 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAG: Flow Policy MaxEnt-RL by Latent Augmented Guidance
May 29, 2026Maximum entropy reinforcement learning (MaxEnt-RL) enables robust exploration, yet practical implementations often restrict policies to simple Gaussians. While recent approaches incorporate expressive generative policies via importance-weighted supervised learning, they are prone to importance weight collapse, which limits their scalability in high-dimensional action spaces. Our key insight is to mitigate this limitation by localizing the sampling region, avoiding the weight degeneracy induced by importance sampling over the entire action space. To instantiate this insight, we introduce \textbf{FLAG} (\textbf{F}low policy with \textbf{L}atent-\textbf{A}ugmented \textbf{G}uidance). FLAG augments the state space with a flow latent variable and optimizes a provably consistent proxy MaxEnt-RL objective. We empirically demonstrate that FLAG enables expressive policy optimization with limited importance samples and scales to high-dimensional control tasks. Furthermore, FLAG achieves state-of-the-art performance across challenging benchmarks. Our project webpage: https://flag-rl.github.io/
DynaFLIP: Rethinking Robotics Perception via Tri-Modal-Dynamics Guided Representation
May 28, 2026Robot manipulation critically depends on perception that preserves the action-relevant aspects of a scene. Yet most robot learning pipelines are built upon visual encoders pre-trained for static recognition or vision-language alignment, leaving motion understanding to downstream policies. We introduce DynaFLIP, a dynamics-aware multimodal pre-training framework that pushes motion understanding upstream into perception. We construct image-language-3D flow triplets from heterogeneous human and robot videos, and use these triplets as training-time supervision to shape an image-only encoder. Our key idea is to encourage the three modalities to span a small simplex volume in the shared hyperspherical space -- a smaller simplex volume indicating stronger alignment. To avoid the geometric ambiguity and trivial collapse of naive volume minimization, we combine simplex-volume minimization with a cosine regularizer and a contrastive objective. Our analyses show that DynaFLIP focuses on control-relevant regions critical for manipulation. The resulting dynamics-aware representations serve as reusable visual backbones and consistently outperform baselines across diverse downstream policies, including VLAs. We validate this across diverse simulation and real-world setups, with gains reaching +22.5% under out-of-distribution scenarios. Our results suggest that robot generalization improves when visual representations are trained to encode not just what is present, but how the world changes under action.
EgoAVFlow: Robot Policy Learning with Active Vision from Human Egocentric Videos via 3D Flow
Feb 25, 2026Egocentric human videos provide a scalable source of manipulation demonstrations; however, deploying them on robots requires active viewpoint control to maintain task-critical visibility, which human viewpoint imitation often fails to provide due to human-specific priors. We propose EgoAVFlow, which learns manipulation and active vision from egocentric videos through a shared 3D flow representation that supports geometric visibility reasoning and transfers without robot demonstrations. EgoAVFlow uses diffusion models to predict robot actions, future 3D flow, and camera trajectories, and refines viewpoints at test time with reward-maximizing denoising under a visibility-aware reward computed from predicted motion and scene geometry. Real-world experiments under actively changing viewpoints show that EgoAVFlow consistently outperforms prior human-demo-based baselines, demonstrating effective visibility maintenance and robust manipulation without robot demonstrations.
AdaptManip: Learning Adaptive Whole-Body Object Lifting and Delivery with Online Recurrent State Estimation
Feb 16, 2026This paper presents Adaptive Whole-body Loco-Manipulation, AdaptManip, a fully autonomous framework for humanoid robots to perform integrated navigation, object lifting, and delivery. Unlike prior imitation learning-based approaches that rely on human demonstrations and are often brittle to disturbances, AdaptManip aims to train a robust loco-manipulation policy via reinforcement learning without human demonstrations or teleoperation data. The proposed framework consists of three coupled components: (1) a recurrent object state estimator that tracks the manipulated object in real time under limited field-of-view and occlusions; (2) a whole-body base policy for robust locomotion with residual manipulation control for stable object lifting and delivery; and (3) a LiDAR-based robot global position estimator that provides drift-robust localization. All components are trained in simulation using reinforcement learning and deployed on real hardware in a zero-shot manner. Experimental results show that AdaptManip significantly outperforms baseline methods, including imitation learning-based approaches, in adaptability and overall success rate, while accurate object state estimation improves manipulation performance even under occlusion. We further demonstrate fully autonomous real-world navigation, object lifting, and delivery on a humanoid robot.
