 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Non-parametric Ensemble Empirical Mode Decomposition for extracting weak features to identify bearing defects
Sep 12, 2023
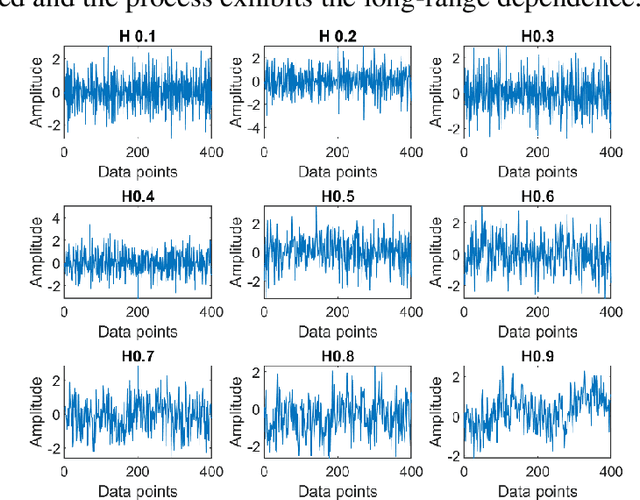
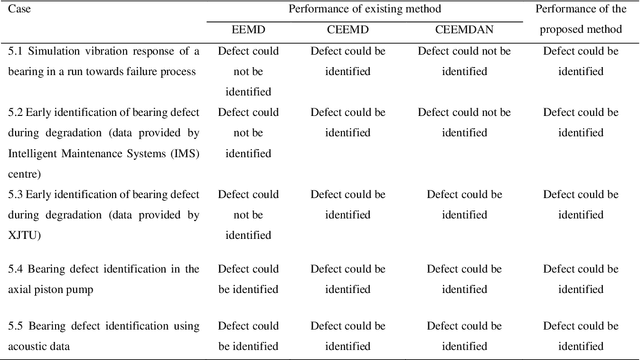
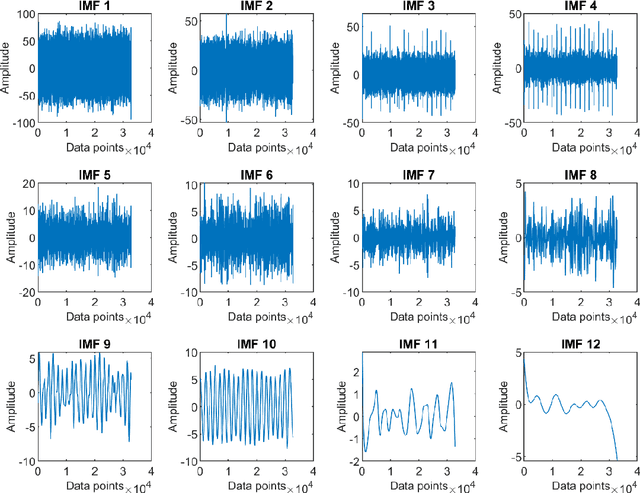
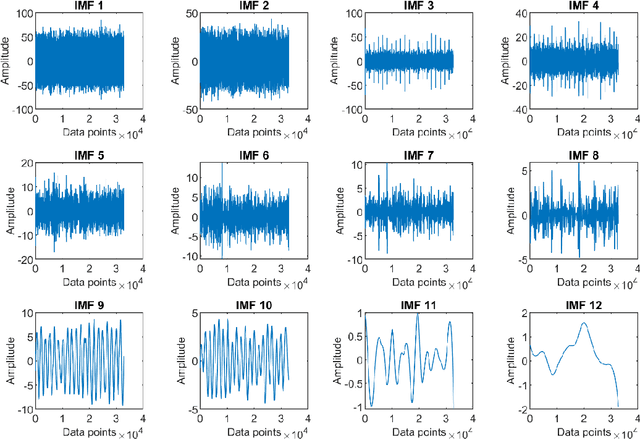
A non-parametric complementary ensemble empirical mode decomposition (NPCEEMD) is proposed for identifying bearing defects using weak features. NPCEEMD is non-parametric because, unlike existing decomposition methods such as ensemble empirical mode decomposition, it does not require defining the ideal SNR of noise and the number of ensembles, every time while processing the signals. The simulation results show that mode mixing in NPCEEMD is less than the existing decomposition methods. After conducting in-depth simulation analysis, the proposed method is applied to experimental data. The proposed NPCEEMD method works in following steps. First raw signal is obtained. Second, the obtained signal is decomposed. Then, the mutual information (MI) of the raw signal with NPCEEMD-generated IMFs is computed. Further IMFs with MI above 0.1 are selected and combined to form a resulting signal. Finally, envelope spectrum of resulting signal is computed to confirm the presence of defect.
