 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning graph-Fourier spectra of textured surface images for defect localization
Nov 28, 2023

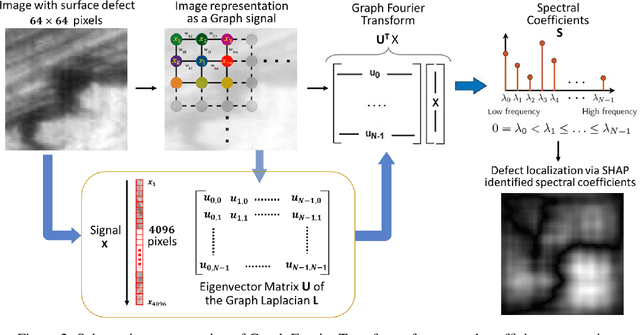
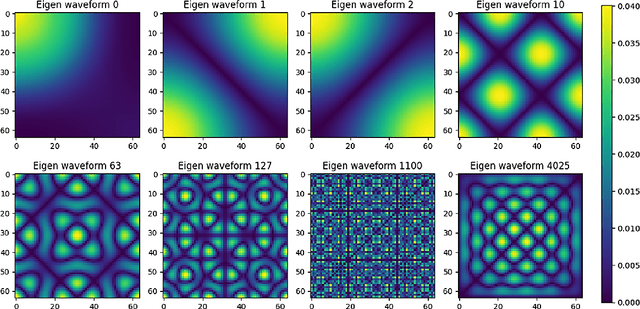
In the realm of industrial manufacturing, product inspection remains a significant bottleneck, with only a small fraction of manufactured items undergoing inspection for surface defects. Advances in imaging systems and AI can allow automated full inspection of manufactured surfaces. However, even the most contemporary imaging and machine learning methods perform poorly for detecting defects in images with highly textured backgrounds, that stem from diverse manufacturing processes. This paper introduces an approach based on graph Fourier analysis to automatically identify defective images, as well as crucial graph Fourier coefficients that inform the defects in images amidst highly textured backgrounds. The approach capitalizes on the ability of graph representations to capture the complex dynamics inherent in high-dimensional data, preserving crucial locality properties in a lower dimensional space. A convolutional neural network model (1D-CNN) was trained with the coefficients of the graph Fourier transform of the images as the input to identify, with classification accuracy of 99.4%, if the image contains a defect. An explainable AI method using SHAP (SHapley Additive exPlanations) was used to further analyze the trained 1D-CNN model to discern important spectral coefficients for each image. This approach sheds light on the crucial contribution of low-frequency graph eigen waveforms to precisely localize surface defects in images, thereby advancing the realization of zero-defect manufacturing.
M$^{2}$UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models
Nov 28, 2023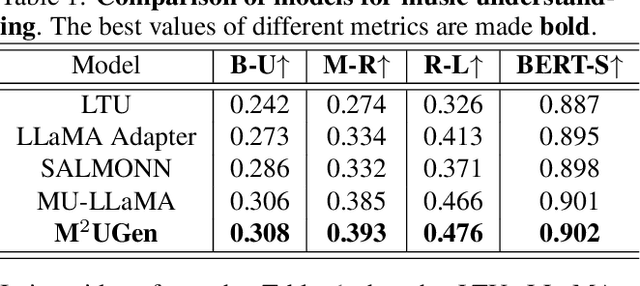
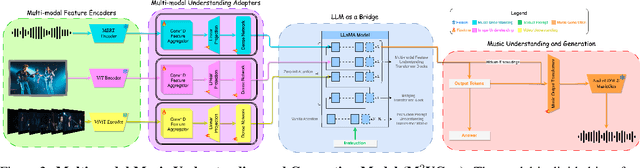
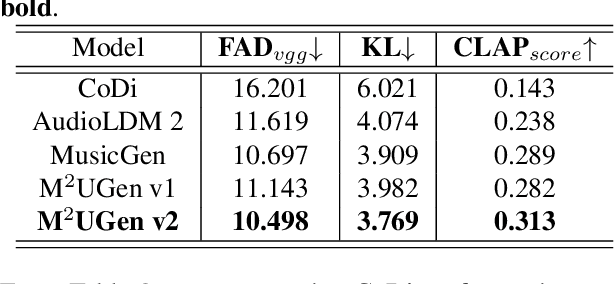
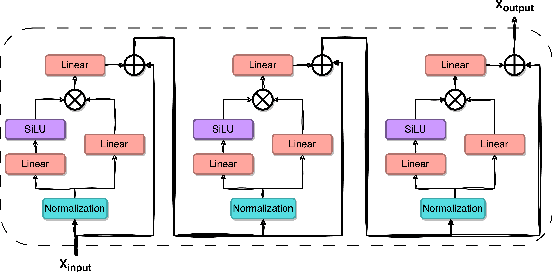
The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. They also utilize LLMs to understand human intention and generate desired outputs like images, videos, and music. However, research that combines both understanding and generation using LLMs is still limited and in its nascent stage. To address this gap, we introduce a Multi-modal Music Understanding and Generation (M$^{2}$UGen) framework that integrates LLM's abilities to comprehend and generate music for different modalities. The M$^{2}$UGen framework is purpose-built to unlock creative potential from diverse sources of inspiration, encompassing music, image, and video through the use of pretrained MERT, ViT, and ViViT models, respectively. To enable music generation, we explore the use of AudioLDM 2 and MusicGen. Bridging multi-modal understanding and music generation is accomplished through the integration of the LLaMA 2 model. Furthermore, we make use of the MU-LLaMA model to generate extensive datasets that support text/image/video-to-music generation, facilitating the training of our M$^{2}$UGen framework. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models.
