 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PDE Discovery for Soft Sensors Using Coupled Physics-Informed Neural Network with Akaike's Information Criterion
Aug 11, 2023
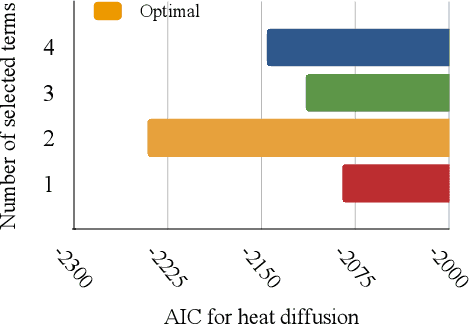
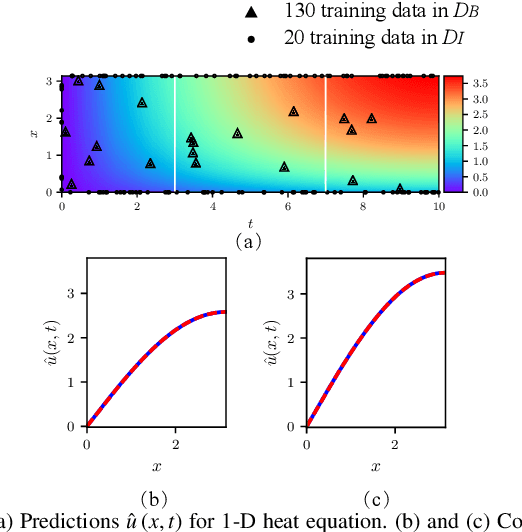
Soft sensors have been extensively used to monitor key variables using easy-to-measure variables and mathematical models. Partial differential equations (PDEs) are model candidates for soft sensors in industrial processes with spatiotemporal dependence. However, gaps often exist between idealized PDEs and practical situations. Discovering proper structures of PDEs, including the differential operators and source terms, can remedy the gaps. To this end, a coupled physics-informed neural network with Akaike's criterion information (CPINN-AIC) is proposed for PDE discovery of soft sensors. First, CPINN is adopted for obtaining solutions and source terms satisfying PDEs. Then, we propose a data-physics-hybrid loss function for training CPINN, in which undetermined combinations of differential operators are involved. Consequently, AIC is used to discover the proper combination of differential operators. Finally, the artificial and practical datasets are used to verify the feasibility and effectiveness of CPINN-AIC for soft sensors. The proposed CPINN-AIC is a data-driven method to discover proper PDE structures and neural network-based solutions for soft sensors.
Strength in Diversity: Multi-Branch Representation Learning for Vehicle Re-Identification
Oct 02, 2023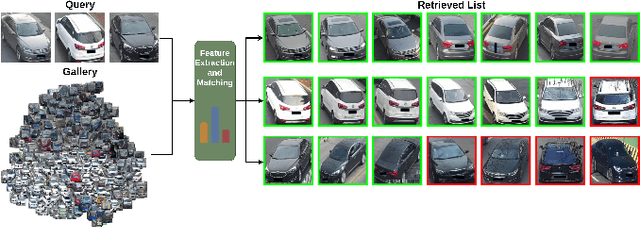
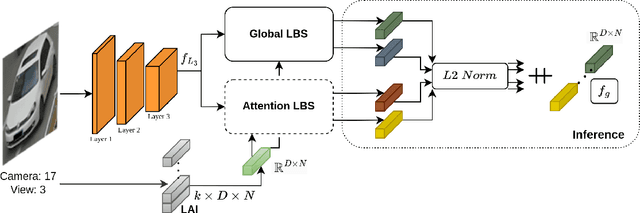
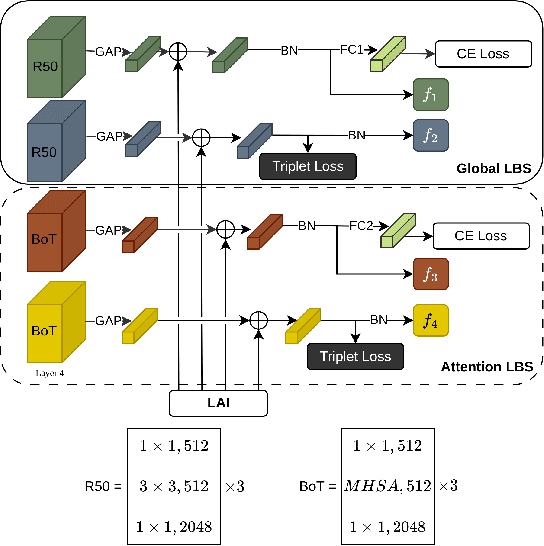
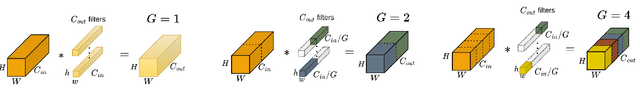
This paper presents an efficient and lightweight multi-branch deep architecture to improve vehicle re-identification (V-ReID). While most V-ReID work uses a combination of complex multi-branch architectures to extract robust and diversified embeddings towards re-identification, we advocate that simple and lightweight architectures can be designed to fulfill the Re-ID task without compromising performance. We propose a combination of Grouped-convolution and Loss-Branch-Split strategies to design a multi-branch architecture that improve feature diversity and feature discriminability. We combine a ResNet50 global branch architecture with a BotNet self-attention branch architecture, both designed within a Loss-Branch-Split (LBS) strategy. We argue that specialized loss-branch-splitting helps to improve re-identification tasks by generating specialized re-identification features. A lightweight solution using grouped convolution is also proposed to mimic the learning of loss-splitting into multiple embeddings while significantly reducing the model size. In addition, we designed an improved solution to leverage additional metadata, such as camera ID and pose information, that uses 97% less parameters, further