 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self Information Update for Large Language Models through Mitigating Exposure Bias
May 29, 2023

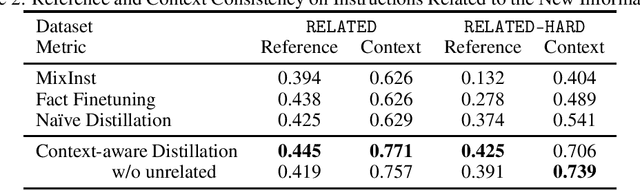
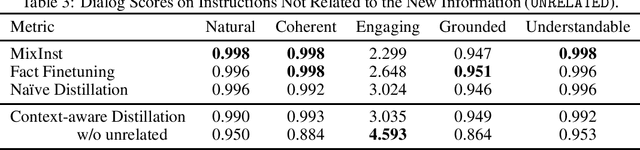

Current LLMs have demonstrated remarkable capabilities in addressing users' requests for various types of information. However, these models are limited by the most recent data available in their pretraining corpora, rendering them incapable of providing up-to-date information. Retraining LLMs from scratch is cost-prohibitive, and the effectiveness of continual fine-tuning on new corpora has not been thoroughly examined. Additionally, current update procedures typically demand significant human input to prepare the information into more structured format, such as knowledge triples, conversational data or responses with human feedback. In this study, we conduct a comprehensive examination of a novel self information update task in LLMs, which only requires the provision of informative text corpora. For instance, we can use the latest news articles to update the LLMs' existing knowledge. We define the self information update task and assess the continual fine-tuning approach for this purpose. We observe that the naive method of continual fine-tuning can be problematic due to LLMs' exposure bias, which prioritizes existing information over new information we aim to integrate and leads to incorrect reasoning chains that ultimately diminish the efficacy of information updates. Based on our analysis, we propose an effective method to mitigate exposure bias by incorporating the selection of relevant facts into training losses. Furthermore, we develop a dataset to evaluate information updates, derived from news articles published after March 2023. Experimental results demonstrate that our proposed approach significantly increases the factual consistency score (0 to 1) by 0.16 while having minimal impact on performance for instructions not directly related to the new information.
Domain Information Control at Inference Time for Acoustic Scene Classification
Jun 13, 2023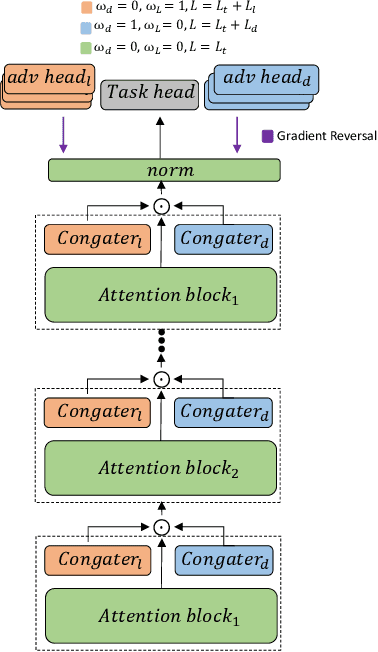
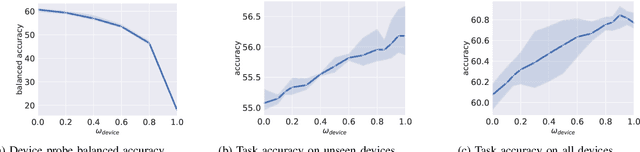

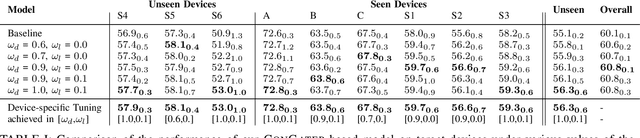
Domain shift is considered a challenge in machine learning as it causes significant degradation of model performance. In the Acoustic Scene Classification task (ASC), domain shift is mainly caused by different recording devices. Several studies have already targeted domain generalization to improve the performance of ASC models on unseen domains, such as new devices. Recently, the Controllable Gate Adapter ConGater has been proposed in Natural Language Processing to address the biased training data problem. ConGater allows controlling the debiasing process at inference time. ConGater's main advantage is the continuous and selective debiasing of a trained model, during inference. In this work, we adapt ConGater to the audio spectrogram transformer for an acoustic scene classification task. We show that ConGater can be used to selectively adapt the learned representations to be invariant to device domain shifts such as recording devices. Our analysis shows that ConGater can progressively remove device information from the learned representations and improve the model generalization, especially under domain shift conditions (e.g. unseen devices). We show that information removal can be extended to both device and location domain. Finally, we demonstrate ConGater's ability to enhance specific device performance without further training.