HGCLIP: Exploring Vision-Language Models with Graph Representations for Hierarchical Understanding
Nov 23, 2023Object categories are typically organized into a multi-granularity taxonomic hierarchy. When classifying categories at different hierarchy levels, traditional uni-modal approaches focus primarily on image features, revealing limitations in complex scenarios. Recent studies integrating Vision-Language Models (VLMs) with class hierarchies have shown promise, yet they fall short of fully exploiting the hierarchical relationships. These efforts are constrained by their inability to perform effectively across varied granularity of categories. To tackle this issue, we propose a novel framework (HGCLIP) that effectively combines CLIP with a deeper exploitation of the Hierarchical class structure via Graph representation learning. We explore constructing the class hierarchy into a graph, with its nodes representing the textual or image features of each category. After passing through a graph encoder, the textual features incorporate hierarchical structure information, while the image features emphasize class-aware features derived from prototypes through the attention mechanism. Our approach demonstrates significant improvements on both generic and fine-grained visual recognition benchmarks. Our codes are fully available at https://github.com/richard-peng-xia/HGCLIP.
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
Nov 07, 2023Video synthesis has recently made remarkable strides benefiting from the rapid development of diffusion models. However, it still encounters challenges in terms of semantic accuracy, clarity and spatio-temporal continuity. They primarily arise from the scarcity of well-aligned text-video data and the complex inherent structure of videos, making it difficult for the model to simultaneously ensure semantic and qualitative excellence. In this report, we propose a cascaded I2VGen-XL approach that enhances model performance by decoupling these two factors and ensures the alignment of the input data by utilizing static images as a form of crucial guidance. I2VGen-XL consists of two stages: i) the base stage guarantees coherent semantics and preserves content from input images by using two hierarchical encoders, and ii) the refinement stage enhances the video's details by incorporating an additional brief text and improves the resolution to 1280$\times$720. To improve the diversity, we collect around 35 million single-shot text-video pairs and 6 billion text-image pairs to optimize the model. By this means, I2VGen-XL can simultaneously enhance the semantic accuracy, continuity of details and clarity of generated videos. Through extensive experiments, we have investigated the underlying principles of I2VGen-XL and compared it with current top methods, which can demonstrate its effectiveness on diverse data. The source code and models will be publicly available at \url{https://i2vgen-xl.github.io}.
MMA-Diffusion: MultiModal Attack on Diffusion Models
Nov 29, 2023In recent years, Text-to-Image (T2I) models have seen remarkable advancements, gaining widespread adoption. However, this progress has inadvertently opened avenues for potential misuse, particularly in generating inappropriate or Not-Safe-For-Work (NSFW) content. Our work introduces MMA-Diffusion, a framework that presents a significant and realistic threat to the security of T2I models by effectively circumventing current defensive measures in both open-source models and commercial online services. Unlike previous approaches, MMA-Diffusion leverages both textual and visual modalities to bypass safeguards like prompt filters and post-hoc safety checkers, thus exposing and highlighting the vulnerabilities in existing defense mechanisms.
Echoes in the Noise: Posterior Samples of Faint Galaxy Surface Brightness Profiles with Score-Based Likelihoods and Priors
Nov 29, 2023Examining the detailed structure of galaxy populations provides valuable insights into their formation and evolution mechanisms. Significant barriers to such analysis are the non-trivial noise properties of real astronomical images and the point spread function (PSF) which blurs structure. Here we present a framework which combines recent advances in score-based likelihood characterization and diffusion model priors to perform a Bayesian analysis of image deconvolution. The method, when applied to minimally processed \emph{Hubble Space Telescope} (\emph{HST}) data, recovers structures which have otherwise only become visible in next-generation \emph{James Webb Space Telescope} (\emph{JWST}) imaging.