improving re-identification performance. In comparison to state-of-the-art (SoTA) methods, our approach outperforms competing solutions in Veri-776 by achieving 85.6% mAP and 97.7% CMC1 and obtains competitive results in Veri-Wild with 88.1% mAP and 96.3% CMC1. Overall, our work provides important insights into improving vehicle re-identification and presents a strong basis for other retrieval tasks. Our code is available at the https://github.com/videturfortuna/vehicle_reid_itsc2023.
Estimating and Implementing Conventional Fairness Metrics With Probabilistic Protected Features
Oct 02, 2023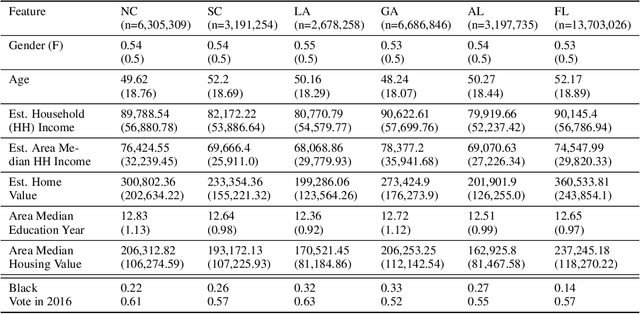
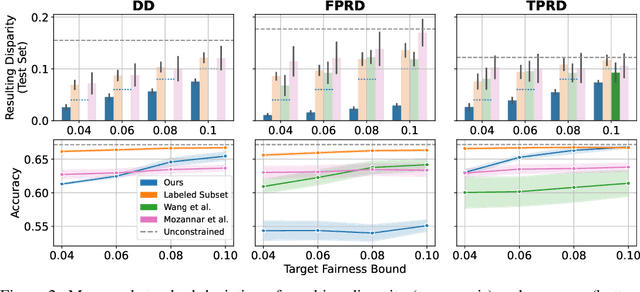
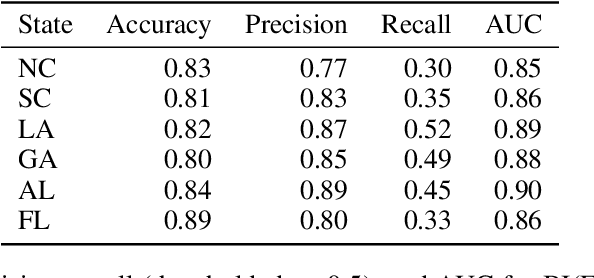
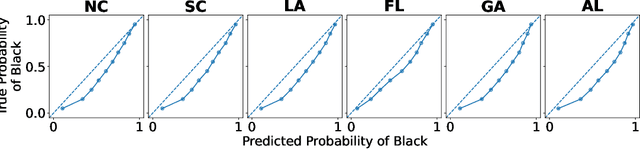
The vast majority of techniques to train fair models require access to the protected attribute (e.g., race, gender), either at train time or in production. However, in many important applications this protected attribute is largely unavailable. In this paper, we develop methods for measuring and reducing fairness violations in a setting with limited access to protected attribute labels. Specifically, we assume access to protected attribute labels on a small subset of the dataset of interest, but only probabilistic estimates of protected attribute labels (e.g., via Bayesian Improved Surname Geocoding) for the rest of the dataset. With this setting in mind, we propose a method to estimate bounds on common fairness metrics for an existing model, as well as a method for training a model to limit fairness violations by solving a constrained non-convex optimization problem. Unlike similar existing approaches, our methods take advantage of contextual information -- specifically, the relationships between a model's predictions and the probabilistic prediction of protected attributes, given the true protected attribute, and vice versa -- to provide tighter bounds on the true disparity. We provide an empirical illustration of our methods using voting data. First, we show our measurement method can bound the true disparity up to 5.5x tighter than previous methods in these applications. Then, we demonstrate that our training technique effectively reduces disparity while incurring lesser fairness-accuracy trade-offs than other fair optimization methods with limited access to protected attributes.
RF-ULM: Deep Learning for Radio-Frequency Ultrasound Localization Microscopy
Oct 02, 2023In Ultrasound Localization Microscopy (ULM), achieving high-resolution images relies on the precise localization of contrast agent particles across consecutive beamformed frames. However, our study uncovers an enormous potential: The process of delay-and-sum beamforming leads to an irreversible reduction of Radio-Frequency (RF) data, while its implications for localization remain largely unexplored. The rich contextual information embedded