Diversify & Conquer: Outcome-directed Curriculum RL via Out-of-Distribution Disagreement
Oct 30, 2023Reinforcement learning (RL) often faces the challenges of uninformed search problems where the agent should explore without access to the domain knowledge such as characteristics of the environment or external rewards. To tackle these challenges, this work proposes a new approach for curriculum RL called Diversify for Disagreement & Conquer (D2C). Unlike previous curriculum learning methods, D2C requires only a few examples of desired outcomes and works in any environment, regardless of its geometry or the distribution of the desired outcome examples. The proposed method performs diversification of the goal-conditional classifiers to identify similarities between visited and desired outcome states and ensures that the classifiers disagree on states from out-of-distribution, which enables quantifying the unexplored region and designing an arbitrary goal-conditioned intrinsic reward signal in a simple and intuitive way. The proposed method then employs bipartite matching to define a curriculum learning objective that produces a sequence of well-adjusted intermediate goals, which enable the agent to automatically explore and conquer the unexplored region. We present experimental results demonstrating that D2C outperforms prior curriculum RL methods in both quantitative and qualitative aspects, even with the arbitrarily distributed desired outcome examples.
CQM: Curriculum Reinforcement Learning with a Quantized World Model
Oct 26, 2023Recent curriculum Reinforcement Learning (RL) has shown notable progress in solving complex tasks by proposing sequences of surrogate tasks. However, the previous approaches often face challenges when they generate curriculum goals in a high-dimensional space. Thus, they usually rely on manually specified goal spaces. To alleviate this limitation and improve the scalability of the curriculum, we propose a novel curriculum method that automatically defines the semantic goal space which contains vital information for the curriculum process, and suggests curriculum goals over it. To define the semantic goal space, our method discretizes continuous observations via vector quantized-variational autoencoders (VQ-VAE) and restores the temporal relations between the discretized observations by a graph. Concurrently, ours suggests uncertainty and temporal distance-aware curriculum goals that converges to the final goals over the automatically composed goal space. We demonstrate that the proposed method allows efficient explorations in an uninformed environment with raw goal examples only. Also, ours outperforms the state-of-the-art curriculum RL methods on data efficiency and performance, in various goal-reaching tasks even with ego-centric visual inputs.
Demonstration-free Autonomous Reinforcement Learning via Implicit and Bidirectional Curriculum
May 17, 2023While reinforcement learning (RL) has achieved great success in acquiring complex skills solely from environmental interactions, it assumes that resets to the initial state are readily available at the end of each episode. Such an assumption hinders the autonomous learning of embodied agents due to the time-consuming and cumbersome workarounds for resetting in the physical world. Hence, there has been a growing interest in autonomous RL (ARL) methods that are capable of learning from non-episodic interactions. However, existing works on ARL are limited by their reliance on prior data and are unable to learn in environments where task-relevant interactions are sparse. In contrast, we propose a demonstration-free ARL algorithm via Implicit and Bi-directional Curriculum (IBC). With an auxiliary agent that is conditionally activated upon learning progress and a bidirectional goal curriculum based on optimal transport, our method outperforms previous methods, even the ones that leverage demonstrations.
