 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ComPtr: Towards Diverse Bi-source Dense Prediction Tasks via A Simple yet General Complementary Transformer
Jul 23, 2023
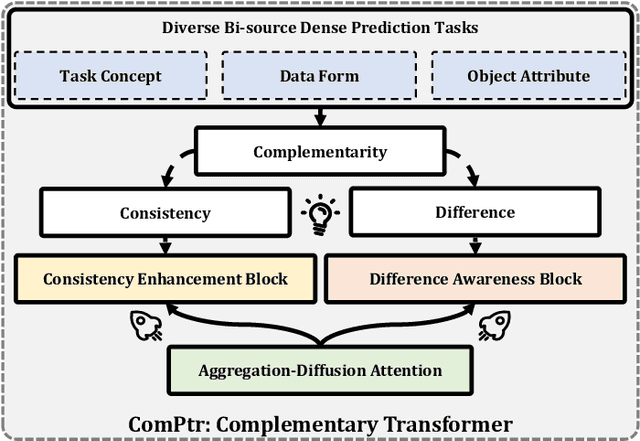
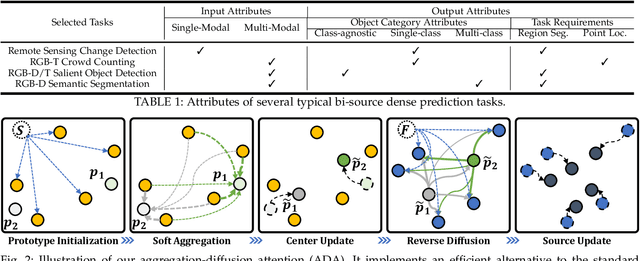
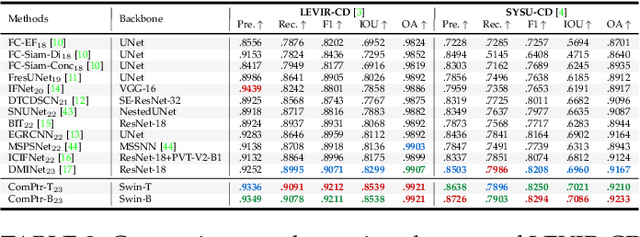
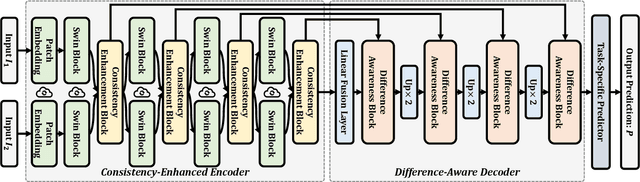
Deep learning (DL) has advanced the field of dense prediction, while gradually dissolving the inherent barriers between different tasks. However, most existing works focus on designing architectures and constructing visual cues only for the specific task, which ignores the potential uniformity introduced by the DL paradigm. In this paper, we attempt to construct a novel \underline{ComP}lementary \underline{tr}ansformer, \textbf{ComPtr}, for diverse bi-source dense prediction tasks. Specifically, unlike existing methods that over-specialize in a single task or a subset of tasks, ComPtr starts from the more general concept of bi-source dense prediction. Based on the basic dependence on information complementarity, we propose consistency enhancement and difference awareness components with which ComPtr can evacuate and collect important visual semantic cues from different image sources for diverse tasks, respectively. ComPtr treats different inputs equally and builds an efficient dense interaction model in the form of sequence-to-sequence on top of the transformer. This task-generic design provides a smooth foundation for constructing the unified model that can simultaneously deal with various bi-source information. In extensive experiments across several representative vision tasks, i.e. remote sensing change detection, RGB-T crowd counting, RGB-D/T salient object detection, and RGB-D semantic segmentation, the proposed method consistently obtains favorable performance. The code will be available at \url{https://github.com/lartpang/ComPtr}.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 03, 2023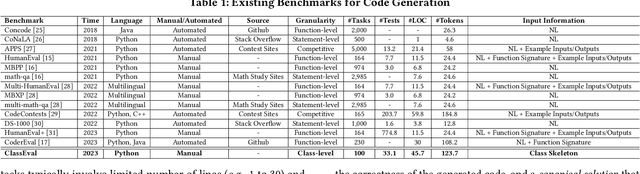