Learning Cross-Modal Affinity for Referring Video Object Segmentation Targeting Limited Samples
Sep 05, 2023
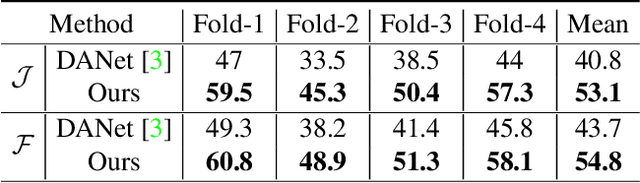
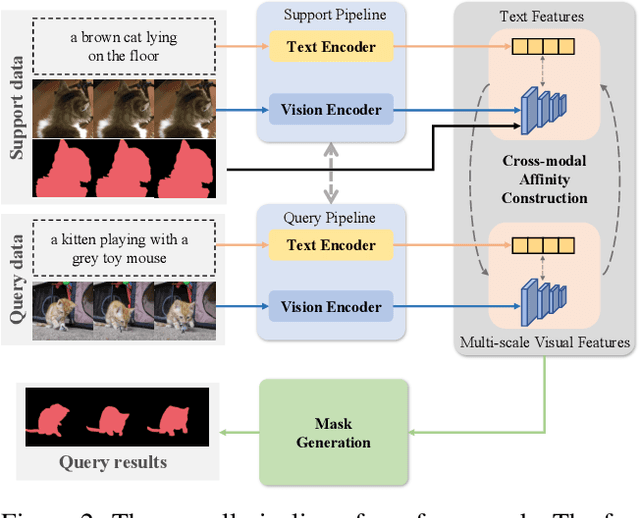
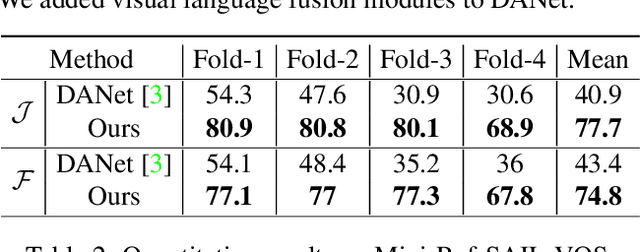
Referring video object segmentation (RVOS), as a supervised learning task, relies on sufficient annotated data for a given scene. However, in more realistic scenarios, only minimal annotations are available for a new scene, which poses significant challenges to existing RVOS methods. With this in mind, we propose a simple yet effective model with a newly designed cross-modal affinity (CMA) module based on a Transformer architecture. The CMA module builds multimodal affinity with a few samples, thus quickly learning new semantic information, and enabling the model to adapt to different scenarios. Since the proposed method targets limited samples for new scenes, we generalize the problem as - few-shot referring video object segmentation (FS-RVOS). To foster research in this direction, we build up a new FS-RVOS benchmark based on currently available datasets. The benchmark covers a wide range and includes multiple situations, which can maximally simulate real-world scenarios. Extensive experiments show that our model adapts well to different scenarios with only a few samples, reaching state-of-the-art performance on the benchmark. On Mini-Ref-YouTube-VOS, our model achieves an average performance of 53.1 J and 54.8 F, which are 10% better than the baselines. Furthermore, we show impressive results of 77.7 J and 74.8 F on Mini-Ref-SAIL-VOS, which are significantly better than the baselines. Code is publicly available at https://github.com/hengliusky/Few_shot_RVOS.