within RF wavefronts, including their hyperbolic shape and phase, offers great promise for guiding Deep Neural Networks (DNNs) in challenging localization scenarios. To fully exploit this data, we propose to directly localize scatterers in RF signals. Our approach involves a custom super-resolution DNN using learned feature channel shuffling and a novel semi-global convolutional sampling block tailored for reliable and accurate localization in RF input data. Additionally, we introduce a geometric point transformation that facilitates seamless mapping between B-mode and RF spaces. To validate the effectiveness of our method and understand the impact of beamforming, we conduct an extensive comparison with State-Of-The-Art (SOTA) techniques in ULM. We present the inaugural in vivo results from an RF-trained DNN, highlighting its real-world practicality. Our findings show that RF-ULM bridges the domain gap between synthetic and real datasets, offering a considerable advantage in terms of precision and complexity. To enable the broader research community to benefit from our findings, our code and the associated SOTA methods are made available at https://github.com/hahnec/rf-ulm.
NEUCORE: Neural Concept Reasoning for Composed Image Retrieval
Oct 02, 2023Composed image retrieval which combines a reference image and a text modifier to identify the desired target image is a challenging task, and requires the model to comprehend both vision and language modalities and their interactions. Existing approaches focus on holistic multi-modal interaction modeling, and ignore the composed and complimentary property between the reference image and text modifier. In order to better utilize the complementarity of multi-modal inputs for effective information fusion and retrieval, we move the multi-modal understanding to fine-granularity at concept-level, and learn the multi-modal concept alignment to identify the visual location in reference or target images corresponding to text modifier. Toward the end, we propose a NEUral COncept REasoning (NEUCORE) model which incorporates multi-modal concept alignment and progressive multimodal fusion over aligned concepts. Specifically, considering that text modifier may refer to semantic concepts not existing in the reference image and requiring to be added into the target image, we learn the multi-modal concept alignment between the text modifier and the concatenation of reference and target images, under multiple-instance learning framework with image and sentence level weak supervision. Furthermore, based on aligned concepts, to form discriminative fusion features of the input modalities for accurate target image retrieval, we propose a progressive fusion strategy with unified execution architecture instantiated by the attended language semantic concepts. Our proposed approach is evaluated on three datasets and achieves state-of-the-art results.
