 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VLAP: Efficient Video-Language Alignment via Frame Prompting and Distilling for Video Question Answering
Dec 13, 2023
In this work, we propose an efficient Video-Language Alignment via Frame-Prompting and Distilling (VLAP) network. Our VLAP model addresses both efficient frame sampling and effective cross-modal alignment in a unified way. In our VLAP network, we design a new learnable question-aware Frame-Prompter together with a new cross-modal distillation (QFormer-Distiller) module. Pre-trained large image-language models have shown promising results on problems such as visual question answering. However, how to efficiently and effectively sample image frames when adapting pre-trained large image-language model to video-language alignment is still the major challenge. Compared with prior work, our VLAP model demonstrates the capability of selecting key frames with critical contents, thus improving the video-language alignment accuracy while reducing the inference latency (+3.3% on NExT-QA Temporal with 3.0X speed up). Overall, our VLAP network outperforms (e.g. +4.6% on STAR Interaction and +2.2% on STAR average with 3.0X speed up, ours 2-frames out-perform SeViLA 4-frames on VLEP with 4.2X speed up) the state-of-the-art methods on the video question-answering benchmarks.
Rusty Detection Using Image Processing For Maintenance Of Stations
Nov 16, 2023This study addresses the challenge of accurately seg-menting rusted areas on painted construction surfaces. A method leveraging digital image processing is explored to calculate the percentage of rust present on painted coatings. The proposed segmentation approach is based on the HSV color model. To equalize luminosity and mitigate the influence of illumination, a fundamental model of single-scale Retinex is applied specifically to the saturation component. Subsequently, the image undergoes further processing, involv-ing manual color filtering. This step is crucial for refining the identification of rusted regions. To enhance precision and filter out noise, the pixel areas selected through color filtering are subjected to the DBScan algorithm. This multi-step process aims to achieve a robust segmentation of rusted areas on painted construction surfaces, providing a valuable contribution to the field of corrosion detection and analysis.
Topic-VQ-VAE: Leveraging Latent Codebooks for Flexible Topic-Guided Document Generation
Dec 15, 2023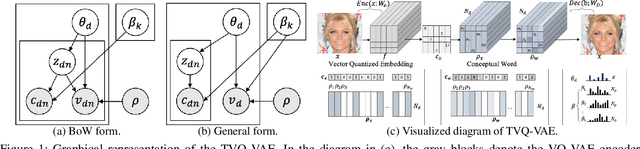


This paper introduces a novel approach for topic modeling utilizing latent codebooks from Vector-Quantized Variational Auto-Encoder~(VQ-VAE), discretely encapsulating the rich information of the pre-trained embeddings such as the pre-trained language model. From the novel interpretation of the latent codebooks and embeddings as conceptual bag-of-words, we propose a new generative topic model called Topic-VQ-VAE~(TVQ-VAE) which inversely generates the original documents related to the respective latent codebook. The TVQ-VAE can visualize the topics with various generative distributions including the traditional BoW distribution and the autoregressive image generation. Our experimental results on document analysis and image generation demonstrate that TVQ-VAE effectively captures the topic context which reveals the underlying structures of the dataset and supports flexible forms of document generation. Official implementation of the proposed TVQ-VAE is available at https://github.com/clovaai/TVQ-VAE.
Multiscale Vision Transformer With Deep Clustering-Guided Refinement for Weakly Supervised Object Localization
Dec 15, 2023This work addresses the task of weakly-supervised object localization. The goal is to learn object localization using only image-level class labels, which are much easier to obtain compared to bounding box annotations. This task is important because it reduces the need for labor-intensive ground-truth annotations. However, methods for object localization trained using weak supervision often suffer from limited accuracy in localization. To address this challenge and enhance localization accuracy, we propose a multiscale object localization transformer (MOLT). It comprises multiple object localization transformers that extract patch embeddings across various scales. Moreover, we introduce a deep clustering-guided refinement method that further enhances localization accuracy by utilizing separately extracted image segments. These segments are obtained by clustering pixels using convolutional neural networks. Finally, we demonstrate the effectiveness of our proposed method by conducting experiments on the publicly available ILSVRC-2012 dataset.
* 5 pages
Diffusing More Objects for Semi-Supervised Domain Adaptation with Less Labeling
Dec 19, 2023For object detection, it is possible to view the prediction of bounding boxes as a reverse diffusion process. Using a diffusion model, the random bounding boxes are iteratively refined in a denoising step, conditioned on the image. We propose a stochastic accumulator function that starts each run with random bounding boxes and combines the slightly different predictions. We empirically verify that this improves detection performance. The improved detections are leveraged on unlabelled images as weighted pseudo-labels for semi-supervised learning. We evaluate the method on a challenging out-of-domain test set. Our method brings significant improvements and is on par with human-selected pseudo-labels, while not requiring any human involvement.
