 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generating by Understanding: Neural Visual Generation with Logical Symbol Groundings
Oct 26, 2023
Despite the great success of neural visual generative models in recent years, integrating them with strong symbolic knowledge reasoning systems remains a challenging task. The main challenges are two-fold: one is symbol assignment, i.e. bonding latent factors of neural visual generators with meaningful symbols from knowledge reasoning systems. Another is rule learning, i.e. learning new rules, which govern the generative process of the data, to augment the knowledge reasoning systems. To deal with these symbol grounding problems, we propose a neural-symbolic learning approach, Abductive Visual Generation (AbdGen), for integrating logic programming systems with neural visual generative models based on the abductive learning framework. To achieve reliable and efficient symbol assignment, the quantized abduction method is introduced for generating abduction proposals by the nearest-neighbor lookups within semantic codebooks. To achieve precise rule learning, the contrastive meta-abduction method is proposed to eliminate wrong rules with positive cases and avoid less-informative rules with negative cases simultaneously. Experimental results on various benchmark datasets show that compared to the baselines, AbdGen requires significantly fewer instance-level labeling information for symbol assignment. Furthermore, our approach can effectively learn underlying logical generative rules from data, which is out of the capability of existing approaches.
Cultural Adaptation of Recipes
Oct 26, 2023
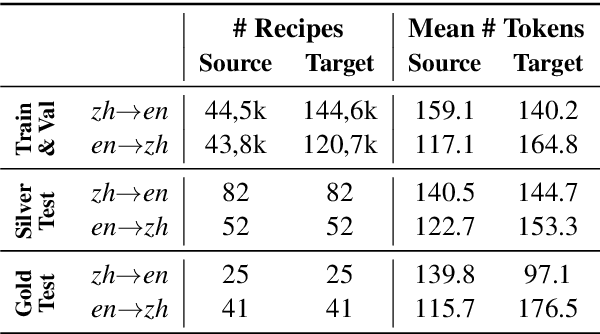
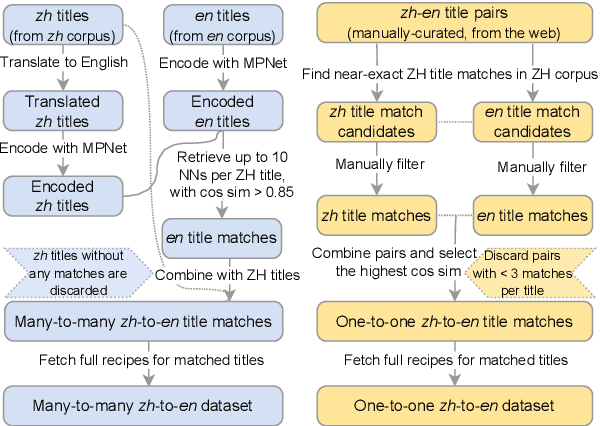

Building upon the considerable advances in Large Language Models (LLMs), we are now equipped to address more sophisticated tasks demanding a nuanced understanding of cross-cultural contexts. A key example is recipe adaptation, which goes beyond simple translation to include a grasp of ingredients, culinary techniques, and dietary preferences specific to a given culture. We introduce a new task involving the translation and cultural adaptation of recipes between Chinese and English-speaking cuisines. To support this investigation, we present CulturalRecipes, a unique dataset comprised of automatically paired recipes written in Mandarin Chinese and English. This dataset is further enriched with a human-written and curated test set. In this intricate task of cross-cultural recipe adaptation, we evaluate the performance of various methods, including GPT-4 and other LLMs, traditional machine translation, and information retrieval techniques. Our comprehensive analysis includes both automatic and human evaluation metrics. While GPT-4 exhibits impressive abilities in adapting Chinese recipes into English, it still lags behind human expertise when translating English recipes into Chinese. This underscores the multifaceted nature of cultural adaptations. We anticipate that these insights will significantly contribute to future research on culturally-aware language models and their practical application in culturally diverse contexts.
