 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffColor: Toward High Fidelity Text-Guided Image Colorization with Diffusion Models
Aug 03, 2023
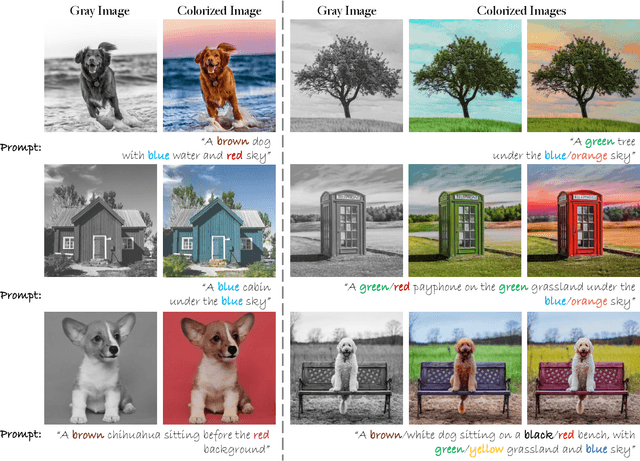
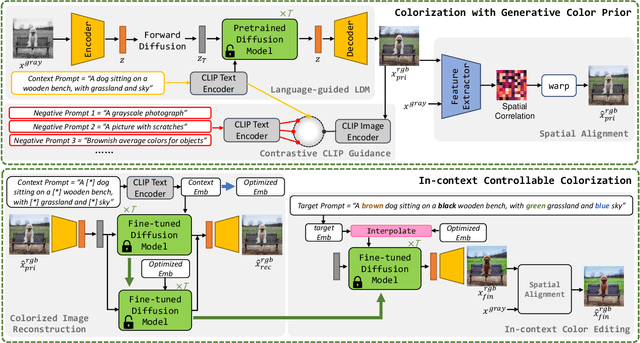
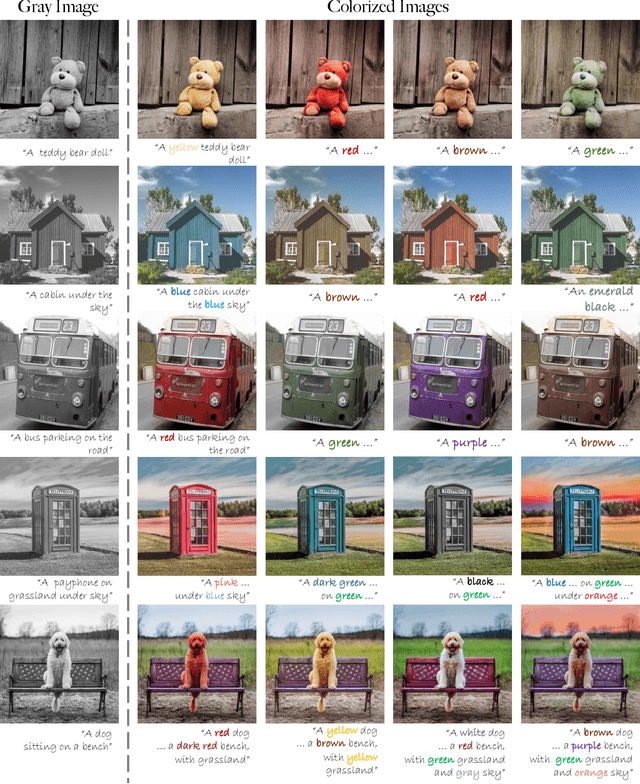

Recent data-driven image colorization methods have enabled automatic or reference-based colorization, while still suffering from unsatisfactory and inaccurate object-level color control. To address these issues, we propose a new method called DiffColor that leverages the power of pre-trained diffusion models to recover vivid colors conditioned on a prompt text, without any additional inputs. DiffColor mainly contains two stages: colorization with generative color prior and in-context controllable colorization. Specifically, we first fine-tune a pre-trained text-to-image model to generate colorized images using a CLIP-based contrastive loss. Then we try to obtain an optimized text embedding aligning the colorized image and the text prompt, and a fine-tuned diffusion model enabling high-quality image reconstruction. Our method can produce vivid and diverse colors with a few iterations, and keep the structure and background intact while having colors well-aligned with the target language guidance. Moreover, our method allows for in-context colorization, i.e., producing different colorization results by modifying prompt texts without any fine-tuning, and can achieve object-level controllable colorization results. Extensive experiments and user studies demonstrate that DiffColor outperforms previous works in terms of visual quality, color fidelity, and diversity of colorization options.