Outcome-directed Reinforcement Learning by Uncertainty & Temporal Distance-Aware Curriculum Goal Generation
Jan 27, 2023Current reinforcement learning (RL) often suffers when solving a challenging exploration problem where the desired outcomes or high rewards are rarely observed. Even though curriculum RL, a framework that solves complex tasks by proposing a sequence of surrogate tasks, shows reasonable results, most of the previous works still have difficulty in proposing curriculum due to the absence of a mechanism for obtaining calibrated guidance to the desired outcome state without any prior domain knowledge. To alleviate it, we propose an uncertainty & temporal distance-aware curriculum goal generation method for the outcome-directed RL via solving a bipartite matching problem. It could not only provide precisely calibrated guidance of the curriculum to the desired outcome states but also bring much better sample efficiency and geometry-agnostic curriculum goal proposal capability compared to previous curriculum RL methods. We demonstrate that our algorithm significantly outperforms these prior methods in a variety of challenging navigation tasks and robotic manipulation tasks in a quantitative and qualitative way.
S2P: State-conditioned Image Synthesis for Data Augmentation in Offline Reinforcement Learning
Sep 30, 2022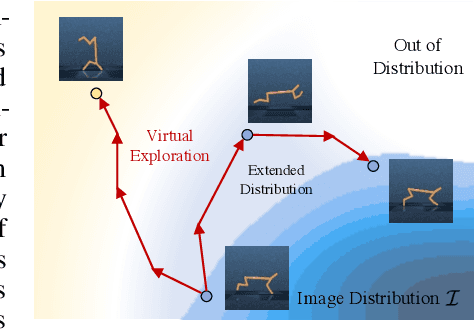
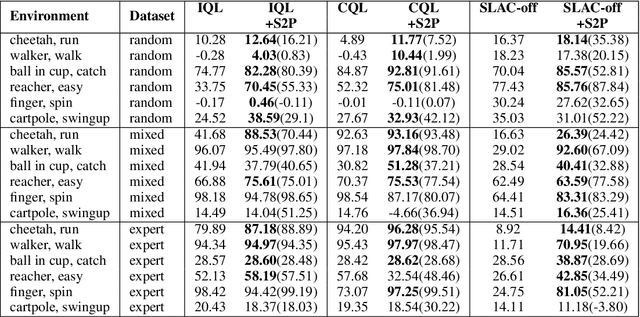
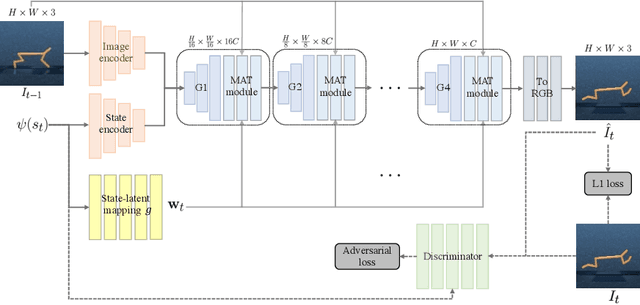
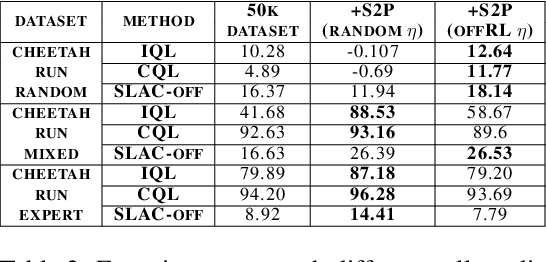
Offline reinforcement learning (Offline RL) suffers from the innate distributional shift as it cannot interact with the physical environment during training. To alleviate such limitation, state-based offline RL leverages a learned dynamics model from the logged experience and augments the predicted state transition to extend the data distribution. For exploiting such benefit also on the image-based RL, we firstly propose a generative model, S2P (State2Pixel), which synthesizes the raw pixel of the agent from its corresponding state. It enables bridging the gap between the state and the image domain in RL algorithms, and virtually exploring unseen image distribution via model-based transition in the state space. Through experiments, we confirm that our S2P-based image synthesis not only improves the image-based offline RL performance but also shows powerful generalization capability on unseen tasks.