A Survey on Multi-Behavior Sequential Recommendation
Aug 30, 2023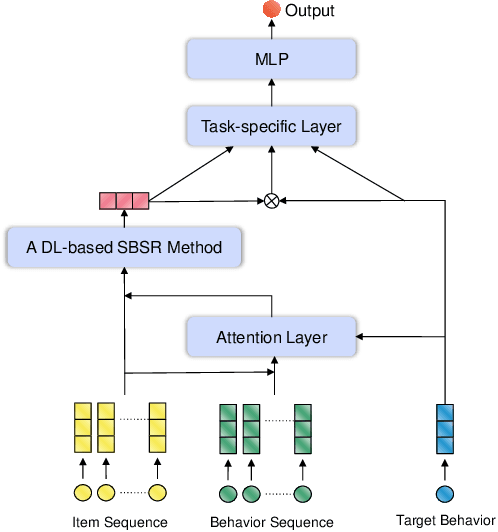
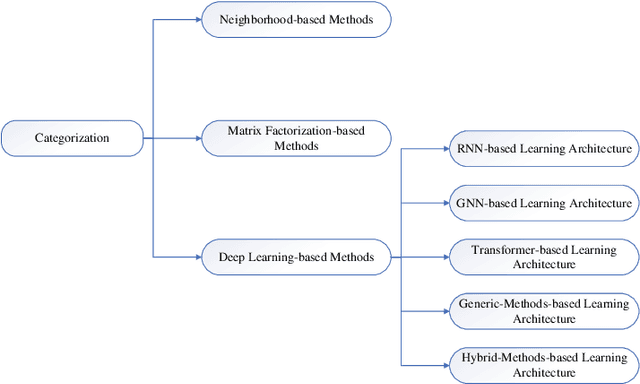

Recommender systems is set up to address the issue of information overload in traditional information retrieval systems, which is focused on recommending information that is of most interest to users from massive information. Generally, there is a sequential nature and heterogeneity to the behavior of a person interacting with a system, leading to the proposal of multi-behavior sequential recommendation (MBSR). MBSR is a relatively new and worthy direction for in-depth research, which can achieve state-of-the-art recommendation through suitable modeling, and some related works have been proposed. This survey aims to shed light on the MBSR problem. Firstly, we introduce MBSR in detail, including its problem definition, application scenarios and challenges faced. Secondly, we detail the classification of MBSR, including neighborhood-based methods, matrix factorization-based methods and deep learning-based methods, where we further classify the deep learning-based methods into different learning architectures based on RNN, GNN, Transformer, and generic architectures as well as architectures that integrate hybrid techniques. In each method, we present related works based on the data perspective and the modeling perspective, as well as analyze the strengths, weaknesses and features of these works. Finally, we discuss some promising future research directions to address the challenges and improve the current status of MBSR.
Semi-Supervised Semantic Depth Estimation using Symbiotic Transformer and NearFarMix Augmentation
Aug 28, 2023In computer vision, depth estimation is crucial for domains like robotics, autonomous vehicles, augmented reality, and virtual reality. Integrating semantics with depth enhances scene understanding through reciprocal information sharing. However, the scarcity of semantic information in datasets poses challenges. Existing convolutional approaches with limited local receptive fields hinder the full utilization of the symbiotic potential between depth and semantics. This paper introduces a dataset-invariant semi-supervised strategy to address the scarcity of semantic information. It proposes the Depth Semantics Symbiosis module, leveraging the Symbiotic Transformer for achieving comprehensive mutual awareness by information exchange within both local and global contexts. Additionally, a novel augmentation, NearFarMix is introduced to combat overfitting and compensate both depth-semantic tasks by strategically merging regions from two images, generating diverse and structurally consistent samples with enhanced control. Extensive experiments on NYU-Depth-V2 and KITTI datasets demonstrate the superiority of our proposed techniques in indoor and outdoor environments.
