 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Voting Network for Contour Levee Farmland Segmentation and Classification
Sep 28, 2023
High-resolution aerial imagery allows fine details in the segmentation of farmlands. However, small objects and features introduce distortions to the delineation of object boundaries, and larger contextual views are needed to mitigate class confusion. In this work, we present an end-to-end trainable network for segmenting farmlands with contour levees from high-resolution aerial imagery. A fusion block is devised that includes multiple voting blocks to achieve image segmentation and classification. We integrate the fusion block with a backbone and produce both semantic predictions and segmentation slices. The segmentation slices are used to perform majority voting on the predictions. The network is trained to assign the most likely class label of a segment to its pixels, learning the concept of farmlands rather than analyzing constitutive pixels separately. We evaluate our method using images from the National Agriculture Imagery Program. Our method achieved an average accuracy of 94.34\%. Compared to the state-of-the-art methods, the proposed method obtains an improvement of 6.96% and 2.63% in the F1 score on average.
Distilling ODE Solvers of Diffusion Models into Smaller Steps
Sep 28, 2023Distillation techniques have substantially improved the sampling speed of diffusion models, allowing of the generation within only one step or a few steps. However, these distillation methods require extensive training for each dataset, sampler, and network, which limits their practical applicability. To address this limitation, we propose a straightforward distillation approach, Distilled-ODE solvers (D-ODE solvers), that optimizes the ODE solver rather than training the denoising network. D-ODE solvers are formulated by simply applying a single parameter adjustment to existing ODE solvers. Subsequently, D-ODE solvers with smaller steps are optimized by ODE solvers with larger steps through distillation over a batch of samples. Our comprehensive experiments indicate that D-ODE solvers outperform existing ODE solvers, including DDIM, PNDM, DPM-Solver, DEIS, and EDM, especially when generating samples with fewer steps. Our method incur negligible computational overhead compared to previous distillation techniques, enabling simple and rapid integration with previous samplers. Qualitative analysis further shows that D-ODE solvers enhance image quality while preserving the sampling trajectory of ODE solvers.
Deep Single Models vs. Ensembles: Insights for a Fast Deployment of Parking Monitoring Systems
Sep 28, 2023Searching for available parking spots in high-density urban centers is a stressful task for drivers that can be mitigated by systems that know in advance the nearest parking space available. To this end, image-based systems offer cost advantages over other sensor-based alternatives (e.g., ultrasonic sensors), requiring less physical infrastructure for installation and maintenance. Despite recent deep learning advances, deploying intelligent parking monitoring is still a challenge since most approaches involve collecting and labeling large amounts of data, which is laborious and time-consuming. Our