 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OTMatch: Improving Semi-Supervised Learning with Optimal Transport
Oct 26, 2023
Semi-supervised learning has made remarkable strides by effectively utilizing a limited amount of labeled data while capitalizing on the abundant information present in unlabeled data. However, current algorithms often prioritize aligning image predictions with specific classes generated through self-training techniques, thereby neglecting the inherent relationships that exist within these classes. In this paper, we present a new approach called OTMatch, which leverages semantic relationships among classes by employing an optimal transport loss function. By utilizing optimal transport, our proposed method consistently outperforms established state-of-the-art methods. Notably, we observed a substantial improvement of a certain percentage in accuracy compared to the current state-of-the-art method, FreeMatch. OTMatch achieves 3.18%, 3.46%, and 1.28% error rate reduction over FreeMatch on CIFAR-10 with 1 label per class, STL-10 with 4 labels per class, and ImageNet with 100 labels per class, respectively. This demonstrates the effectiveness and superiority of our approach in harnessing semantic relationships to enhance learning performance in a semi-supervised setting.
CQM: Curriculum Reinforcement Learning with a Quantized World Model
Oct 26, 2023Recent curriculum Reinforcement Learning (RL) has shown notable progress in solving complex tasks by proposing sequences of surrogate tasks. However, the previous approaches often face challenges when they generate curriculum goals in a high-dimensional space. Thus, they usually rely on manually specified goal spaces. To alleviate this limitation and improve the scalability of the curriculum, we propose a novel curriculum method that automatically defines the semantic goal space which contains vital information for the curriculum process, and suggests curriculum goals over it. To define the semantic goal space, our method discretizes continuous observations via vector quantized-variational autoencoders (VQ-VAE) and restores the temporal relations between the discretized observations by a graph. Concurrently, ours suggests uncertainty and temporal distance-aware curriculum goals that converges to the final goals over the automatically composed goal space. We demonstrate that the proposed method allows efficient explorations in an uninformed environment with raw goal examples only. Also, ours outperforms the state-of-the-art curriculum RL methods on data efficiency and performance, in various goal-reaching tasks even with ego-centric visual inputs.
Bin Assignment and Decentralized Path Planning for Multi-Robot Parcel Sorting
Oct 26, 2023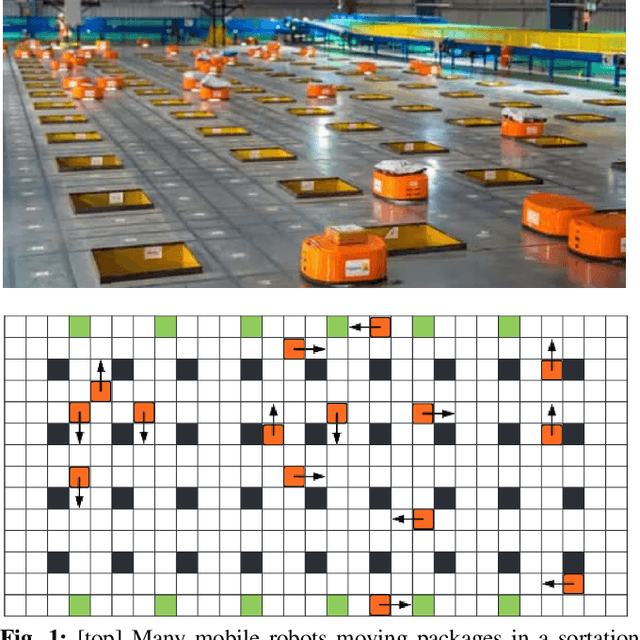
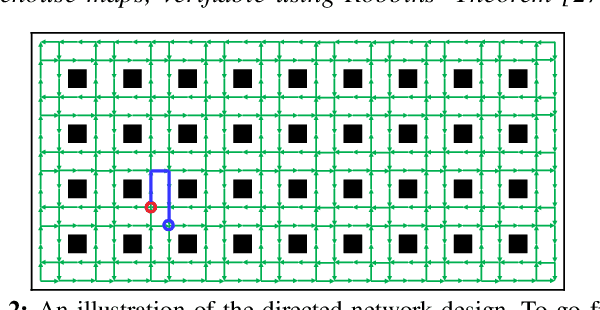
