 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Disturbance Preview for Nonlinear Model Predictive Trajectory Tracking of Underwater Vehicles in Wave Dominated Environments
Jul 27, 2023
Operating in the near-vicinity of marine energy devices poses significant challenges to the control of underwater vehicles, predominantly due to the presence of large magnitude wave disturbances causing hazardous state perturbations. Approaches to tackle this problem have varied, but one promising solution is to adopt predictive control methods. Given the predictable nature of ocean waves, the potential exists to incorporate disturbance estimations directly within the plant model; this requires inclusion of a wave predictor to provide online preview information. To this end, this paper presents a Nonlinear Model Predictive Controller with an integrated Deterministic Sea Wave Predictor for trajectory tracking of underwater vehicles. State information is obtained through an Extended Kalman Filter, forming a complete closed-loop strategy and facilitating online wave load estimations. The strategy is compared to a similar feed-forward disturbance mitigation scheme, showing mean performance improvements of 51% in positional error and 44.5% in attitude error. The preliminary results presented here provide strong evidence of the proposed method's high potential to effectively mitigate disturbances, facilitating accurate tracking performance even in the presence of high wave loading.
Audio-Enhanced Text-to-Video Retrieval using Text-Conditioned Feature Alignment
Jul 24, 2023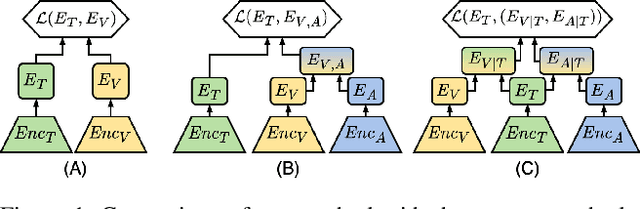
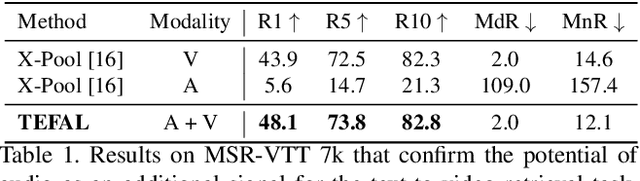

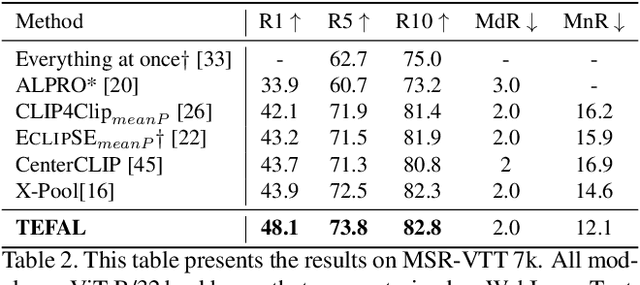
Text-to-video retrieval systems have recently made significant progress by utilizing pre-trained models trained on large-scale image-text pairs. However, most of the latest methods primarily focus on the video modality while disregarding the audio signal for this task. Nevertheless, a recent advancement by ECLIPSE has improved long-range text-to-video retrieval by developing an audiovisual video representation. Nonetheless, the objective of the text-to-video retrieval task is to capture the complementary audio and video information that is pertinent to the text query rather than simply achieving better audio and video alignment. To address this issue, we introduce TEFAL, a TExt-conditioned Feature ALignment method that produces both audio and video representations conditioned on the text query. Instead of using only an audiovisual attention block, which could suppress the audio information relevant to the text query, our approach employs two independent cross-modal attention blocks that enable the text to attend to the audio and video representations separately. Our proposed method's efficacy is demonstrated on four benchmark datasets that include audio: MSR-VTT, LSMDC, VATEX, and Charades, and achieves better than state-of-the-art performance consistently across the four datasets. This is attributed to the additional text-query-conditioned audio representation and the complementary information it adds to the text-query-conditioned video representation.