study aims to uncover the challenges in creating a global framework, trained using publicly available labeled parking lot images, that performs accurately across diverse scenarios, enabling the parking space monitoring as a ready-to-use system to deploy in a new environment. Through exhaustive experiments involving different datasets and deep learning architectures, including fusion strategies and ensemble methods, we found that models trained on diverse datasets can achieve 95\% accuracy without the burden of data annotation and model training on the target parking lot
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Sep 28, 2023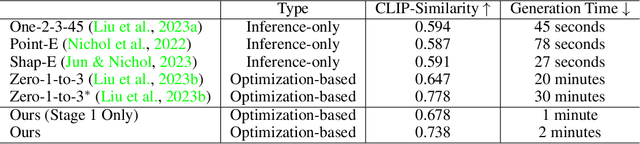
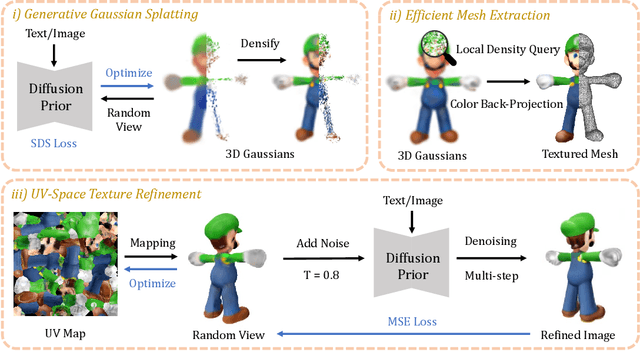


Recent advances in 3D content creation mostly leverage optimization-based 3D generation via score distillation sampling (SDS). Though promising results have been exhibited, these methods often suffer from slow per-sample optimization, limiting their practical usage. In this paper, we propose DreamGaussian, a novel 3D content generation framework that achieves both efficiency and quality simultaneously. Our key insight is to design a generative 3D Gaussian Splatting model with companioned mesh extraction and texture refinement in UV space. In contrast to the occupancy pruning used in Neural Radiance Fields, we demonstrate that the progressive densification of 3D Gaussians converges significantly faster for 3D generative tasks. To further enhance the texture quality and facilitate downstream applications, we introduce an efficient algorithm to convert 3D Gaussians into textured meshes and apply a fine-tuning stage to refine the details. Extensive experiments demonstrate the superior efficiency and competitive generation quality of our proposed approach. Notably, DreamGaussian produces high-quality textured meshes in just 2 minutes from a single-view image, achieving approximately 10 times acceleration compared to existing methods.
On the Contractivity of Plug-and-Play Operators
Sep 28, 2023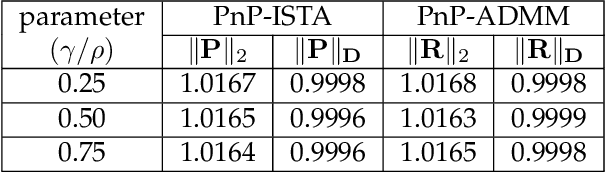

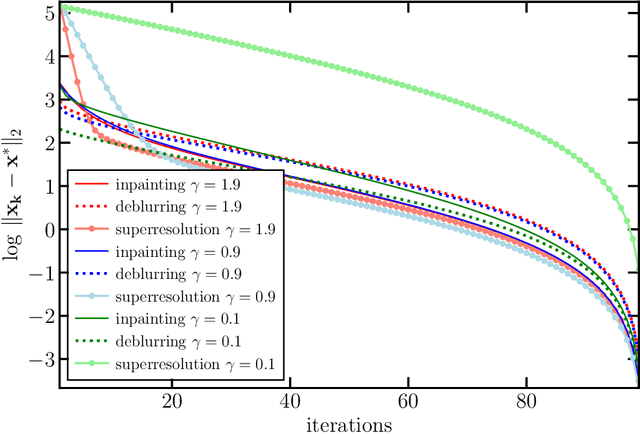

In plug-and-play (PnP) regularization, the proximal operator in algorithms such as ISTA and ADMM is replaced by a powerful denoiser. This formal substitution works surprisingly well in practice. In fact, PnP has been shown to give state-of-the-art results for various imaging applications. The empirical success of PnP has motivated researchers to understand its theoretical underpinnings and, in particular, its convergence. It was shown in prior work that for kernel denoisers such as the nonlocal means, PnP-ISTA provably converges under some strong assumptions on the forward model. The present work is motivated by the following questions: Can we relax the assumptions on the forward model? Can the convergence analysis be extended to PnP-ADMM? Can we estimate the convergence rate? In this letter, we resolve these questions using the contraction mapping theorem: (i) for symmetric denoisers, we show that (under mild conditions) PnP-ISTA and PnP-ADMM exhibit linear convergence; and (ii) for kernel denoisers, we show that PnP-ISTA and PnP-ADMM converge linearly for image inpainting. We validate our theoretical findings using reconstruction experiments.