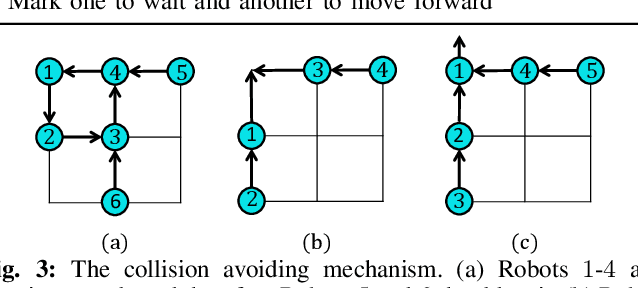
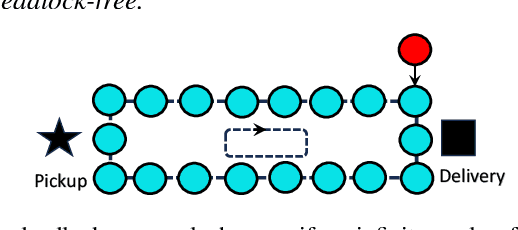
At modern warehouses, mobile robots transport packages and drop them into collection bins/chutes based on shipping destinations grouped by, e.g., the ZIP code. System throughput, measured as the number of packages sorted per unit of time, determines the efficiency of the warehouse. This research develops a scalable, high-throughput multi-robot parcel sorting solution, decomposing the task into two related processes, bin assignment and offline/online multi-robot path planning, and optimizing both. Bin assignment matches collection bins with package types to minimize traveling costs. Subsequently, robots are assigned to pick up and drop packages into assigned bins. Multiple highly effective bin assignment algorithms are proposed that can work with an arbitrary planning algorithm. We propose a decentralized path planning routine using only local information to route the robots over a carefully constructed directed road network for multi-robot path planning. Our decentralized planner, provably probabilistically deadlock-free, consistently delivers near-optimal results on par with some top-performing centralized planners while significantly reducing computation times by orders of magnitude. Extensive simulations show that our overall framework delivers promising performances.
Multi-Modal Knowledge Graph Transformer Framework for Multi-Modal Entity Alignment
Oct 10, 2023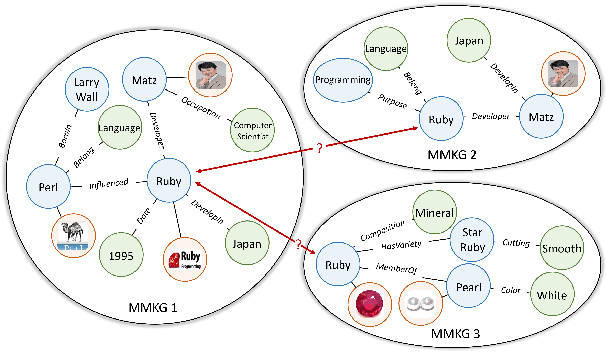
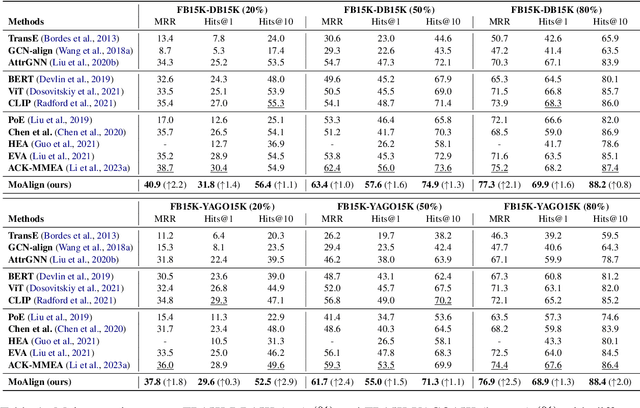
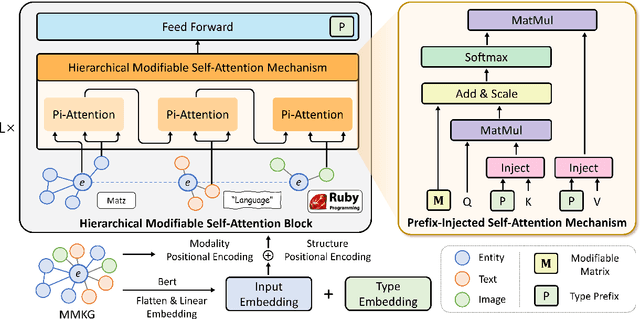
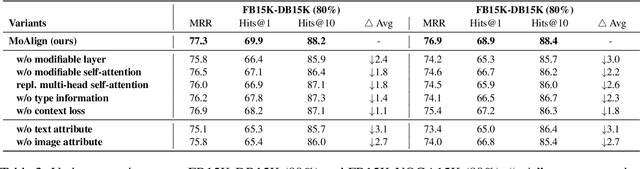
Multi-Modal Entity Alignment (MMEA) is a critical task that aims to identify equivalent entity pairs across multi-modal knowledge graphs (MMKGs). However, this task faces challenges due to the presence of different types of information, including neighboring entities, multi-modal attributes, and entity types. Directly incorporating the above information (e.g., concatenation or attention) can lead to an unaligned information space. To address these challenges, we propose a novel MMEA transformer, called MoAlign, that hierarchically introduces neighbor features, multi-modal attributes, and entity types to enhance the alignment task. Taking advantage of the transformer's ability to better integrate multiple information, we design a hierarchical modifiable self-attention block in a transformer encoder to preserve the unique semantics of different information. Furthermore, we design two entity-type prefix injection methods to integrate entity-type information using type prefixes, which help to restrict the global information of entities not present in the MMKGs. Our extensive experiments on benchmark datasets demonstrate that our approach outperforms strong competitors and achieves excellent entity alignment performance.