HVDetFusion: A Simple and Robust Camera-Radar Fusion Framework
Jul 21, 2023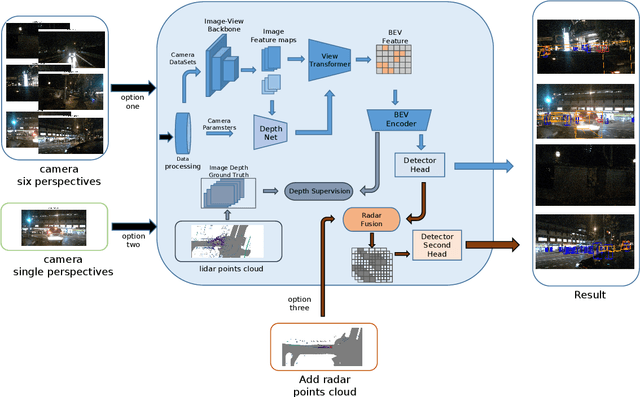
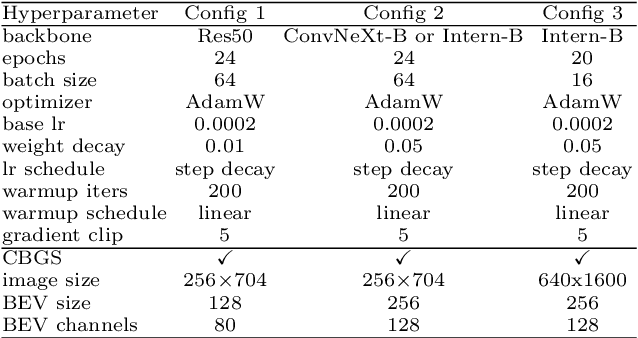
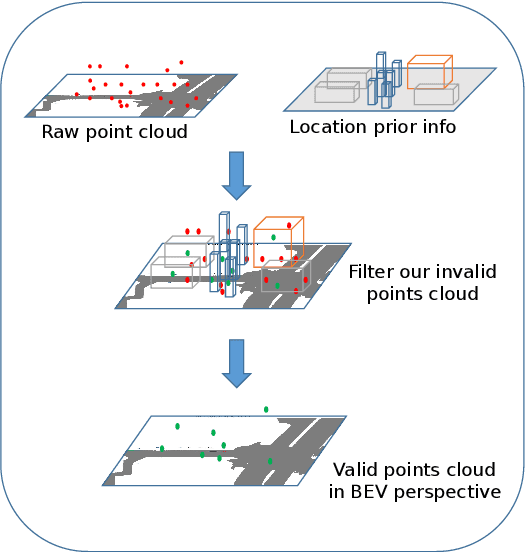
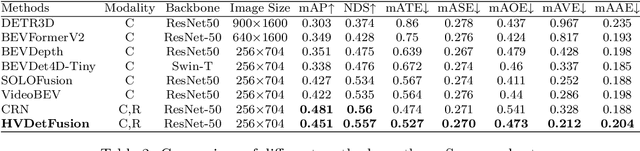
In the field of autonomous driving, 3D object detection is a very important perception module. Although the current SOTA algorithm combines Camera and Lidar sensors, limited by the high price of Lidar, the current mainstream landing schemes are pure Camera sensors or Camera+Radar sensors. In this study, we propose a new detection algorithm called HVDetFusion, which is a multi-modal detection algorithm that not only supports pure camera data as input for detection, but also can perform fusion input of radar data and camera data. The camera stream does not depend on the input of Radar data, thus addressing the downside of previous methods. In the pure camera stream, we modify the framework of Bevdet4D for better perception and more efficient inference, and this stream has the whole 3D detection output. Further, to incorporate the benefits of Radar signals, we use the prior information of different object positions to filter the false positive information of the original radar data, according to the positioning information and radial velocity information recorded by the radar sensors to supplement and fuse the BEV features generated by the original camera data, and the effect is further improved in the process of fusion training. Finally, HVDetFusion achieves the new state-of-the-art 67.4\% NDS on the challenging nuScenes test set among all camera-radar 3D object detectors. The code is available at https://github.com/HVXLab/HVDetFusion
Multimodal Pretrained Models for Sequential Decision-Making: Synthesis, Verification, Grounding, and Perception
Aug 10, 2023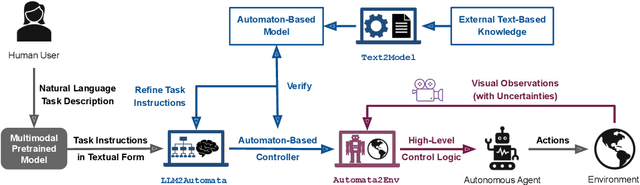
