 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Fuzzy to Formal: Scaling Hospital Quality Improvement with AI
Apr 21, 2026Hospital Quality Improvement (QI) plays a critical role in optimizing healthcare delivery by translating high-level hospital goals into actionable solutions. A critical step of QI is to identify the key modifiable contributing factors, a process we call QI factor discovery, typically through expert-driven semi-structured qualitative tools like fishbone diagrams, chart reviews, and Lean Healthcare methods. AI has the potential to transform and accelerate QI factor discovery, which is traditionally time- and resource-intensive and limited in reproducibility and auditability. Nevertheless, current AI alignment methods assume the task is well-defined, whereas QI factor discovery is an exploratory, fuzzy, and iterative sense-making process that relies on complex implicit expert judgments. To design an AI pipeline that formalizes the QI process while preserving its exploratory components, we propose viewing the task as learning not only LLM prompts but also the overarching natural-language specifications. In particular, we map QI factor discovery to steps of the classical AI/ML development process (problem formalization, model learning, and model validation) where the specifications are tunable hyperparameters. Domain experts and AI agents iteratively refine both the overarching specifications and AI pipeline until AI extractions are concordant with expert annotations and aligned with clinical objectives. We applied this "Human-AI Spec-Solution Co-optimization" framework at an urban safety-net hospital to identify factors driving prolonged length of stay and unplanned 30-day readmissions. The resulting AI-for-QI pipelines achieved $\ge 70\%$ concordance with expert annotations. Compared to prior manual Lean analyses, the AI pipeline was substantially more efficient, recovered previous findings, surfaced new modifiable factors, and produced auditable reasoning traces.
More Than "Means to an End": Supporting Reasoning with Transparently Designed AI Data Science Processes
Mar 25, 2026Generative artificial intelligence (AI) tools can now help people perform complex data science tasks regardless of their expertise. While these tools have great potential to help more people work with data, their end-to-end approach does not support users in evaluating alternative approaches and reformulating problems, both critical to solving open-ended tasks in high-stakes domains. In this paper, we reflect on two AI data science systems designed for the medical setting and how they function as tools for thought. We find that success in these systems was driven by constructing AI workflows around intentionally-designed intermediate artifacts, such as readable query languages, concept definitions, or input-output examples. Despite opaqueness in other parts of the AI process, these intermediates helped users reason about important analytical choices, refine their initial questions, and contribute their unique knowledge. We invite the HCI community to consider when and how intermediate artifacts should be designed to promote effective data science thinking.
Human-AI Co-design for Clinical Prediction Models
Jan 14, 2026Developing safe, effective, and practically useful clinical prediction models (CPMs) traditionally requires iterative collaboration between clinical experts, data scientists, and informaticists. This process refines the often small but critical details of the model building process, such as which features/patients to include and how clinical categories should be defined. However, this traditional collaboration process is extremely time- and resource-intensive, resulting in only a small fraction of CPMs reaching clinical practice. This challenge intensifies when teams attempt to incorporate unstructured clinical notes, which can contain an enormous number of concepts. To address this challenge, we introduce HACHI, an iterative human-in-the-loop framework that uses AI agents to accelerate the development of fully interpretable CPMs by enabling the exploration of concepts in clinical notes. HACHI alternates between (i) an AI agent rapidly exploring and evaluating candidate concepts in clinical notes and (ii) clinical and domain experts providing feedback to improve the CPM learning process. HACHI defines concepts as simple yes-no questions that are used in linear models, allowing the clinical AI team to transparently review, refine, and validate the CPM learned in each round. In two real-world prediction tasks (acute kidney injury and traumatic brain injury), HACHI outperforms existing approaches, surfaces new clinically relevant concepts not included in commonly-used CPMs, and improves model generalizability across clinical sites and time periods. Furthermore, HACHI reveals the critical role of the clinical AI team, such as directing the AI agent to explore concepts that it had not previously considered, adjusting the granularity of concepts it considers, changing the objective function to better align with the clinical objectives, and identifying issues of data bias and leakage.
When the Domain Expert Has No Time and the LLM Developer Has No Clinical Expertise: Real-World Lessons from LLM Co-Design in a Safety-Net Hospital
Aug 11, 2025Large language models (LLMs) have the potential to address social and behavioral determinants of health by transforming labor intensive workflows in resource-constrained settings. Creating LLM-based applications that serve the needs of underserved communities requires a deep understanding of their local context, but it is often the case that neither LLMs nor their developers possess this local expertise, and the experts in these communities often face severe time/resource constraints. This creates a disconnect: how can one engage in meaningful co-design of an LLM-based application for an under-resourced community when the communication channel between the LLM developer and domain expert is constrained? We explored this question through a real-world case study, in which our data science team sought to partner with social workers at a safety net hospital to build an LLM application that summarizes patients' social needs. Whereas prior works focus on the challenge of prompt tuning, we found that the most critical challenge in this setting is the careful and precise specification of \what information to surface to providers so that the LLM application is accurate, comprehensive, and verifiable. Here we present a novel co-design framework for settings with limited access to domain experts, in which the summary generation task is first decomposed into individually-optimizable attributes and then each attribute is efficiently refined and validated through a multi-tier cascading approach.