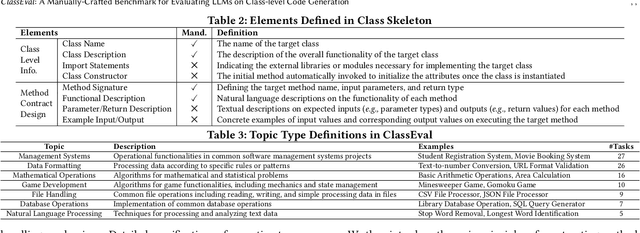
In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
ADRNet: A Generalized Collaborative Filtering Framework Combining Clinical and Non-Clinical Data for Adverse Drug Reaction Prediction
Aug 03, 2023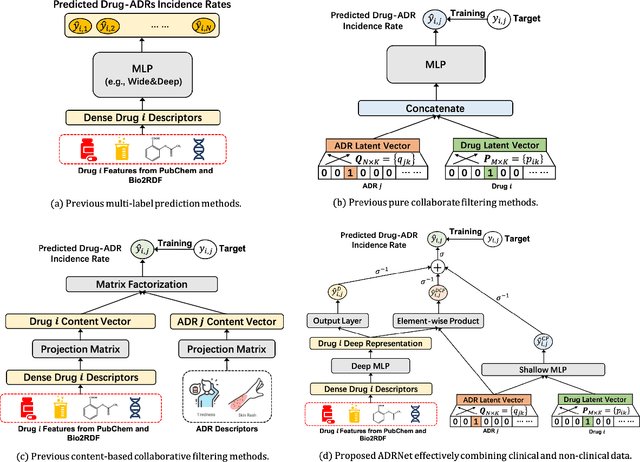
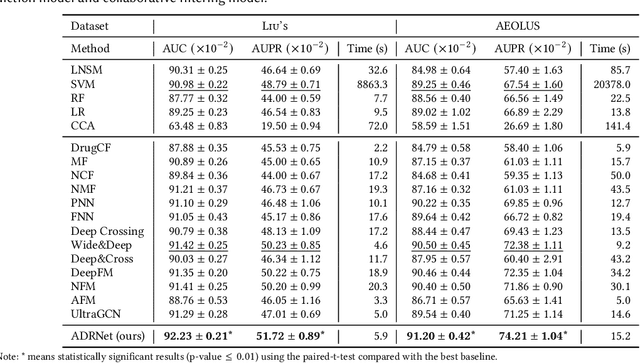
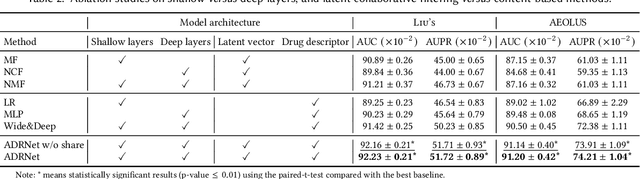

Adverse drug reaction (ADR) prediction plays a crucial role in both health care and drug discovery for reducing patient mortality and enhancing drug safety. Recently, many studies have been devoted to effectively predict the drug-ADRs incidence rates. However, these methods either did not effectively utilize non-clinical data, i.e., physical, chemical, and biological information about the drug, or did little to establish a link between content-based and pure collaborative filtering during the training phase. In this paper, we first formulate the prediction of multi-label ADRs as a drug-ADR collaborative filtering problem, and to the best of our knowledge, this is the first work to provide extensive benchmark results of previous collaborative filtering methods on two large publicly available clinical datasets. Then, by exploiting the easy accessible drug characteristics from non-clinical data, we propose ADRNet, a generalized collaborative filtering framework combining clinical and non-clinical data for drug-ADR prediction. Specifically, ADRNet has a shallow collaborative filtering module and a deep drug representation module, which can exploit the high-dimensional drug descriptors to further guide the learning of low-dimensional ADR latent embeddings, which incorporates both the benefits of collaborative filtering and representation learning. Extensive experiments are conducted on two publicly available real-world drug-ADR clinical datasets and two non-clinical datasets to demonstrate the accuracy and efficiency of the proposed ADRNet. The code is available at https://github.com/haoxuanli-pku/ADRnet.
