 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pure Monte Carlo Counterfactual Regret Minimization
Sep 04, 2023
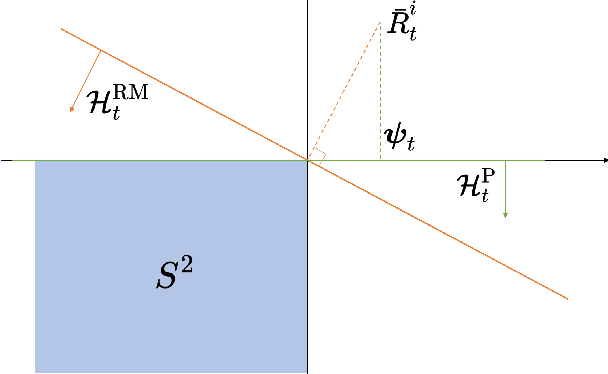
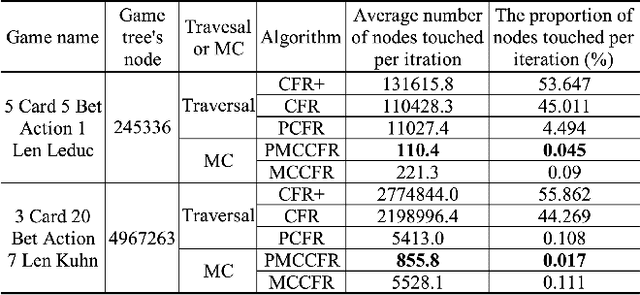
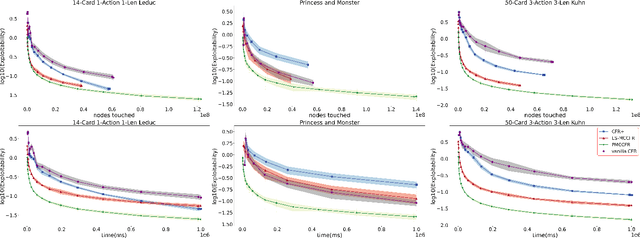
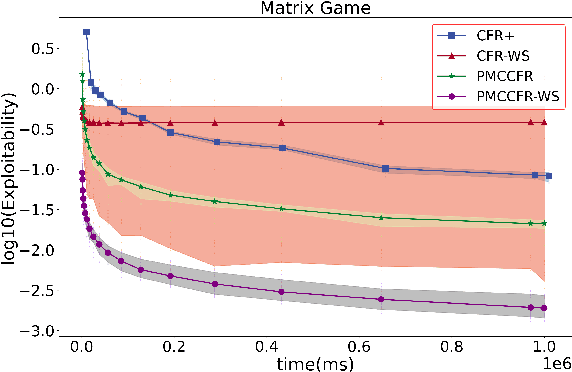
Counterfactual Regret Minimization (CFR) and its variants are the best algorithms so far for solving large-scale incomplete information games. Building upon CFR, this paper proposes a new algorithm named Pure CFR (PCFR) for achieving better performance. PCFR can be seen as a combination of CFR and Fictitious Play (FP), inheriting the concept of counterfactual regret (value) from CFR, and using the best response strategy instead of the regret matching strategy for the next iteration. Our theoretical proof that PCFR can achieve Blackwell approachability enables PCFR's ability to combine with any CFR variant including Monte Carlo CFR (MCCFR). The resultant Pure MCCFR (PMCCFR) can significantly reduce time and space complexity. Particularly, the convergence speed of PMCCFR is at least three times more than that of MCCFR. In addition, since PMCCFR does not pass through the path of strictly dominated strategies, we developed a new warm-start algorithm inspired by the strictly dominated strategies elimination method. Consequently, the PMCCFR with new warm start algorithm can converge by two orders of magnitude faster than the CFR+ algorithm.
