 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
V-DETR: DETR with Vertex Relative Position Encoding for 3D Object Detection
Aug 08, 2023

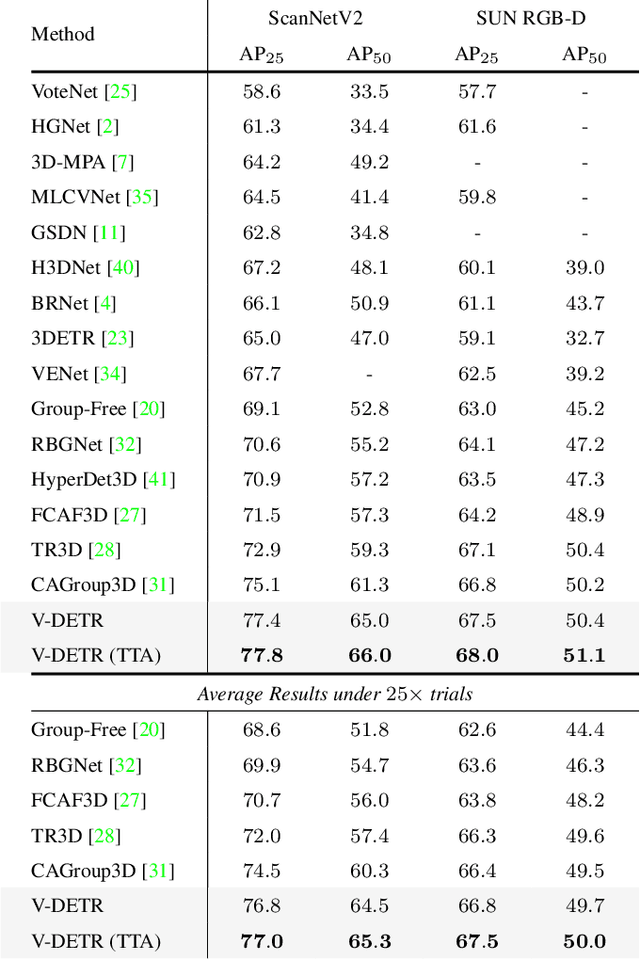

We introduce a highly performant 3D object detector for point clouds using the DETR framework. The prior attempts all end up with suboptimal results because they fail to learn accurate inductive biases from the limited scale of training data. In particular, the queries often attend to points that are far away from the target objects, violating the locality principle in object detection. To address the limitation, we introduce a novel 3D Vertex Relative Position Encoding (3DV-RPE) method which computes position encoding for each point based on its relative position to the 3D boxes predicted by the queries in each decoder layer, thus providing clear information to guide the model to focus on points near the objects, in accordance with the principle of locality. In addition, we systematically improve the pipeline from various aspects such as data normalization based on our understanding of the task. We show exceptional results on the challenging ScanNetV2 benchmark, achieving significant improvements over the previous 3DETR in $\rm{AP}_{25}$/$\rm{AP}_{50}$ from 65.0\%/47.0\% to 77.8\%/66.0\%, respectively. In addition, our method sets a new record on ScanNetV2 and SUN RGB-D datasets.Code will be released at http://github.com/yichaoshen-MS/V-DETR.