LA-Net: Landmark-Aware Learning for Reliable Facial Expression Recognition under Label Noise
Jul 19, 2023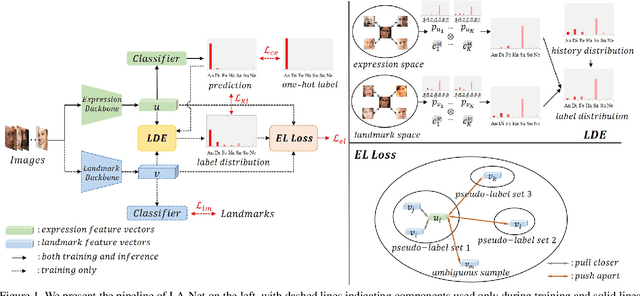
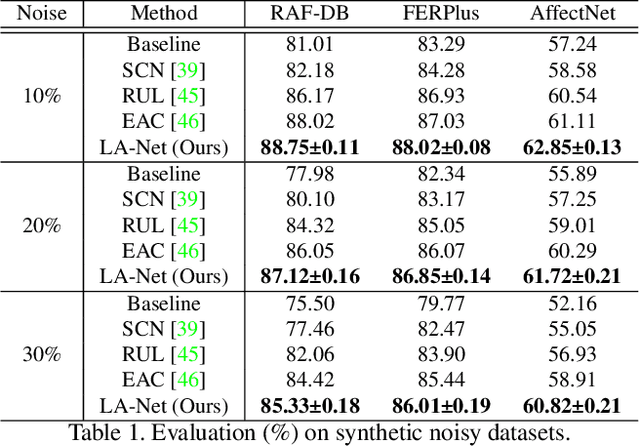
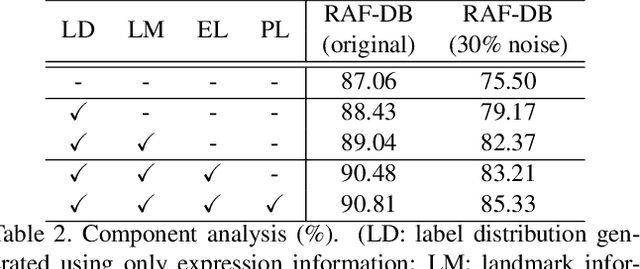
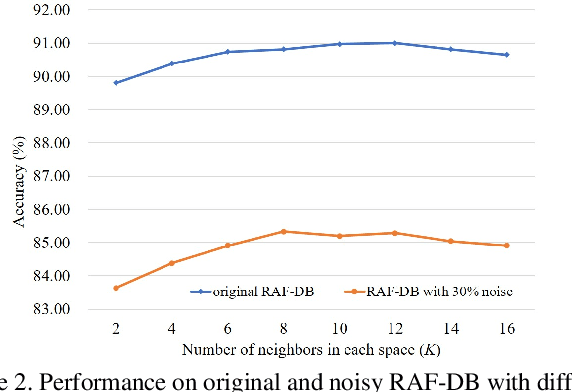
Facial expression recognition (FER) remains a challenging task due to the ambiguity of expressions. The derived noisy labels significantly harm the performance in real-world scenarios. To address this issue, we present a new FER model named Landmark-Aware Net~(LA-Net), which leverages facial landmarks to mitigate the impact of label noise from two perspectives. Firstly, LA-Net uses landmark information to suppress the uncertainty in expression space and constructs the label distribution of each sample by neighborhood aggregation, which in turn improves the quality of training supervision. Secondly, the model incorporates landmark information into expression representations using the devised expression-landmark contrastive loss. The enhanced expression feature extractor can be less susceptible to label noise. Our method can be integrated with any deep neural network for better training supervision without introducing extra inference costs. We conduct extensive experiments on both in-the-wild datasets and synthetic noisy datasets and demonstrate that LA-Net achieves state-of-the-art performance.