Image Prior and Posterior Conditional Probability Representation for Efficient Damage Assessment
Oct 26, 2023It is important to quantify Damage Assessment (DA) for Human Assistance and Disaster Response (HADR) applications. In this paper, to achieve efficient and scalable DA in HADR, an image prior and posterior conditional probability (IP2CP) is developed as an effective computational imaging representation. Equipped with the IP2CP representation, the matching pre- and post-disaster images are effectively encoded into one image that is then processed using deep learning approaches to determine the damage levels. Two scenarios of crucial importance for the practical use of DA in HADR applications are examined: pixel-wise semantic segmentation and patch-based contrastive learning-based global damage classification. Results achieved by IP2CP in both scenarios demonstrate promising performances, showing that our IP2CP-based methods within the deep learning framework can effectively achieve data and computational efficiency, which is of utmost importance for the DA in HADR applications.
Recoverable Privacy-Preserving Image Classification through Noise-like Adversarial Examples
Oct 19, 2023With the increasing prevalence of cloud computing platforms, ensuring data privacy during the cloud-based image related services such as classification has become crucial. In this study, we propose a novel privacypreserving image classification scheme that enables the direct application of classifiers trained in the plaintext domain to classify encrypted images, without the need of retraining a dedicated classifier. Moreover, encrypted images can be decrypted back into their original form with high fidelity (recoverable) using a secret key. Specifically, our proposed scheme involves utilizing a feature extractor and an encoder to mask the plaintext image through a newly designed Noise-like Adversarial Example (NAE). Such an NAE not only introduces a noise-like visual appearance to the encrypted image but also compels the target classifier to predict the ciphertext as the same label as the original plaintext image. At the decoding phase, we adopt a Symmetric Residual Learning (SRL) framework for restoring the plaintext image with minimal degradation. Extensive experiments demonstrate that 1) the classification accuracy of the classifier trained in the plaintext domain remains the same in both the ciphertext and plaintext domains; 2) the encrypted images can be recovered into their original form with an average PSNR of up to 51+ dB for the SVHN dataset and 48+ dB for the VGGFace2 dataset; 3) our system exhibits satisfactory generalization capability on the encryption, decryption and classification tasks across datasets that are different from the training one; and 4) a high-level of security is achieved against three potential threat models. The code is available at https://github.com/csjunjun/RIC.git.
Neural Network Characterization and Entropy Regulated Data Balancing through Principal Component Analysis
Dec 03, 2023This paper examines the relationship between the behavior of a neural network and the distribution formed from the projections of the data records into the space spanned by the low-order principal components of the training data. For example, in a benchmark calculation involving rotated and unrotated MNIST digits, classes (digits) that are mapped far from the origin in a low-dimensional principal component space and that overlap minimally with other digits converge rapidly and exhibit high degrees of accuracy in neural network calculations that employ the associated components of each data record as inputs. Further, if the space spanned by these low-order principal components is divided into bins and the input data records that are mapped into a given bin averaged, the resulting pattern can be distinguished by its geometric features which interpolate between those of adjacent bins in an analogous manner to variational autoencoders. Based on this observation, a simply realized data balancing procedure can be realized by evaluating the entropy associated with each histogram bin and subsequently repeating the original image data associated with the bin by a number of times that is determined from this entropy.
Facial Emotion Recognition Under Mask Coverage Using a Data Augmentation Technique
Dec 03, 2023Identifying human emotions using AI-based computer vision systems, when individuals wear face masks, presents a new challenge in the current Covid-19 pandemic. In this study, we propose a facial emotion recognition system capable of recognizing emotions from individuals wearing different face masks. A novel data augmentation technique was utilized to improve the performance of our model using four mask types for each face image. We evaluated the effectiveness of four convolutional neural networks, Alexnet, Squeezenet, Resnet50 and VGGFace2 that were trained using transfer learning. The experimental findings revealed that our model works effectively in multi-mask mode compared to single-mask mode. The VGGFace2 network achieved the highest accuracy rate, with 97.82% for the person-dependent mode and 74.21% for the person-independent mode using the JAFFE dataset. However, we evaluated our proposed model using the UIBVFED dataset. The Resnet50 has demonstrated superior performance, with accuracies of 73.68% for the person-dependent mode and 59.57% for the person-independent mode. Moreover, we employed metrics such as precision, sensitivity, specificity, AUC, F1 score, and confusion matrix to measure our system's efficiency in detail. Additionally, the LIME algorithm was used to visualize CNN's decision-making strategy.