LLM-Prop: Predicting Physical And Electronic Properties Of Crystalline Solids From Their Text Descriptions
Oct 21, 2023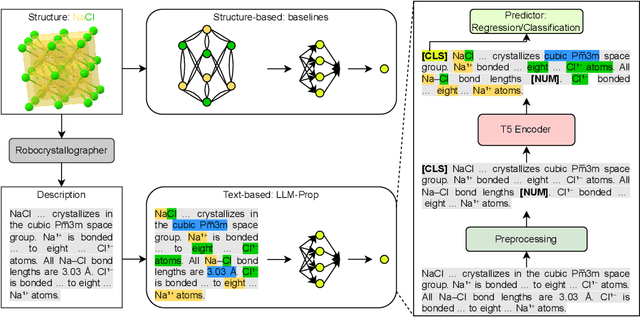
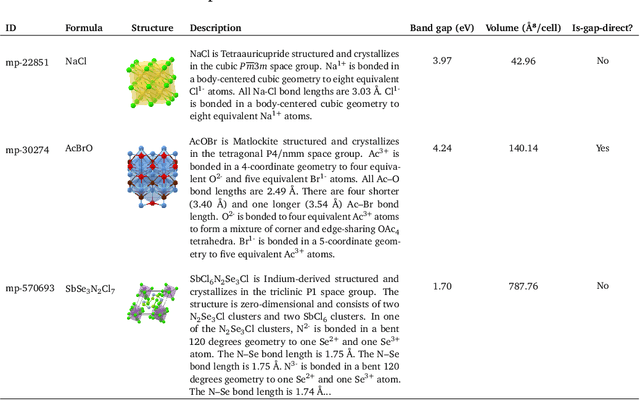
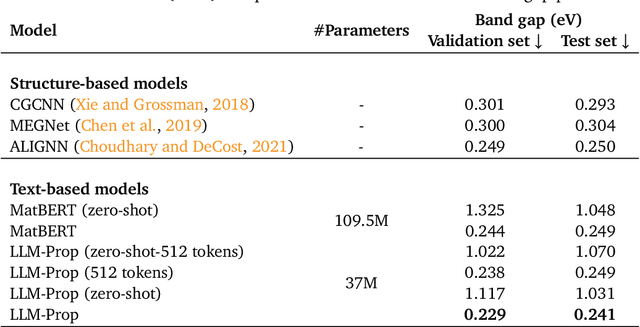
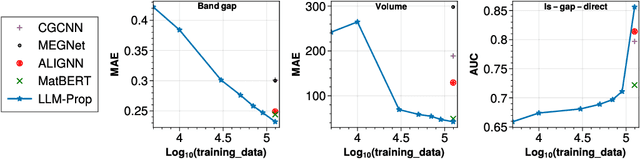
The prediction of crystal properties plays a crucial role in the crystal design process. Current methods for predicting crystal properties focus on modeling crystal structures using graph neural networks (GNNs). Although GNNs are powerful, accurately modeling the complex interactions between atoms and molecules within a crystal remains a challenge. Surprisingly, predicting crystal properties from crystal text descriptions is understudied, despite the rich information and expressiveness that text data offer. One of the main reasons is the lack of publicly available data for this task. In this paper, we develop and make public a benchmark dataset (called TextEdge) that contains text descriptions of crystal structures with their properties. We then propose LLM-Prop, a method that leverages the general-purpose learning capabilities of large language models (LLMs) to predict the physical and electronic properties of crystals from their text descriptions. LLM-Prop outperforms the current state-of-the-art GNN-based crystal property predictor by about 4% in predicting band gap, 3% in classifying whether the band gap is direct or indirect, and 66% in predicting unit cell volume. LLM-Prop also outperforms a finetuned MatBERT, a domain-specific pre-trained BERT model, despite having 3 times fewer parameters. Our empirical results may highlight the current inability of GNNs to capture information pertaining to space group symmetry and Wyckoff sites for accurate crystal property prediction.