Recurrence-Free Survival Prediction for Anal Squamous Cell Carcinoma Chemoradiotherapy using Planning CT-based Radiomics Model
Sep 05, 2023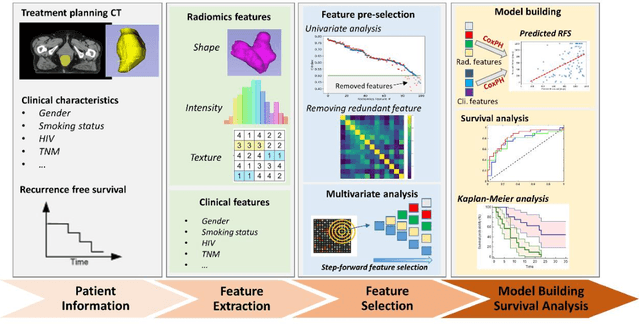
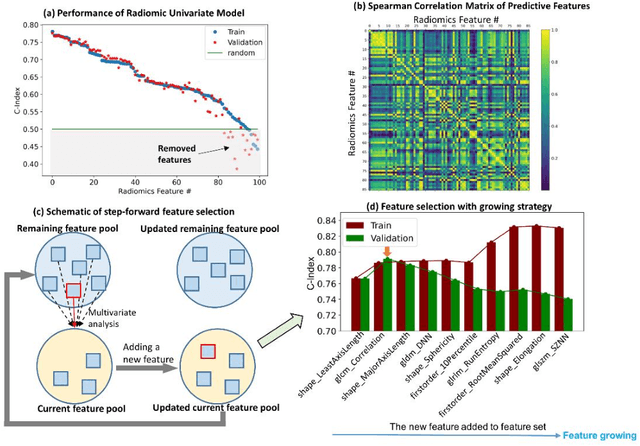
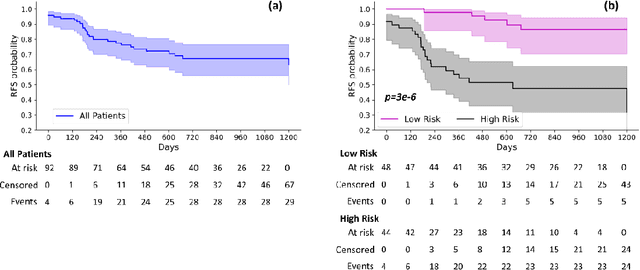
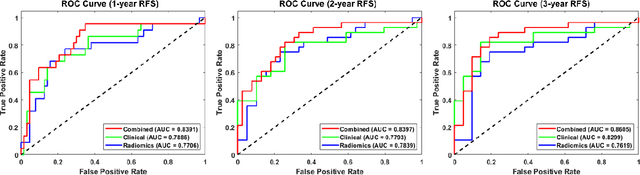
Objectives: Approximately 30% of non-metastatic anal squamous cell carcinoma (ASCC) patients will experience recurrence after chemoradiotherapy (CRT), and currently available clinical variables are poor predictors of treatment response. We aimed to develop a model leveraging information extracted from radiation pretreatment planning CT to predict recurrence-free survival (RFS) in ASCC patients after CRT. Methods: Radiomics features were extracted from planning CT images of 96 ASCC patients. Following pre-feature selection, the optimal feature set was selected via step-forward feature selection with a multivariate Cox proportional hazard model. The RFS prediction was generated from a radiomics-clinical combined model based on an optimal feature set with five repeats of five-fold cross validation. The risk stratification ability of the proposed model was evaluated with Kaplan-Meier analysis. Results: Shape- and texture-based radiomics features significantly predicted RFS. Compared to a clinical-only model, radiomics-clinical combined model achieves better performance in the testing cohort with higher C-index (0.80 vs 0.73) and AUC (0.84 vs 0.79 for 1-year RFS, 0.84 vs 0.78 for 2-year RFS, and 0.86 vs 0.83 for 3-year RFS), leading to distinctive high- and low-risk of recurrence groups (p<0.001). Conclusions: A treatment planning CT based radiomics and clinical combined model had improved prognostic performance in predicting RFS for ASCC patients treated with CRT as compared to a model using clinical features only.