Design of Recognition and Evaluation System for Table Tennis Players' Motor Skills Based on Artificial Intelligence
Sep 04, 2023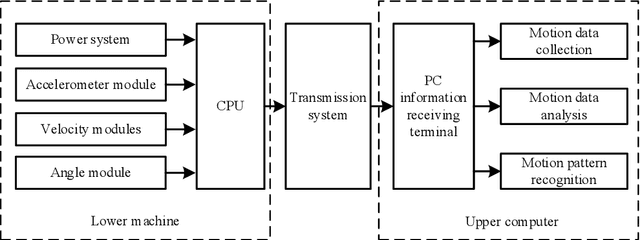
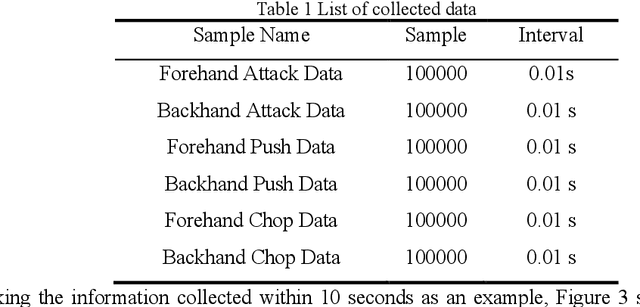


With the rapid development of electronic science and technology, the research on wearable devices is constantly updated, but for now, it is not comprehensive for wearable devices to recognize and analyze the movement of specific sports. Based on this, this paper improves wearable devices of table tennis sport, and realizes the pattern recognition and evaluation of table tennis players' motor skills through artificial intelligence. Firstly, a device is designed to collect the movement information of table tennis players and the actual movement data is processed. Secondly, a sliding window is made to divide the collected motion data into a characteristic database of six table tennis benchmark movements. Thirdly, motion features were constructed based on feature engineering, and motor skills were identified for different models after dimensionality reduction. Finally, the hierarchical evaluation system of motor skills is established with the loss functions of different evaluation indexes. The results show that in the recognition of table tennis players' motor skills, the feature-based BP neural network proposed in this paper has higher recognition accuracy and stronger generalization ability than the traditional convolutional neural network.
Evaluating Explanation Methods for Multivariate Time Series Classification
Sep 07, 2023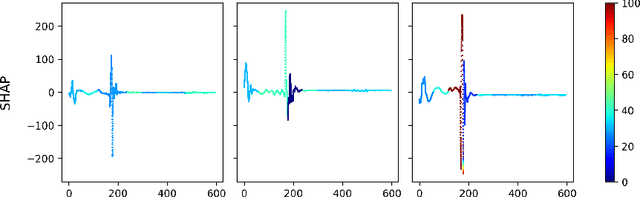

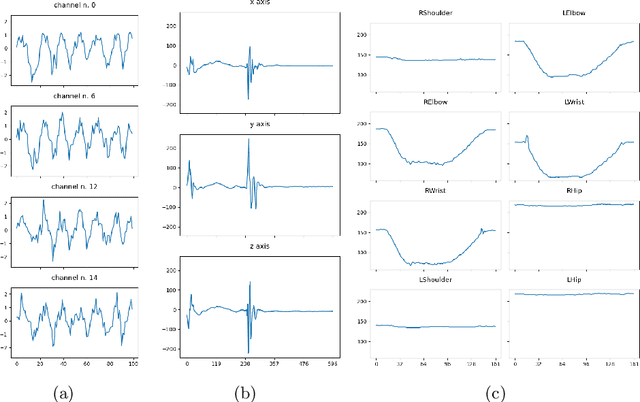
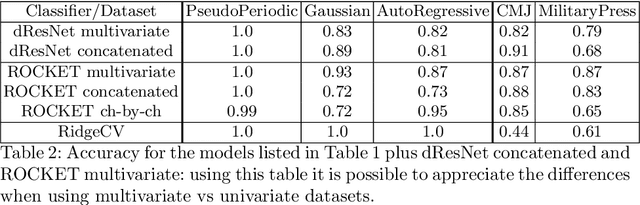
Multivariate time series classification is an important computational task arising in applications where data is recorded over time and over multiple channels. For example, a smartwatch can record the acceleration and orientation of a person's motion, and these signals are recorded as multivariate time series. We can classify this data to understand and predict human movement and various properties such as fitness levels. In many applications classification alone is not enough, we often need to classify but also understand what the model learns (e.g., why was a prediction given, based on what information in the data). The main focus of this paper is on analysing and evaluating explanation methods tailored to Multivariate Time Series Classification (MTSC). We focus on saliency-based explanation methods that can point out the most relevant channels and time series points for the classification decision. We analyse two popular and accurate multivariate time series classifiers, ROCKET and dResNet, as well as two popular explanation methods, SHAP and dCAM. We study these methods on 3 synthetic datasets and 2 real-world datasets and provide a quantitative and qualitative analysis of the explanations provided. We find that flattening the multivariate datasets by concatenating the channels works as well as using multivariate classifiers directly and adaptations of SHAP for MTSC work quite well. Additionally, we also find that the popular synthetic datasets we used are not suitable for time series analysis.
Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalized Stylization
Sep 07, 2023
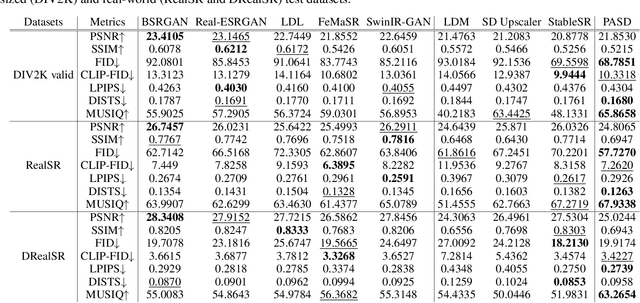
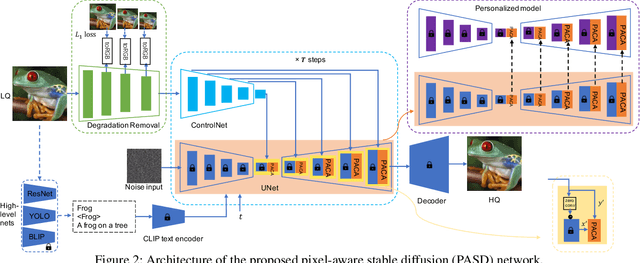
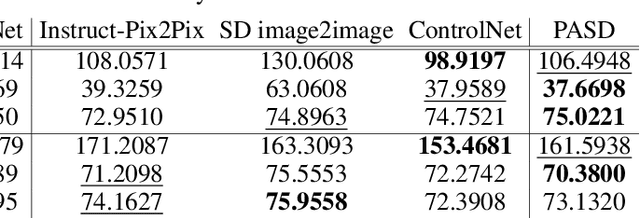
Realistic image super-resolution (Real-ISR) aims to reproduce perceptually realistic image details from a low-quality input. The commonly used adversarial training based Real-ISR methods often introduce unnatural visual artifacts and fail to generate realistic textures for natural scene images. The recently developed generative stable diffusion models provide a potential solution to Real-ISR with pre-learned strong image priors. However, the existing methods along this line either fail to keep faithful pixel-wise image structures or resort to extra skipped connections to reproduce details, which requires additional training in image space and limits their extension to other related tasks in latent space such as image stylization. In this work, we propose a pixel-aware stable diffusion (PASD) network to achieve robust Real-ISR as well as personalized stylization. In specific, a pixel-aware cross attention module is introduced to enable diffusion models perceiving image local structures in pixel-wise level, while a degradation removal module is used to extract degradation insensitive features to guide the diffusion process together with image high level information. By simply replacing the base diffusion model with a personalized one, our method can generate diverse stylized images without the need to collect pairwise training data. PASD can be easily integrated into existing diffusion models such as Stable Diffusion. Experiments on Real-ISR and personalized stylization demonstrate the effectiveness of our proposed approach. The source code and models can be found at \url{https://github.com/yangxy/PASD}.
Evaluating ChatGPT as a Recommender System: A Rigorous Approach
Sep 07, 2023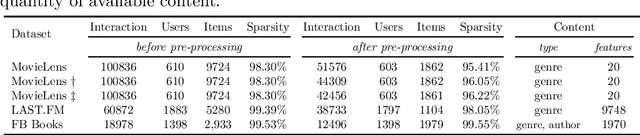
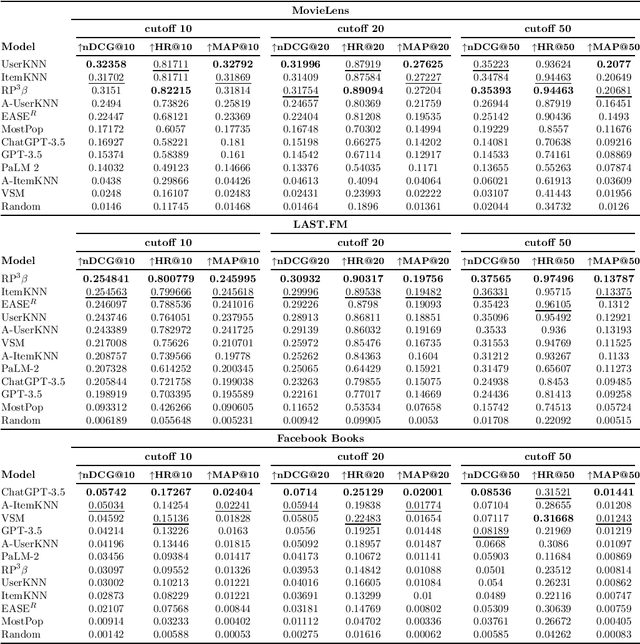
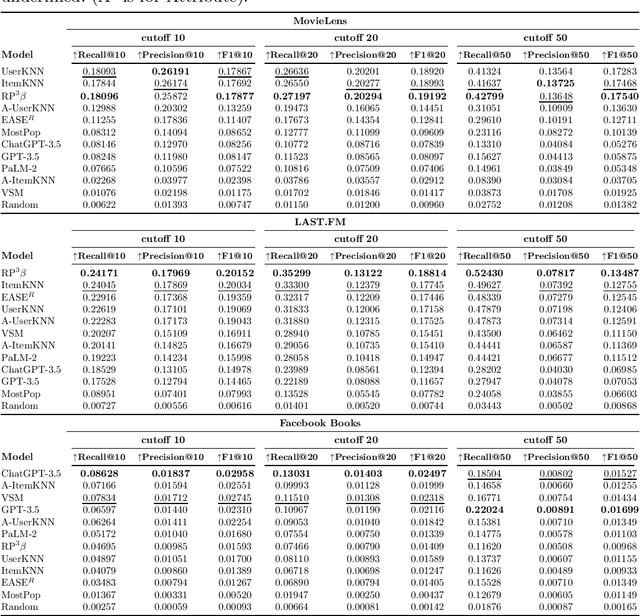
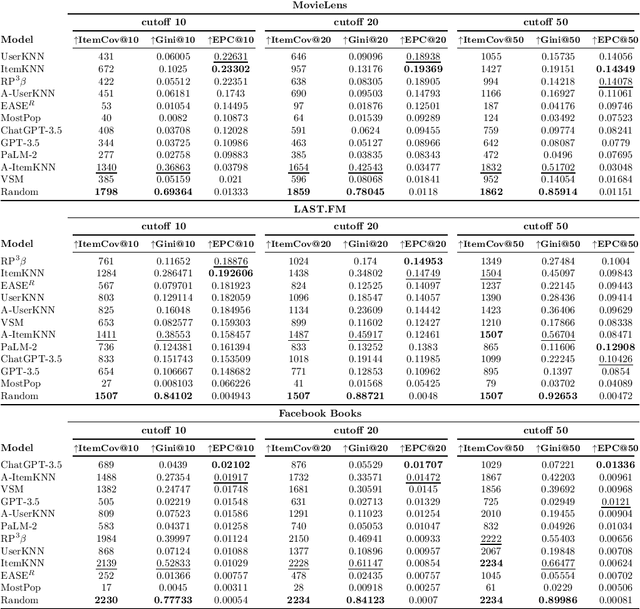
