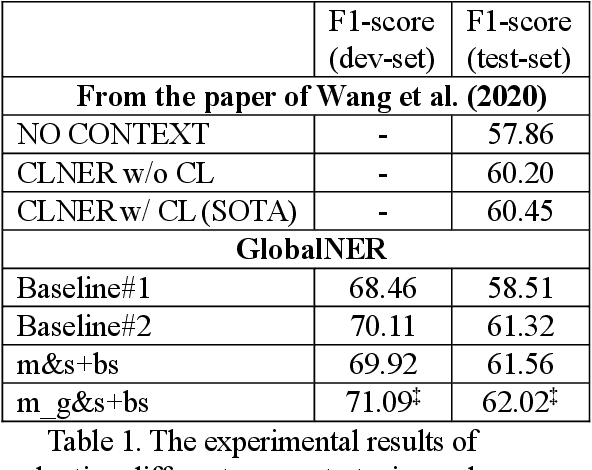
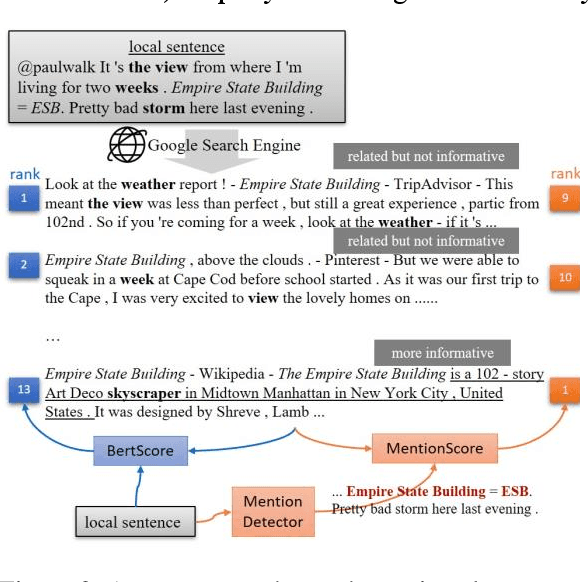
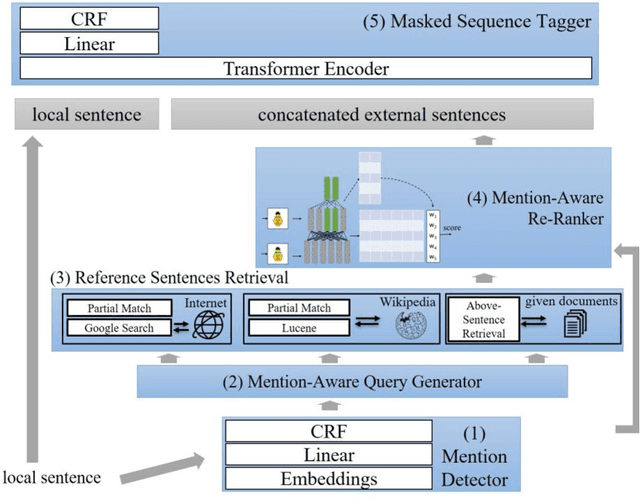
Nowadays, many Natural Language Processing (NLP) tasks see the demand for incorporating knowledge external to the local information to further improve the performance. However, there is little related work on Named Entity Recognition (NER), which is one of the foundations of NLP. Specifically, no studies were conducted on the query generation and re-ranking for retrieving the related information for the purpose of improving NER. This work demonstrates the effectiveness of a DNN-based query generation method and a mention-aware re-ranking architecture based on BERTScore particularly for NER. In the end, a state-of-the-art performance of 61.56 micro-f1 score on WNUT17 dataset is achieved.