Padding-free Convolution based on Preservation of Differential Characteristics of Kernels
Sep 12, 2023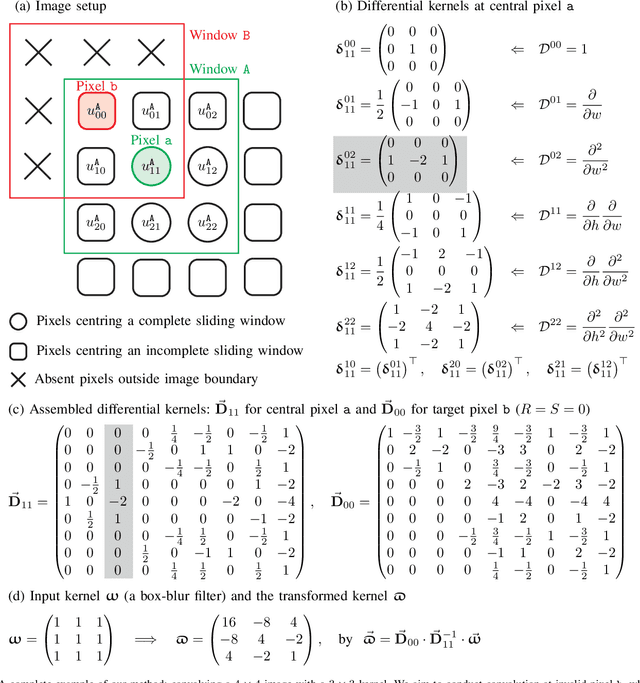
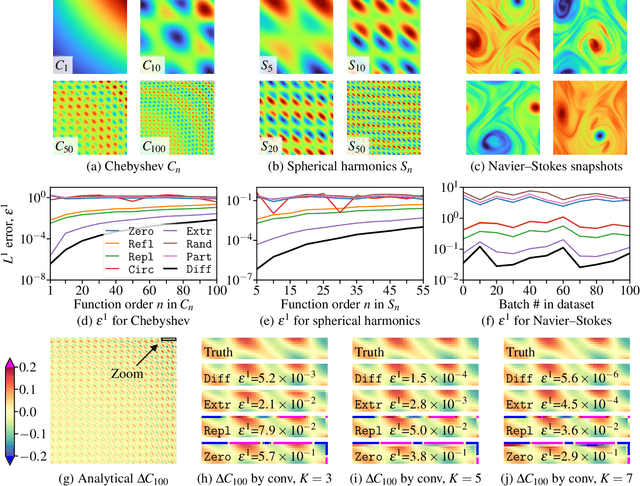
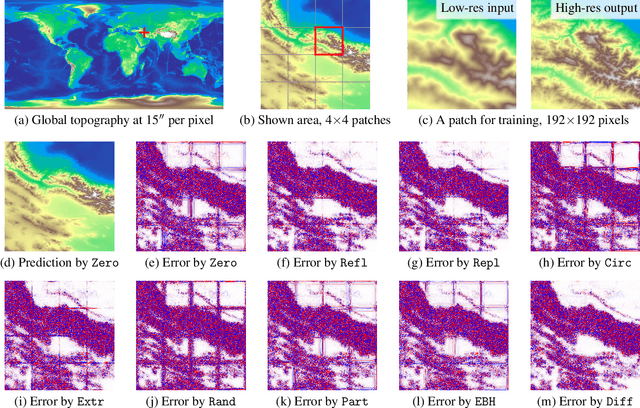
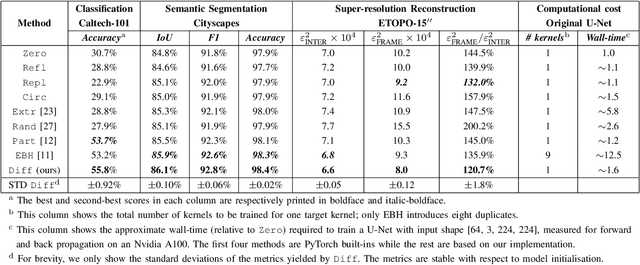
Convolution is a fundamental operation in image processing and machine learning. Aimed primarily at maintaining image size, padding is a key ingredient of convolution, which, however, can introduce undesirable boundary effects. We present a non-padding-based method for size-keeping convolution based on the preservation of differential characteristics of kernels. The main idea is to make convolution over an incomplete sliding window "collapse" to a linear differential operator evaluated locally at its central pixel, which no longer requires information from the neighbouring missing pixels. While the underlying theory is rigorous, our final formula turns out to be simple: the convolution over an incomplete window is achieved by convolving its nearest complete window with a transformed kernel. This formula is computationally lightweight, involving neither interpolation or extrapolation nor restrictions on image and kernel sizes. Our method favours data with smooth boundaries, such as high-resolution images and fields from physics. Our experiments include: i) filtering analytical and non-analytical fields from computational physics and, ii) training convolutional neural networks (CNNs) for the tasks of image classification, semantic segmentation and super-resolution reconstruction. In all these experiments, our method has exhibited visible superiority over the compared ones.