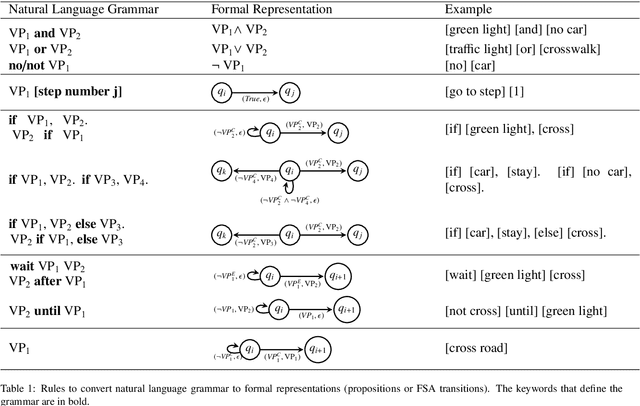
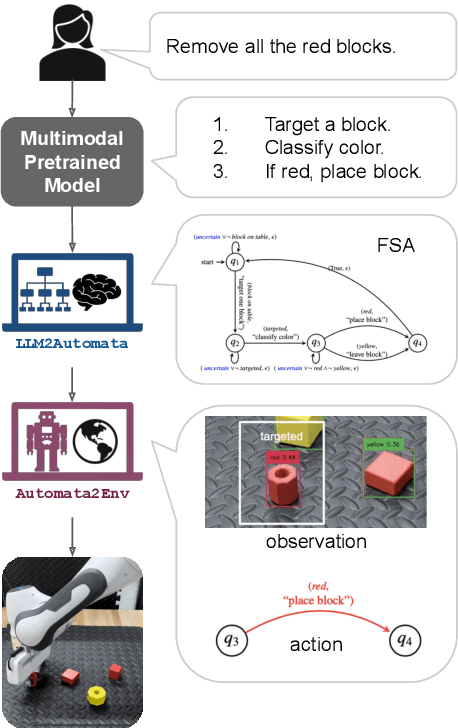
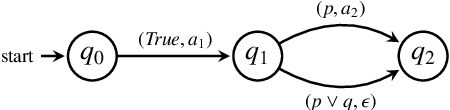
Recently developed pretrained models can encode rich world knowledge expressed in multiple modalities, such as text and images. However, the outputs of these models cannot be integrated into algorithms to solve sequential decision-making tasks. We develop an algorithm that utilizes the knowledge from pretrained models to construct and verify controllers for sequential decision-making tasks, and to ground these controllers to task environments through visual observations. In particular, the algorithm queries a pretrained model with a user-provided, text-based task description and uses the model's output to construct an automaton-based controller that encodes the model's task-relevant knowledge. It then verifies whether the knowledge encoded in the controller is consistent with other independently available knowledge, which may include abstract information on the environment or user-provided specifications. If this verification step discovers any inconsistency, the algorithm automatically refines the controller to resolve the inconsistency. Next, the algorithm leverages the vision and language capabilities of pretrained models to ground the controller to the task environment. It collects image-based observations from the task environment and uses the pretrained model to link these observations to the text-based control logic encoded in the controller (e.g., actions and conditions that trigger the actions). We propose a mechanism to ensure the controller satisfies the user-provided specification even when perceptual uncertainties are present. We demonstrate the algorithm's ability to construct, verify, and ground automaton-based controllers through a suite of real-world tasks, including daily life and robot manipulation tasks.