ChatGPT as the Transportation Equity Information Source for Scientific Writing
Mar 10, 2023

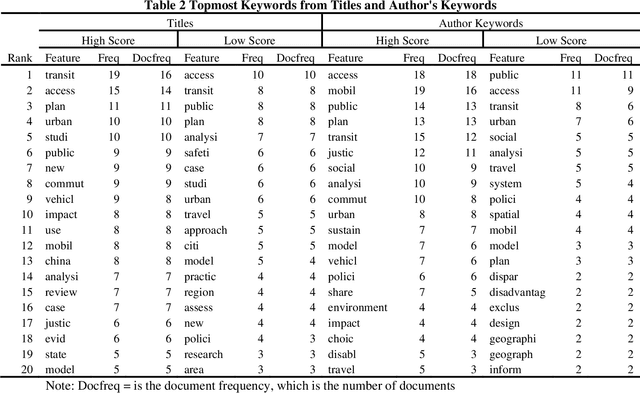
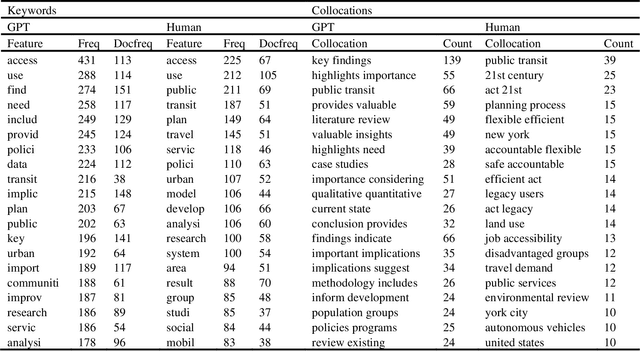
Transportation equity is an interdisciplinary agenda that requires both transportation and social inputs. Traditionally, transportation equity information are sources from public libraries, conferences, televisions, social media, among other. Artificial intelligence (AI) tools including advanced language models such as ChatGPT are becoming favorite information sources. However, their credibility has not been well explored. This study explored the content and usefulness of ChatGPT-generated information related to transportation equity. It utilized 152 papers retrieved through the Web of Science (WoS) repository. The prompt was crafted for ChatGPT to provide an abstract given the title of the paper. The ChatGPT-based abstracts were then compared to human-written abstracts using statistical tools and unsupervised text mining. The results indicate that a weak similarity between ChatGPT and human-written abstracts. On average, the human-written abstracts and ChatGPT generated abstracts were about 58% similar, with a maximum and minimum of 97% and 1.4%, respectively. The keywords from the abstracts of papers with over the mean similarity score were more likely to be similar whereas those from below the average score were less likely to be similar. Themes with high similarity scores include access, public transit, and policy, among others. Further, clear differences in the key pattern of clusters for high and low similarity score abstracts was observed. Contrarily, the findings from collocated keywords were inconclusive. The study findings suggest that ChatGPT has the potential to be a source of transportation equity information. However, currently, a great amount of attention is needed before a user can utilize materials from ChatGPT
To Fold or Not to Fold: Graph Regularized Tensor Train for Visual Data Completion
Jun 19, 2023
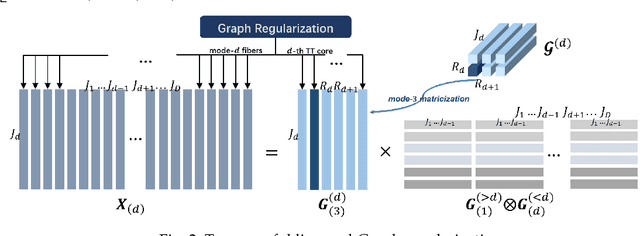
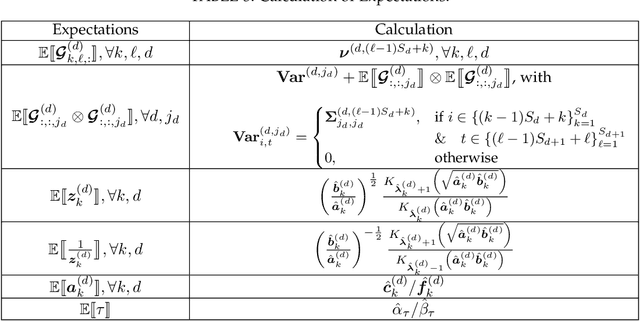
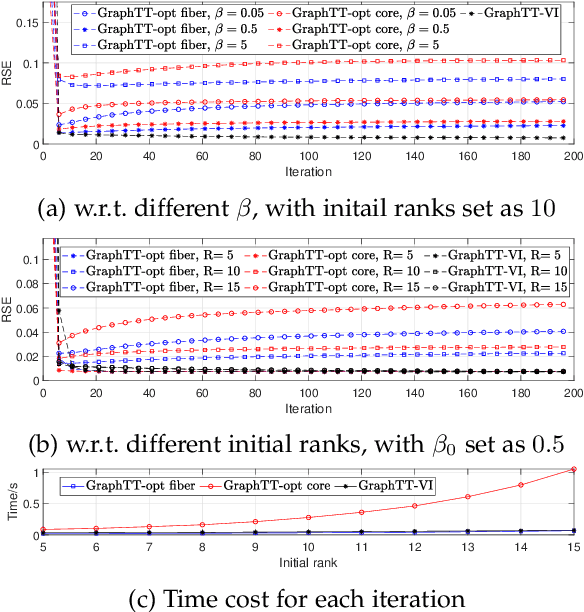
Tensor train (TT) representation has achieved tremendous success in visual data completion tasks, especially when it is combined with tensor folding. However, folding an image or video tensor breaks the original data structure, leading to local information loss as nearby pixels may be assigned into different dimensions and become far away from each other. In this paper, to fully preserve the local information of the original visual data, we explore not folding the data tensor, and at the same