Judging LLMs on a Simplex
May 28, 2025Automated evaluation of free-form outputs from large language models (LLMs) is challenging because many distinct answers can be equally valid. A common practice is to use LLMs themselves as judges, but the theoretical properties of this approach are not yet well understood. We show that a geometric framework that represents both judges and candidates as points on a probability simplex can provide helpful insight on what is or is not identifiable using LLM judges. Our theoretical analysis uncovers a "phase transition" in ranking identifiability: for binary scoring systems, true rankings are identifiable even with weak judges under mild assumptions, while rankings become non-identifiable for three or more scoring levels even with infinite data, absent additional prior knowledge. This non-identifiability highlights how uncertainty in rankings stems from not only aleatoric uncertainty (i.e., inherent stochasticity in the data) but also epistemic uncertainty regarding which assumptions hold, an aspect that has received limited attention until now. To integrate both types of uncertainty, we use Bayesian inference to encode assumptions as priors and conduct sensitivity analysis of ranking estimates and credible intervals. Empirical evaluations across multiple benchmarks demonstrate that Bayesian inference yields more accurate rankings and substantially improves coverage rates. These results underscore the importance of taking a more holistic approach to uncertainty quantification when using LLMs as judges.
Estimating and Implementing Conventional Fairness Metrics With Probabilistic Protected Features
Oct 02, 2023



The vast majority of techniques to train fair models require access to the protected attribute (e.g., race, gender), either at train time or in production. However, in many important applications this protected attribute is largely unavailable. In this paper, we develop methods for measuring and reducing fairness violations in a setting with limited access to protected attribute labels. Specifically, we assume access to protected attribute labels on a small subset of the dataset of interest, but only probabilistic estimates of protected attribute labels (e.g., via Bayesian Improved Surname Geocoding) for the rest of the dataset. With this setting in mind, we propose a method to estimate bounds on common fairness metrics for an existing model, as well as a method for training a model to limit fairness violations by solving a constrained non-convex optimization problem. Unlike similar existing approaches, our methods take advantage of contextual information -- specifically, the relationships between a model's predictions and the probabilistic prediction of protected attributes, given the true protected attribute, and vice versa -- to provide tighter bounds on the true disparity. We provide an empirical illustration of our methods using voting data. First, we show our measurement method can bound the true disparity up to 5.5x tighter than previous methods in these applications. Then, we demonstrate that our training technique effectively reduces disparity while incurring lesser fairness-accuracy trade-offs than other fair optimization methods with limited access to protected attributes.
ODTlearn: A Package for Learning Optimal Decision Trees for Prediction and Prescription
Jul 28, 2023

ODTLearn is an open-source Python package that provides methods for learning optimal decision trees for high-stakes predictive and prescriptive tasks based on the mixed-integer optimization (MIO) framework proposed in Aghaei et al. (2019) and several of its extensions. The current version of the package provides implementations for learning optimal classification trees, optimal fair classification trees, optimal classification trees robust to distribution shifts, and optimal prescriptive trees from observational data. We have designed the package to be easy to maintain and extend as new optimal decision tree problem classes, reformulation strategies, and solution algorithms are introduced. To this end, the package follows object-oriented design principles and supports both commercial (Gurobi) and open source (COIN-OR branch and cut) solvers. The package documentation and an extensive user guide can be found at https://d3m-research-group.github.io/odtlearn/. Additionally, users can view the package source code and submit feature requests and bug reports by visiting https://github.com/D3M-Research-Group/odtlearn.
Deploying a Robust Active Preference Elicitation Algorithm: Experiment Design, Interface, and Evaluation for COVID-19 Patient Prioritization
Jun 06, 2023



Preference elicitation leverages AI or optimization to learn stakeholder preferences in settings ranging from marketing to public policy. The online robust preference elicitation procedure of arXiv:2003.01899 has been shown in simulation to outperform various other elicitation procedures in terms of effectively learning individuals' true utilities. However, as with any simulation, the method makes a series of assumptions that cannot easily be verified to hold true beyond simulation. Thus, we propose to validate the robust method's performance in deployment, focused on the particular challenge of selecting policies for prioritizing COVID-19 patients for scarce hospital resources during the pandemic. To this end, we develop an online platform for preference elicitation where users report their preferences between alternatives over a moderate number of pairwise comparisons chosen by a particular elicitation procedure. We recruit Amazon Mechanical Turk workers ($n$ = 193) to report their preferences and demonstrate that the robust method outperforms asking random queries by 21%, the next best performing method in the simulated results of arXiv:2003.01899, in terms of recommending policies with a higher utility.