Learning Optimal Classification Trees Robust to Distribution Shifts
Oct 26, 2023We consider the problem of learning classification trees that are robust to distribution shifts between training and testing/deployment data. This problem arises frequently in high stakes settings such as public health and social work where data is often collected using self-reported surveys which are highly sensitive to e.g., the framing of the questions, the time when and place where the survey is conducted, and the level of comfort the interviewee has in sharing information with the interviewer. We propose a method for learning optimal robust classification trees based on mixed-integer robust optimization technology. In particular, we demonstrate that the problem of learning an optimal robust tree can be cast as a single-stage mixed-integer robust optimization problem with a highly nonlinear and discontinuous objective. We reformulate this problem equivalently as a two-stage linear robust optimization problem for which we devise a tailored solution procedure based on constraint generation. We evaluate the performance of our approach on numerous publicly available datasets, and compare the performance to a regularized, non-robust optimal tree. We show an increase of up to 12.48% in worst-case accuracy and of up to 4.85% in average-case accuracy across several datasets and distribution shifts from using our robust solution in comparison to the non-robust one.
A Simple Baseline for Knowledge-Based Visual Question Answering
Oct 24, 2023This paper is on the problem of Knowledge-Based Visual Question Answering (KB-VQA). Recent works have emphasized the significance of incorporating both explicit (through external databases) and implicit (through LLMs) knowledge to answer questions requiring external knowledge effectively. A common limitation of such approaches is that they consist of relatively complicated pipelines and often heavily rely on accessing GPT-3 API. Our main contribution in this paper is to propose a much simpler and readily reproducible pipeline which, in a nutshell, is based on efficient in-context learning by prompting LLaMA (1 and 2) using question-informative captions as contextual information. Contrary to recent approaches, our method is training-free, does not require access to external databases or APIs, and yet achieves state-of-the-art accuracy on the OK-VQA and A-OK-VQA datasets. Finally, we perform several ablation studies to understand important aspects of our method. Our code is publicly available at https://github.com/alexandrosXe/ASimple-Baseline-For-Knowledge-Based-VQA
A New Benchmark and Reverse Validation Method for Passage-level Hallucination Detection
Oct 24, 2023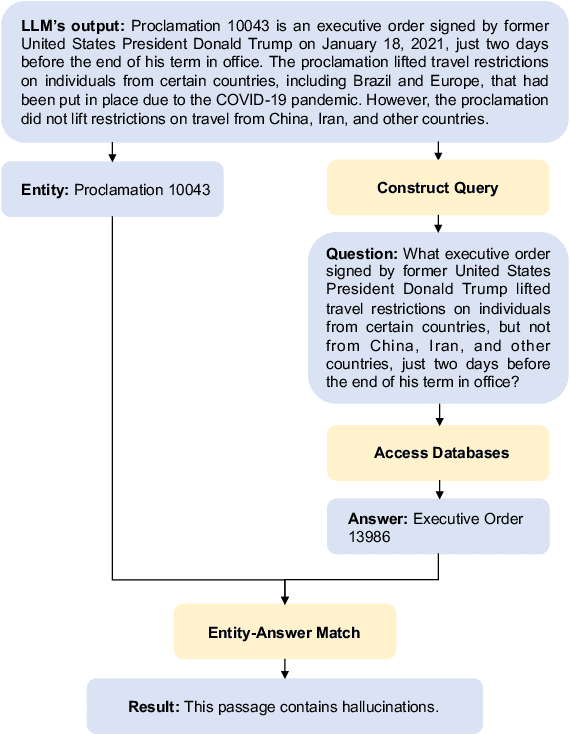
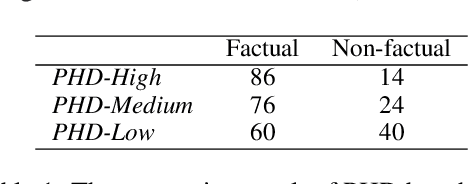

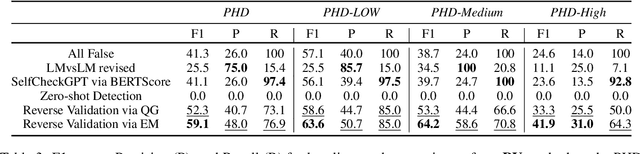
Large Language Models (LLMs) have shown their ability to collaborate effectively with humans in real-world scenarios. However, LLMs are apt to generate hallucinations, i.e., makeup incorrect text and unverified information, which can cause significant damage when deployed for mission-critical tasks. In this paper, we propose a self-check approach based on reverse validation to detect factual errors automatically in a zero-resource fashion. To facilitate future studies and assess different methods, we construct a hallucination detection benchmark named PHD, which is generated by ChatGPT and annotated by human annotators. Contrasting previous studies of zero-resource hallucination detection, our method and benchmark concentrate on passage-level detection instead of sentence-level. We empirically evaluate our method and existing zero-resource detection methods on two datasets. The experimental results demonstrate that the proposed method considerably outperforms the baselines while costing fewer tokens and less time. Furthermore, we manually analyze some hallucination cases that LLM failed to capture, revealing the shared limitation of zero-resource methods.
