 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ALPHA: AnomaLous Physiological Health Assessment Using Large Language Models
Nov 21, 2023
This study concentrates on evaluating the efficacy of Large Language Models (LLMs) in healthcare, with a specific focus on their application in personal anomalous health monitoring. Our research primarily investigates the capabilities of LLMs in interpreting and analyzing physiological data obtained from FDA-approved devices. We conducted an extensive analysis using anomalous physiological data gathered in a simulated low-air-pressure plateau environment. This allowed us to assess the precision and reliability of LLMs in understanding and evaluating users' health status with notable specificity. Our findings reveal that LLMs exhibit exceptional performance in determining medical indicators, including a Mean Absolute Error (MAE) of less than 1 beat per minute for heart rate and less than 1% for oxygen saturation (SpO2). Furthermore, the Mean Absolute Percentage Error (MAPE) for these evaluations remained below 1%, with the overall accuracy of health assessments surpassing 85%. In image analysis tasks, such as interpreting photoplethysmography (PPG) data, our specially adapted GPT models demonstrated remarkable proficiency, achieving less than 1 bpm error in cycle count and 7.28 MAE for heart rate estimation. This study highlights LLMs' dual role as health data analysis tools and pivotal elements in advanced AI health assistants, offering personalized health insights and recommendations within the future health assistant framework.
Two Views Are Better than One: Monocular 3D Pose Estimation with Multiview Consistency
Nov 21, 2023Deducing a 3D human pose from a single 2D image or 2D keypoints is inherently challenging, given the fundamental ambiguity wherein multiple 3D poses can correspond to the same 2D representation. The acquisition of 3D data, while invaluable for resolving pose ambiguity, is expensive and requires an intricate setup, often restricting its applicability to controlled lab environments. We improve performance of monocular human pose estimation models using multiview data for fine-tuning. We propose a novel loss function, multiview consistency, to enable adding additional training data with only 2D supervision. This loss enforces that the inferred 3D pose from one view aligns with the inferred 3D pose from another view under similarity transformations. Our consistency loss substantially improves performance for fine-tuning with no available 3D data. Our experiments demonstrate that two views offset by 90 degrees are enough to obtain good performance, with only marginal improvements by adding more views. Thus, we enable the acquisition of domain-specific data by capturing activities with off-the-shelf cameras, eliminating the need for elaborate calibration procedures. This research introduces new possibilities for domain adaptation in 3D pose estimation, providing a practical and cost-effective solution to customize models for specific applications. The used dataset, featuring additional views, will be made publicly available.
Enhancing mTBI Diagnosis with Residual Triplet Convolutional Neural Network Using 3D CT
Nov 23, 2023Mild Traumatic Brain Injury (mTBI) is a common and challenging condition to diagnose accurately. Timely and precise diagnosis is essential for effective treatment and improved patient outcomes. Traditional diagnostic methods for mTBI often have limitations in terms of accuracy and sensitivity. In this study, we introduce an innovative approach to enhance mTBI diagnosis using 3D Computed Tomography (CT) images and a metric learning technique trained with triplet loss. To address these challenges, we propose a Residual Triplet Convolutional Neural Network (RTCNN) model to distinguish between mTBI cases and healthy ones by embedding 3D CT scans into a feature space. The triplet loss function maximizes the margin between similar and dissimilar image pairs, optimizing feature representations. This facilitates better context placement of individual cases, aids informed decision-making, and has the potential to improve patient outcomes. Our RTCNN model shows promising performance in mTBI diagnosis, achieving an average accuracy of 94.3%, a sensitivity of 94.1%, and a specificity of 95.2%, as confirmed through a five-fold cross-validation. Importantly, when compared to the conventional Residual Convolutional Neural Network (RCNN) model, the RTCNN exhibits a significant improvement, showcasing a remarkable 22.5% increase in specificity, a notable 16.2% boost in accuracy, and an 11.3% enhancement in sensitivity. Moreover, RTCNN requires lower memory resources, making it not only highly effective but also resource-efficient in minimizing false positives while maximizing its diagnostic accuracy in distinguishing normal CT scans from mTBI cases. The quantitative performance metrics provided and utilization of occlusion sensitivity maps to visually explain the model's decision-making process further enhance the interpretability and transparency of our approach.