Optimal Estimator for Linear Regression with Shuffled Labels
Oct 02, 2023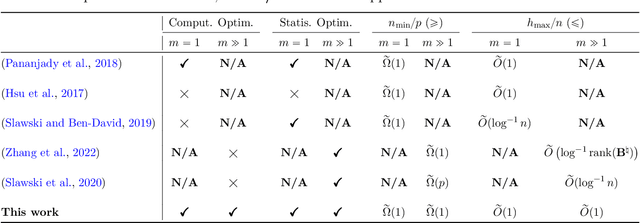
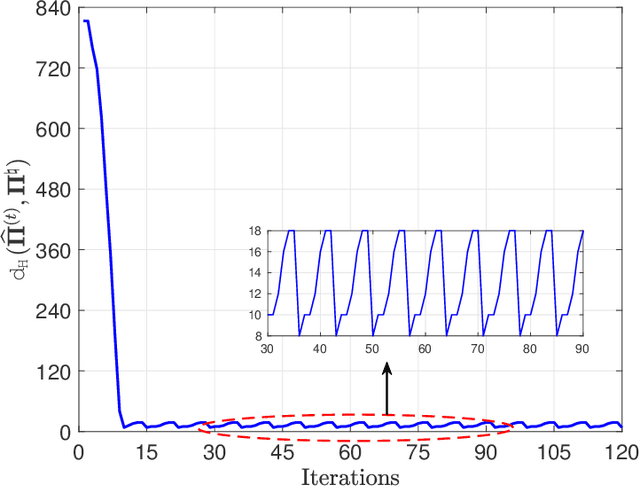
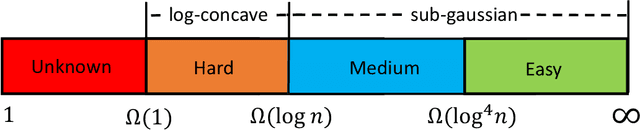
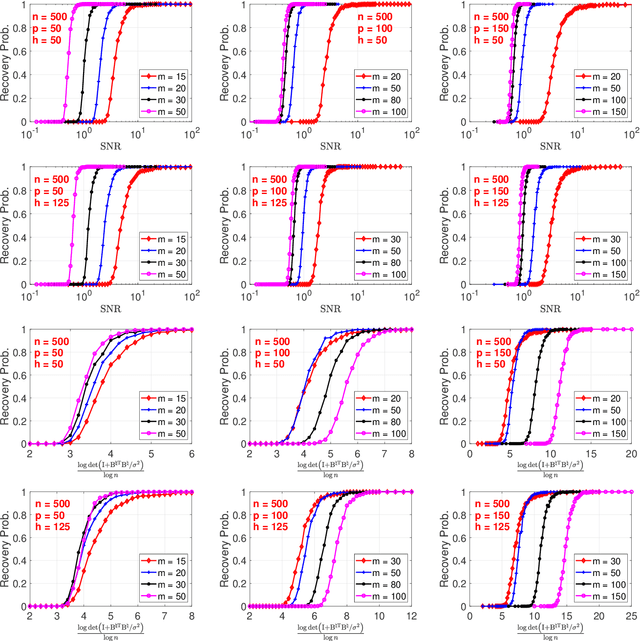
This paper considers the task of linear regression with shuffled labels, i.e., $\mathbf Y = \mathbf \Pi \mathbf X \mathbf B + \mathbf W$, where $\mathbf Y \in \mathbb R^{n\times m}, \mathbf Pi \in \mathbb R^{n\times n}, \mathbf X\in \mathbb R^{n\times p}, \mathbf B \in \mathbb R^{p\times m}$, and $\mathbf W\in \mathbb R^{n\times m}$, respectively, represent the sensing results, (unknown or missing) corresponding information, sensing matrix, signal of interest, and additive sensing noise. Given the observation $\mathbf Y$ and sensing matrix $\mathbf X$, we propose a one-step estimator to reconstruct $(\mathbf \Pi, \mathbf B)$. From the computational perspective, our estimator's complexity is $O(n^3 + np^2m)$, which is no greater than the maximum complexity of a linear assignment algorithm (e.g., $O(n^3)$) and a least square algorithm (e.g., $O(np^2 m)$). From the statistical perspective, we divide the minimum $snr$ requirement into four regimes, e.g., unknown, hard, medium, and easy regimes; and present sufficient conditions for the correct permutation recovery under each regime: $(i)$ $snr \geq \Omega(1)$ in the easy regime; $(ii)$ $snr \geq \Omega(\log n)$ in the medium regime; and $(iii)$ $snr \geq \Omega((\log n)^{c_0}\cdot n^{{c_1}/{srank(\mathbf B)}})$ in the hard regime ($c_0, c_1$ are some positive constants and $srank(\mathbf B)$ denotes the stable rank of $\mathbf B$). In the end, we also provide numerical experiments to confirm the above claims.
Learning manipulation of steep granular slopes for fast Mini Rover turning
Oct 02, 2023Future planetary exploration missions will require reaching challenging regions such as craters and steep slopes. Such regions are ubiquitous and present science-rich targets potentially containing information regarding the planet's internal structure. Steep slopes consisting of low-cohesion regolith are prone to flow downward under small disturbances, making it very challenging for autonomous rovers to traverse. Moreover, the navigation trajectories of rovers are heavily limited by the terrain topology and future systems will need to maneuver on flowable surfaces without getting trapped, allowing them to further expand their reach and increase mission efficiency. In this work, we used a laboratory-scale rover robot and performed maneuvering