Federated Zeroth-Order Optimization using Trajectory-Informed Surrogate Gradients
Aug 08, 2023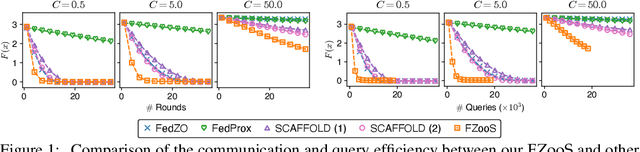
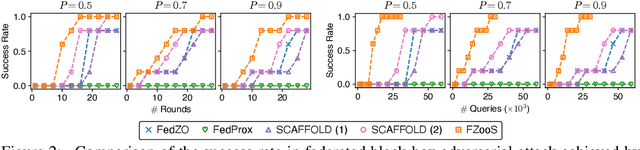
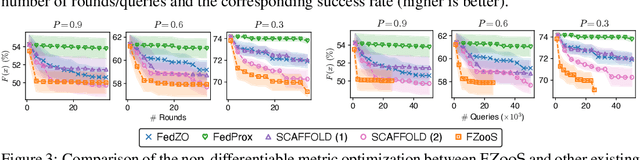
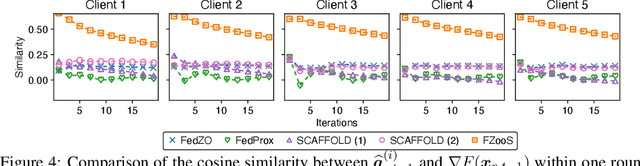
Federated optimization, an emerging paradigm which finds wide real-world applications such as federated learning, enables multiple clients (e.g., edge devices) to collaboratively optimize a global function. The clients do not share their local datasets and typically only share their local gradients. However, the gradient information is not available in many applications of federated optimization, which hence gives rise to the paradigm of federated zeroth-order optimization (ZOO). Existing federated ZOO algorithms suffer from the limitations of query and communication inefficiency, which can be attributed to (a) their reliance on a substantial number of function queries for gradient estimation and (b) the significant disparity between their realized local updates and the intended global updates. To this end, we (a) introduce trajectory-informed gradient surrogates which is able to use the history of function queries during optimization for accurate and query-efficient gradient estimation, and (b) develop the technique of adaptive gradient correction using these gradient surrogates to mitigate the aforementioned disparity. Based on these, we propose the federated zeroth-order optimization using trajectory-informed surrogate gradients (FZooS) algorithm for query- and communication-efficient federated ZOO. Our FZooS achieves theoretical improvements over the existing approaches, which is supported by our real-world experiments such as federated black-box adversarial attack and federated non-differentiable metric optimization.
Developmental Bootstrapping of AIs
Aug 11, 2023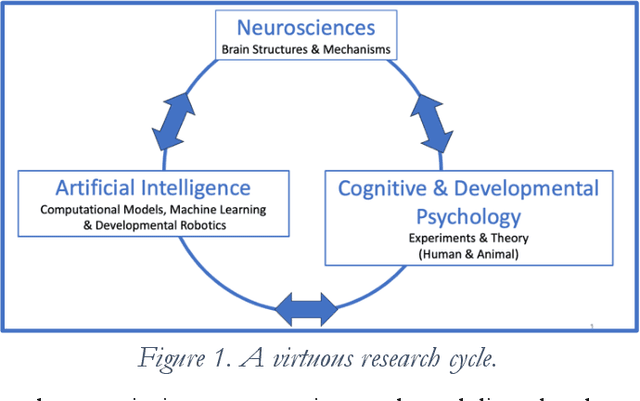

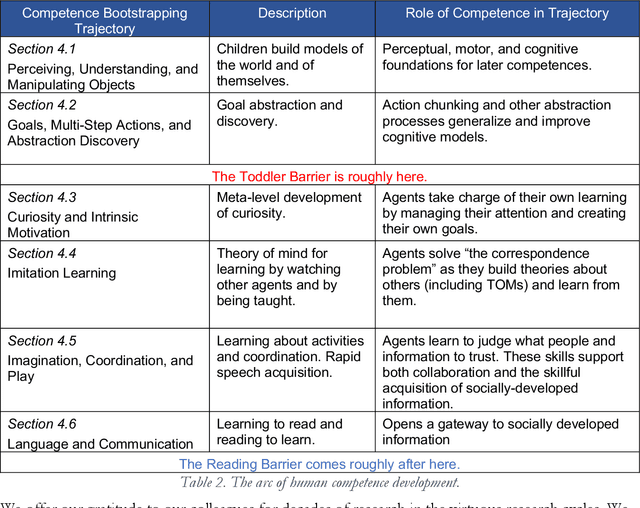
Although some current AIs surpass human abilities especially in closed artificial worlds such as board games, their abilities in the real world are limited. They make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. They do not make good collaborators. Mainstream approaches for creating AIs are built using the traditional manually-constructed symbolic AI approach and generative and deep learning AI approaches including large language models (LLMs). These systems are not well suited for creating robust and trustworthy AIs. Although it is outside of the mainstream, the developmental bootstrapping approach has more promise. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. They interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. They acquire the competences that they need through an incremental bootstrapping process. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped at the Toddler Barrier corresponding to human infant development at about two years of age, before their speech is fluent. They also do not bridge the Reading Barrier, to skillfully and skeptically tap into the vast socially developed recorded information resources that power LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This position paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to acquire further competences and create robust and resilient AIs.