time adopt graph information to regularize local similarity between nearby entries. To overcome the high computational complexity introduced by the graph-based regularization in the TT completion problem, we propose to break the original problem into multiple sub-problems with respect to each TT core fiber, instead of each TT core as in traditional methods. Furthermore, to avoid heavy parameter tuning, a sparsity promoting probabilistic model is built based on the generalized inverse Gaussian (GIG) prior, and an inference algorithm is derived under the mean-field approximation. Experiments on both synthetic data and real-world visual data show the superiority of the proposed methods.
Masked Contrastive Graph Representation Learning for Age Estimation
Jun 16, 2023
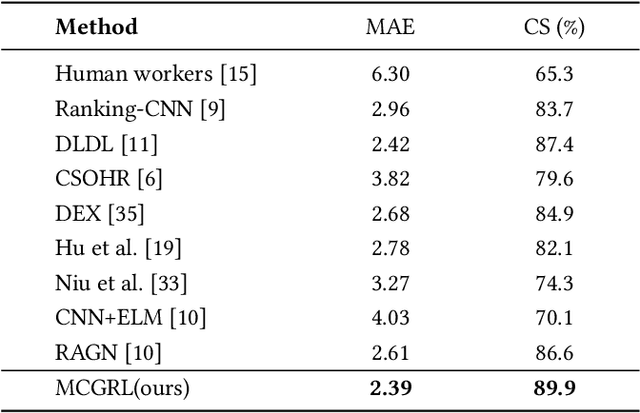

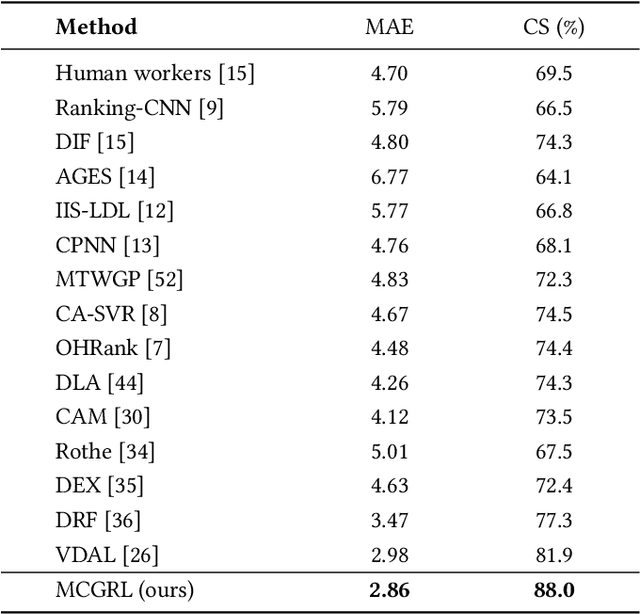
Age estimation of face images is a crucial task with various practical applications in areas such as video surveillance and Internet access control. While deep learning-based age estimation frameworks, e.g., convolutional neural network (CNN), multi-layer perceptrons (MLP), and transformers have shown remarkable performance, they have limitations when modelling complex or irregular objects in an image that contains a large amount of redundant information. To address this issue, this paper utilizes the robustness property of graph representation learning in dealing with image redundancy information and proposes a novel Masked Contrastive Graph Representation Learning (MCGRL) method for age estimation. Specifically, our approach first leverages CNN to extract semantic features of the image, which are then partitioned into patches that serve as nodes in the graph. Then, we use a masked graph convolutional network (GCN) to derive image-based node representations that capture rich structural information. Finally, we incorporate multiple losses to explore the complementary relationship between structural information and semantic features, which improves the feature representation capability of GCN. Experimental results on real-world face image datasets demonstrate the superiority of our proposed method over other state-of-the-art age estimation approaches.
Text + Sketch: Image Compression at Ultra Low Rates
Jul 04, 2023
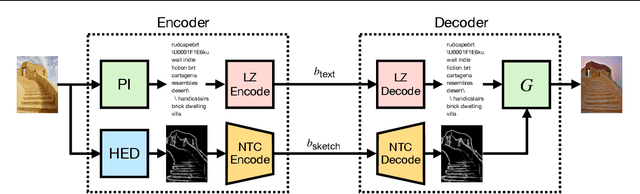
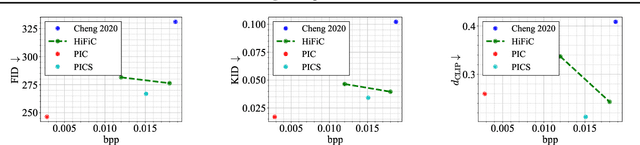
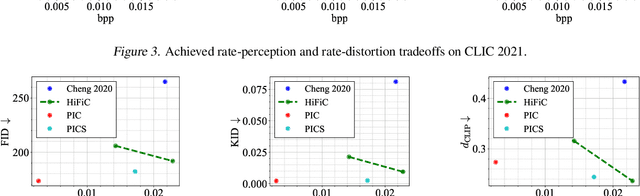