Physical Layer Security for NOMA Systems: Requirements, Issues, and Recommendations
Aug 10, 2023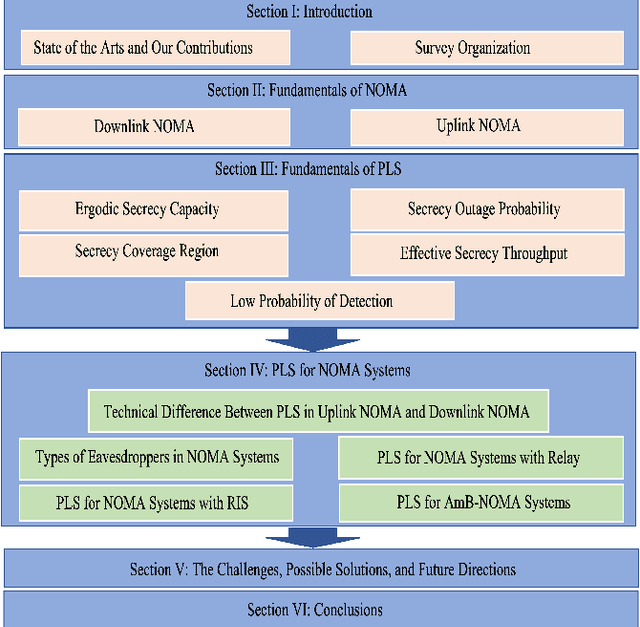
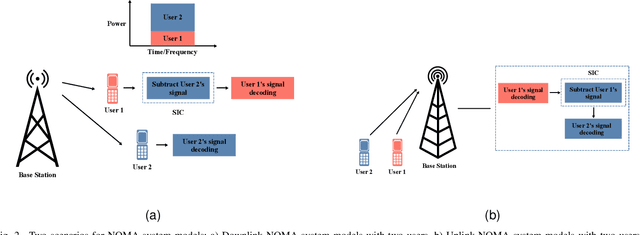
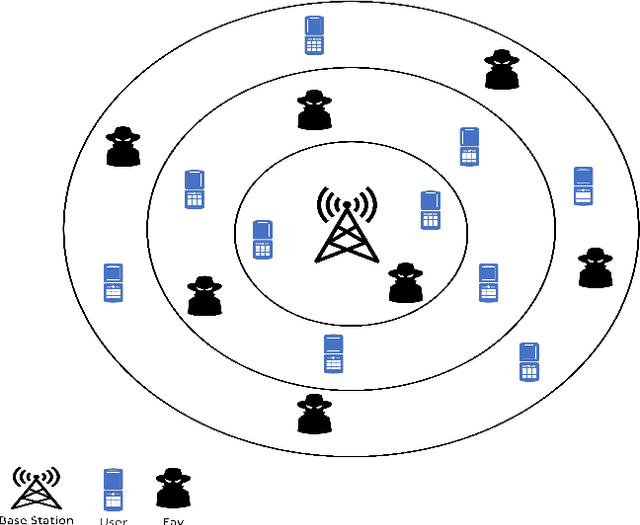
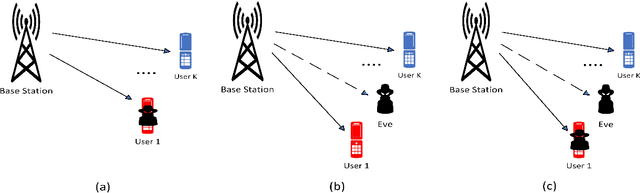
Non-orthogonal multiple access (NOMA) has been viewed as a potential candidate for the upcoming generation of wireless communication systems. Comparing to traditional orthogonal multiple access (OMA), multiplexing users in the same time-frequency resource block can increase the number of served users and improve the efficiency of the systems in terms of spectral efficiency. Nevertheless, from a security view-point, when multiple users are utilizing the same time-frequency resource, there may be concerns regarding keeping information confidential. In this context, physical layer security (PLS) has been introduced as a supplement of protection to conventional encryption techniques by making use of the random nature of wireless transmission media for ensuring communication secrecy. The recent years have seen significant interests in PLS being applied to NOMA networks. Numerous scenarios have been investigated to assess the security of NOMA systems, including when active and passive eavesdroppers are present, as well as when these systems are combined with relay and reconfigurable intelligent surfaces (RIS). Additionally, the security of the ambient backscatter (AmB)-NOMA systems are other issues that have lately drawn a lot of attention. In this paper, a thorough analysis of the PLS-assisted NOMA systems research state-of-the-art is presented. In this regard, we begin by outlining the foundations of NOMA and PLS, respectively. Following that, we discuss the PLS performances for NOMA systems in four categories depending on the type of the eavesdropper, the existence of relay, RIS, and AmB systems in different conditions. Finally, a thorough explanation of the most recent PLS-assisted NOMA systems is given.