Research on self-cross transformer model of point cloud change detecter
Sep 14, 2023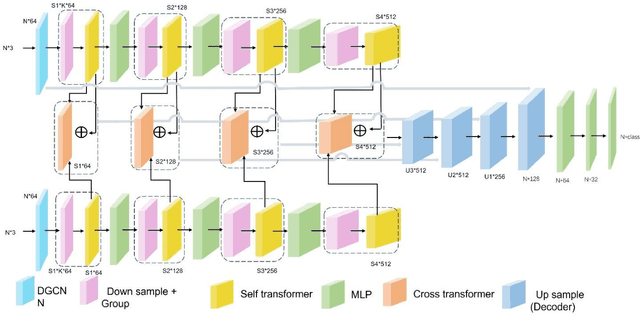

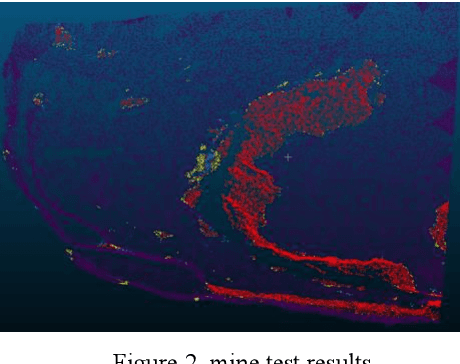
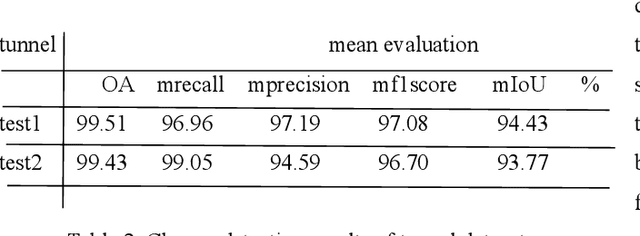
With the vigorous development of the urban construction industry, engineering deformation or changes often occur during the construction process. To combat this phenomenon, it is necessary to detect changes in order to detect construction loopholes in time, ensure the integrity of the project and reduce labor costs. Or the inconvenience and injuriousness of the road. In the study of change detection in 3D point clouds, researchers have published various research methods on 3D point clouds. Directly based on but mostly based ontraditional threshold distance methods (C2C, M3C2, M3C2-EP), and some are to convert 3D point clouds into DSM, which loses a lot of original information. Although deep learning is used in remote sensing methods, in terms of change detection of 3D point clouds, it is more converted into two-dimensional patches, and neural networks are rarely applied directly. We prefer that the network is given at the level of pixels or points. Variety. Therefore, in this article, our network builds a network for 3D point cloud change detection, and proposes a new module Cross transformer suitable for change detection. Simultaneously simulate tunneling data for change detection, and do test experiments with our network.
Semantic Adversarial Attacks via Diffusion Models
Sep 14, 2023Traditional adversarial attacks concentrate on manipulating clean examples in the pixel space by adding adversarial perturbations. By contrast, semantic adversarial attacks focus on changing semantic attributes of clean examples, such as color, context, and features, which are more feasible in the real world. In this paper, we propose a framework to quickly generate a semantic adversarial attack by leveraging recent diffusion models since semantic information is included in the latent space of well-trained diffusion models. Then there are two variants of this framework: 1) the Semantic Transformation (ST) approach fine-tunes the latent space of the generated image and/or the diffusion model itself; 2) the Latent Masking (LM) approach masks the latent space with another target image and local backpropagation-based interpretation methods. Additionally, the ST approach can be applied in either white-box or black-box settings. Extensive experiments are conducted on CelebA-HQ and AFHQ datasets, and our framework demonstrates great fidelity, generalizability, and transferability compared to other baselines. Our approaches achieve approximately 100% attack success rate in multiple settings with the best FID as 36.61. Code is available at https://github.com/steven202/semantic_adv_via_dm.