Dimension-Free Average Treatment Effect Inference with Deep Neural Networks
Dec 02, 2021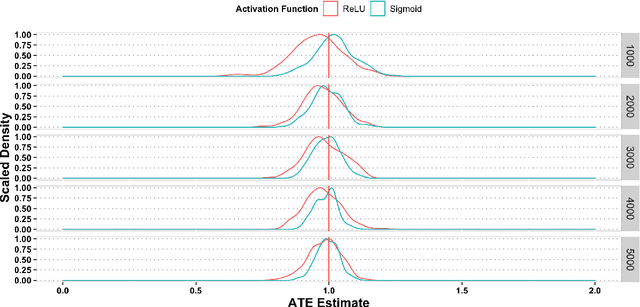
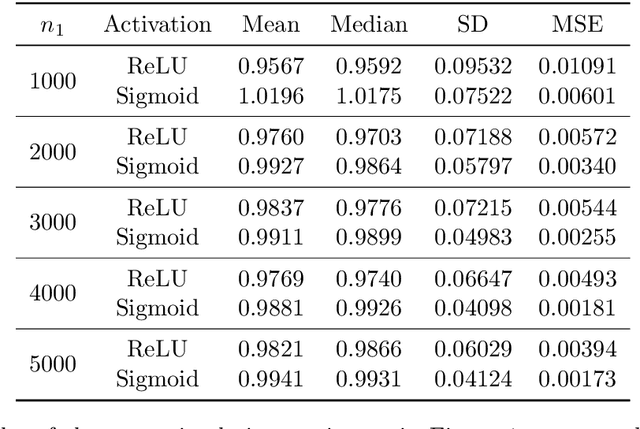
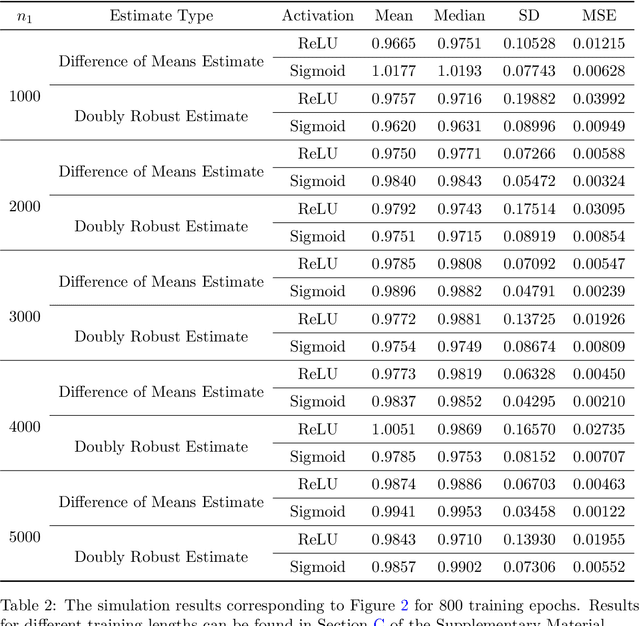
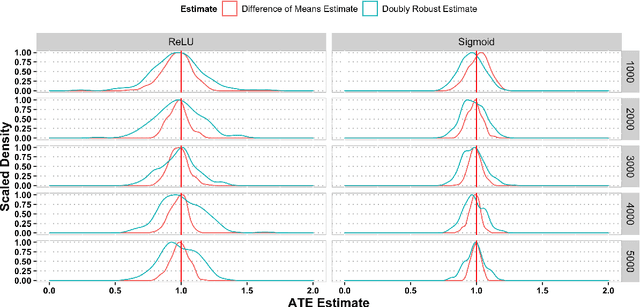
This paper investigates the estimation and inference of the average treatment effect (ATE) using deep neural networks (DNNs) in the potential outcomes framework. Under some regularity conditions, the observed response can be formulated as the response of a mean regression problem with both the confounding variables and the treatment indicator as the independent variables. Using such formulation, we investigate two methods for ATE estimation and inference based on the estimated mean regression function via DNN regression using a specific network architecture. We show that both DNN estimates of ATE are consistent with dimension-free consistency rates under some assumptions on the underlying true mean regression model. Our model assumptions accommodate the potentially complicated dependence structure of the observed response on the covariates, including latent factors and nonlinear interactions between the treatment indicator and confounding variables. We also establish the asymptotic normality of our estimators based on the idea of sample splitting, ensuring precise inference and uncertainty quantification. Simulation studies and real data application justify our theoretical findings and support our DNN estimation and inference methods.