* 17 pages, 4 figures
INTapt: Information-Theoretic Adversarial Prompt Tuning for Enhanced Non-Native Speech Recognition
May 25, 2023
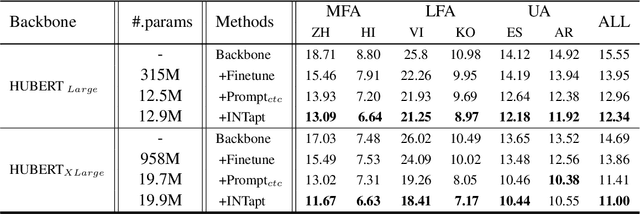
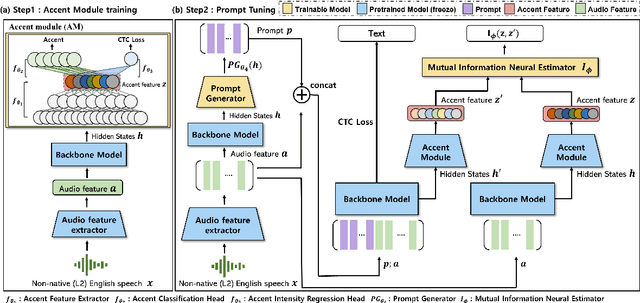
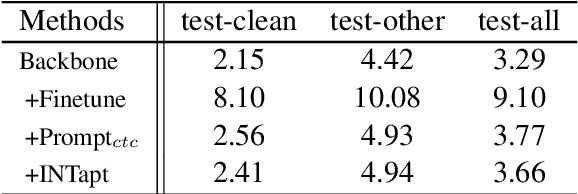
Automatic Speech Recognition (ASR) systems have attained unprecedented performance with large speech models pre-trained based on self-supervised speech representation learning. However, these pre-trained speech models suffer from representational bias as they tend to better represent those prominent accents (i.e., native (L1) English accent) in the pre-training speech corpus than less represented accents, resulting in a deteriorated performance for non-native (L2) English accents. Although there have been some approaches to mitigate this issue, all of these methods require updating the pre-trained model weights. In this paper, we propose Information Theoretic Adversarial Prompt Tuning (INTapt), which introduces prompts concatenated to the original input that can re-modulate the attention of the pre-trained model such that the corresponding input resembles a native (L1) English speech without updating the backbone weights. INTapt is trained simultaneously in the following two manners: (1) adversarial training to reduce accent feature dependence between the original input and the prompt-concatenated input and (2) training to minimize CTC loss for improving ASR performance to a prompt-concatenated input. Experimental results show that INTapt improves the performance of L2 English and increases feature similarity between L2 and L1 accents.
Exactly Tight Information-Theoretic Generalization Error Bound for the Quadratic Gaussian Problem
May 01, 2023We provide a new information-theoretic generalization error bound that is exactly tight (i.e., matching even the constant) for the canonical quadratic Gaussian mean estimation problem. Despite considerable existing efforts in deriving information-theoretic generalization error bounds, applying them to this simple setting where sample average is used as the estimate of the mean value of Gaussian data has not yielded satisfying results. In fact, most existing bounds are order-wise loose in this setting, which has raised concerns about the fundamental capability of information-theoretic bounds in reasoning the generalization behavior for machine learning. The proposed new bound adopts the individual-sample-based approach proposed by Bu et al., but also has several key new ingredients. Firstly, instead of applying the change of measure inequality on the loss function, we apply it to the generalization error function itself; secondly, the bound is derived in a conditional manner; lastly, a reference distribution, which bears a certain similarity to the prior distribution in the Bayesian setting, is introduced. The combination of these components produces a general KL-divergence-based generalization error bound. We further show that although the conditional bounding and the reference distribution can make the bound exactly tight, removing them does not significantly degrade the bound, which leads to a mutual-information-based bound that is also asymptotically tight in this setting.
