 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of the Evolution of Advanced Transformer-Based Language Models: Experiments on Opinion Mining
Aug 07, 2023



Opinion mining, also known as sentiment analysis, is a subfield of natural language processing (NLP) that focuses on identifying and extracting subjective information in textual material. This can include determining the overall sentiment of a piece of text (e.g., positive or negative), as well as identifying specific emotions or opinions expressed in the text, that involves the use of advanced machine and deep learning techniques. Recently, transformer-based language models make this task of human emotion analysis intuitive, thanks to the attention mechanism and parallel computation. These advantages make such models very powerful on linguistic tasks, unlike recurrent neural networks that spend a lot of time on sequential processing, making them prone to fail when it comes to processing long text. The scope of our paper aims to study the behaviour of the cutting-edge Transformer-based language models on opinion mining and provide a high-level comparison between them to highlight their key particularities. Additionally, our comparative study shows leads and paves the way for production engineers regarding the approach to focus on and is useful for researchers as it provides guidelines for future research subjects.
BERT Based Clinical Knowledge Extraction for Biomedical Knowledge Graph Construction and Analysis
Apr 21, 2023Background : Knowledge is evolving over time, often as a result of new discoveries or changes in the adopted methods of reasoning. Also, new facts or evidence may become available, leading to new understandings of complex phenomena. This is particularly true in the biomedical field, where scientists and physicians are constantly striving to find new methods of diagnosis, treatment and eventually cure. Knowledge Graphs (KGs) offer a real way of organizing and retrieving the massive and growing amount of biomedical knowledge. Objective : We propose an end-to-end approach for knowledge extraction and analysis from biomedical clinical notes using the Bidirectional Encoder Representations from Transformers (BERT) model and Conditional Random Field (CRF) layer. Methods : The approach is based on knowledge graphs, which can effectively process abstract biomedical concepts such as relationships and interactions between medical entities. Besides offering an intuitive way to visualize these concepts, KGs can solve more complex knowledge retrieval problems by simplifying them into simpler representations or by transforming the problems into representations from different perspectives. We created a biomedical Knowledge Graph using using Natural Language Processing models for named entity recognition and relation extraction. The generated biomedical knowledge graphs (KGs) are then used for question answering. Results : The proposed framework can successfully extract relevant structured information with high accuracy (90.7% for Named-entity recognition (NER), 88% for relation extraction (RE)), according to experimental findings based on real-world 505 patient biomedical unstructured clinical notes. Conclusions : In this paper, we propose a novel end-to-end system for the construction of a biomedical knowledge graph from clinical textual using a variation of BERT models.
Supervised Machine Learning for Breast Cancer Risk Factors Analysis and Survival Prediction
Apr 13, 2023The choice of the most effective treatment may eventually be influenced by breast cancer survival prediction. To predict the chances of a patient surviving, a variety of techniques were employed, such as statistical, machine learning, and deep learning models. In the current study, 1904 patient records from the METABRIC dataset were utilized to predict a 5-year breast cancer survival using a machine learning approach. In this study, we compare the outcomes of seven classification models to evaluate how well they perform using the following metrics: recall, AUC, confusion matrix, accuracy, precision, false positive rate, and true positive rate. The findings demonstrate that the classifiers for Logistic Regression (LR), Support Vector Machines (SVM), Decision Tree (DT), Random Forest (RD), Extremely Randomized Trees (ET), K-Nearest Neighbor (KNN), and Adaptive Boosting (AdaBoost) can accurately predict the survival rate of the tested samples, which is 75,4\%, 74,7\%, 71,5\%, 75,5\%, 70,3\%, and 78 percent.
Smart Agriculture : A Novel Multilevel Approach for Agricultural Risk Assessment over Unstructured Data
Nov 22, 2022Detecting opportunities and threats from massive text data is a challenging task for most. Traditionally, companies would rely mainly on structured data to detect and predict risks, losing a huge amount of information that could be extracted from unstructured text data. Fortunately, artificial intelligence came to remedy this issue by innovating in data extraction and processing techniques, allowing us to understand and make use of Natural Language data and turning it into structures that a machine can process and extract insight from. Uncertainty refers to a state of not knowing what will happen in the future. This paper aims to leverage natural language processing and machine learning techniques to model uncertainties and evaluate the risk level in each uncertainty cluster using massive text data.