Creating and Benchmarking a Synthetic Dataset for Cloud Optical Thickness Estimation
Nov 23, 2023Cloud formations often obscure optical satellite-based monitoring of the Earth's surface, thus limiting Earth observation (EO) activities such as land cover mapping, ocean color analysis, and cropland monitoring. The integration of machine learning (ML) methods within the remote sensing domain has significantly improved performance on a wide range of EO tasks, including cloud detection and filtering, but there is still much room for improvement. A key bottleneck is that ML methods typically depend on large amounts of annotated data for training, which is often difficult to come by in EO contexts. This is especially true for the task of cloud optical thickness (COT) estimation. A reliable estimation of COT enables more fine-grained and application-dependent control compared to using pre-specified cloud categories, as is commonly done in practice. To alleviate the COT data scarcity problem, in this work we propose a novel synthetic dataset for COT estimation, where top-of-atmosphere radiances have been simulated for 12 of the spectral bands of the Multi-Spectral Instrument (MSI) sensor onboard Sentinel-2 platforms. These data points have been simulated under consideration of different cloud types, COTs, and ground surface and atmospheric profiles. Extensive experimentation of training several ML models to predict COT from the measured reflectivity of the spectral bands demonstrates the usefulness of our proposed dataset. Generalization to real data is also demonstrated on two satellite image datasets -- one that is publicly available, and one which we have collected and annotated. The synthetic data, the newly collected real dataset, code and models have been made publicly available at https://github.com/aleksispi/ml-cloud-opt-thick.
Deep Kernel and Image Quality Estimators for Optimizing Robotic Ultrasound Controller using Bayesian Optimization
Oct 11, 2023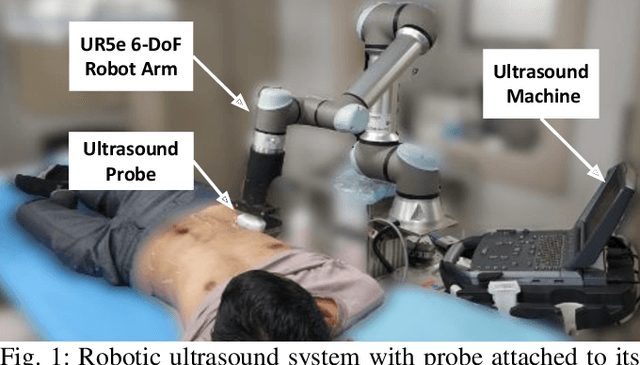

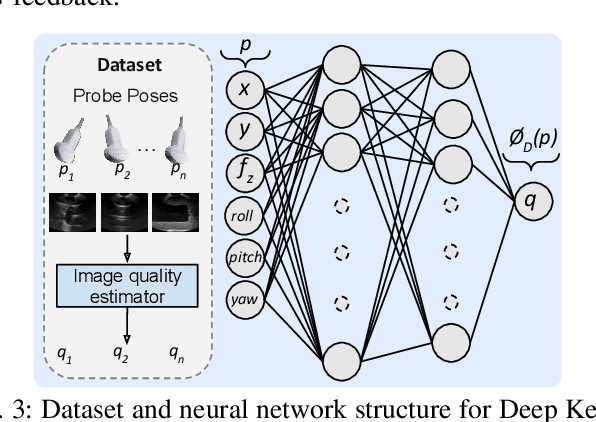

Ultrasound is a commonly used medical imaging modality that requires expert sonographers to manually maneuver the ultrasound probe based on the acquired image. Autonomous Robotic Ultrasound (A-RUS) is an appealing alternative to this manual procedure in order to reduce sonographers' workload. The key challenge to A-RUS is optimizing the ultrasound image quality for the region of interest across different patients. This requires knowledge of anatomy, recognition of error sources and precise probe position, orientation and pressure. Sample efficiency is important while optimizing these parameters associated with the robotized probe controller. Bayesian Optimization (BO), a sample-efficient optimization framework, has recently been applied to optimize the 2D motion of the probe. Nevertheless, further improvements are needed to improve the sample efficiency for high-dimensional control of the probe. We aim to overcome this problem by using a neural network to learn a low-dimensional kernel in BO, termed as Deep Kernel (DK). The neural network of DK is trained using probe and image data acquired during the procedure. The two image quality estimators are proposed that use a deep convolution neural network and provide real-time feedback to the BO. We validated our framework using these two feedback functions on three urinary bladder phantoms. We obtained over 50% increase in sample efficiency for 6D control of the robotized probe. Furthermore, our results indicate that this performance enhancement in BO is independent of the specific training dataset, demonstrating inter-patient adaptability.