Grounded Image Text Matching with Mismatched Relation Reasoning
Aug 02, 2023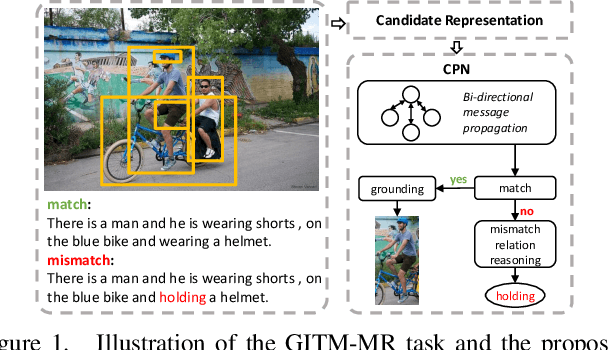

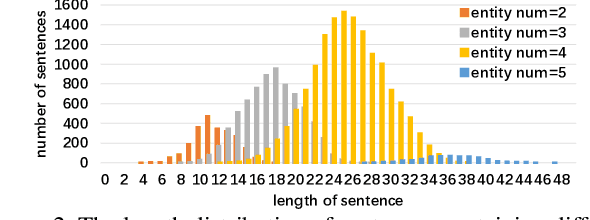
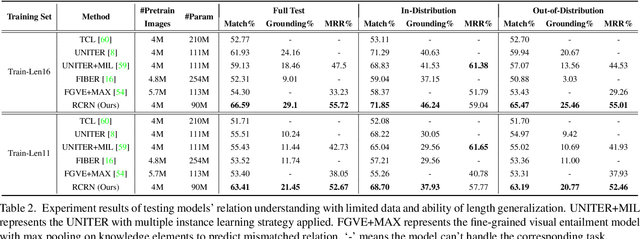
This paper introduces Grounded Image Text Matching with Mismatched Relation (GITM-MR), a novel visual-linguistic joint task that evaluates the relation understanding capabilities of transformer-based pre-trained models. GITM-MR requires a model to first determine if an expression describes an image, then localize referred objects or ground the mismatched parts of the text. We provide a benchmark for evaluating pre-trained models on this task, with a focus on the challenging settings of limited data and out-of-distribution sentence lengths. Our evaluation demonstrates that pre-trained models lack data efficiency and length generalization ability. To address this, we propose the Relation-sensitive Correspondence Reasoning Network (RCRN), which incorporates relation-aware reasoning via bi-directional message propagation guided by language structure. RCRN can be interpreted as a modular program and delivers strong performance in both length generalization and data efficiency.
Event-Driven Imaging in Turbid Media: A Confluence of Optoelectronics and Neuromorphic Computation
Sep 13, 2023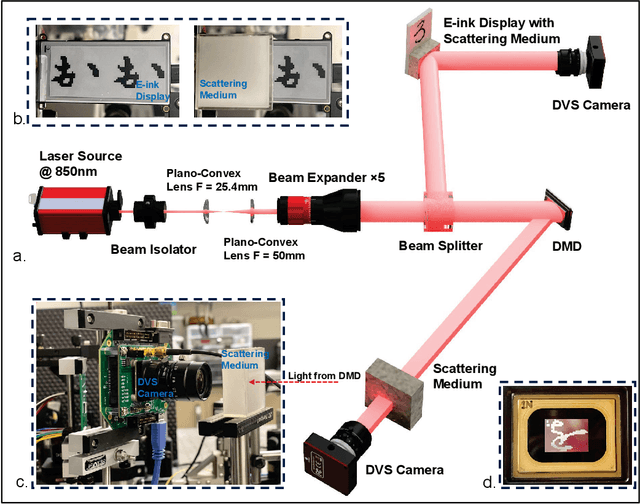
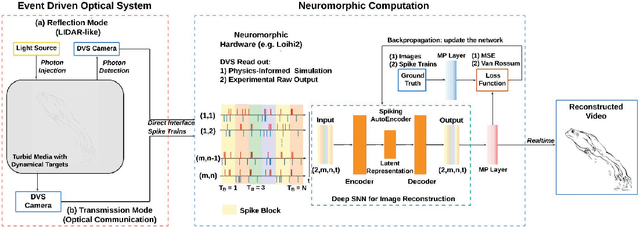
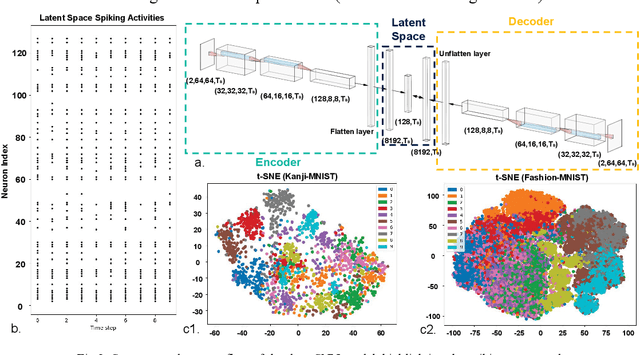

In this paper a new optical-computational method is introduced to unveil images of targets whose visibility is severely obscured by light scattering in dense, turbid media. The targets of interest are taken to be dynamic in that their optical properties are time-varying whether stationary in space or moving. The scheme, to our knowledge the first of its kind, is human vision inspired whereby diffuse photons collected from the turbid medium are first transformed to spike trains by a dynamic vision sensor as in the retina, and image reconstruction is then performed by a neuromorphic computing approach mimicking the brain. We combine benchtop experimental data in both reflection (backscattering) and transmission geometries with support from physics-based simulations to develop a neuromorphic computational model and then apply this for image reconstruction of different MNIST characters and image sets by a dedicated deep spiking neural network algorithm. Image reconstruction is achieved under conditions of turbidity where an original image is unintelligible to the human eye or a digital video camera, yet clearly and quantifiable identifiable when using the new neuromorphic computational approach.
Generalized Schrödinger Bridge Matching