Towards a Generic Multimodal Architecture for Batch and Streaming Big Data Integration
Aug 09, 2021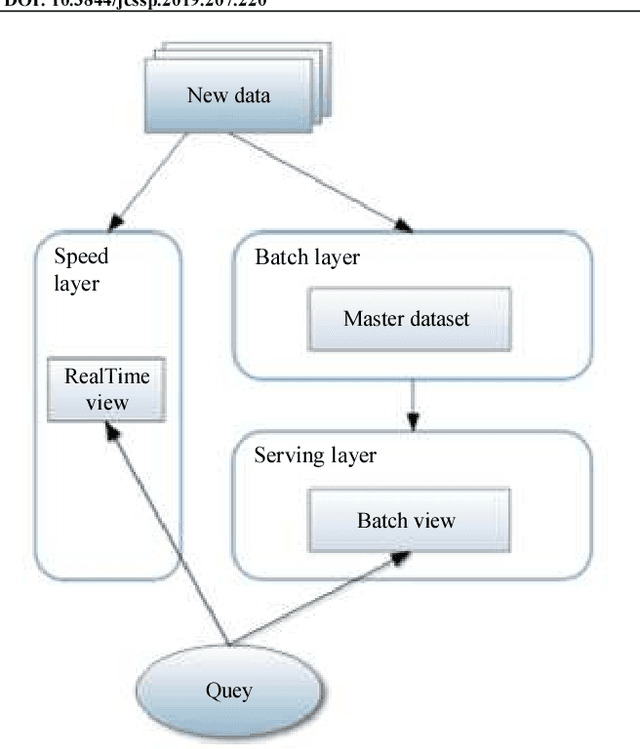
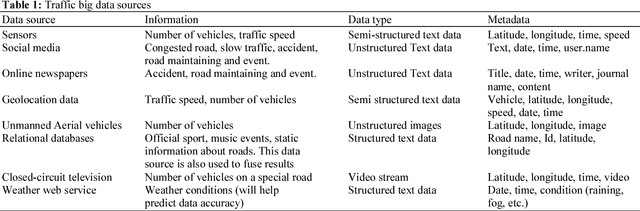
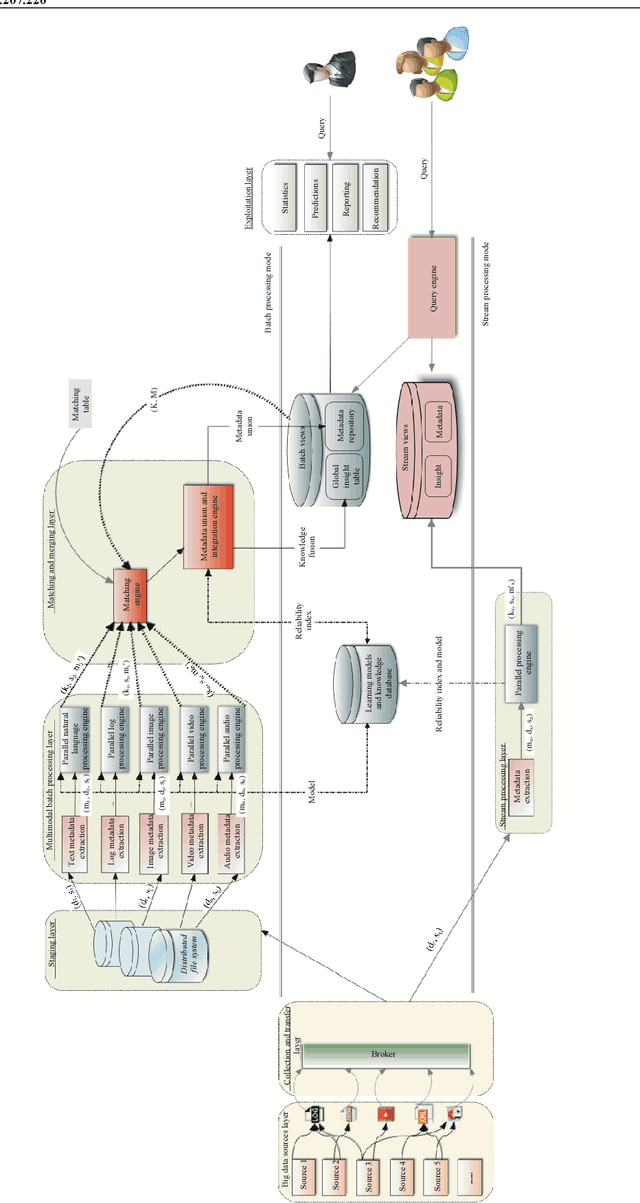
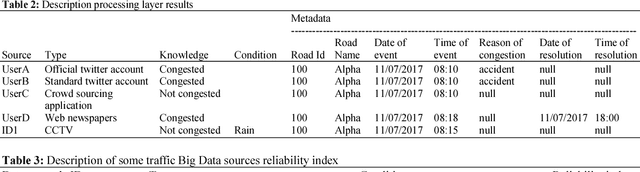
Big Data are rapidly produced from various heterogeneous data sources. They are of different types (text, image, video or audio) and have different levels of reliability and completeness. One of the most interesting architectures that deal with the large amount of emerging data at high velocity is called the lambda architecture. In fact, it combines two different processing layers namely batch and speed layers, each providing specific views of data while ensuring robustness, fast and scalable data processing. However, most papers dealing with the lambda architecture are focusing one single type of data generally produced by a single data source. Besides, the layers of the architecture are implemented independently, or, at best, are combined to perform basic processing without assessing either the data reliability or completeness. Therefore, inspired by the lambda architecture, we propose in this paper a generic multimodal architecture that combines both batch and streaming processing in order to build a complete, global and accurate insight in near-real-time based on the knowledge extracted from multiple heterogeneous Big Data sources. Our architecture uses batch processing to analyze the data structures and contents, build the learning models and calculate the reliability index of the involved sources, while the streaming processing uses the built-in models of the batch layer to immediately process incoming data and rapidly provide results. We validate our architecture in the context of urban traffic management systems in order to detect congestions.