Recent advances in text-to-image generative models provide the ability to generate high-quality images from short text descriptions. These foundation models, when pre-trained on billion-scale datasets, are effective for various downstream tasks with little or no further training. A natural question to ask is how such models may be adapted for image compression. We investigate several techniques in which the pre-trained models can be directly used to implement compression schemes targeting novel low rate regimes. We show how text descriptions can be used in conjunction with side information to generate high-fidelity reconstructions that preserve both semantics and spatial structure of the original. We demonstrate that at very low bit-rates, our method can significantly improve upon learned compressors in terms of perceptual and semantic fidelity, despite no end-to-end training.
On the hierarchical Bayesian modelling of frequency response functions
Jul 12, 2023Population-based structural health monitoring (PBSHM) aims to share valuable information among members of a population, such as normal- and damage-condition data, to improve inferences regarding the health states of the members. Even when the population is comprised of nominally-identical structures, benign variations among the members will exist as a result of slight differences in material properties, geometry, boundary conditions, or environmental effects (e.g., temperature changes). These discrepancies can affect modal properties and present as changes in the characteristics of the resonance peaks of the frequency response function (FRF). Many SHM strategies depend on monitoring the dynamic properties of structures, so benign variations can be challenging for the practical implementation of these systems. Another common challenge with vibration-based SHM is data loss, which may result from transmission issues, sensor failure, a sample-rate mismatch between sensors, and other causes. Missing data in the time domain will result in decreased resolution in the frequency domain, which can impair dynamic characterisation. The hierarchical Bayesian approach provides a useful modelling structure for PBSHM, because statistical distributions at the population and individual (or domain) level are learnt simultaneously to bolster statistical strength among the parameters. As a result, variance is reduced among the parameter estimates, particularly when data are limited. In this paper, combined probabilistic FRF models are developed for a small population of nominally-identical helicopter blades under varying temperature conditions, using a hierarchical Bayesian structure. These models address critical challenges in SHM, by accommodating benign variations that present as differences in the underlying dynamics, while also considering (and utilising), the similarities among the blades.