experiments on a steep granular slope of poppy seeds to explore the rover's turning capabilities. The rover is capable of lifting, sweeping, and spinning its wheels, allowing it to execute leg-like gait patterns. The high-dimensional actuation capabilities of the rover facilitate effective manipulation of the underlying granular surface. We used Bayesian Optimization (BO) to gain insight into successful turning gaits in high dimensional search space and found strategies such as differential wheel spinning and pivoting around a single sweeping wheel. We then used these insights to further fine-tune the turning gait, enabling the rover to turn 90 degrees at just above 4 seconds with minimal slip. Combining gait optimization and human-tuning approaches, we found that fast turning is empowered by creating anisotropic torques with the sweeping wheel.
Neural Processing of Tri-Plane Hybrid Neural Fields
Oct 02, 2023Driven by the appealing properties of neural fields for storing and communicating 3D data, the problem of directly processing them to address tasks such as classification and part segmentation has emerged and has been investigated in recent works. Early approaches employ neural fields parameterized by shared networks trained on the whole dataset, achieving good task performance but sacrificing reconstruction quality. To improve the latter, later methods focus on individual neural fields parameterized as large Multi-Layer Perceptrons (MLPs), which are, however, challenging to process due to the high dimensionality of the weight space, intrinsic weight space symmetries, and sensitivity to random initialization. Hence, results turn out significantly inferior to those achieved by processing explicit representations, e.g., point clouds or meshes. In the meantime, hybrid representations, in particular based on tri-planes, have emerged as a more effective and efficient alternative to realize neural fields, but their direct processing has not been investigated yet. In this paper, we show that the tri-plane discrete data structure encodes rich information, which can be effectively processed by standard deep-learning machinery. We define an extensive benchmark covering a diverse set of fields such as occupancy, signed/unsigned distance, and, for the first time, radiance fields. While processing a field with the same reconstruction quality, we achieve task performance far superior to frameworks that process large MLPs and, for the first time, almost on par with architectures handling explicit representations.