Learning from Abstract Images: on the Importance of Occlusion in a Minimalist Encoding of Human Poses
Jul 19, 2023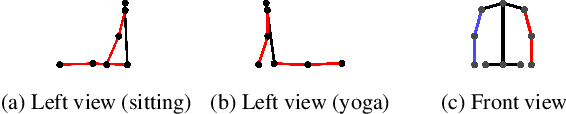
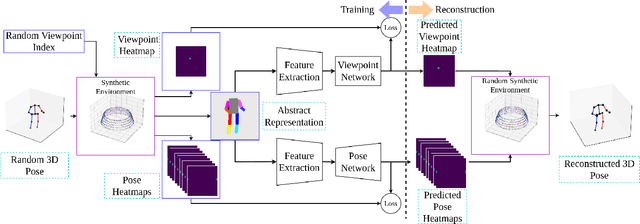
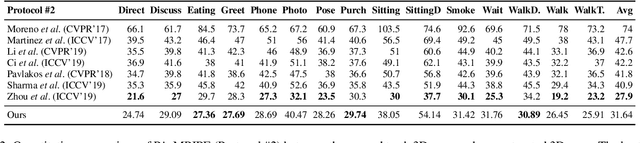
Existing 2D-to-3D pose lifting networks suffer from poor performance in cross-dataset benchmarks. Although the use of 2D keypoints joined by "stick-figure" limbs has shown promise as an intermediate step, stick-figures do not account for occlusion information that is often inherent in an image. In this paper, we propose a novel representation using opaque 3D limbs that preserves occlusion information while implicitly encoding joint locations. Crucially, when training on data with accurate three-dimensional keypoints and without part-maps, this representation allows training on abstract synthetic images, with occlusion, from as many synthetic viewpoints as desired. The result is a pose defined by limb angles rather than joint positions $\unicode{x2013}$ because poses are, in the real world, independent of cameras $\unicode{x2013}$ allowing us to predict poses that are completely independent of camera viewpoint. The result provides not only an improvement in same-dataset benchmarks, but a "quantum leap" in cross-dataset benchmarks.
IncDSI: Incrementally Updatable Document Retrieval
Jul 19, 2023

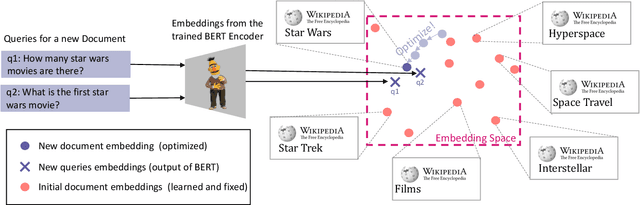
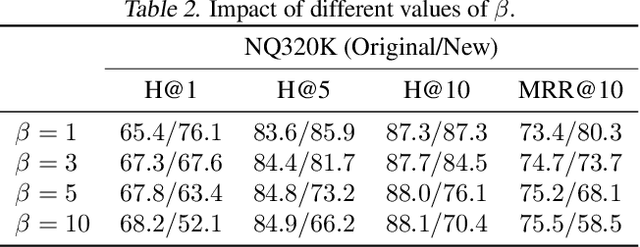
Differentiable Search Index is a recently proposed paradigm for document retrieval, that encodes information about a corpus of documents within the parameters of a neural network and directly maps queries to corresponding documents. These models have achieved state-of-the-art performances for document retrieval across many benchmarks. These kinds of models have a significant limitation: it is not easy to add new documents after a model is trained. We propose IncDSI, a method to add documents in real time (about 20-50ms per document), without retraining the model on the entire dataset (or even parts thereof). Instead we formulate the addition of documents as a constrained optimization problem that makes minimal changes to the network parameters. Although orders of magnitude faster, our approach is competitive with re-training the model on the whole dataset and enables the development of document retrieval systems that can be updated with new information in real-time. Our code for IncDSI is available at https://github.com/varshakishore/IncDSI.