Oct 03, 2023Modern distribution matching algorithms for training diffusion or flow models directly prescribe the time evolution of the marginal distributions between two boundary distributions. In this work, we consider a generalized distribution matching setup, where these marginals are only implicitly described as a solution to some task-specific objective function. The problem setup, known as the Generalized Schr\"odinger Bridge (GSB), appears prevalently in many scientific areas both within and without machine learning. We propose Generalized Schr\"odinger Bridge Matching (GSBM), a new matching algorithm inspired by recent advances, generalizing them beyond kinetic energy minimization and to account for task-specific state costs. We show that such a generalization can be cast as solving conditional stochastic optimal control, for which efficient variational approximations can be used, and further debiased with the aid of path integral theory. Compared to prior methods for solving GSB problems, our GSBM algorithm always preserves a feasible transport map between the boundary distributions throughout training, thereby enabling stable convergence and significantly improved scalability. We empirically validate our claims on an extensive suite of experimental setups, including crowd navigation, opinion depolarization, LiDAR manifolds, and image domain transfer. Our work brings new algorithmic opportunities for training diffusion models enhanced with task-specific optimality structures.
ScaleNet: An Unsupervised Representation Learning Method for Limited Information
Oct 03, 2023Although large-scale labeled data are essential for deep convolutional neural networks (ConvNets) to learn high-level semantic visual representations, it is time-consuming and impractical to collect and annotate large-scale datasets. A simple and efficient unsupervised representation learning method named ScaleNet based on multi-scale images is proposed in this study to enhance the performance of ConvNets when limited information is available. The input images are first resized to a smaller size and fed to the ConvNet to recognize the rotation degree. Next, the ConvNet learns the rotation-prediction task for the original size images based on the parameters transferred from the previous model. The CIFAR-10 and ImageNet datasets are examined on different architectures such as AlexNet and ResNet50 in this study. The current study demonstrates that specific image features, such as Harris corner information, play a critical role in the efficiency of the rotation-prediction task. The ScaleNet supersedes the RotNet by ~7% in the limited CIFAR-10 dataset. The transferred parameters from a ScaleNet model with limited data improve the ImageNet Classification task by about 6% compared to the RotNet model. This study shows the capability of the ScaleNet method to improve other cutting-edge models such as SimCLR by learning effective features for classification tasks.
HallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision Language Models for Detailed Caption
Oct 03, 2023
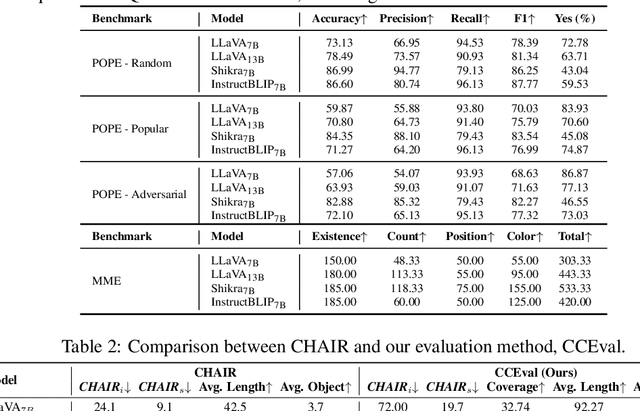

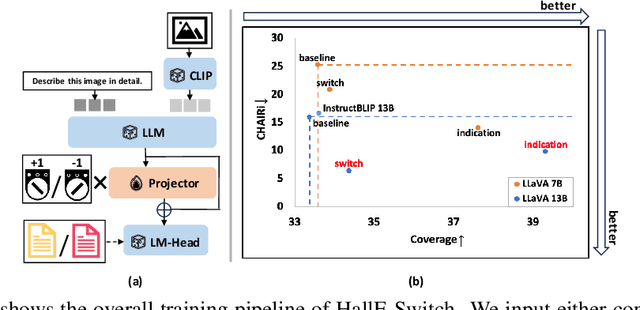
Current large vision-language models (LVLMs) achieve remarkable progress, yet there remains significant uncertainty regarding their ability to accurately apprehend visual details, that is, in performing detailed captioning. To address this, we introduce \textit{CCEval}, a GPT-4 assisted evaluation method tailored for detailed captioning. Interestingly, while LVLMs demonstrate minimal object existence hallucination in existing VQA benchmarks, our proposed evaluation reveals continued susceptibility to such hallucinations. In this paper, we make the first attempt to investigate and attribute such hallucinations, including image resolution, the language decoder size, and instruction data amount, quality, granularity. Our findings underscore the unwarranted inference when the language description includes details at a finer object granularity than what the vision module can ground or verify, thus inducing hallucination. To control such hallucinations, we further attribute the reliability of captioning to contextual knowledge (involving only contextually grounded objects) and parametric knowledge (containing inferred objects by the model). Thus, we introduce $\textit{HallE-Switch}$, a controllable LVLM in terms of $\textbf{Hall}$ucination in object $\textbf{E}$xistence. HallE-Switch can condition the captioning to shift between (i) exclusively depicting contextual knowledge for grounded objects and (ii) blending it with parametric knowledge to imagine inferred objects. Our method reduces hallucination by 44% compared to LLaVA$_{7B}$ and maintains the same object coverage.
An End-to-end Food Portion Estimation Framework Based on Shape Reconstruction from Monocular Image
Aug 03, 2023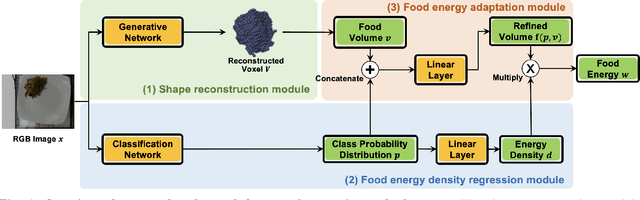
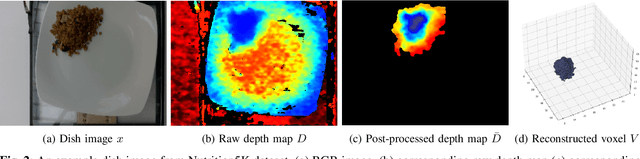


Dietary assessment is a key contributor to monitoring health status. Existing self-report methods are tedious and time-consuming with substantial biases and errors. Image-based food portion estimation aims to estimate food energy values directly from food images, showing great potential for automated dietary assessment solutions. Existing image-based methods either use a single-view image or incorporate multi-view images and depth information to estimate the food energy, which either has limited performance or creates user burdens. In this paper, we propose an end-to-end deep learning framework for food energy estimation from a monocular image through 3D shape reconstruction. We leverage a generative model to reconstruct the voxel representation of the food object from the input image to recover the missing 3D information. Our method is evaluated on a publicly available food image dataset Nutrition5k, resulting a Mean Absolute Error (MAE) of 40.05 kCal and Mean Absolute Percentage Error (MAPE) of 11.47% for food energy estimation. Our method uses RGB image as the only input at the inference stage and achieves competitive results compared to the existing method requiring both RGB and depth information.