Appearance Codes using Joint Embedding Learning of Multiple Modalities
Nov 19, 2023The use of appearance codes in recent work on generative modeling has enabled novel view renders with variable appearance and illumination, such as day-time and night-time renders of a scene. A major limitation of this technique is the need to re-train new appearance codes for every scene on inference, so in this work we address this problem proposing a framework that learns a joint embedding space for the appearance and structure of the scene by enforcing a contrastive loss constraint between different modalities. We apply our framework to a simple Variational Auto-Encoder model on the RADIATE dataset \cite{sheeny2021radiate} and qualitatively demonstrate that we can generate new renders of night-time photos using day-time appearance codes without additional optimization iterations. Additionally, we compare our model to a baseline VAE that uses the standard per-image appearance code technique and show that our approach achieves generations of similar quality without learning appearance codes for any unseen images on inference.
CMFDFormer: Transformer-based Copy-Move Forgery Detection with Continual Learning
Nov 22, 2023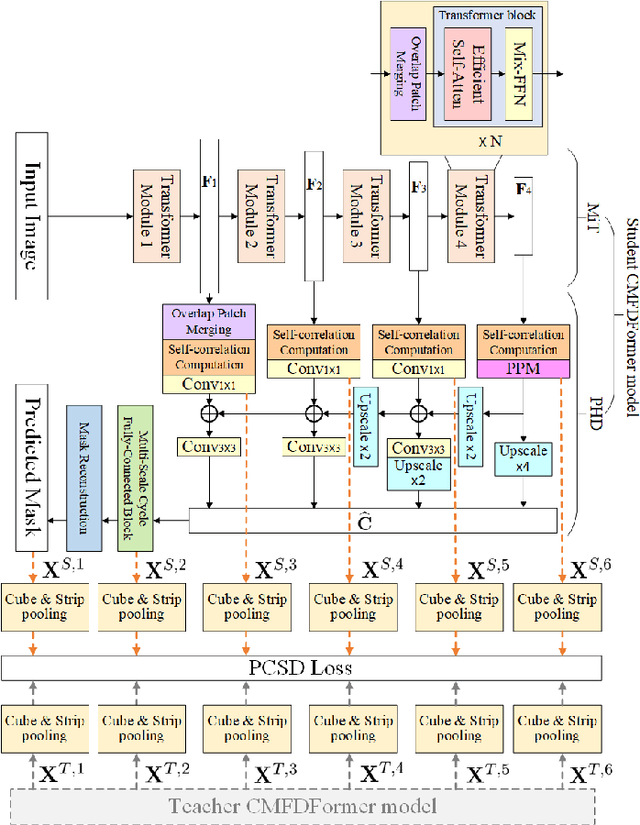
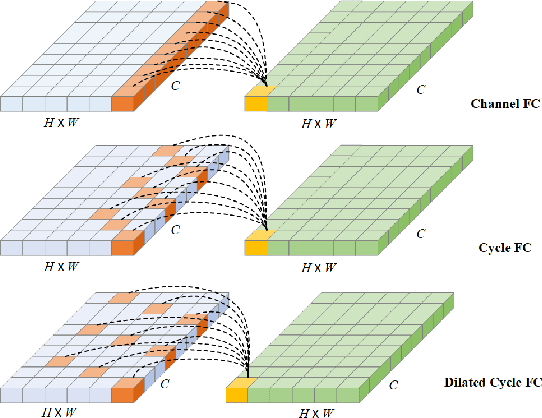
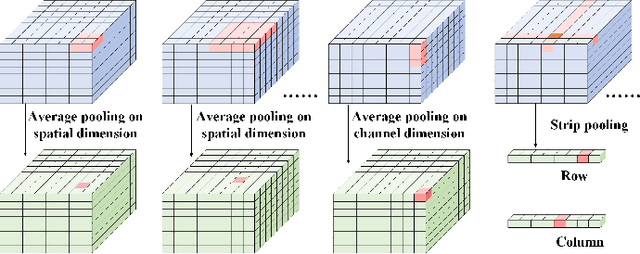
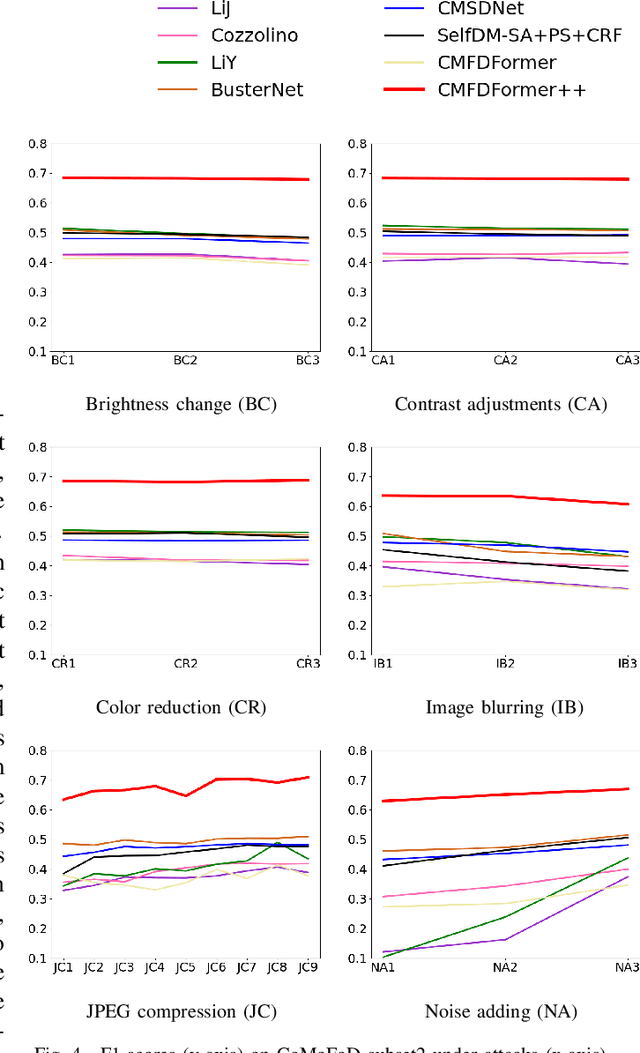
Copy-move forgery detection aims at detecting duplicated regions in a suspected forged image, and deep learning based copy-move forgery detection methods are in the ascendant. These deep learning based methods heavily rely on synthetic training data, and the performance will degrade when facing new tasks. In this paper, we propose a Transformer-style copy-move forgery detection network named as CMFDFormer, and provide a novel PCSD (Pooled Cube and Strip Distillation) continual learning framework to help CMFDFormer handle new tasks. CMFDFormer consists of a MiT (Mix Transformer) backbone network and a PHD (Pluggable Hybrid Decoder) mask prediction network. The MiT backbone network is a Transformer-style network which is adopted on the basis of comprehensive analyses with CNN-style and MLP-style backbones. The PHD network is constructed based on self-correlation computation, hierarchical feature integration, a multi-scale cycle fully-connected block and a mask reconstruction block. The PHD network is applicable to feature extractors of different styles for hierarchical multi-scale information extraction, achieving comparable performance. Last but not least, we propose a PCSD