Large Language Models to Identify Social Determinants of Health in Electronic Health Records
Aug 11, 2023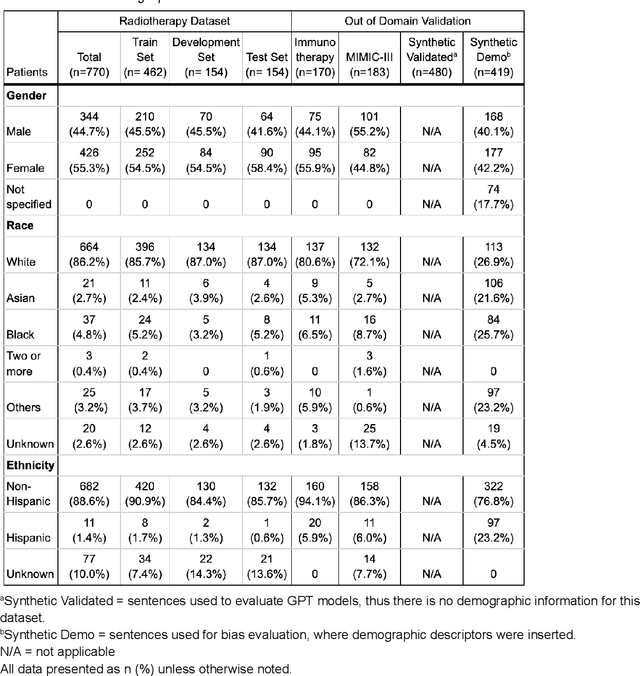

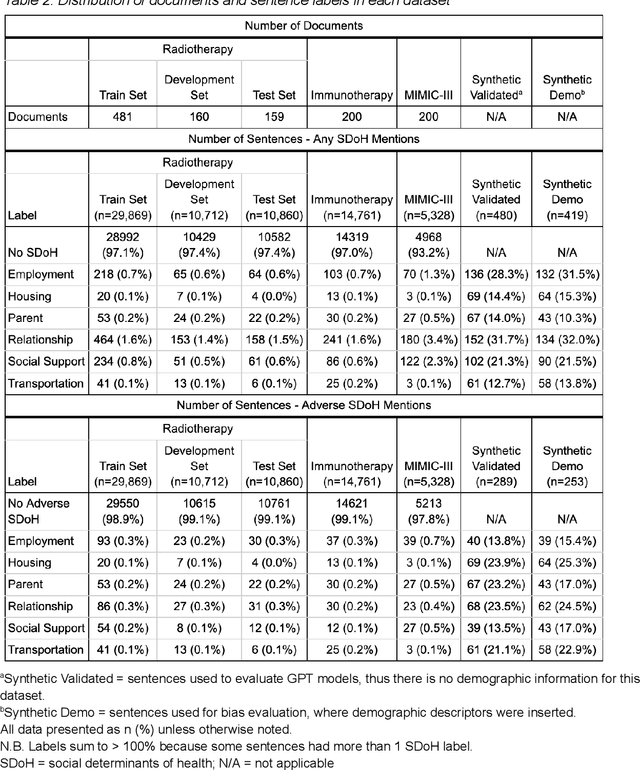
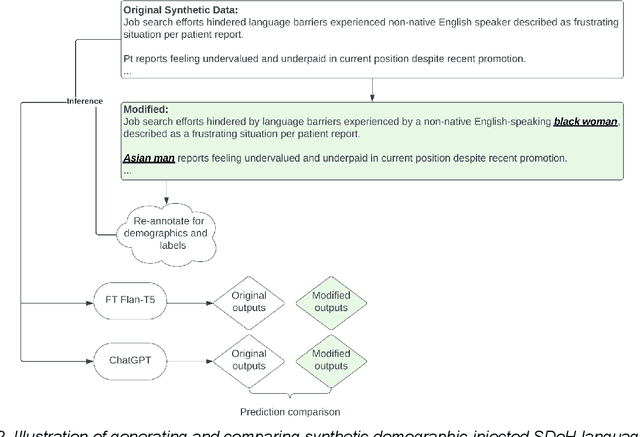
Social determinants of health (SDoH) have an important impact on patient outcomes but are incompletely collected from the electronic health records (EHR). This study researched the ability of large language models to extract SDoH from free text in EHRs, where they are most commonly documented, and explored the role of synthetic clinical text for improving the extraction of these scarcely documented, yet extremely valuable, clinical data. 800 patient notes were annotated for SDoH categories, and several transformer-based models were evaluated. The study also experimented with synthetic data generation and assessed for algorithmic bias. Our best-performing models were fine-tuned Flan-T5 XL (macro-F1 0.71) for any SDoH, and Flan-T5 XXL (macro-F1 0.70). The benefit of augmenting fine-tuning with synthetic data varied across model architecture and size, with smaller Flan-T5 models (base and large) showing the greatest improvements in performance (delta F1 +0.12 to +0.23). Model performance was similar on the in-hospital system dataset but worse on the MIMIC-III dataset. Our best-performing fine-tuned models outperformed zero- and few-shot performance of ChatGPT-family models for both tasks. These fine-tuned models were less likely than ChatGPT to change their prediction when race/ethnicity and gender descriptors were added to the text, suggesting less algorithmic bias (p<0.05). At the patient-level, our models identified 93.8% of patients with adverse SDoH, while ICD-10 codes captured 2.0%. Our method can effectively extracted SDoH information from clinic notes, performing better compare to GPT zero- and few-shot settings. These models could enhance real-world evidence on SDoH and aid in identifying patients needing social support.