MapFormer: Boosting Change Detection by Using Pre-change Information
Mar 31, 2023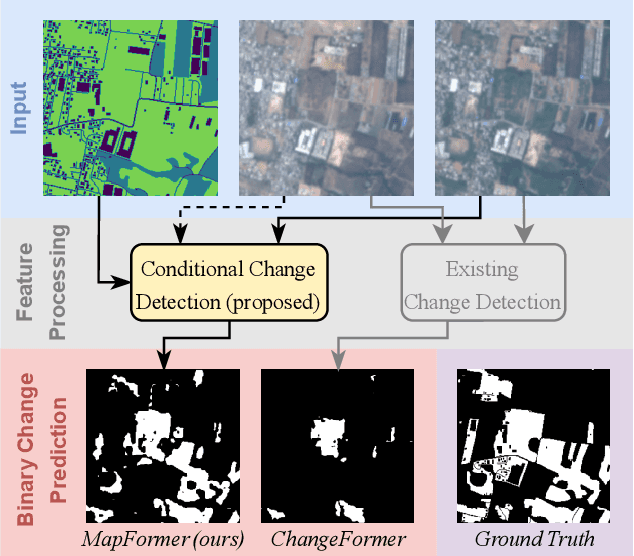
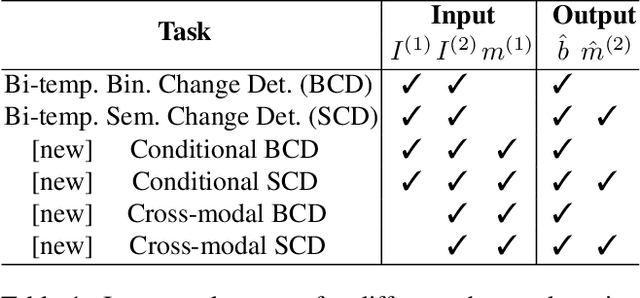
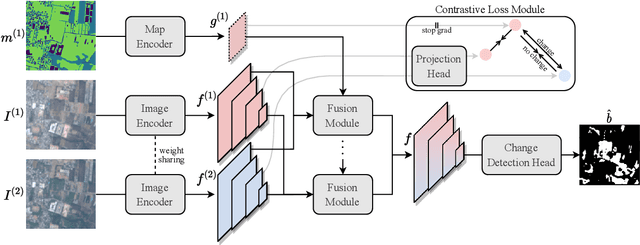
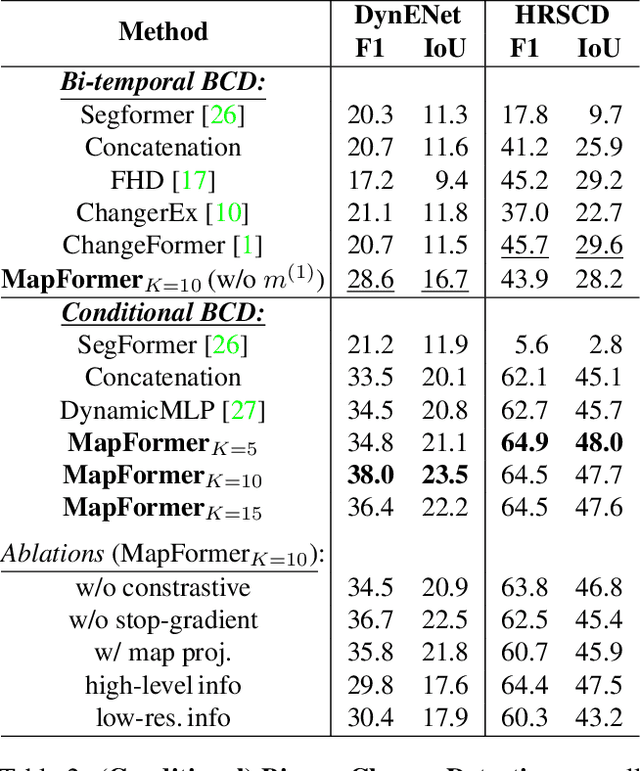
Change detection in remote sensing imagery is essential for a variety of applications such as urban planning, disaster management, and climate research. However, existing methods for identifying semantically changed areas overlook the availability of semantic information in the form of existing maps describing features of the earth's surface. In this paper, we leverage this information for change detection in bi-temporal images. We show that the simple integration of the additional information via concatenation of latent representations suffices to significantly outperform state-of-the-art change detection methods. Motivated by this observation, we propose the new task of Conditional Change Detection, where pre-change semantic information is used as input next to bi-temporal images. To fully exploit the extra information, we propose MapFormer, a novel architecture based on a multi-modal feature fusion module that allows for feature processing conditioned on the available semantic information. We further employ a supervised, cross-modal contrastive loss to guide the learning of visual representations. Our approach outperforms existing change detection methods by an absolute 11.7% and 18.4% in terms of binary