Unsupervised Reinforcement Learning for Transferable Manipulation Skill Discovery
Apr 29, 2022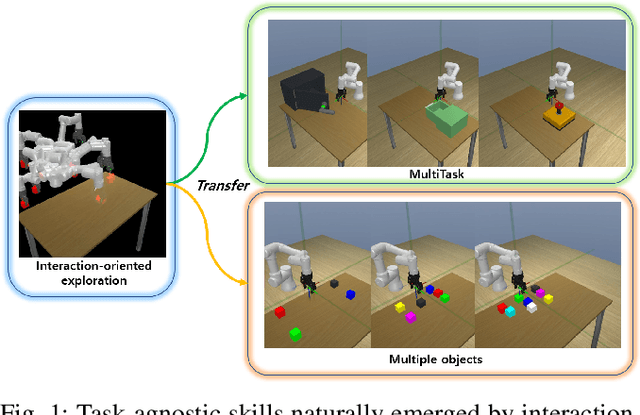
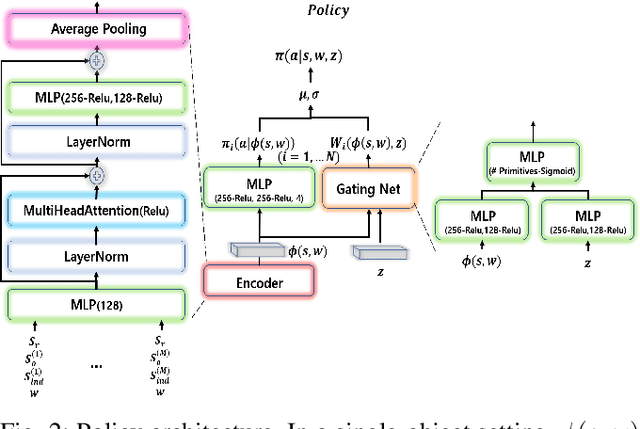
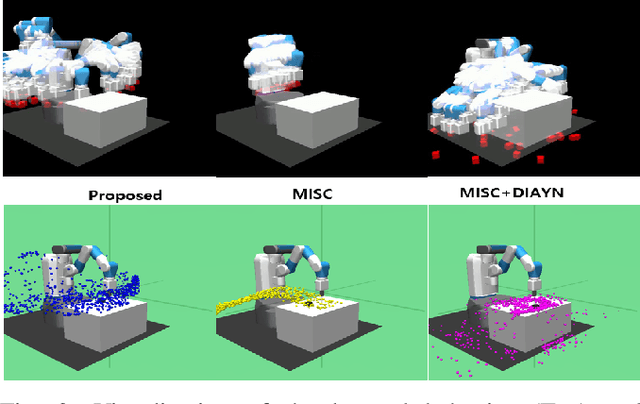
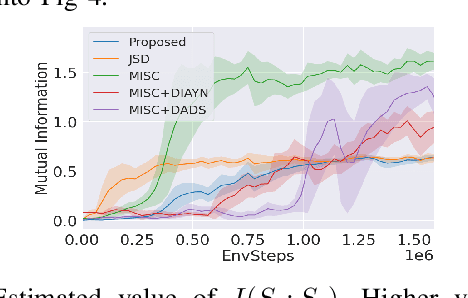
Current reinforcement learning (RL) in robotics often experiences difficulty in generalizing to new downstream tasks due to the innate task-specific training paradigm. To alleviate it, unsupervised RL, a framework that pre-trains the agent in a task-agnostic manner without access to the task-specific reward, leverages active exploration for distilling diverse experience into essential skills or reusable knowledge. For exploiting such benefits also in robotic manipulation, we propose an unsupervised method for transferable manipulation skill discovery that ties structured exploration toward interacting behavior and transferable skill learning. It not only enables the agent to learn interaction behavior, the key aspect of the robotic manipulation learning, without access to the environment reward, but also to generalize to arbitrary downstream manipulation tasks with the learned task-agnostic skills. Through comparative experiments, we show that our approach achieves the most diverse interacting behavior and significantly improves sample efficiency in downstream tasks including the extension to multi-object, multitask problems.