GNN4FR: A Lossless GNN-based Federated Recommendation Framework
Jul 25, 2023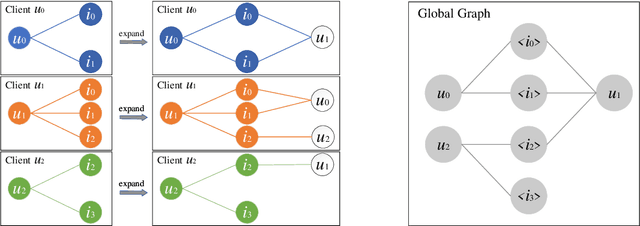



Graph neural networks (GNNs) have gained wide popularity in recommender systems due to their capability to capture higher-order structure information among the nodes of users and items. However, these methods need to collect personal interaction data between a user and the corresponding items and then model them in a central server, which would break the privacy laws such as GDPR. So far, no existing work can construct a global graph without leaking each user's private interaction data (i.e., his or her subgraph). In this paper, we are the first to design a novel lossless federated recommendation framework based on GNN, which achieves full-graph training with complete high-order structure information, enabling the training process to be equivalent to the corresponding un-federated counterpart. In addition, we use LightGCN to instantiate an example of our framework and show its equivalence.
MiAMix: Enhancing Image Classification through a Multi-stage Augmented Mixied Sample Data Augmentation Method
Aug 05, 2023
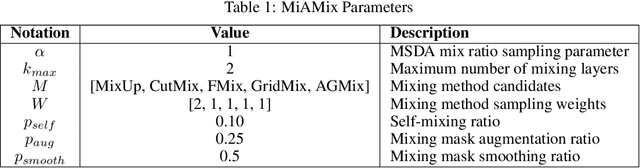
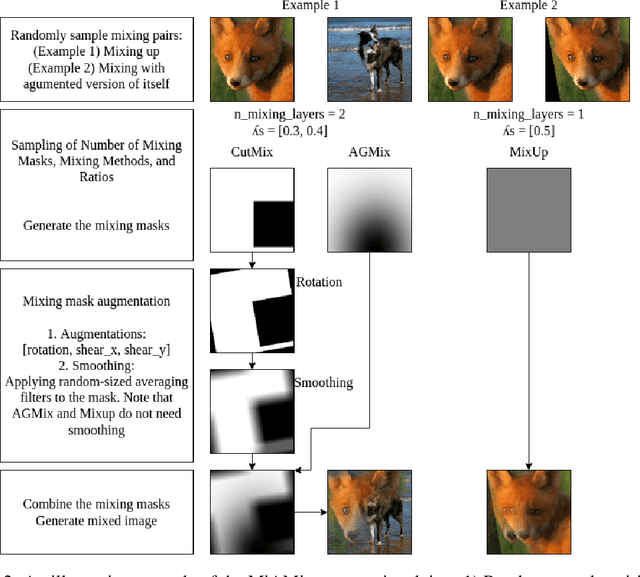
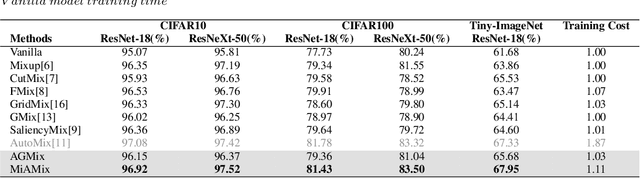
Despite substantial progress in the field of deep learning, overfitting persists as a critical challenge, and data augmentation has emerged as a particularly promising approach due to its capacity to enhance model generalization in various computer vision tasks. While various strategies have been proposed, Mixed Sample Data Augmentation (MSDA) has shown great potential for enhancing model performance and generalization. We introduce a novel mixup method called MiAMix, which stands for Multi-stage Augmented Mixup. MiAMix integrates image augmentation into the mixup framework, utilizes multiple diversified mixing methods concurrently, and improves the mixing method by randomly selecting mixing mask augmentation methods. Recent methods utilize saliency