RecycleNet: Latent Feature Recycling Leads to Iterative Decision Refinement
Sep 14, 2023Despite the remarkable success of deep learning systems over the last decade, a key difference still remains between neural network and human decision-making: As humans, we cannot only form a decision on the spot, but also ponder, revisiting an initial guess from different angles, distilling relevant information, arriving at a better decision. Here, we propose RecycleNet, a latent feature recycling method, instilling the pondering capability for neural networks to refine initial decisions over a number of recycling steps, where outputs are fed back into earlier network layers in an iterative fashion. This approach makes minimal assumptions about the neural network architecture and thus can be implemented in a wide variety of contexts. Using medical image segmentation as the evaluation environment, we show that latent feature recycling enables the network to iteratively refine initial predictions even beyond the iterations seen during training, converging towards an improved decision. We evaluate this across a variety of segmentation benchmarks and show consistent improvements even compared with top-performing segmentation methods. This allows trading increased computation time for improved performance, which can be beneficial, especially for safety-critical applications.
M3-AUDIODEC: Multi-channel multi-speaker multi-spatial audio codec
Sep 14, 2023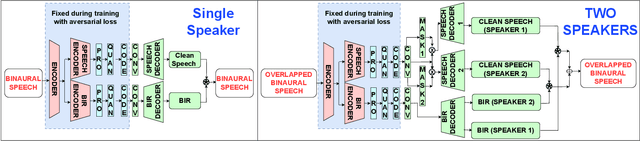

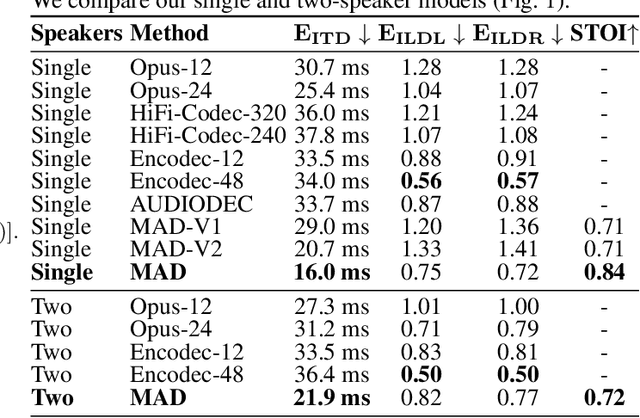
We introduce M3-AUDIODEC, an innovative neural spatial audio codec designed for efficient compression of multi-channel (binaural) speech in both single and multi-speaker scenarios, while retaining the spatial location information of each speaker. This model boasts versatility, allowing configuration and training tailored to a predetermined set of multi-channel, multi-speaker, and multi-spatial overlapping speech conditions. Key contributions are as follows: 1) Previous neural codecs are extended from single to multi-channel audios. 2) The ability of our proposed model to compress and decode for overlapping speech. 3) A groundbreaking architecture that compresses speech content and spatial cues separately, ensuring the preservation of each speaker's spatial context after decoding. 4) M3-AUDIODEC's proficiency in reducing the bandwidth for compressing two-channel speech by 48% when compared to individual binaural channel compression. Impressively, at a 12.6 kbps operation, it outperforms Opus at 24 kbps and AUDIODEC at 24 kbps by 37% and 52%, respectively. In our assessment, we employed speech enhancement and room acoustic metrics to ascertain the accuracy of clean speech and spatial cue estimates from M3-AUDIODEC. Audio demonstrations and source code are available online.