Recent popularity surrounds large AI language models due to their impressive natural language capabilities. They contribute significantly to language-related tasks, including prompt-based learning, making them valuable for various specific tasks. This approach unlocks their full potential, enhancing precision and generalization. Research communities are actively exploring their applications, with ChatGPT receiving recognition. Despite extensive research on large language models, their potential in recommendation scenarios still needs to be explored. This study aims to fill this gap by investigating ChatGPT's capabilities as a zero-shot recommender system. Our goals include evaluating its ability to use user preferences for recommendations, reordering existing recommendation lists, leveraging information from similar users, and handling cold-start situations. We assess ChatGPT's performance through comprehensive experiments using three datasets (MovieLens Small, Last.FM, and Facebook Book). We compare ChatGPT's performance against standard recommendation algorithms and other large language models, such as GPT-3.5 and PaLM-2. To measure recommendation effectiveness, we employ widely-used evaluation metrics like Mean Average Precision (MAP), Recall, Precision, F1, normalized Discounted Cumulative Gain (nDCG), Item Coverage, Expected Popularity Complement (EPC), Average Coverage of Long Tail (ACLT), Average Recommendation Popularity (ARP), and Popularity-based Ranking-based Equal Opportunity (PopREO). Through thoroughly exploring ChatGPT's abilities in recommender systems, our study aims to contribute to the growing body of research on the versatility and potential applications of large language models. Our experiment code is available on the GitHub repository: https://github.com/sisinflab/Recommender-ChatGPT
Private Membership Aggregation
Sep 07, 2023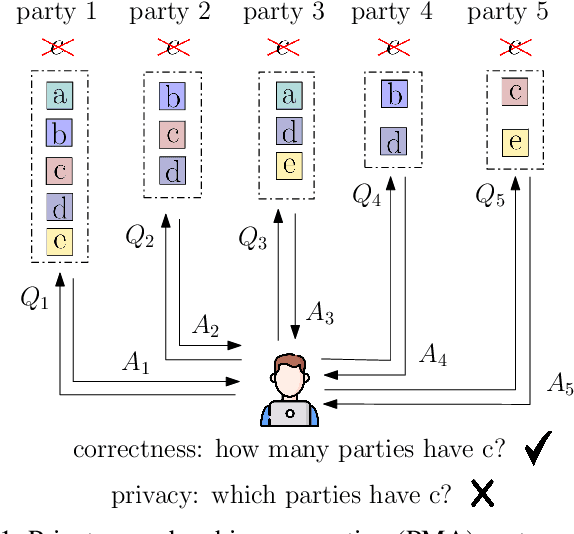
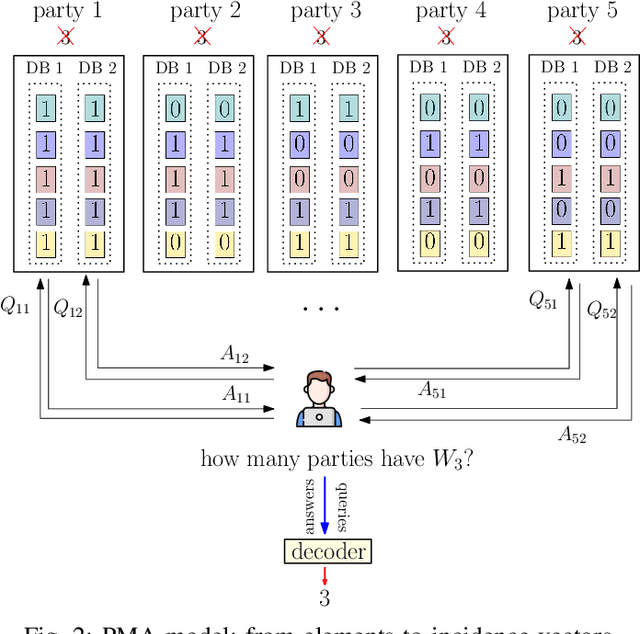
We consider the problem of private membership aggregation (PMA), in which a user counts the number of times a certain element is stored in a system of independent parties that store arbitrary sets of elements from a universal alphabet. The parties are not allowed to learn which element is being counted by the user. Further, neither the user nor the other parties are allowed to learn the stored elements of each party involved in the process. PMA is a generalization of the recently introduced problem of $K$ private set intersection ($K$-PSI). The $K$-PSI problem considers a set of $M$ parties storing arbitrary sets of elements, and a user who wants to determine if a certain element is repeated at least at $K$ parties out of the $M$ parties without learning which party has the required element and which party does not. To solve the general problem of PMA, we dissect it into four categories based on the privacy requirement and the collusions among databases/parties. We map these problems into equivalent private information retrieval (PIR) problems. We propose achievable schemes for each of the four variants of the problem based on the concept of cross-subspace alignment (CSA). The proposed schemes achieve \emph{linear} communication complexity as opposed to the state-of-the-art $K$-PSI scheme that requires \emph{exponential} complexity even though our PMA problems contain more security and privacy constraints.
Enhancing Sample Utilization through Sample Adaptive Augmentation in Semi-Supervised Learning
Sep 07, 2023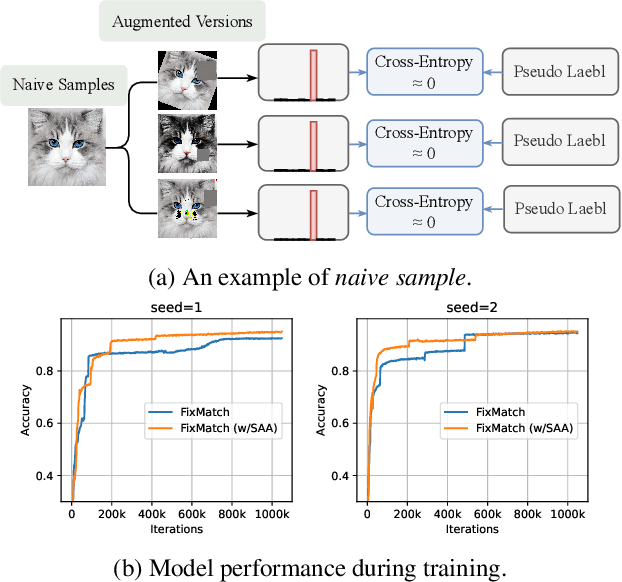
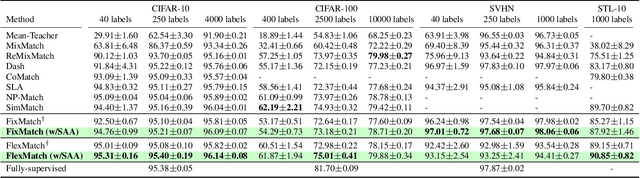
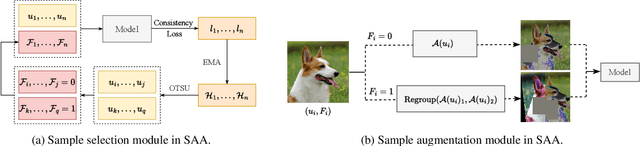
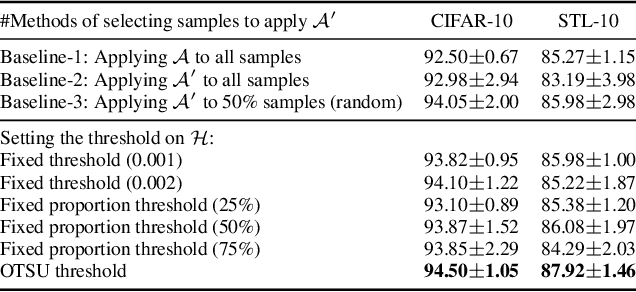
In semi-supervised learning, unlabeled samples can be utilized through augmentation and consistency regularization. However, we observed certain samples, even undergoing strong augmentation, are still correctly classified with high confidence, resulting in a loss close to zero. It indicates that these samples have been already learned well and do not provide any additional optimization benefits to the model. We refer to these samples as ``naive samples". Unfortunately, existing SSL models overlook the characteristics of naive samples, and they just apply the same learning strategy to all samples. To further optimize the SSL model, we emphasize the importance of giving attention to naive samples and augmenting them in a more diverse manner. Sample adaptive augmentation (SAA) is proposed for this stated purpose and consists of two modules: 1) sample selection module; 2) sample augmentation module. Specifically, the sample selection module picks out {naive samples} based on historical training information at each epoch, then the naive samples will be augmented in a more diverse manner in the sample augmentation