information and the MiAMix is designed for computational efficiency as well, reducing additional overhead and offering easy integration into existing training pipelines. We comprehensively evaluate MiaMix using four image benchmarks and pitting it against current state-of-the-art mixed sample data augmentation techniques to demonstrate that MIAMix improves performance without heavy computational overhead.
Minimally-Supervised Speech Synthesis with Conditional Diffusion Model and Language Model: A Comparative Study of Semantic Coding
Jul 28, 2023
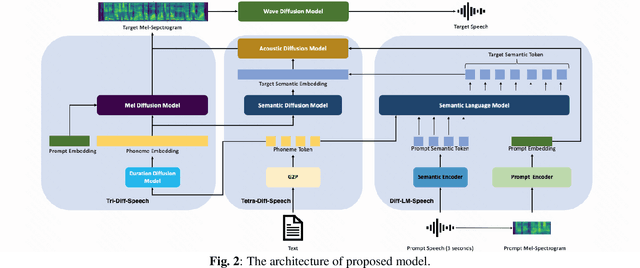
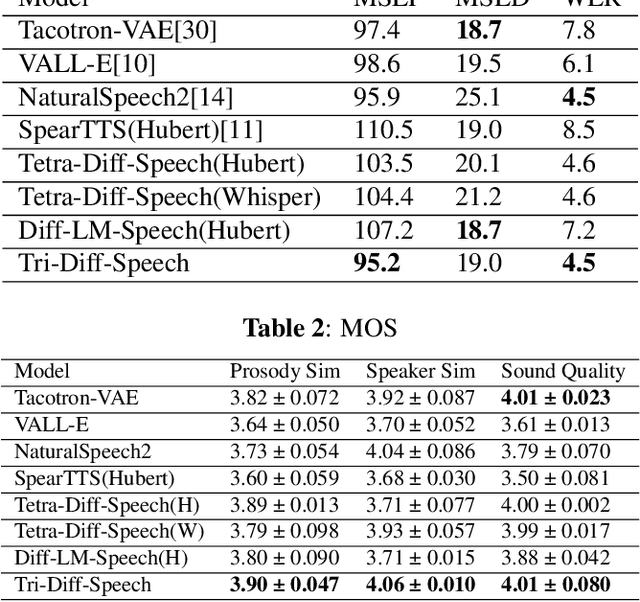
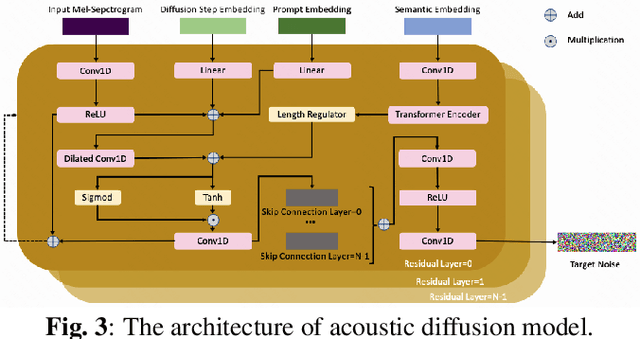
Recently, there has been a growing interest in text-to-speech (TTS) methods that can be trained with minimal supervision by combining two types of discrete speech representations and using two sequence-to-sequence tasks to decouple TTS. To address the challenges associated with high dimensionality and waveform distortion in discrete representations, we propose Diff-LM-Speech, which models semantic embeddings into mel-spectrogram based on diffusion models and introduces a prompt encoder structure based on variational autoencoders and prosody bottlenecks to improve prompt representation capabilities. Autoregressive language models often suffer from missing and repeated words, while non-autoregressive frameworks face expression averaging problems due to duration prediction models. To address these issues, we propose Tetra-Diff-Speech, which designs a duration diffusion model to achieve diverse prosodic expressions. While we expect the information content of semantic coding to be between that of text and acoustic coding, existing models extract semantic coding with a lot of redundant information and dimensionality explosion. To verify that semantic coding is not necessary, we propose Tri-Diff-Speech. Experimental results show that our proposed methods outperform baseline methods. We provide a website with audio samples.