Weakly Supervised Semantic Segmentation by Knowledge Graph Inference
Sep 25, 2023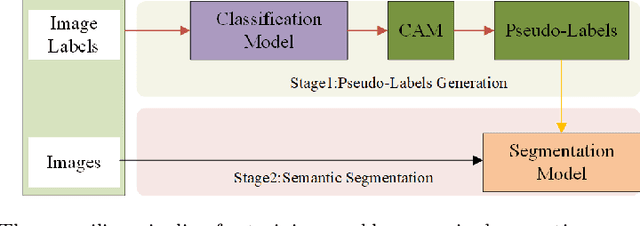
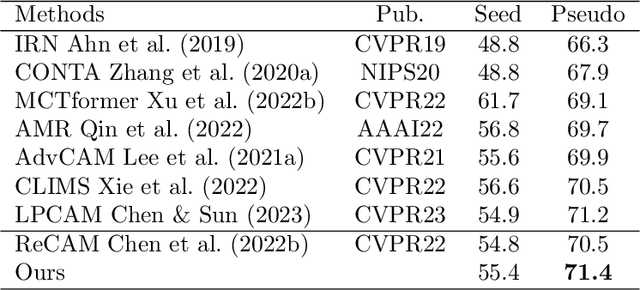
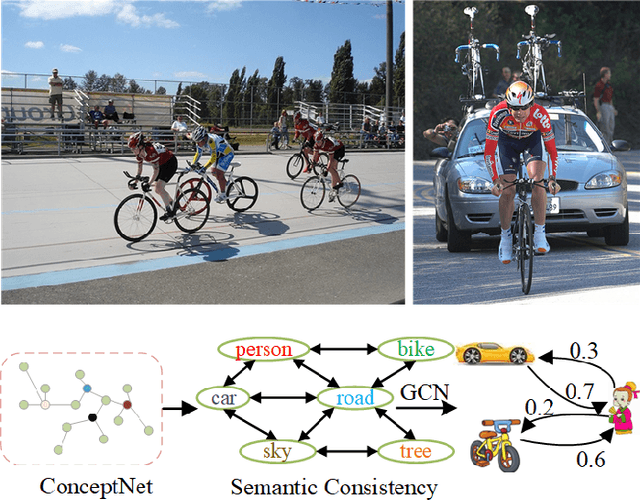
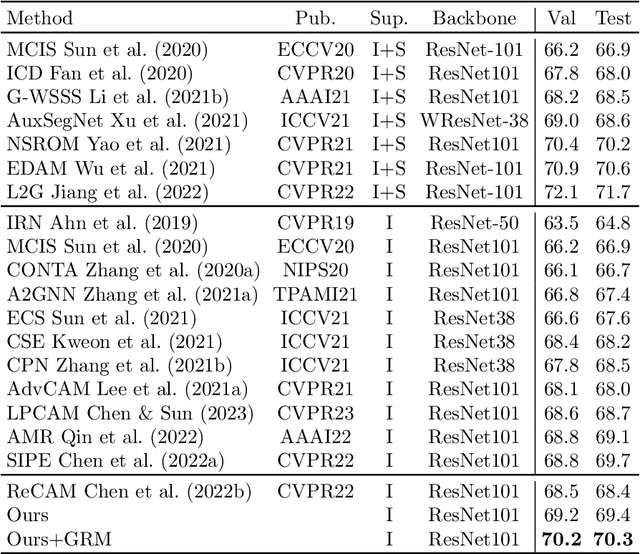
Currently, existing efforts in Weakly Supervised Semantic Segmentation (WSSS) based on Convolutional Neural Networks (CNNs) have predominantly focused on enhancing the multi-label classification network stage, with limited attention given to the equally important downstream segmentation network. Furthermore, CNN-based local convolutions lack the ability to model the extensive inter-category dependencies. Therefore, this paper introduces a graph reasoning-based approach to enhance WSSS. The aim is to improve WSSS holistically by simultaneously enhancing both the multi-label classification and segmentation network stages. In the multi-label classification network segment, external knowledge is integrated, coupled with GCNs, to globally reason about inter-class dependencies. This encourages the network to uncover features in non-salient regions of images, thereby refining the completeness of generated pseudo-labels. In the segmentation network segment, the proposed Graph Reasoning Mapping (GRM) module is employed to leverage knowledge obtained from textual databases, facilitating contextual reasoning for class representation within image regions. This GRM module enhances feature representation in high-level semantics of the segmentation network's local convolutions, while dynamically learning semantic coherence for individual samples. Using solely image-level supervision, we have achieved state-of-the-art performance in WSSS on the PASCAL VOC 2012 and MS-COCO datasets. Extensive experimentation on both the multi-label classification and segmentation network stages underscores the effectiveness of the proposed graph reasoning approach for advancing WSSS.
IBCL: Zero-shot Model Generation for Task Trade-offs in Continual Learning
Oct 05, 2023Like generic multi-task learning, continual learning has the nature of multi-objective optimization, and therefore faces a trade-off between the performance of different tasks. That is, to optimize for the current task distribution, it may need to compromise performance on some previous tasks. This means that there exist multiple models that are Pareto-optimal at different times, each addressing a distinct task performance trade-off. Researchers have discussed how to train particular models to address specific trade-off preferences. However, existing algorithms require training overheads proportional to the number of preferences -- a large burden when there are multiple, possibly