On the Complexity of Differentially Private Best-Arm Identification with Fixed Confidence
Sep 05, 2023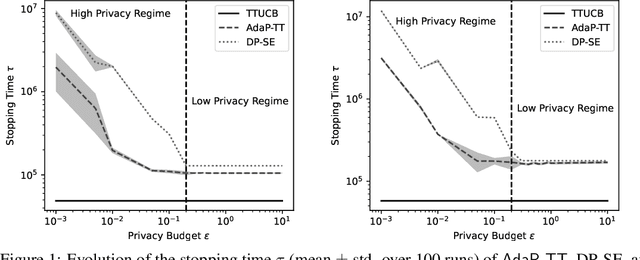
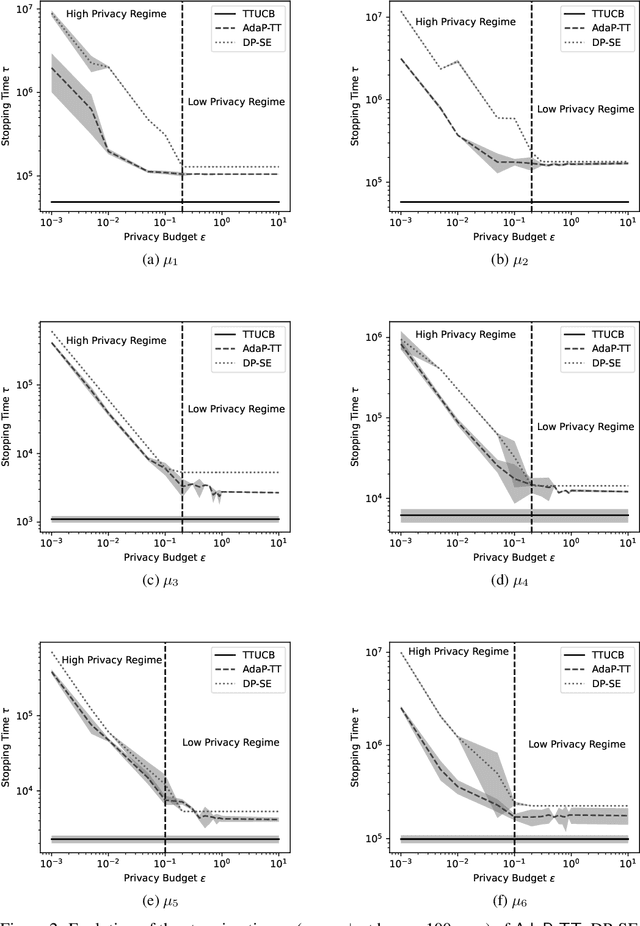
Best Arm Identification (BAI) problems are progressively used for data-sensitive applications, such as designing adaptive clinical trials, tuning hyper-parameters, and conducting user studies to name a few. Motivated by the data privacy concerns invoked by these applications, we study the problem of BAI with fixed confidence under $\epsilon$-global Differential Privacy (DP). First, to quantify the cost of privacy, we derive a lower bound on the sample complexity of any $\delta$-correct BAI algorithm satisfying $\epsilon$-global DP. Our lower bound suggests the existence of two privacy regimes depending on the privacy budget $\epsilon$. In the high-privacy regime (small $\epsilon$), the hardness depends on a coupled effect of privacy and a novel information-theoretic quantity, called the Total Variation Characteristic Time. In the low-privacy regime (large $\epsilon$), the sample complexity lower bound reduces to the classical non-private lower bound. Second, we propose AdaP-TT, an $\epsilon$-global DP variant of the Top Two algorithm. AdaP-TT runs in arm-dependent adaptive episodes and adds Laplace noise to ensure a good privacy-utility trade-off. We derive an asymptotic upper bound on the sample complexity of AdaP-TT that matches with the lower bound up to multiplicative constants in the high-privacy regime. Finally, we provide an experimental analysis of AdaP-TT that validates our theoretical results.