How User Language Affects Conflict Fatality Estimates in ChatGPT
Jul 26, 2023
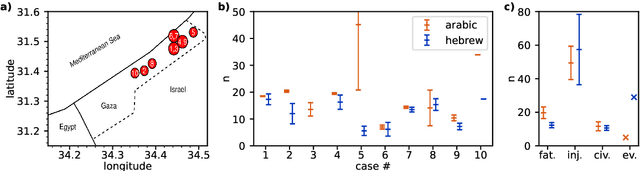
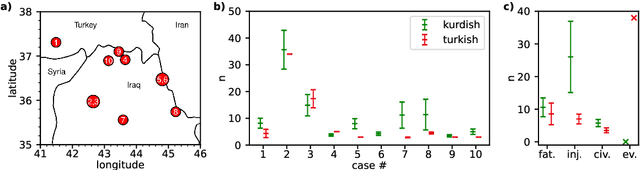
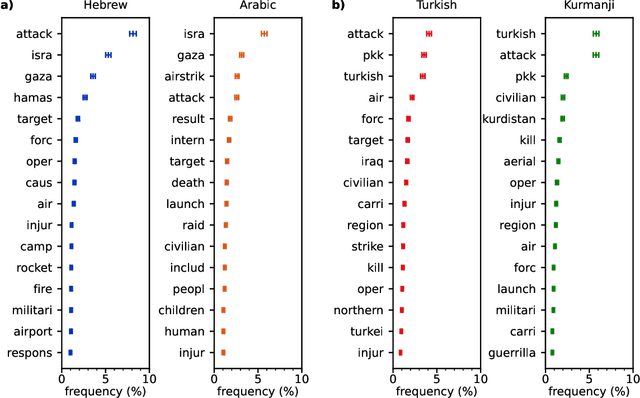
OpenAI's ChatGPT language model has gained popularity as a powerful tool for complex problem-solving and information retrieval. However, concerns arise about the reproduction of biases present in the language-specific training data. In this study, we address this issue in the context of the Israeli-Palestinian and Turkish-Kurdish conflicts. Using GPT-3.5, we employed an automated query procedure to inquire about casualties in specific airstrikes, in both Hebrew and Arabic for the former conflict and Turkish and Kurdish for the latter. Our analysis reveals that GPT-3.5 provides 27$\pm$11 percent lower fatality estimates when queried in the language of the attacker than in the language of the targeted group. Evasive answers denying the existence of such attacks further increase the discrepancy, creating a novel bias mechanism not present in regular search engines. This language bias has the potential to amplify existing media biases and contribute to information bubbles, ultimately reinforcing conflicts.
Extreme Image Compression using Fine-tuned VQGAN Models
Aug 07, 2023



Recent advances in generative compression methods have demonstrated remarkable progress in enhancing the perceptual quality of compressed data, especially in scenarios with low bitrates. Nevertheless, their efficacy and applicability in achieving extreme compression ratios ($<0.1$ bpp) still remain constrained. In this work, we propose a simple yet effective coding framework by introducing vector quantization (VQ)-based generative models into the image compression domain. The main insight is that the codebook learned by the VQGAN model yields strong expressive capacity, facilitating efficient compression of continuous information in the latent space while maintaining reconstruction quality. Specifically, an image can be represented as VQ-indices by finding the nearest codeword, which can be encoded using lossless compression methods into bitstreams. We then propose clustering a pre-trained large-scale codebook into smaller codebooks using the K-means algorithm. This enables images to be represented as diverse ranges of VQ-indices maps, resulting in variable bitrates and different levels of reconstruction quality. Extensive qualitative and quantitative experiments on various datasets demonstrate that the proposed framework outperforms the state-of-the-art codecs in terms of perceptual quality-oriented metrics and human perception under extremely low bitrates.