Localize, Retrieve and Fuse: A Generalized Framework for Free-Form Question Answering over Tables
Sep 20, 2023
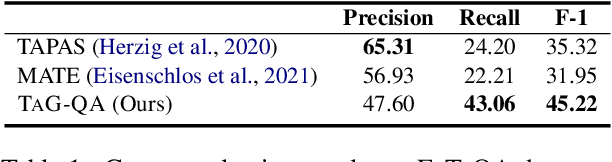
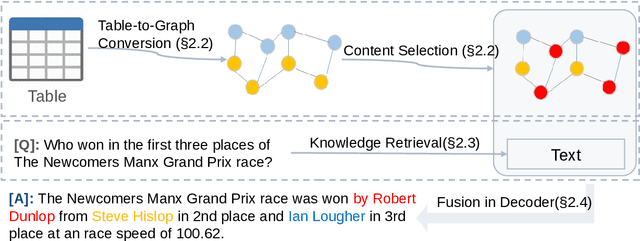
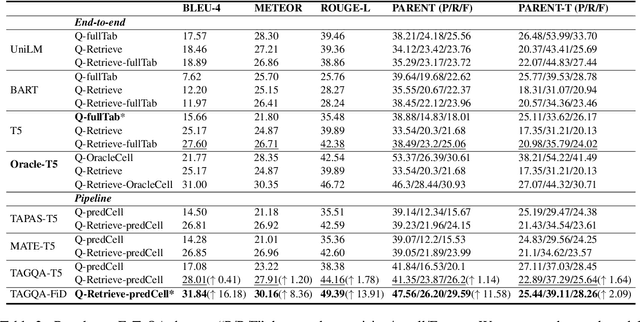
Question answering on tabular data (TableQA), which aims at generating answers to questions grounded on a given table, has attracted increasing attention in recent years. Existing work tends to generate factual short-form answers by extracting information from one or a few table cells without reasoning over selected table cells. However, the free-form TableQA, requiring a more complex relevant table cell selection strategy and the complex integration and inference of separate pieces of information, has been under-explored. To this end, this paper proposes a generalized three-stage approach: Table-to-Graph conversion and cell localizing, external knowledge retrieval and table-text fusion (called TAG-QA), addressing the challenge of inferring long free-form answer for generative TableQA. In particular, TAG-QA (1) locates relevant table cells using a graph neural network to gather intersecting cells between relevant rows and columns; (2) leverages external knowledge from Wikipedia and (3) generates answers by integrating both tabular data and natural linguistic information. Experiments with a human evaluation demonstrate that TAG-QA is capable of generating more faithful and coherent sentence when compared with several state-of-the-art baselines. Especially, TAG-QA outperforms the strong pipeline-based baseline TAPAS by 17% and 14%, in terms of BLEU-4 and PARENT F-score, respectively. Moreover, TAG-QA outperforms end-to-end model T5 by 16% and 12% on BLEU-4 and PARENT F-score.
Applying BioBERT to Extract Germline Gene-Disease Associations for Building a Knowledge Graph from the Biomedical Literature
Sep 30, 2023Published biomedical information has and continues to rapidly increase. The recent advancements in Natural Language Processing (NLP), have generated considerable interest in automating the extraction, normalization, and representation of biomedical knowledge about entities such as genes and diseases. Our study analyzes germline abstracts in the construction of knowledge graphs of the of the immense work that has been done in this area for genes and diseases. This paper presents SimpleGermKG, an automatic knowledge graph construction approach that connects germline genes and diseases. For the extraction of genes and diseases, we employ BioBERT, a pre-trained BERT model on biomedical corpora. We propose an ontology-based and rule-based algorithm to standardize and disambiguate medical terms. For semantic relationships between articles, genes, and diseases, we implemented a part-whole relation approach to connect each entity with its data source and visualize them in a graph-based knowledge representation. Lastly, we discuss the knowledge graph applications, limitations, and challenges to inspire the future research of germline corpora. Our knowledge graph contains 297 genes, 130 diseases, and 46,747 triples. Graph-based visualizations are used to show the results.
* 10 pages