A DenseNet-based method for decoding auditory spatial attention with EEG
Sep 14, 2023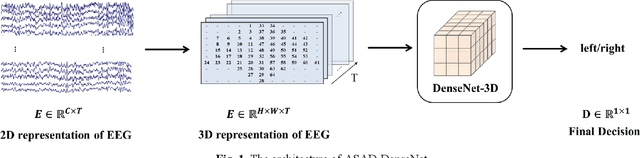
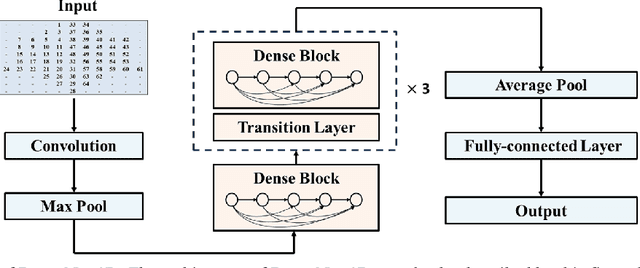
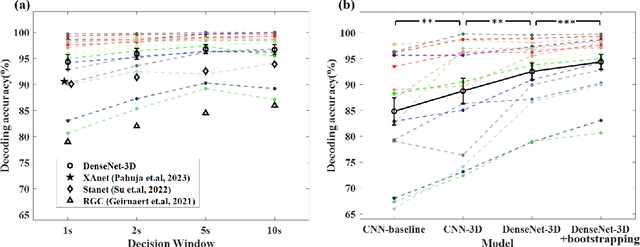
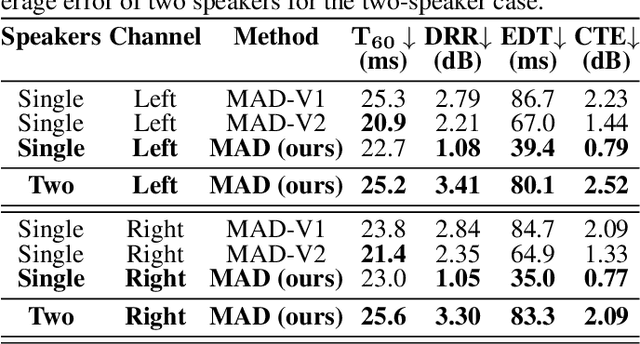
Auditory spatial attention detection (ASAD) aims to decode the attended spatial location with EEG in a multiple-speaker setting. ASAD methods are inspired by the brain lateralization of cortical neural responses during the processing of auditory spatial attention, and show promising performance for the task of auditory attention decoding (AAD) with neural recordings. In the previous ASAD methods, the spatial distribution of EEG electrodes is not fully exploited, which may limit the performance of these methods. In the present work, by transforming the original EEG channels into a two-dimensional (2D) spatial topological map, the EEG data is transformed into a three-dimensional (3D) arrangement containing spatial-temporal information. And then a 3D deep convolutional neural network (DenseNet-3D) is used to extract temporal and spatial features of the neural representation for the attended locations. The results show that the proposed method achieves higher decoding accuracy than the state-of-the-art (SOTA) method (94.4% compared to XANet's 90.6%) with 1-second decision window for the widely used KULeuven (KUL) dataset, and the code to implement our work is available on Github: https://github.com/xuxiran/ASAD_DenseNet
Usability Evaluation of Spoken Humanoid Embodied Conversational Agents in Mobile Serious Games
Sep 14, 2023This paper presents an empirical investigation of the extent to which spoken Humanoid Embodied Conversational Agents (HECAs) can foster usability in mobile serious game (MSG) applications. The aim of the research is to assess the impact of multiple agents and illusion of humanness on the quality of the interaction. The experiment investigates two styles of agent presentation: an agent of high human-likeness (HECA) and an agent of low human-likeness (text). The purpose of the experiment is to assess whether and how agents of high humanlikeness can evoke the illusion of humanness and affect usability. Agents of high human-likeness were designed by following the ECA design model that is a proposed guide for ECA development. The results of the experiment with 90 participants show that users prefer to interact with the HECAs. The difference between the two versions is statistically significant with a large effect size (d=1.01), with many of the participants justifying their choice by saying that the human-like characteristics of the HECA made the version more appealing. This research provides key information on the potential effect of HECAs on serious games, which can provide insight into the design of future mobile serious games.
Towards Safer Robot-Assisted Surgery: A Markerless Augmented Reality Framework
Sep 14, 2023Robot-assisted surgery is rapidly developing in the medical field, and the integration of augmented reality shows the potential of improving the surgeons' operation performance by providing more visual information. In this paper, we proposed a markerless augmented reality framework to enhance safety by avoiding intra-operative bleeding which is a high risk caused by the collision between the surgical instruments and the blood vessel. Advanced stereo reconstruction and segmentation networks are compared to find out the best combination to reconstruct the intra-operative blood vessel in the 3D space for the registration of the pre-operative model, and the minimum distance detection between the instruments and the blood vessel is implemented. A robot-assisted lymphadenectomy is simulated on the da Vinci Research Kit in a dry lab, and ten human subjects performed this operation to explore the usability of the proposed framework. The result shows that the augmented reality framework can help the users to avoid the dangerous collision between the instruments and the blood vessel while not introducing an extra load. It provides a flexible framework that integrates augmented reality into the medical robot platform to enhance safety during the operation.