 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enhancing Ship Classification in Optical Satellite Imagery: Integrating Convolutional Block Attention Module with ResNet for Improved Performance
Apr 08, 2024
This study presents an advanced Convolutional Neural Network (CNN) architecture for ship classification from optical satellite imagery, significantly enhancing performance through the integration of the Convolutional Block Attention Module (CBAM) and additional architectural innovations. Building upon the foundational ResNet50 model, we first incorporated a standard CBAM to direct the model's focus towards more informative features, achieving an accuracy of 87% compared to the baseline ResNet50's 85%. Further augmentations involved multi-scale feature integration, depthwise separable convolutions, and dilated convolutions, culminating in the Enhanced ResNet Model with Improved CBAM. This model demonstrated a remarkable accuracy of 95%, with precision, recall, and f1-scores all witnessing substantial improvements across various ship classes. The bulk carrier and oil tanker classes, in particular, showcased nearly perfect precision and recall rates, underscoring the model's enhanced capability in accurately identifying and classifying ships. Attention heatmap analyses further validated the improved model's efficacy, revealing a more focused attention on relevant ship features, regardless of background complexities. These findings underscore the potential of integrating attention mechanisms and architectural innovations in CNNs for high-resolution satellite imagery classification. The study navigates through the challenges of class imbalance and computational costs, proposing future directions towards scalability and adaptability in new or rare ship type recognition. This research lays a groundwork for the application of advanced deep learning techniques in the domain of remote sensing, offering insights into scalable and efficient satellite image classification.
No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance
Apr 08, 2024Web-crawled pretraining datasets underlie the impressive "zero-shot" evaluation performance of multimodal models, such as CLIP for classification/retrieval and Stable-Diffusion for image generation. However, it is unclear how meaningful the notion of "zero-shot" generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during "zero-shot" evaluation. In this work, we ask: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets? We comprehensively investigate this question across 34 models and five standard pretraining datasets (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-Aesthetics), generating over 300GB of data artifacts. We consistently find that, far from exhibiting "zero-shot" generalization, multimodal models require exponentially more data to achieve linear improvements in downstream "zero-shot" performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets, and testing on purely synthetic data distributions. Furthermore, upon benchmarking models on long-tailed data sampled based on our analysis, we demonstrate that multimodal models across the board perform poorly. We contribute this long-tail test set as the "Let it Wag!" benchmark to further research in this direction. Taken together, our study reveals an exponential need for training data which implies that the key to "zero-shot" generalization capabilities under large-scale training paradigms remains to be found.
Step-Calibrated Diffusion for Biomedical Optical Image Restoration
Mar 20, 2024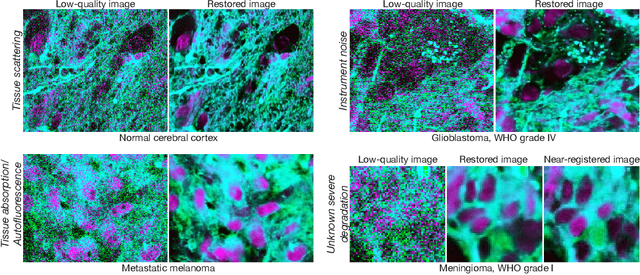

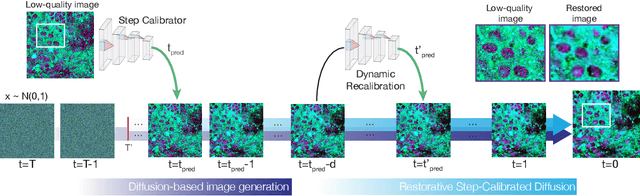
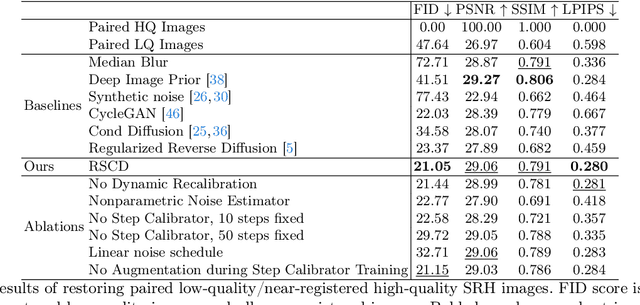
High-quality, high-resolution medical imaging is essential for clinical care. Raman-based biomedical optical imaging uses non-ionizing infrared radiation to evaluate human tissues in real time and is used for early cancer detection, brain tumor diagnosis, and intraoperative tissue analysis. Unfortunately, optical imaging is vulnerable to image degradation due to laser scattering and absorption, which can result in diagnostic errors and misguided treatment. Restoration of optical images is a challenging computer vision task because the sources of image degradation are multi-factorial, stochastic, and tissue-dependent, preventing a straightforward method to obtain paired low-quality/high-quality data. Here, we present Restorative Step-Calibrated Diffusion (RSCD), an unpaired image restoration method that views the image restoration problem as completing the finishing steps of a diffusion-based image generation task. RSCD uses a step calibrator model to dynamically determine the severity of image degradation and the number of steps required to complete the reverse diffusion process for image restoration. RSCD outperforms other widely used unpaired image restoration methods on both image quality and perceptual evaluation metrics for restoring optical images. Medical imaging experts consistently prefer images restored using RSCD in blinded comparison experiments and report minimal to no hallucinations. Finally, we show that RSCD improves performance on downstream clinical imaging tasks, including automated brain tumor diagnosis and deep tissue imaging. Our code is available at https://github.com/MLNeurosurg/restorative_step-calibrated_diffusion.