module. Thanks to the extreme ease of implementation of the above modules, SAA is advantageous for being simple and lightweight. We add SAA on top of FixMatch and FlexMatch respectively, and experiments demonstrate SAA can significantly improve the models. For example, SAA helped improve the accuracy of FixMatch from 92.50% to 94.76% and that of FlexMatch from 95.01% to 95.31% on CIFAR-10 with 40 labels.
* Accepted as International Conference on Computer Vision (ICCV) 2023
MS-UNet-v2: Adaptive Denoising Method and Training Strategy for Medical Image Segmentation with Small Training Data
Sep 07, 2023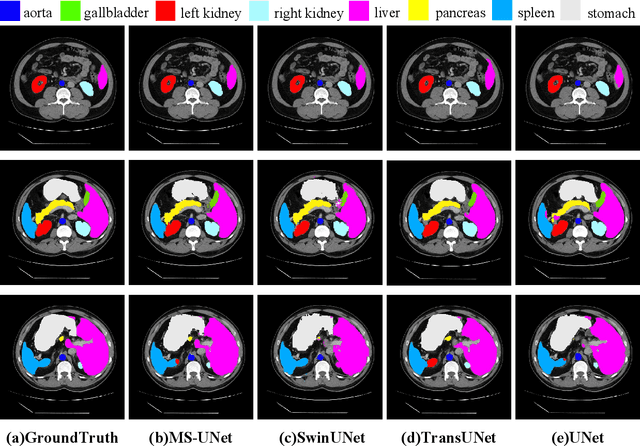
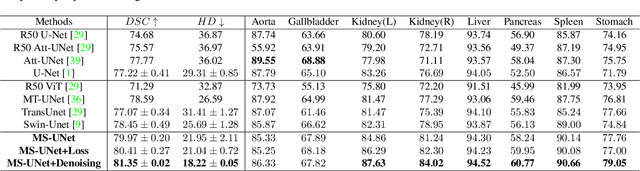
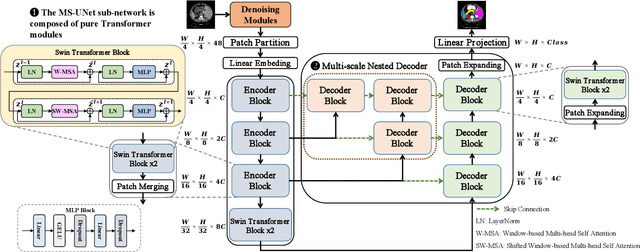

Models based on U-like structures have improved the performance of medical image segmentation. However, the single-layer decoder structure of U-Net is too "thin" to exploit enough information, resulting in large semantic differences between the encoder and decoder parts. Things get worse if the number of training sets of data is not sufficiently large, which is common in medical image processing tasks where annotated data are more difficult to obtain than other tasks. Based on this observation, we propose a novel U-Net model named MS-UNet for the medical image segmentation task in this study. Instead of the single-layer U-Net decoder structure used in Swin-UNet and TransUnet, we specifically design a multi-scale nested decoder based on the Swin Transformer for U-Net. The proposed multi-scale nested decoder structure allows the feature mapping between the decoder and encoder to be semantically closer, thus enabling the network to learn more detailed features. In addition, we propose a novel edge loss and a plug-and-play fine-tuning Denoising module, which not only effectively improves the segmentation performance of MS-UNet, but could also be applied to other models individually. Experimental results show that MS-UNet could effectively improve the network performance with more efficient feature learning capability and exhibit more advanced performance, especially in the extreme case with a small amount of training data, and the proposed Edge loss and Denoising module could significantly enhance the segmentation performance of MS-UNet.