change IoU on DynamicEarthNet and HRSCD, respectively. Furthermore, we demonstrate the robustness of our approach to the quality of the pre-change semantic information and the absence pre-change imagery. The code will be made publicly available.
Multimodal Document Analytics for Banking Process Automation
Jul 21, 2023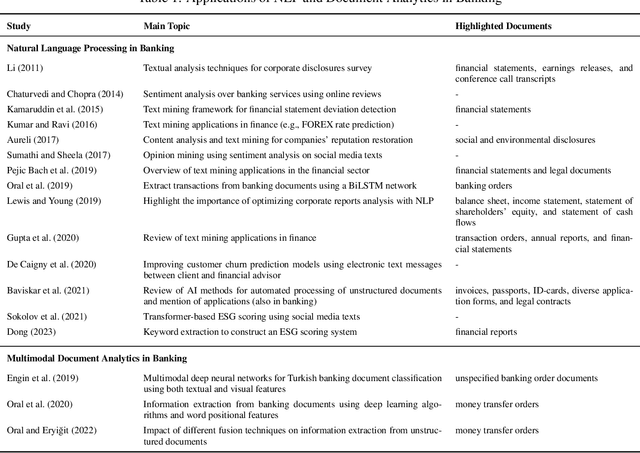
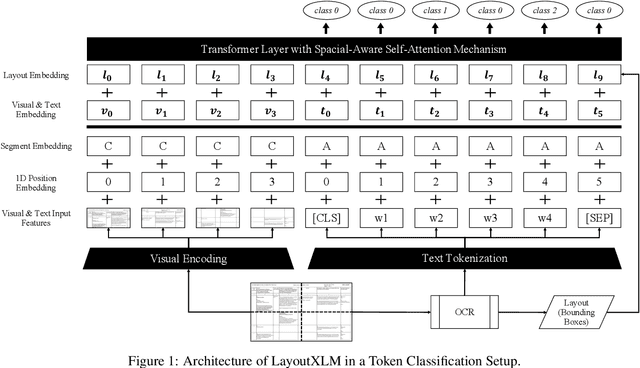
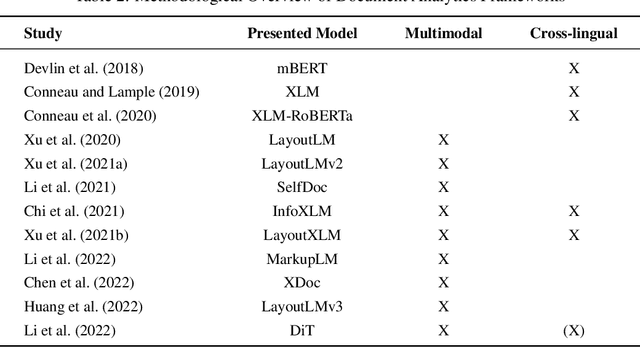
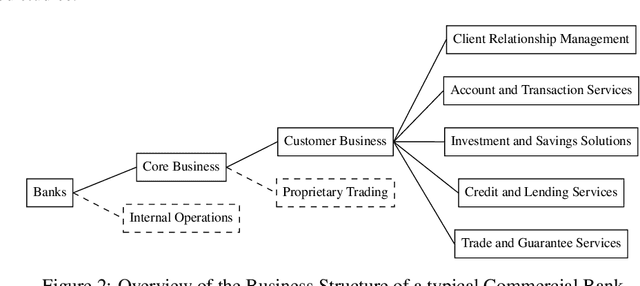
In response to growing FinTech competition and the need for improved operational efficiency, this research focuses on understanding the potential of advanced document analytics, particularly using multimodal models, in banking processes. We perform a comprehensive analysis of the diverse banking document landscape, highlighting the opportunities for efficiency gains through automation and advanced analytics techniques in the customer business. Building on the rapidly evolving field of natural language processing (NLP), we illustrate the potential of models such as LayoutXLM, a cross-lingual, multimodal, pre-trained model, for analyzing diverse documents in the banking sector. This model performs a text token classification on German company register extracts with an overall F1 score performance of around 80\%. Our empirical evidence confirms the critical role of layout information in improving model performance and further underscores the benefits of integrating image information. Interestingly, our study shows that over 75% F1 score can be achieved with only 30% of the training data, demonstrating the efficiency of LayoutXLM. Through addressing state-of-the-art document analysis frameworks, our study aims to enhance process efficiency and demonstrate the real-world applicability and benefits of multimodal models within banking.
Testing the Depth of ChatGPT's Comprehension via Cross-Modal Tasks Based on ASCII-Art: GPT3.5's Abilities in Regard to Recognizing and Generating ASCII-Art Are Not Totally Lacking
Jul 28, 2023Over the eight months since its release, ChatGPT and its underlying model, GPT3.5, have garnered massive attention, due to their potent mix of capability and accessibility. While a niche-industry of papers have emerged examining the scope of capabilities these models possess, the information fed to and extracted from these networks has been either natural language text or stylized, code-like language. Drawing inspiration from the prowess we expect a truly human-level intelligent agent to have across multiple signal modalities, in this work we examine GPT3.5's aptitude for visual tasks, where the inputs feature content provided as ASCII-art without overt distillation into a lingual summary. We conduct experiments analyzing the model's performance on image recognition tasks after various transforms typical in visual settings, trials investigating knowledge of image parts, and tasks covering image generation.