Plaintext-Free Deep Learning for Privacy-Preserving Medical Image Analysis via Frequency Information Embedding
Mar 25, 2024In the fast-evolving field of medical image analysis, Deep Learning (DL)-based methods have achieved tremendous success. However, these methods require plaintext data for training and inference stages, raising privacy concerns, especially in the sensitive area of medical data. To tackle these concerns, this paper proposes a novel framework that uses surrogate images for analysis, eliminating the need for plaintext images. This approach is called Frequency-domain Exchange Style Fusion (FESF). The framework includes two main components: Image Hidden Module (IHM) and Image Quality Enhancement Module~(IQEM). The~IHM performs in the frequency domain, blending the features of plaintext medical images into host medical images, and then combines this with IQEM to improve and create surrogate images effectively. During the diagnostic model training process, only surrogate images are used, enabling anonymous analysis without any plaintext data during both training and inference stages. Extensive evaluations demonstrate that our framework effectively preserves the privacy of medical images and maintains diagnostic accuracy of DL models at a relatively high level, proving its effectiveness across various datasets and DL-based models.
Robust Concept Erasure Using Task Vectors
Apr 04, 2024With the rapid growth of text-to-image models, a variety of techniques have been suggested to prevent undesirable image generations. Yet, these methods often only protect against specific user prompts and have been shown to allow unsafe generations with other inputs. Here we focus on unconditionally erasing a concept from a text-to-image model rather than conditioning the erasure on the user's prompt. We first show that compared to input-dependent erasure methods, concept erasure that uses Task Vectors (TV) is more robust to unexpected user inputs, not seen during training. However, TV-based erasure can also affect the core performance of the edited model, particularly when the required edit strength is unknown. To this end, we propose a method called Diverse Inversion, which we use to estimate the required strength of the TV edit. Diverse Inversion finds within the model input space a large set of word embeddings, each of which induces the generation of the target concept. We find that encouraging diversity in the set makes our estimation more robust to unexpected prompts. Finally, we show that Diverse Inversion enables us to apply a TV edit only to a subset of the model weights, enhancing the erasure capabilities while better maintaining the core functionality of the model.
Unsegment Anything by Simulating Deformation
Apr 03, 2024Foundation segmentation models, while powerful, pose a significant risk: they enable users to effortlessly extract any objects from any digital content with a single click, potentially leading to copyright infringement or malicious misuse. To mitigate this risk, we introduce a new task "Anything Unsegmentable" to grant any image "the right to be unsegmented". The ambitious pursuit of the task is to achieve highly transferable adversarial attacks against all prompt-based segmentation models, regardless of model parameterizations and prompts. We highlight the non-transferable and heterogeneous nature of prompt-specific adversarial noises. Our approach focuses on disrupting image encoder features to achieve prompt-agnostic attacks. Intriguingly, targeted feature attacks exhibit better transferability compared to untargeted ones, suggesting the optimal update direction aligns with the image manifold. Based on the observations, we design a novel attack named Unsegment Anything by Simulating Deformation (UAD). Our attack optimizes a differentiable deformation function to create a target deformed image, which alters structural information while preserving achievable feature distance by adversarial example. Extensive experiments verify the effectiveness of our approach, compromising a variety of promptable segmentation models with different architectures and prompt interfaces. We release the code at https://github.com/jiahaolu97/anything-unsegmentable.