infinitely many, preferences. As a response, we propose Imprecise Bayesian Continual Learning (IBCL). Upon a new task, IBCL (1) updates a knowledge base in the form of a convex hull of model parameter distributions and (2) obtains particular models to address task trade-off preferences with zero-shot. That is, IBCL does not require any additional training overhead to generate preference-addressing models from its knowledge base. We show that models obtained by IBCL have guarantees in identifying the Pareto optimal parameters. Moreover, experiments on standard image classification and NLP tasks support this guarantee. Statistically, IBCL improves average per-task accuracy by at most 23\% and peak per-task accuracy by at most 15\% with respect to the baseline methods, with steadily near-zero or positive backward transfer. Most importantly, IBCL significantly reduces the training overhead from training 1 model per preference to at most 3 models for all preferences.
Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Constraints
Oct 05, 2023Text-driven 3D indoor scene generation could be useful for gaming, film industry, and AR/VR applications. However, existing methods cannot faithfully capture the room layout, nor do they allow flexible editing of individual objects in the room. To address these problems, we present Ctrl-Room, which is able to generate convincing 3D rooms with designer-style layouts and high-fidelity textures from just a text prompt. Moreover, Ctrl-Room enables versatile interactive editing operations such as resizing or moving individual furniture items. Our key insight is to separate the modeling of layouts and appearance. %how to model the room that takes into account both scene texture and geometry at the same time. To this end, Our proposed method consists of two stages, a `Layout Generation Stage' and an `Appearance Generation Stage'. The `Layout Generation Stage' trains a text-conditional diffusion model to learn the layout distribution with our holistic scene code parameterization. Next, the `Appearance Generation Stage' employs a fine-tuned ControlNet to produce a vivid panoramic image of the room guided by the 3D scene layout and text prompt. In this way, we achieve a high-quality 3D room with convincing layouts and lively textures. Benefiting from the scene code parameterization, we can easily edit the generated room model through our mask-guided editing module, without expensive editing-specific training. Extensive experiments on the Structured3D dataset demonstrate that our method outperforms existing methods in producing more reasonable, view-consistent, and editable 3D rooms from natural language prompts.