 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Deep Neural Networks to Quantify Parking Dwell Time
Oct 31, 2024In smart cities, it is common practice to define a maximum length of stay for a given parking space to increase the space's rotativity and discourage the usage of individual transportation solutions. However, automatically determining individual car dwell times from images faces challenges, such as images collected from low-resolution cameras, lighting variations, and weather effects. In this work, we propose a method that combines two deep neural networks to compute the dwell time of each car in a parking lot. The proposed method first defines the parking space status between occupied and empty using a deep classification network. Then, it uses a Siamese network to check if the parked car is the same as the previous image. Using an experimental protocol that focuses on a cross-dataset scenario, we show that if a perfect classifier is used, the proposed system generates 75% of perfect dwell time predictions, where the predicted value matched exactly the time the car stayed parked. Nevertheless, our experiments show a drop in prediction quality when a real-world classifier is used to predict the parking space statuses, reaching 49% of perfect predictions, showing that the proposed Siamese network is promising but impacted by the quality of the classifier used at the beginning of the pipeline.
Deep Single Models vs. Ensembles: Insights for a Fast Deployment of Parking Monitoring Systems
Sep 28, 2023Searching for available parking spots in high-density urban centers is a stressful task for drivers that can be mitigated by systems that know in advance the nearest parking space available. To this end, image-based systems offer cost advantages over other sensor-based alternatives (e.g., ultrasonic sensors), requiring less physical infrastructure for installation and maintenance. Despite recent deep learning advances, deploying intelligent parking monitoring is still a challenge since most approaches involve collecting and labeling large amounts of data, which is laborious and time-consuming. Our study aims to uncover the challenges in creating a global framework, trained using publicly available labeled parking lot images, that performs accurately across diverse scenarios, enabling the parking space monitoring as a ready-to-use system to deploy in a new environment. Through exhaustive experiments involving different datasets and deep learning architectures, including fusion strategies and ensemble methods, we found that models trained on diverse datasets can achieve 95\% accuracy without the burden of data annotation and model training on the target parking lot
A Systematic Review on Computer Vision-Based Parking Lot Management Applied on Public Datasets
Mar 12, 2022
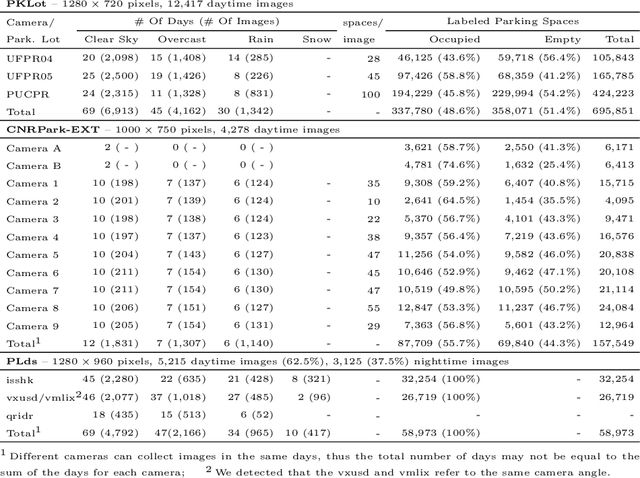

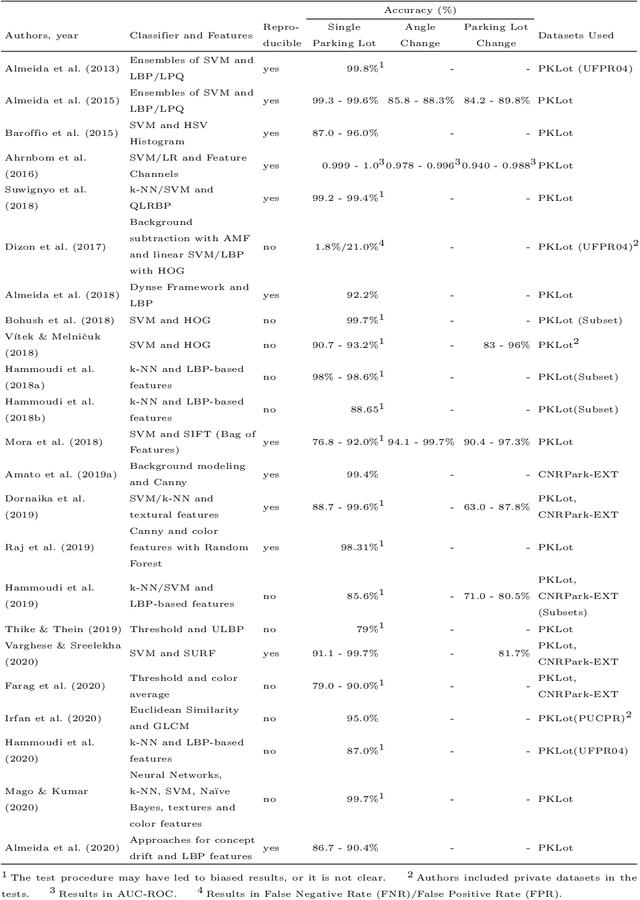
Computer vision-based parking lot management methods have been extensively researched upon owing to their flexibility and cost-effectiveness. To evaluate such methods authors often employ publicly available parking lot image datasets. In this study, we surveyed and compared robust publicly available image datasets specifically crafted to test computer vision-based methods for parking lot management approaches and consequently present a systematic and comprehensive review of existing works that employ such datasets. The literature review identified relevant gaps that require further research, such as the requirement of dataset-independent approaches and methods suitable for autonomous detection of position of parking spaces. In addition, we have noticed that several important factors such as the presence of the same cars across consecutive images, have been neglected in most studies, thereby rendering unrealistic assessment protocols. Furthermore, the analysis of the datasets also revealed that certain features that should be present when developing new benchmarks, such as the availability of video sequences and images taken in more diverse conditions, including nighttime and snow, have not been incorporated.