continual learning framework to improve the forgery detectability and avoid catastrophic forgetting when handling new tasks. Our continual learning framework restricts intermediate features from the PHD network, and takes advantage of both cube pooling and strip pooling. Extensive experiments on publicly available datasets demonstrate the good performance of CMFDFormer and the effectiveness of the PCSD continual learning framework.
Neural Degradation Representation Learning for All-In-One Image Restoration
Oct 19, 2023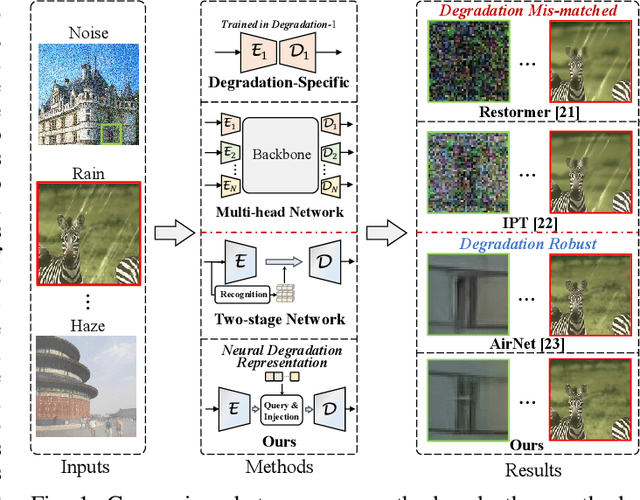
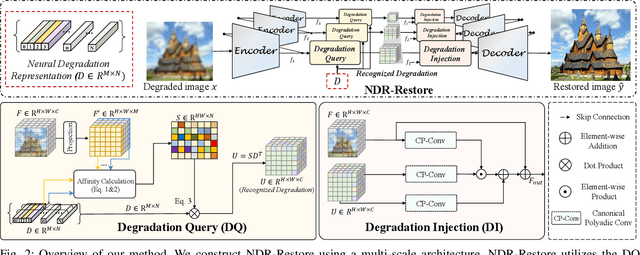
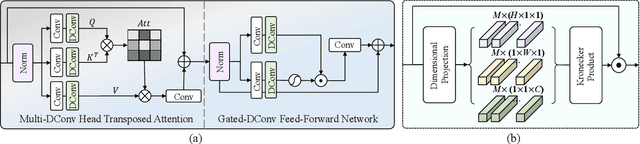
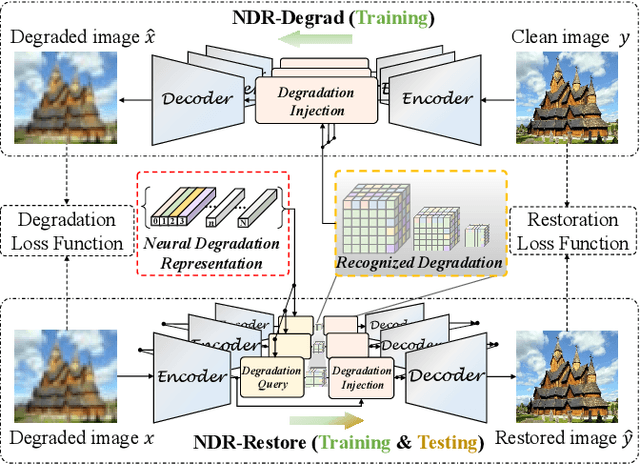
Existing methods have demonstrated effective performance on a single degradation type. In practical applications, however, the degradation is often unknown, and the mismatch between the model and the degradation will result in a severe performance drop. In this paper, we propose an all-in-one image restoration network that tackles multiple degradations. Due to the heterogeneous nature of different types of degradations, it is difficult to process multiple degradations in a single network. To this end, we propose to learn a neural degradation representation (NDR) that captures the underlying characteristics of various degradations. The learned NDR decomposes different types of degradations adaptively, similar to a neural dictionary that represents basic degradation components. Subsequently, we develop a degradation query module and a degradation injection module to effectively recognize and utilize the specific degradation based on NDR, enabling the all-in-one restoration ability for multiple degradations. Moreover, we propose a bidirectional optimization strategy to effectively drive NDR to learn the degradation representation by optimizing the degradation and restoration processes alternately. Comprehensive experiments on representative types of degradations (including noise, haze, rain, and downsampling) demonstrate the effectiveness and generalization capability of our method.
Co-Learning Semantic-aware Unsupervised Segmentation for Pathological Image Registration
Oct 19, 2023The registration of pathological images plays an important role in medical applications. Despite its significance, most researchers in this field primarily focus on the registration of normal tissue into normal tissue. The negative impact of focal tissue, such as the loss of spatial correspondence information and the abnormal distortion of tissue, are rarely considered. In this paper, we