Multi-scale Target-Aware Framework for Constrained Image Splicing Detection and Localization
Aug 21, 2023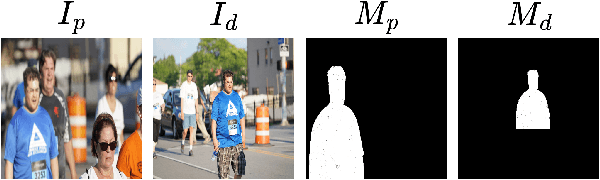
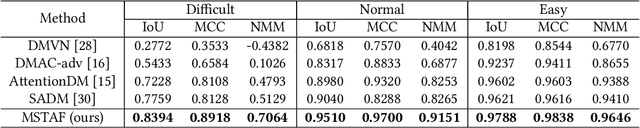
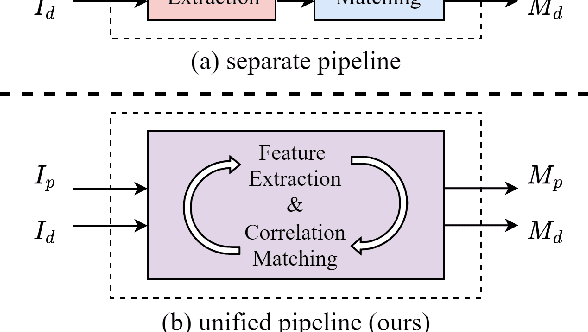
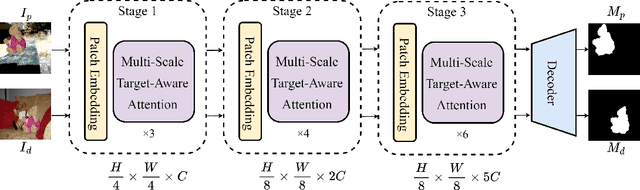
Constrained image splicing detection and localization (CISDL) is a fundamental task of multimedia forensics, which detects splicing operation between two suspected images and localizes the spliced region on both images. Recent works regard it as a deep matching problem and have made significant progress. However, existing frameworks typically perform feature extraction and correlation matching as separate processes, which may hinder the model's ability to learn discriminative features for matching and can be susceptible to interference from ambiguous background pixels. In this work, we propose a multi-scale target-aware framework to couple feature extraction and correlation matching in a unified pipeline. In contrast to previous methods, we design a target-aware attention mechanism that jointly learns features and performs correlation matching between the probe and donor images. Our approach can effectively promote the collaborative learning of related patches, and perform mutual promotion of feature learning and correlation matching. Additionally, in order to handle scale transformations, we introduce a multi-scale projection method, which can be readily integrated into our target-aware framework that enables the attention process to be conducted between tokens containing information of varying scales. Our experiments demonstrate that our model, which uses a unified pipeline, outperforms state-of-the-art methods on several benchmark datasets and is robust against scale transformations.