When to generate hedges in peer-tutoring interactions
Jul 28, 2023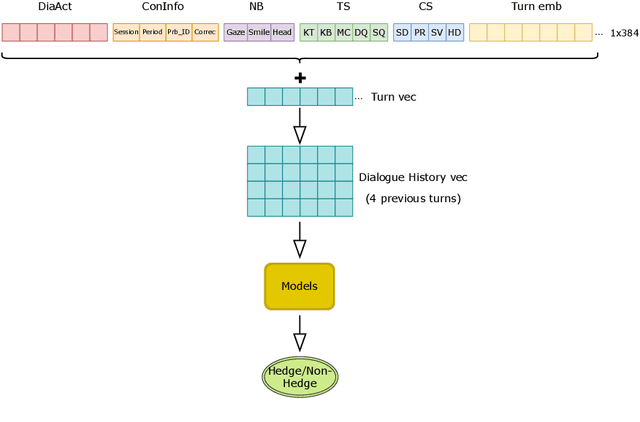
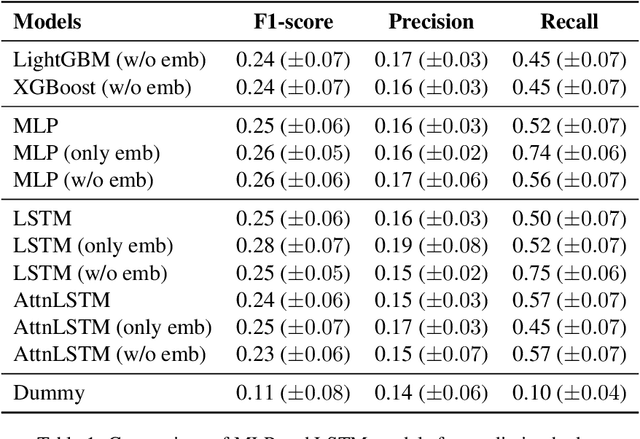
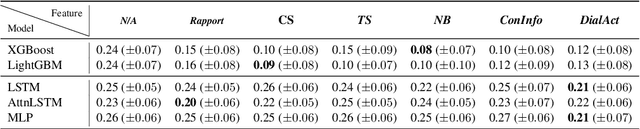
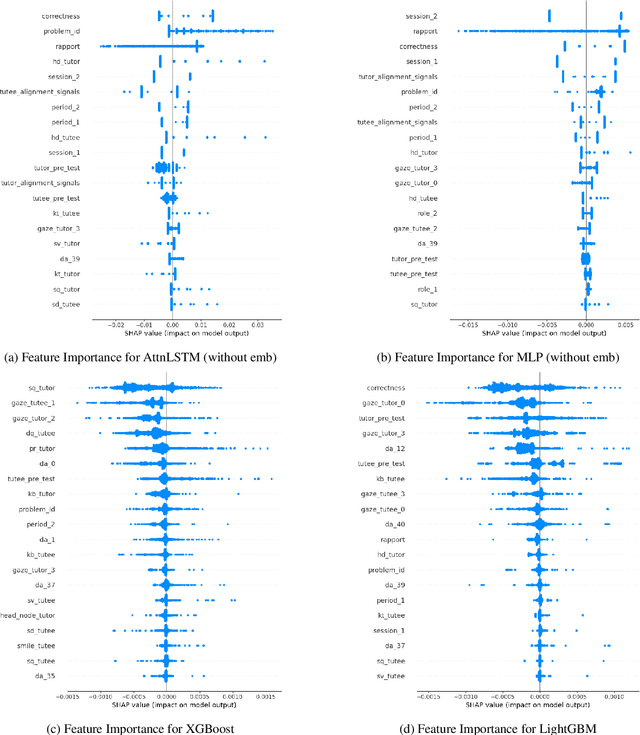
This paper explores the application of machine learning techniques to predict where hedging occurs in peer-tutoring interactions. The study uses a naturalistic face-to-face dataset annotated for natural language turns, conversational strategies, tutoring strategies, and nonverbal behaviours. These elements are processed into a vector representation of the previous turns, which serves as input to several machine learning models. Results show that embedding layers, that capture the semantic information of the previous turns, significantly improves the model's performance. Additionally, the study provides insights into the importance of various features, such as interpersonal rapport and nonverbal behaviours, in predicting hedges by using Shapley values for feature explanation. We discover that the eye gaze of both the tutor and the tutee has a significant impact on hedge prediction. We further validate this observation through a follow-up ablation study.
* In Proceedings of the 16th Annual Conference ub Discourse and Dialogue (SIGDIAL). Sept 11-15, Prague Czechia