GPatcher: A Simple and Adaptive MLP Model for Alleviating Graph Heterophily
Jun 25, 2023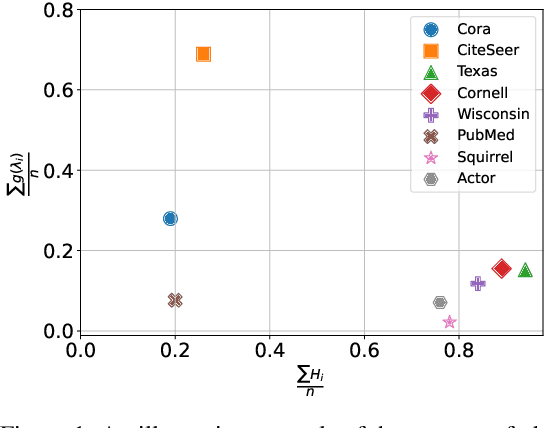
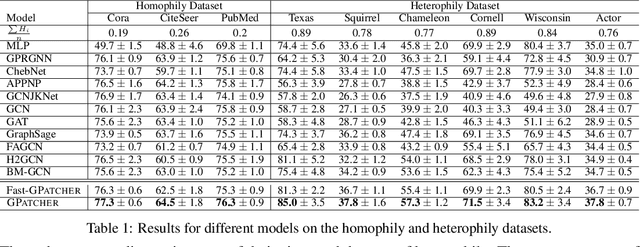
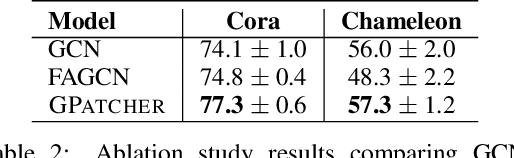
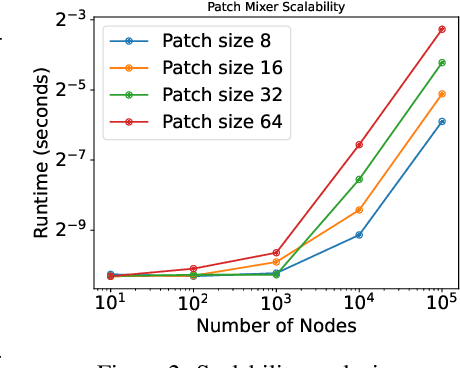
While graph heterophily has been extensively studied in recent years, a fundamental research question largely remains nascent: How and to what extent will graph heterophily affect the prediction performance of graph neural networks (GNNs)? In this paper, we aim to demystify the impact of graph heterophily on GNN spectral filters. Our theoretical results show that it is essential to design adaptive polynomial filters that adapts different degrees of graph heterophily to guarantee the generalization performance of GNNs. Inspired by our theoretical findings, we propose a simple yet powerful GNN named GPatcher by leveraging the MLP-Mixer architectures. Our approach comprises two main components: (1) an adaptive patch extractor function that automatically transforms each node's non-Euclidean graph representations to Euclidean patch representations given different degrees of heterophily, and (2) an efficient patch mixer function that learns salient node representation from both the local context information and the global positional information. Through extensive experiments, the GPatcher model demonstrates outstanding performance on node classification compared with popular homophily GNNs and state-of-the-art heterophily GNNs.