BigFUSE: Global Context-Aware Image Fusion in Dual-View Light-Sheet Fluorescence Microscopy with Image Formation Prior
Sep 05, 2023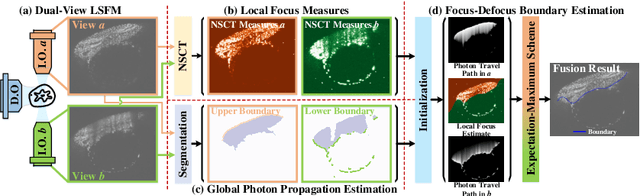
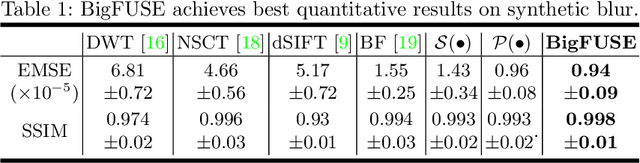


Light-sheet fluorescence microscopy (LSFM), a planar illumination technique that enables high-resolution imaging of samples, experiences defocused image quality caused by light scattering when photons propagate through thick tissues. To circumvent this issue, dualview imaging is helpful. It allows various sections of the specimen to be scanned ideally by viewing the sample from opposing orientations. Recent image fusion approaches can then be applied to determine in-focus pixels by comparing image qualities of two views locally and thus yield spatially inconsistent focus measures due to their limited field-of-view. Here, we propose BigFUSE, a global context-aware image fuser that stabilizes image fusion in LSFM by considering the global impact of photon propagation in the specimen while determining focus-defocus based on local image qualities. Inspired by the image formation prior in dual-view LSFM, image fusion is considered as estimating a focus-defocus boundary using Bayes Theorem, where (i) the effect of light scattering onto focus measures is included within Likelihood; and (ii) the spatial consistency regarding focus-defocus is imposed in Prior. The expectation-maximum algorithm is then adopted to estimate the focus-defocus boundary. Competitive experimental results show that BigFUSE is the first dual-view LSFM fuser that is able to exclude structured artifacts when fusing information, highlighting its abilities of automatic image fusion.
Distributed Dual Coordinate Ascent with Imbalanced Data on a General Tree Network
Aug 28, 2023
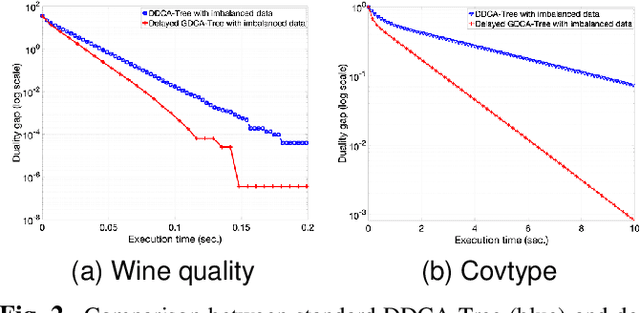
In this paper, we investigate the impact of imbalanced data on the convergence of distributed dual coordinate ascent in a tree network for solving an empirical loss minimization problem in distributed machine learning. To address this issue, we propose a method called delayed generalized distributed dual coordinate ascent that takes into account the information of the imbalanced data, and provide the analysis of the proposed algorithm. Numerical experiments confirm the effectiveness of our proposed method in improving the convergence speed of distributed dual coordinate ascent in a tree network.