S-Adapter: Generalizing Vision Transformer for Face Anti-Spoofing with Statistical Tokens
Sep 07, 2023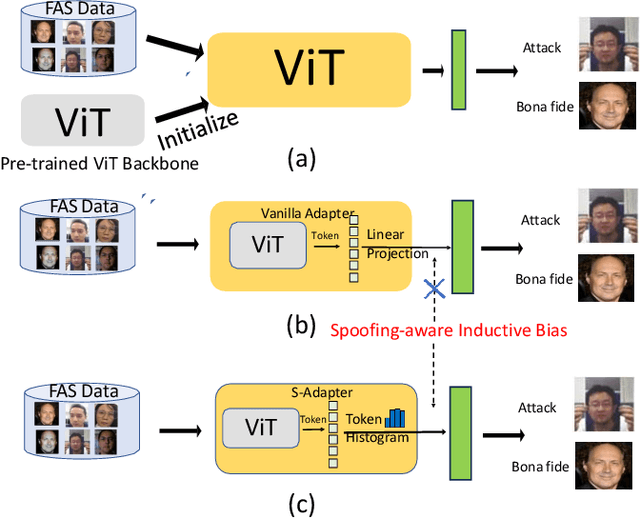
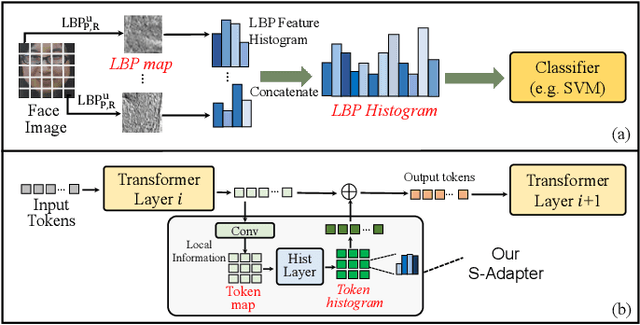
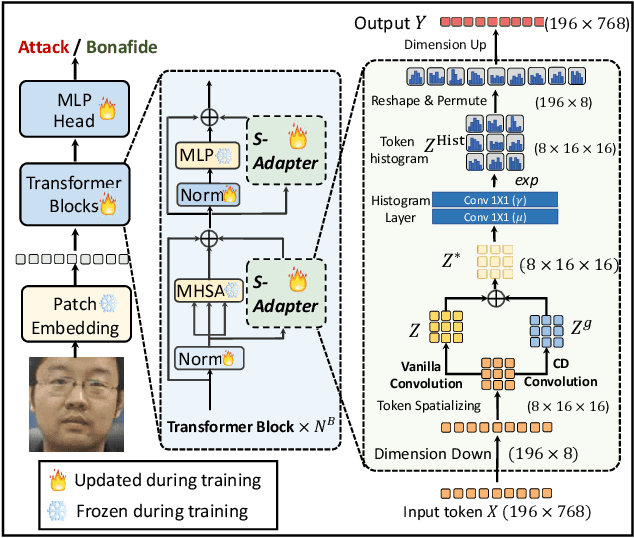
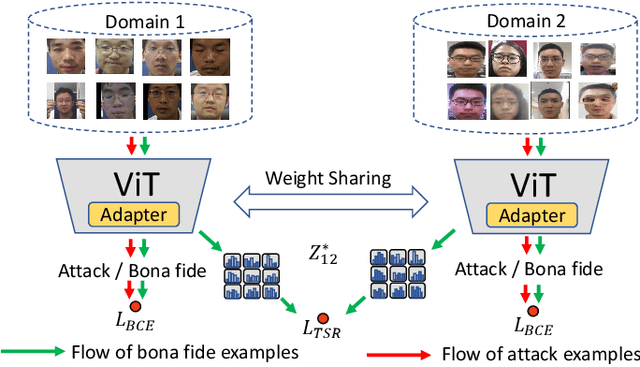
Face Anti-Spoofing (FAS) aims to detect malicious attempts to invade a face recognition system by presenting spoofed faces. State-of-the-art FAS techniques predominantly rely on deep learning models but their cross-domain generalization capabilities are often hindered by the domain shift problem, which arises due to different distributions between training and testing data. In this study, we develop a generalized FAS method under the Efficient Parameter Transfer Learning (EPTL) paradigm, where we adapt the pre-trained Vision Transformer models for the FAS task. During training, the adapter modules are inserted into the pre-trained ViT model, and the adapters are updated while other pre-trained parameters remain fixed. We find the limitations of previous vanilla adapters in that they are based on linear layers, which lack a spoofing-aware inductive bias and thus restrict the cross-domain generalization. To address this limitation and achieve cross-domain generalized FAS, we propose a novel Statistical Adapter (S-Adapter) that gathers local discriminative and statistical information from localized token histograms. To further improve the generalization of the statistical tokens, we propose a novel Token Style Regularization (TSR), which aims to reduce domain style variance by regularizing Gram matrices extracted from tokens across different domains. Our experimental results demonstrate that our proposed S-Adapter and TSR provide significant benefits in both zero-shot and few-shot cross-domain testing, outperforming state-of-the-art methods on several benchmark tests. We will release the source code upon acceptance.
Face Encryption via Frequency-Restricted Identity-Agnostic Attacks