Deep Generative Model based Rate-Distortion for Image Downscaling Assessment
Mar 22, 2024In this paper, we propose Image Downscaling Assessment by Rate-Distortion (IDA-RD), a novel measure to quantitatively evaluate image downscaling algorithms. In contrast to image-based methods that measure the quality of downscaled images, ours is process-based that draws ideas from rate-distortion theory to measure the distortion incurred during downscaling. Our main idea is that downscaling and super-resolution (SR) can be viewed as the encoding and decoding processes in the rate-distortion model, respectively, and that a downscaling algorithm that preserves more details in the resulting low-resolution (LR) images should lead to less distorted high-resolution (HR) images in SR. In other words, the distortion should increase as the downscaling algorithm deteriorates. However, it is non-trivial to measure this distortion as it requires the SR algorithm to be blind and stochastic. Our key insight is that such requirements can be met by recent SR algorithms based on deep generative models that can find all matching HR images for a given LR image on their learned image manifolds. Extensive experimental results show the effectiveness of our IDA-RD measure.
JDEC: JPEG Decoding via Enhanced Continuous Cosine Coefficients
Apr 03, 2024We propose a practical approach to JPEG image decoding, utilizing a local implicit neural representation with continuous cosine formulation. The JPEG algorithm significantly quantizes discrete cosine transform (DCT) spectra to achieve a high compression rate, inevitably resulting in quality degradation while encoding an image. We have designed a continuous cosine spectrum estimator to address the quality degradation issue that restores the distorted spectrum. By leveraging local DCT formulations, our network has the privilege to exploit dequantization and upsampling simultaneously. Our proposed model enables decoding compressed images directly across different quality factors using a single pre-trained model without relying on a conventional JPEG decoder. As a result, our proposed network achieves state-of-the-art performance in flexible color image JPEG artifact removal tasks. Our source code is available at https://github.com/WooKyoungHan/JDEC.
CAM-Based Methods Can See through Walls
Apr 02, 2024CAM-based methods are widely-used post-hoc interpretability method that produce a saliency map to explain the decision of an image classification model. The saliency map highlights the important areas of the image relevant to the prediction. In this paper, we show that most of these methods can incorrectly attribute an important score to parts of the image that the model cannot see. We show that this phenomenon occurs both theoretically and experimentally. On the theory side, we analyze the behavior of GradCAM on a simple masked CNN model at initialization. Experimentally, we train a VGG-like model constrained to not use the lower part of the image and nevertheless observe positive scores in the unseen part of the image. This behavior is evaluated quantitatively on two new datasets. We believe that this is problematic, potentially leading to mis-interpretation of the model's behavior.
Medical Image Data Provenance for Medical Cyber-Physical System
Mar 22, 2024Continuous advancements in medical technology have led to the creation of affordable mobile imaging devices suitable for telemedicine and remote monitoring. However, the rapid examination of large populations poses challenges, including the risk of fraudulent practices by healthcare professionals and social workers exchanging unverified images via mobile applications. To mitigate these risks, this study proposes using watermarking techniques to embed a device fingerprint (DFP) into captured images, ensuring data provenance. The DFP, representing the unique attributes of the capturing device and raw image, is embedded into raw images before storage, thus enabling verification of image authenticity and source. Moreover, a robust remote validation method is introduced to authenticate images, enhancing the integrity of medical image data in interconnected healthcare systems. Through a case study on mobile fundus imaging, the effectiveness of the proposed framework is evaluated in terms of computational efficiency, image quality, security, and trustworthiness. This approach is suitable for a range of applications, including telemedicine, the Internet of Medical Things (IoMT), eHealth, and Medical Cyber-Physical Systems (MCPS) applications, providing a reliable means to maintain data provenance in diagnostic settings utilizing medical images or videos.