Linear Progressive Coding for Semantic Communication using Deep Neural Networks
Sep 27, 2023We propose a general method for semantic representation of images and other data using progressive coding. Semantic coding allows for specific pieces of information to be selectively encoded into a set of measurements that can be highly compressed compared to the size of the original raw data. We consider a hierarchical method of coding where a partial amount of semantic information is first encoded a into a coarse representation of the data, which is then refined by additional encodings that add additional semantic information. Such hierarchical coding is especially well-suited for semantic communication i.e. transferring semantic information over noisy channels. Our proposed method can be considered as a generalization of both progressive image compression and source coding for semantic communication. We present results from experiments on the MNIST and CIFAR-10 datasets that show that progressive semantic coding can provide timely previews of semantic information with a small number of initial measurements while achieving overall accuracy and efficiency comparable to non-progressive methods.
Subjective Face Transform using Human First Impressions
Sep 27, 2023
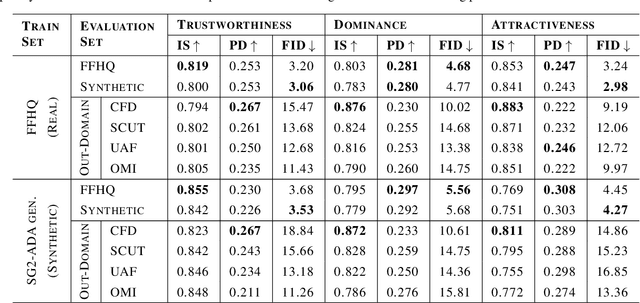
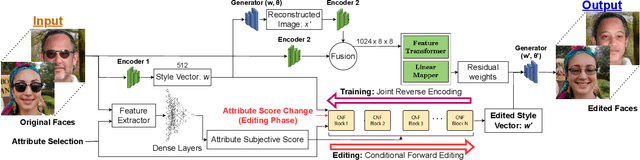
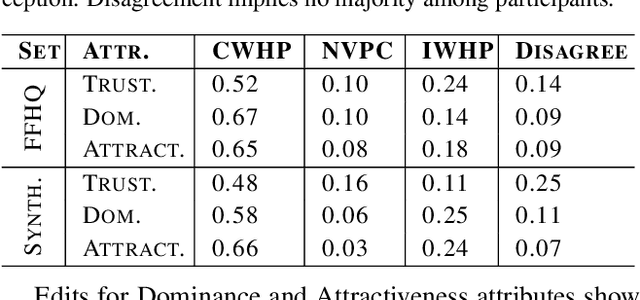
Humans tend to form quick subjective first impressions of non-physical attributes when seeing someone's face, such as perceived trustworthiness or attractiveness. To understand what variations in a face lead to different subjective impressions, this work uses generative models to find semantically meaningful edits to a face image that change perceived attributes. Unlike prior work that relied on statistical manipulation in feature space, our end-to-end framework considers trade-offs between preserving identity and changing perceptual attributes. It maps identity-preserving latent space directions to changes in attribute scores, enabling transformation of any input face along an attribute axis according to a target change. We train on real and synthetic faces, evaluate for in-domain and out-of-domain images using predictive models and human ratings, demonstrating the generalizability of our approach. Ultimately, such a framework can be used to understand and explain biases in subjective interpretation of faces that are not dependent on the identity.
Physics-Based Rigid Body Object Tracking and Friction Filtering From RGB-D Videos
Sep 27, 2023Physics-based understanding of object interactions from sensory observations is an essential capability in augmented reality and robotics. It enables capturing the properties of a scene for simulation and control. In this paper, we propose a novel approach for real-to-sim which tracks rigid objects in 3D from RGB-D images and infers physical properties of the objects. We use a differentiable physics simulation as state-transition model in an Extended Kalman Filter which can model contact and friction for arbitrary mesh-based shapes and in this way estimate physically plausible trajectories. We demonstrate that our approach can filter position, orientation, velocities, and concurrently can estimate the coefficient of friction of the objects. We analyse our approach on various sliding scenarios in synthetic image sequences of single objects and colliding objects. We also demonstrate and evaluate our approach on a real-world dataset. We will make our novel benchmark datasets publicly available to foster future research in this novel problem setting and comparison with our method.