NLLG Quarterly arXiv Report 06/23: What are the most influential current AI Papers?
Jul 31, 2023
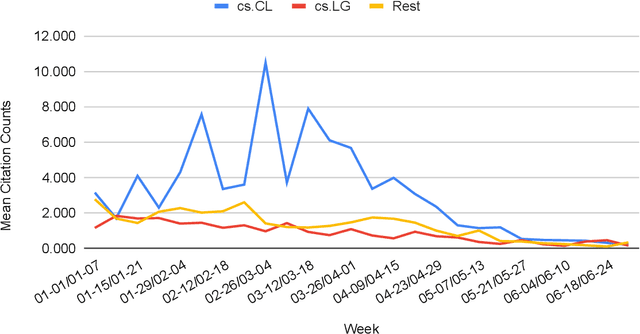
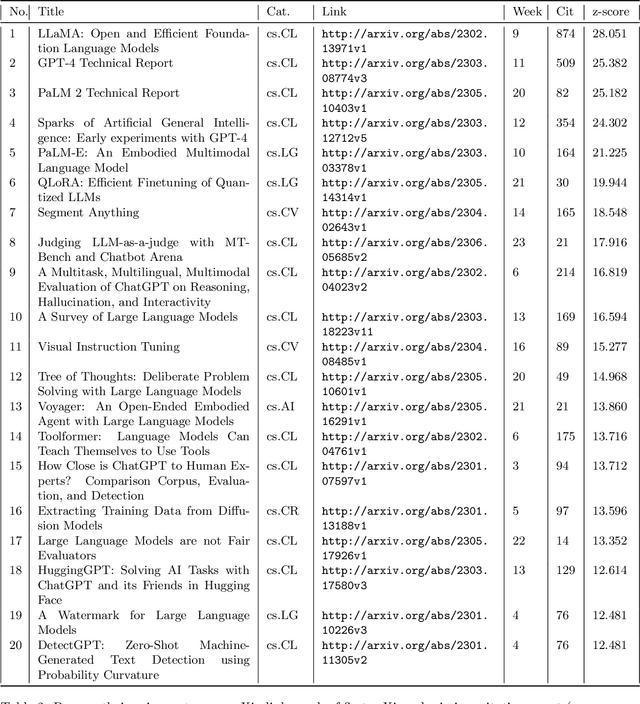
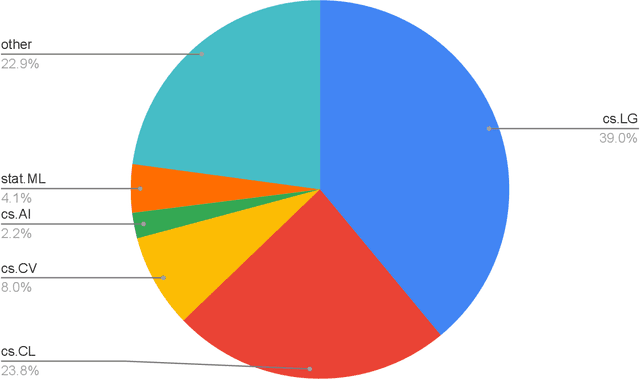
The rapid growth of information in the field of Generative Artificial Intelligence (AI), particularly in the subfields of Natural Language Processing (NLP) and Machine Learning (ML), presents a significant challenge for researchers and practitioners to keep pace with the latest developments. To address the problem of information overload, this report by the Natural Language Learning Group at Bielefeld University focuses on identifying the most popular papers on arXiv, with a specific emphasis on NLP and ML. The objective is to offer a quick guide to the most relevant and widely discussed research, aiding both newcomers and established researchers in staying abreast of current trends. In particular, we compile a list of the 40 most popular papers based on normalized citation counts from the first half of 2023. We observe the dominance of papers related to Large Language Models (LLMs) and specifically ChatGPT during the first half of 2023, with the latter showing signs of declining popularity more recently, however. Further, NLP related papers are the most influential (around 60\% of top papers) even though there are twice as many ML related papers in our data. Core issues investigated in the most heavily cited papers are: LLM efficiency, evaluation techniques, ethical considerations, embodied agents, and problem-solving with LLMs. Additionally, we examine the characteristics of top papers in comparison to others outside the top-40 list (noticing the top paper's focus on LLM related issues and higher number of co-authors) and analyze the citation distributions in our dataset, among others.