Aug 25, 2023
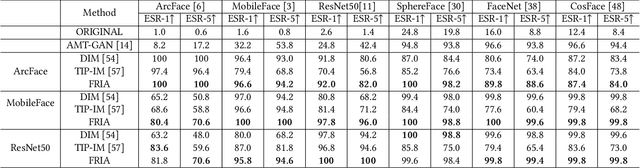
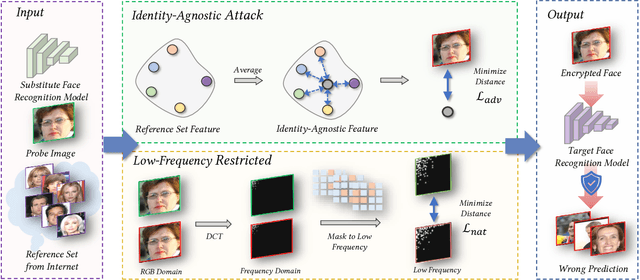
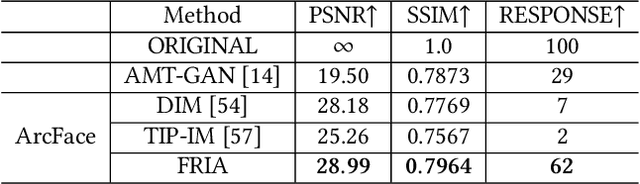
Billions of people are sharing their daily live images on social media everyday. However, malicious collectors use deep face recognition systems to easily steal their biometric information (e.g., faces) from these images. Some studies are being conducted to generate encrypted face photos using adversarial attacks by introducing imperceptible perturbations to reduce face information leakage. However, existing studies need stronger black-box scenario feasibility and more natural visual appearances, which challenge the feasibility of privacy protection. To address these problems, we propose a frequency-restricted identity-agnostic (FRIA) framework to encrypt face images from unauthorized face recognition without access to personal information. As for the weak black-box scenario feasibility, we obverse that representations of the average feature in multiple face recognition models are similar, thus we propose to utilize the average feature via the crawled dataset from the Internet as the target to guide the generation, which is also agnostic to identities of unknown face recognition systems; in nature, the low-frequency perturbations are more visually perceptible by the human vision system. Inspired by this, we restrict the perturbation in the low-frequency facial regions by discrete cosine transform to achieve the visual naturalness guarantee. Extensive experiments on several face recognition models demonstrate that our FRIA outperforms other state-of-the-art methods in generating more natural encrypted faces while attaining high black-box attack success rates of 96%. In addition, we validate the efficacy of FRIA using real-world black-box commercial API, which reveals the potential of FRIA in practice. Our codes can be found in https://github.com/XinDong10/FRIA.