Impact of time and note duration tokenizations on deep learning symbolic music modeling
Oct 12, 2023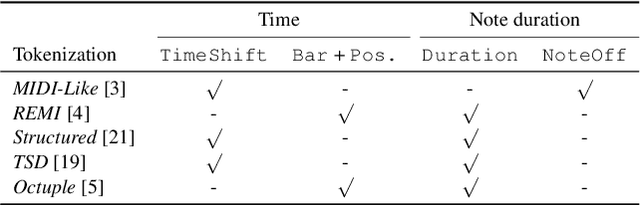
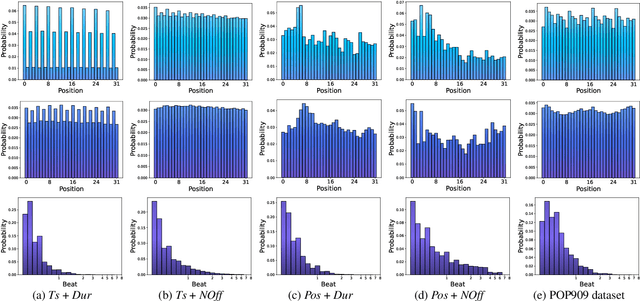
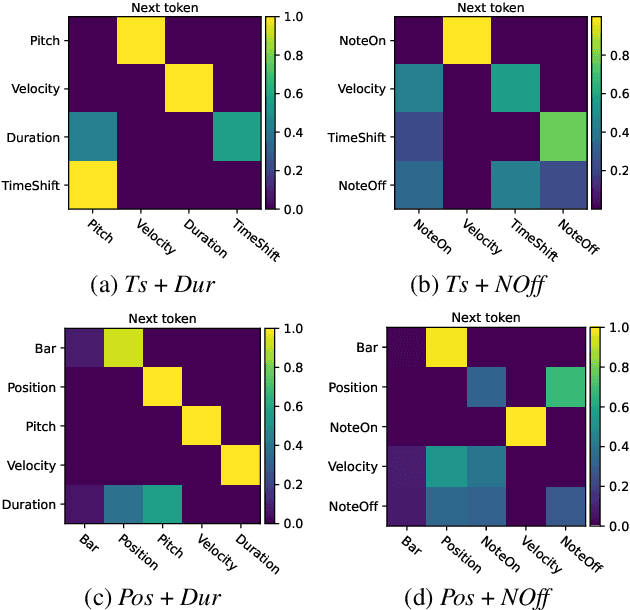
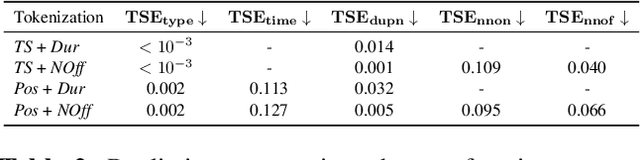
Symbolic music is widely used in various deep learning tasks, including generation, transcription, synthesis, and Music Information Retrieval (MIR). It is mostly employed with discrete models like Transformers, which require music to be tokenized, i.e., formatted into sequences of distinct elements called tokens. Tokenization can be performed in different ways. As Transformer can struggle at reasoning, but capture more easily explicit information, it is important to study how the way the information is represented for such model impact their performances. In this work, we analyze the common tokenization methods and experiment with time and note duration representations. We compare the performances of these two impactful criteria on several tasks, including composer and emotion classification, music generation, and sequence representation learning. We demonstrate that explicit information leads to better results depending on the task.