DACOOP-A: Decentralized Adaptive Cooperative Pursuit via Attention
Oct 24, 2023
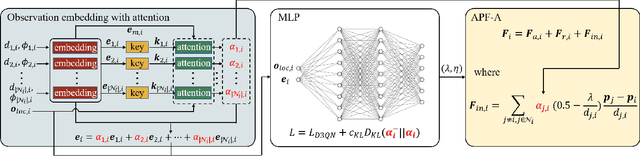
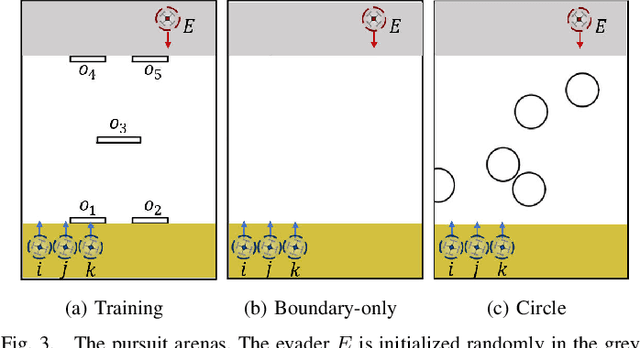
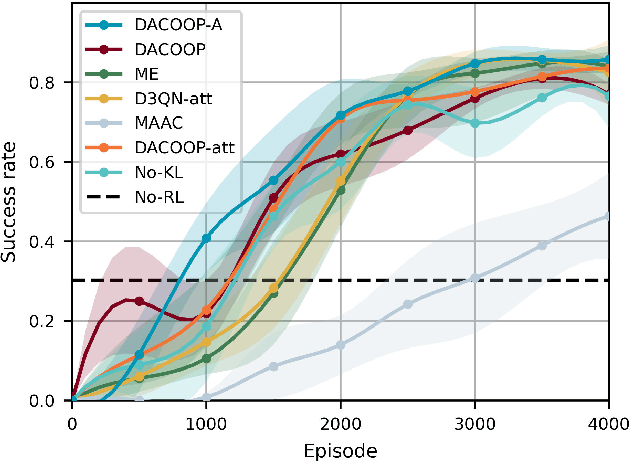
Integrating rule-based policies into reinforcement learning promises to improve data efficiency and generalization in cooperative pursuit problems. However, most implementations do not properly distinguish the influence of neighboring robots in observation embedding or inter-robot interaction rules, leading to information loss and inefficient cooperation. This paper proposes a cooperative pursuit algorithm named Decentralized Adaptive COOperative Pursuit via Attention (DACOOP-A) by empowering reinforcement learning with artificial potential field and attention mechanisms. An attention-based framework is developed to emphasize important neighbors by concurrently integrating the learned attention scores into observation embedding and inter-robot interaction rules. A KL divergence regularization is introduced to alleviate the resultant learning stability issue. Improvements in data efficiency and generalization are demonstrated through numerical simulations. Extensive quantitative analysis and ablation studies are performed to illustrate the advantages of the proposed modules. Real-world experiments are performed to justify the feasibility of deploying DACOOP-A in physical systems.