propose GIRNet, a novel unsupervised approach for pathological image registration by incorporating segmentation and inpainting through the principles of Generation, Inpainting, and Registration (GIR). The registration, segmentation, and inpainting modules are trained simultaneously in a co-learning manner so that the segmentation of the focal area and the registration of inpainted pairs can improve collaboratively. Overall, the registration of pathological images is achieved in a completely unsupervised learning framework. Experimental results on multiple datasets, including Magnetic Resonance Imaging (MRI) of T1 sequences, demonstrate the efficacy of our proposed method. Our results show that our method can accurately achieve the registration of pathological images and identify lesions even in challenging imaging modalities. Our unsupervised approach offers a promising solution for the efficient and cost-effective registration of pathological images. Our code is available at https://github.com/brain-intelligence-lab/GIRNet.
* 13 pages, 7 figures, published in Medical Image Computing and Computer Assisted Intervention (MICCAI) 2023
SegGen: Supercharging Segmentation Models with Text2Mask and Mask2Img Synthesis
Nov 06, 2023We propose SegGen, a highly-effective training data generation method for image segmentation, which pushes the performance limits of state-of-the-art segmentation models to a significant extent. SegGen designs and integrates two data generation strategies: MaskSyn and ImgSyn. (i) MaskSyn synthesizes new mask-image pairs via our proposed text-to-mask generation model and mask-to-image generation model, greatly improving the diversity in segmentation masks for model supervision; (ii) ImgSyn synthesizes new images based on existing masks using the mask-to-image generation model, strongly improving image diversity for model inputs. On the highly competitive ADE20K and COCO benchmarks, our data generation method markedly improves the performance of state-of-the-art segmentation models in semantic segmentation, panoptic segmentation, and instance segmentation. Notably, in terms of the ADE20K mIoU, Mask2Former R50 is largely boosted from 47.2 to 49.9 (+2.7); Mask2Former Swin-L is also significantly increased from 56.1 to 57.4 (+1.3). These promising results strongly suggest the effectiveness of our SegGen even when abundant human-annotated training data is utilized. Moreover, training with our synthetic data makes the segmentation models more robust towards unseen domains. Project website: https://seggenerator.github.io