The Hidden Adversarial Vulnerabilities of Medical Federated Learning
Oct 21, 2023In this paper, we delve into the susceptibility of federated medical image analysis systems to adversarial attacks. Our analysis uncovers a novel exploitation avenue: using gradient information from prior global model updates, adversaries can enhance the efficiency and transferability of their attacks. Specifically, we demonstrate that single-step attacks (e.g. FGSM), when aptly initialized, can outperform the efficiency of their iterative counterparts but with reduced computational demand. Our findings underscore the need to revisit our understanding of AI security in federated healthcare settings.
Policy Gradient with Kernel Quadrature
Oct 23, 2023Reward evaluation of episodes becomes a bottleneck in a broad range of reinforcement learning tasks. Our aim in this paper is to select a small but representative subset of a large batch of episodes, only on which we actually compute rewards for more efficient policy gradient iterations. We build a Gaussian process modeling of discounted returns or rewards to derive a positive definite kernel on the space of episodes, run an "episodic" kernel quadrature method to compress the information of sample episodes, and pass the reduced episodes to the policy network for gradient updates. We present the theoretical background of this procedure as well as its numerical illustrations in MuJoCo and causal discovery tasks.
Penalty Decoding: Well Suppress the Self-Reinforcement Effect in Open-Ended Text Generation
Oct 23, 2023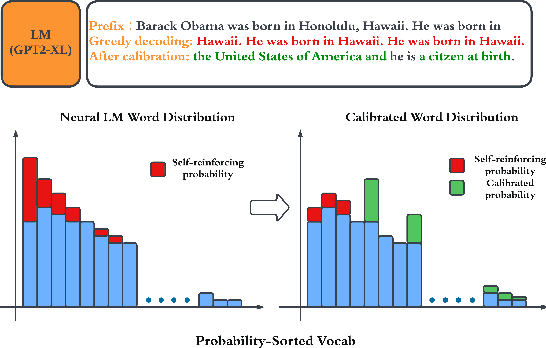
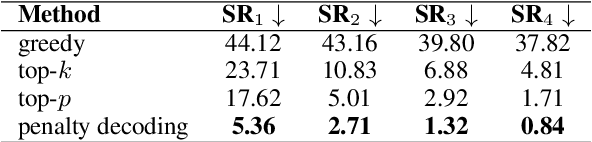
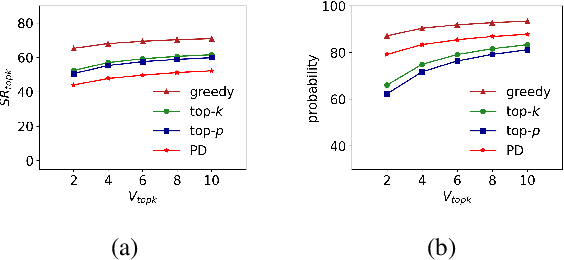
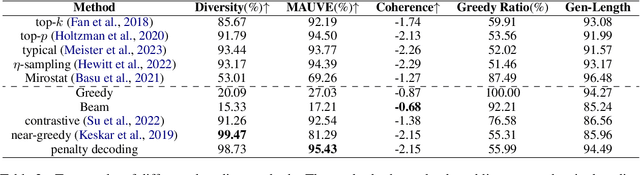
The decoding algorithm is critical for open-ended text generation, transforming latent representations into coherent and meaningful outputs. This paper investigates the self-reinforcement effect in text generation and the effectiveness of a repetition penalty to mitigate it. However, determining the optimal repetition penalty value is challenging. To tackle this, we propose a forgetting mechanism that disregards distant tokens, reducing the burden of penalty selection. In addition, we introduce a length penalty to address overly short sentences caused by excessive penalties. Our penalty decoding approach incorporating three strategies helps resolve issues with sampling methods deviating from factual information. Experimental results demonstrate the efficacy of our approach in generating high-quality sentences resembling human output.
Bayesian Regression Markets
Oct 23, 2023Machine learning tasks are vulnerable to the quality of data used as input. Yet, it is often challenging for firms to obtain adequate datasets, with them being naturally distributed amongst owners, that in practice, may be competitors in a downstream market and reluctant to share information. Focusing on supervised learning for regression tasks, we develop a \textit{regression market} to provide a monetary incentive for data sharing. Our proposed mechanism adopts a Bayesian framework, allowing us to consider a more general class of regression tasks. We present a thorough exploration of the market properties, and show that similar proposals in current literature expose the market agents to sizeable financial risks, which can be mitigated in our probabilistic setting.