Analysis of the Evolution of Advanced Transformer-Based Language Models: Experiments on Opinion Mining
Aug 07, 2023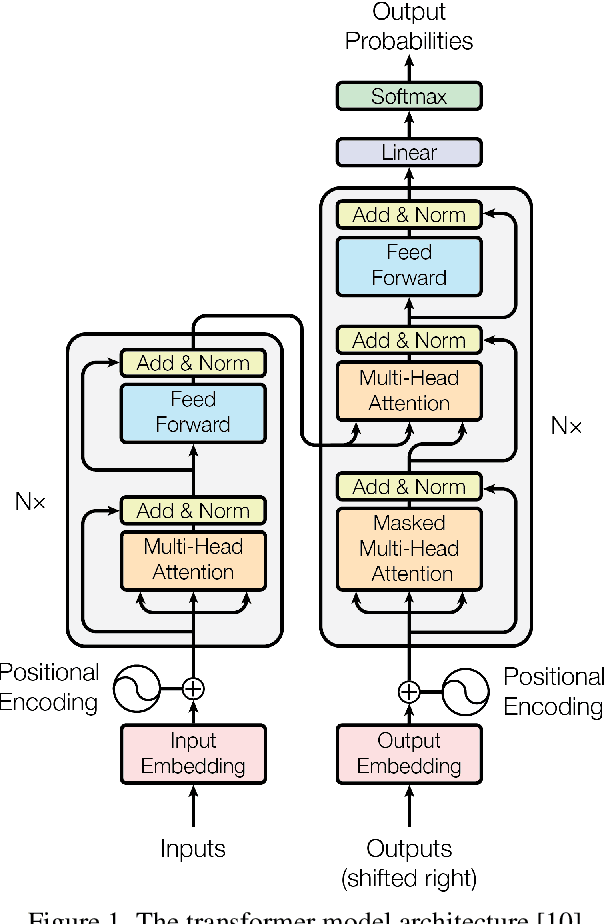
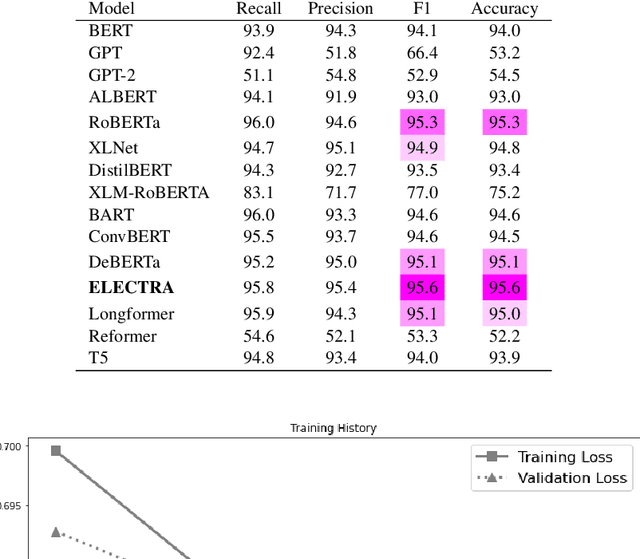
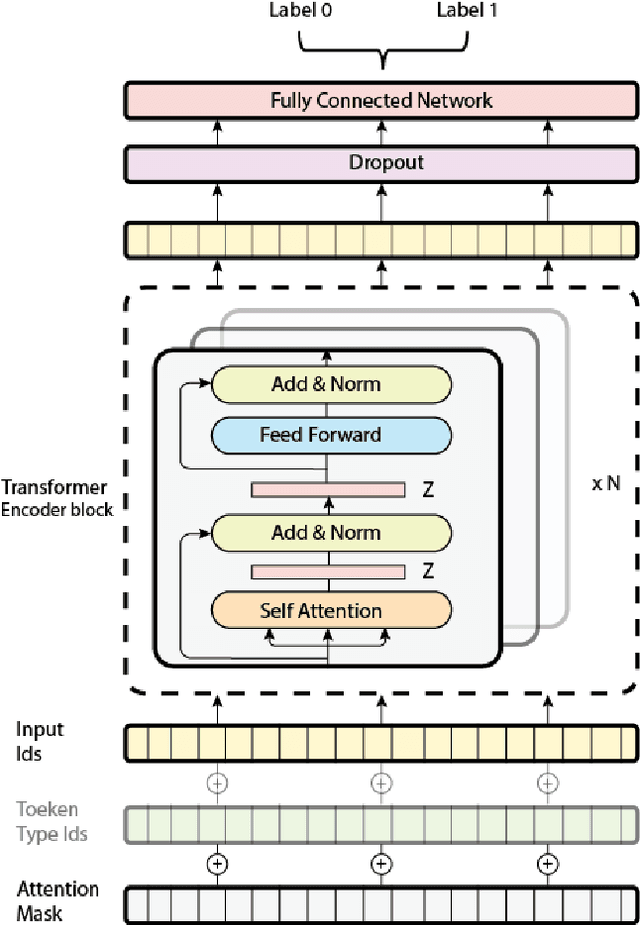
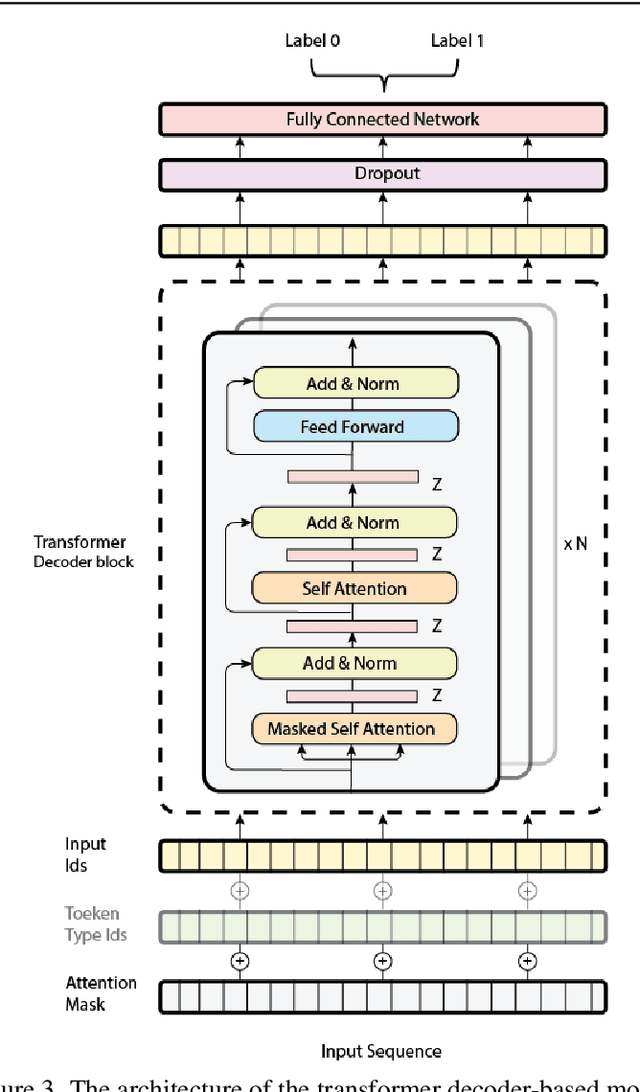
Opinion mining, also known as sentiment analysis, is a subfield of natural language processing (NLP) that focuses on identifying and extracting subjective information in textual material. This can include determining the overall sentiment of a piece of text (e.g., positive or negative), as well as identifying specific emotions or opinions expressed in the text, that involves the use of advanced machine and deep learning techniques. Recently, transformer-based language models make this task of human emotion analysis intuitive, thanks to the attention mechanism and parallel computation. These advantages make such models very powerful on linguistic tasks, unlike recurrent neural networks that spend a lot of time on sequential processing, making them prone to fail when it comes to processing long text. The scope of our paper aims to study the behaviour of the cutting-edge Transformer-based language models on opinion mining and provide a high-level comparison between them to highlight their key particularities. Additionally, our comparative study shows leads and paves the way for production engineers regarding the approach to focus on and is useful for researchers as it provides guidelines for future research subjects.