ShARc: Shape and Appearance Recognition for Person Identification In-the-wild
Oct 24, 2023Identifying individuals in unconstrained video settings is a valuable yet challenging task in biometric analysis due to variations in appearances, environments, degradations, and occlusions. In this paper, we present ShARc, a multimodal approach for video-based person identification in uncontrolled environments that emphasizes 3-D body shape, pose, and appearance. We introduce two encoders: a Pose and Shape Encoder (PSE) and an Aggregated Appearance Encoder (AAE). PSE encodes the body shape via binarized silhouettes, skeleton motions, and 3-D body shape, while AAE provides two levels of temporal appearance feature aggregation: attention-based feature aggregation and averaging aggregation. For attention-based feature aggregation, we employ spatial and temporal attention to focus on key areas for person distinction. For averaging aggregation, we introduce a novel flattening layer after averaging to extract more distinguishable information and reduce overfitting of attention. We utilize centroid feature averaging for gallery registration. We demonstrate significant improvements over existing state-of-the-art methods on public datasets, including CCVID, MEVID, and BRIAR.
Minimax Forward and Backward Learning of Evolving Tasks with Performance Guarantees
Oct 24, 2023For a sequence of classification tasks that arrive over time, it is common that tasks are evolving in the sense that consecutive tasks often have a higher similarity. The incremental learning of a growing sequence of tasks holds promise to enable accurate classification even with few samples per task by leveraging information from all the tasks in the sequence (forward and backward learning). However, existing techniques developed for continual learning and concept drift adaptation are either designed for tasks with time-independent similarities or only aim to learn the last task in the sequence. This paper presents incremental minimax risk classifiers (IMRCs) that effectively exploit forward and backward learning and account for evolving tasks. In addition, we analytically characterize the performance improvement provided by forward and backward learning in terms of the tasks' expected quadratic change and the number of tasks. The experimental evaluation shows that IMRCs can result in a significant performance improvement, especially for reduced sample sizes.
IA Para el Mantenimiento Predictivo en Canteras: Modelado
Oct 24, 2023Dependence on raw materials, especially in the mining sector, is a key part of today's economy. Aggregates are vital, being the second most used raw material after water. Digitally transforming this sector is key to optimizing operations. However, supervision and maintenance (predictive and corrective) are challenges little explored in this sector, due to the particularities of the sector, machinery and environmental conditions. All this, despite the successes achieved in other scenarios in monitoring with acoustic and contact sensors. We present an unsupervised learning scheme that trains a variational autoencoder model on a set of sound records. This is the first such dataset collected during processing plant operations, containing information from different points of the processing line. Our results demonstrate the model's ability to reconstruct and represent in latent space the recorded sounds, the differences in operating conditions and between different equipment. In the future, this should facilitate the classification of sounds, as well as the detection of anomalies and degradation patterns in the operation of the machinery.
Length is a Curse and a Blessing for Document-level Semantics
Oct 24, 2023In recent years, contrastive learning (CL) has been extensively utilized to recover sentence and document-level encoding capability from pre-trained language models. In this work, we question the length generalizability of CL-based models, i.e., their vulnerability towards length-induced semantic shift. We verify not only that length vulnerability is a significant yet overlooked research gap, but we can devise unsupervised CL methods solely depending on the semantic signal provided by document length. We first derive the theoretical foundations underlying length attacks, showing that elongating a document would intensify the high intra-document similarity that is already brought by CL. Moreover, we found that isotropy promised by CL is highly dependent on the length range of text exposed in training. Inspired by these findings, we introduce a simple yet universal document representation learning framework, LA(SER)$^{3}$: length-agnostic self-reference for semantically robust sentence representation learning, achieving state-of-the-art unsupervised performance on the standard information retrieval benchmark.