Bringing PDEs to JAX with forward and reverse modes automatic differentiation
Aug 31, 2023Partial differential equations (PDEs) are used to describe a variety of physical phenomena. Often these equations do not have analytical solutions and numerical approximations are used instead. One of the common methods to solve PDEs is the finite element method. Computing derivative information of the solution with respect to the input parameters is important in many tasks in scientific computing. We extend JAX automatic differentiation library with an interface to Firedrake finite element library. High-level symbolic representation of PDEs allows bypassing differentiating through low-level possibly many iterations of the underlying nonlinear solvers. Differentiating through Firedrake solvers is done using tangent-linear and adjoint equations. This enables the efficient composition of finite element solvers with arbitrary differentiable programs. The code is available at github.com/IvanYashchuk/jax-firedrake.
Towards Spontaneous Style Modeling with Semi-supervised Pre-training for Conversational Text-to-Speech Synthesis
Aug 31, 2023The spontaneous behavior that often occurs in conversations makes speech more human-like compared to reading-style. However, synthesizing spontaneous-style speech is challenging due to the lack of high-quality spontaneous datasets and the high cost of labeling spontaneous behavior. In this paper, we propose a semi-supervised pre-training method to increase the amount of spontaneous-style speech and spontaneous behavioral labels. In the process of semi-supervised learning, both text and speech information are considered for detecting spontaneous behaviors labels in speech. Moreover, a linguistic-aware encoder is used to model the relationship between each sentence in the conversation. Experimental results indicate that our proposed method achieves superior expressive speech synthesis performance with the ability to model spontaneous behavior in spontaneous-style speech and predict reasonable spontaneous behavior from text.
PhonMatchNet: Phoneme-Guided Zero-Shot Keyword Spotting for User-Defined Keywords
Aug 31, 2023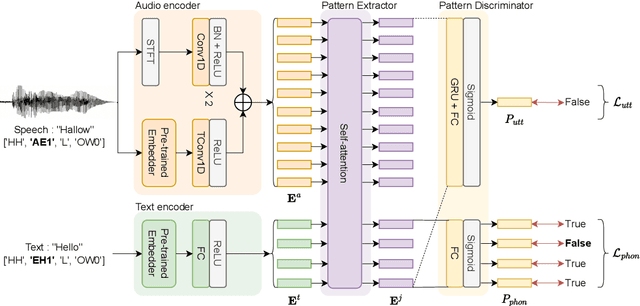

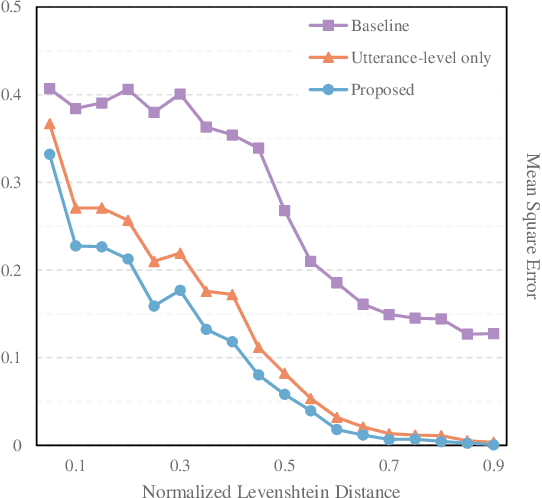
This study presents a novel zero-shot user-defined keyword spotting model that utilizes the audio-phoneme relationship of the keyword to improve performance. Unlike the previous approach that estimates at utterance level, we use both utterance and phoneme level information. Our proposed method comprises a two-stream speech encoder architecture, self-attention-based pattern extractor, and phoneme-level detection loss for high performance in various pronunciation environments. Based on experimental results, our proposed model outperforms the baseline model and achieves competitive performance compared with full-shot keyword spotting models. Our proposed model significantly improves the EER and AUC across all datasets, including familiar words, proper nouns, and indistinguishable pronunciations, with an average relative improvement of 67% and 80%, respectively. The implementation code of our proposed model is available at https://github.com/ncsoft/PhonMatchNet.