A Relay System for Semantic Image Transmission based on Shared Feature Extraction and Hyperprior Entropy Compression
Nov 17, 2023Nowadays, the need for high-quality image reconstruction and restoration is more and more urgent. However, most image transmission systems may suffer from image quality degradation or transmission interruption in the face of interference such as channel noise and link fading. To solve this problem, a relay communication network for semantic image transmission based on shared feature extraction and hyperprior entropy compression (HEC) is proposed, where the shared feature extraction technology based on Pearson correlation is proposed to eliminate partial shared feature of extracted semantic latent feature. In addition, the HEC technology is used to resist the effect of channel noise and link fading and carried out respectively at the source node and the relay node. Experimental results demonstrate that compared with other recent research methods, the proposed system has lower transmission overhead and higher semantic image transmission performance. Particularly, under the same conditions, the multi-scale structural similarity (MS-SSIM) of this system is superior to the comparison method by approximately 0.2.
Enhancing Neural Training via a Correlated Dynamics Model
Dec 20, 2023As neural networks grow in scale, their training becomes both computationally demanding and rich in dynamics. Amidst the flourishing interest in these training dynamics, we present a novel observation: Parameters during training exhibit intrinsic correlations over time. Capitalizing on this, we introduce Correlation Mode Decomposition (CMD). This algorithm clusters the parameter space into groups, termed modes, that display synchronized behavior across epochs. This enables CMD to efficiently represent the training dynamics of complex networks, like ResNets and Transformers, using only a few modes. Moreover, test set generalization is enhanced. We introduce an efficient CMD variant, designed to run concurrently with training. Our experiments indicate that CMD surpasses the state-of-the-art method for compactly modeled dynamics on image classification. Our modeling can improve training efficiency and lower communication overhead, as shown by our preliminary experiments in the context of federated learning.
Deep Image Semantic Communication Model for Artificial Intelligent Internet of Things
Nov 08, 2023With the rapid development of Artificial Intelligent Internet of Things (AIoT), the image data from AIoT devices has been witnessing the explosive increasing. In this paper, a novel deep image semantic communication model is proposed for the efficient image communication in AIoT. Particularly, at the transmitter side, a high-precision image semantic segmentation algorithm is proposed to extract the semantic information of the image to achieve significant compression of the image data. At the receiver side, a semantic image restoration algorithm based on Generative Adversarial Network (GAN) is proposed to convert the semantic image to a real scene image with detailed information. Simulation results demonstrate that the proposed image semantic communication model can improve the image compression ratio and recovery accuracy by 71.93% and 25.07% on average in comparison with WebP and CycleGAN, respectively. More importantly, our demo experiment shows that the proposed model reduces the total delay by 95.26% in the image communication, when comparing with the original image transmission.
Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment
Dec 12, 2023We introduce a method to train vision-language models for remote-sensing images without using any textual annotations. Our key insight is to use co-located internet imagery taken on the ground as an intermediary for connecting remote-sensing images and language. Specifically, we train an image encoder for remote sensing images to align with the image encoder of CLIP using a large amount of paired internet and satellite images. Our unsupervised approach enables the training of a first-of-its-kind large-scale vision language model (VLM) for remote sensing images at two different resolutions. We show that these VLMs enable zero-shot, open-vocabulary image classification, retrieval, segmentation and visual question answering for satellite images. On each of these tasks, our VLM trained without textual annotations outperforms existing VLMs trained with supervision, with gains of up to 20% for classification and 80% for segmentation.
Optimal Image Transport on Sparse Dictionaries
Nov 03, 2023

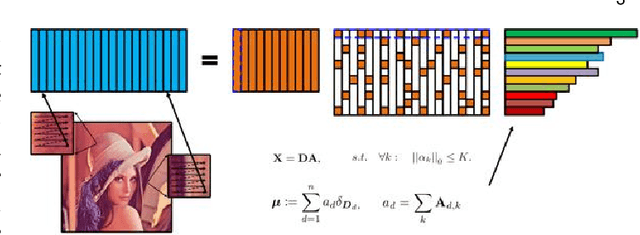
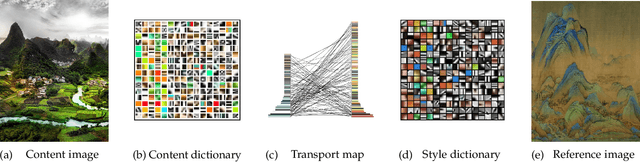
In this paper, we derive a novel optimal image transport algorithm over sparse dictionaries by taking advantage of Sparse Representation (SR) and Optimal Transport (OT). Concisely, we design a unified optimization framework in which the individual image features (color, textures, styles, etc.) are encoded using sparse representation compactly, and an optimal transport plan is then inferred between two learned dictionaries in accordance with the encoding process. This paradigm gives rise to a simple but effective way for simultaneous image representation and transformation, which is also empirically solvable because of the moderate size of sparse coding and optimal transport sub-problems. We demonstrate its versatility and many benefits to different image-to-image translation tasks, in particular image color transform and artistic style transfer, and show the plausible results for photo-realistic transferred effects.