A Comprehensive Evaluation and Analysis Study for Chinese Spelling Check
Jul 25, 2023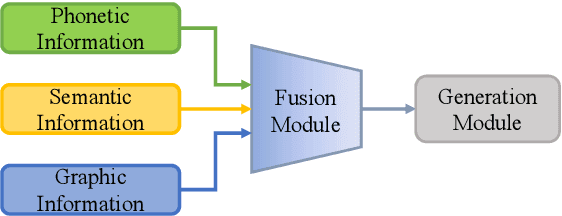


With the development of pre-trained models and the incorporation of phonetic and graphic information, neural models have achieved high scores in Chinese Spelling Check (CSC). However, it does not provide a comprehensive reflection of the models' capability due to the limited test sets. In this study, we abstract the representative model paradigm, implement it with nine structures and experiment them on comprehensive test sets we constructed with different purposes. We perform a detailed analysis of the results and find that: 1) Fusing phonetic and graphic information reasonably is effective for CSC. 2) Models are sensitive to the error distribution of the test set, which reflects the shortcomings of models and reveals the direction we should work on. 3) Whether or not the errors and contexts have been seen has a significant impact on models. 4) The commonly used benchmark, SIGHAN, can not reliably evaluate models' performance.
Integrating large language models and active inference to understand eye movements in reading and dyslexia
Aug 09, 2023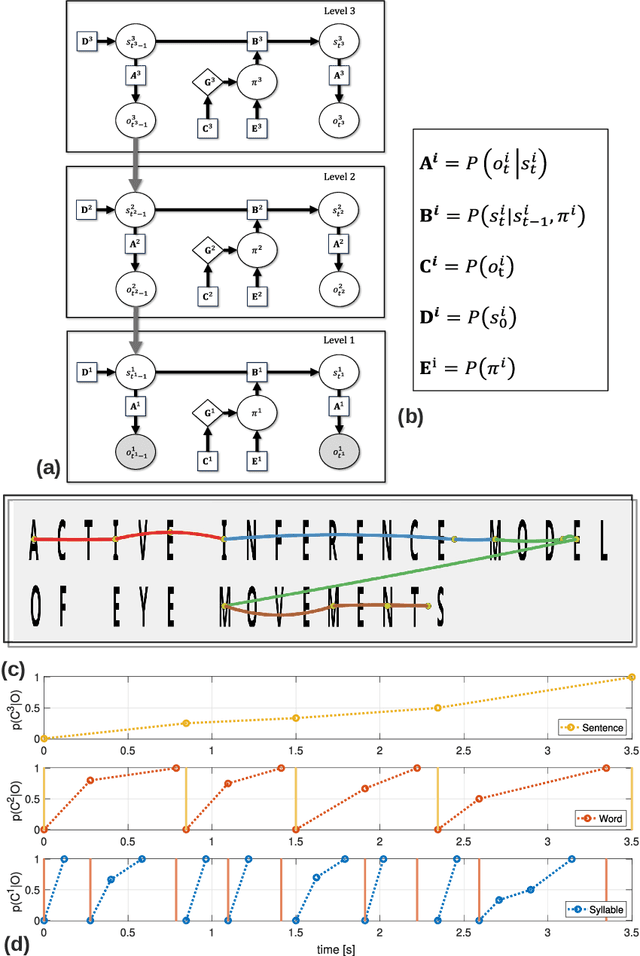
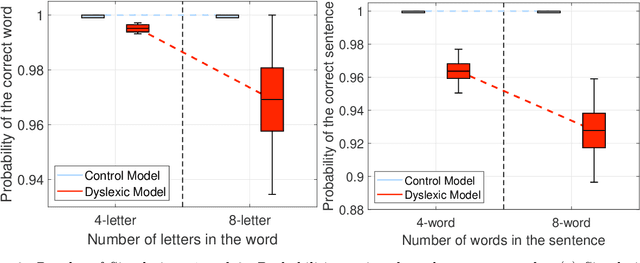
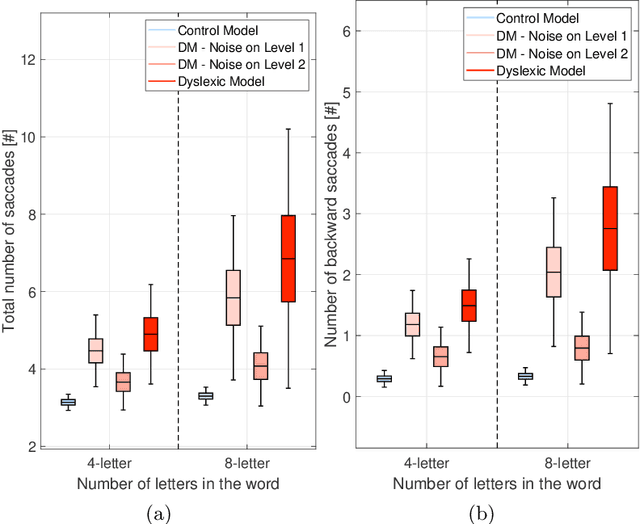
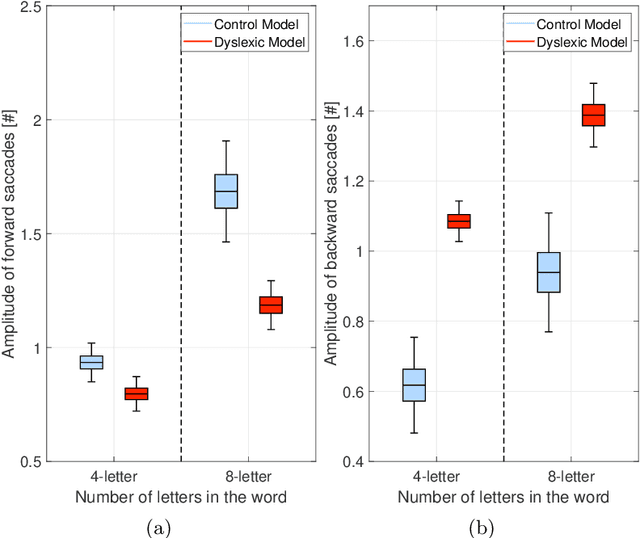
We present a novel computational model employing hierarchical active inference to simulate reading and eye movements. The model characterizes linguistic processing as inference over a hierarchical generative model, facilitating predictions and inferences at various levels of granularity, from syllables to sentences. Our approach combines the strengths of large language models for realistic textual predictions and active inference for guiding eye movements to informative textual information, enabling the testing of predictions. The model exhibits proficiency in reading both known and unknown words and sentences, adhering to the distinction between lexical and nonlexical routes in dual-route theories of reading. Notably, our model permits the exploration of maladaptive inference effects on eye movements during reading, such as in dyslexia. To simulate this condition, we attenuate the contribution of priors during the reading process, leading to incorrect inferences and a more fragmented reading style, characterized by a greater number of shorter saccades. This alignment with empirical findings regarding eye movements in dyslexic individuals highlights the model's potential to aid in understanding the cognitive processes underlying reading and eye movements, as well as how reading deficits associated with dyslexia may emerge from maladaptive predictive processing. In summary, our model represents a significant advancement in comprehending the intricate cognitive processes involved in reading and eye movements, with potential implications for understanding and addressing dyslexia through the simulation of maladaptive inference. It may offer valuable insights into this condition and contribute to the development of more effective interventions for treatment.