 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bayesian approach for near-duplicate image detection
Apr 25, 2011
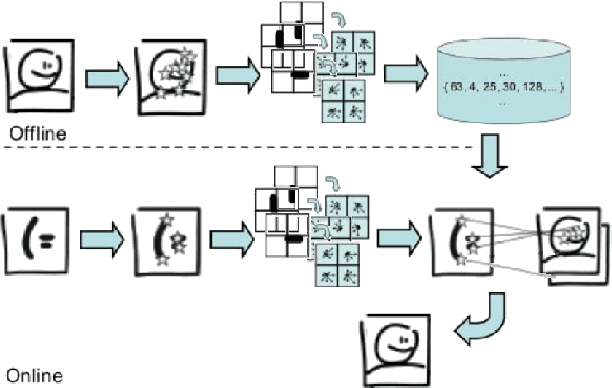
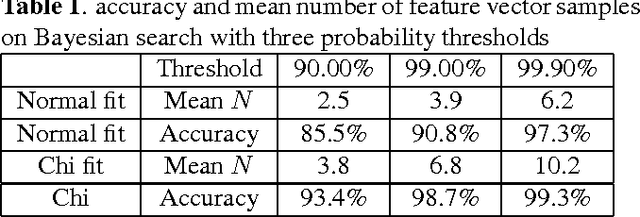
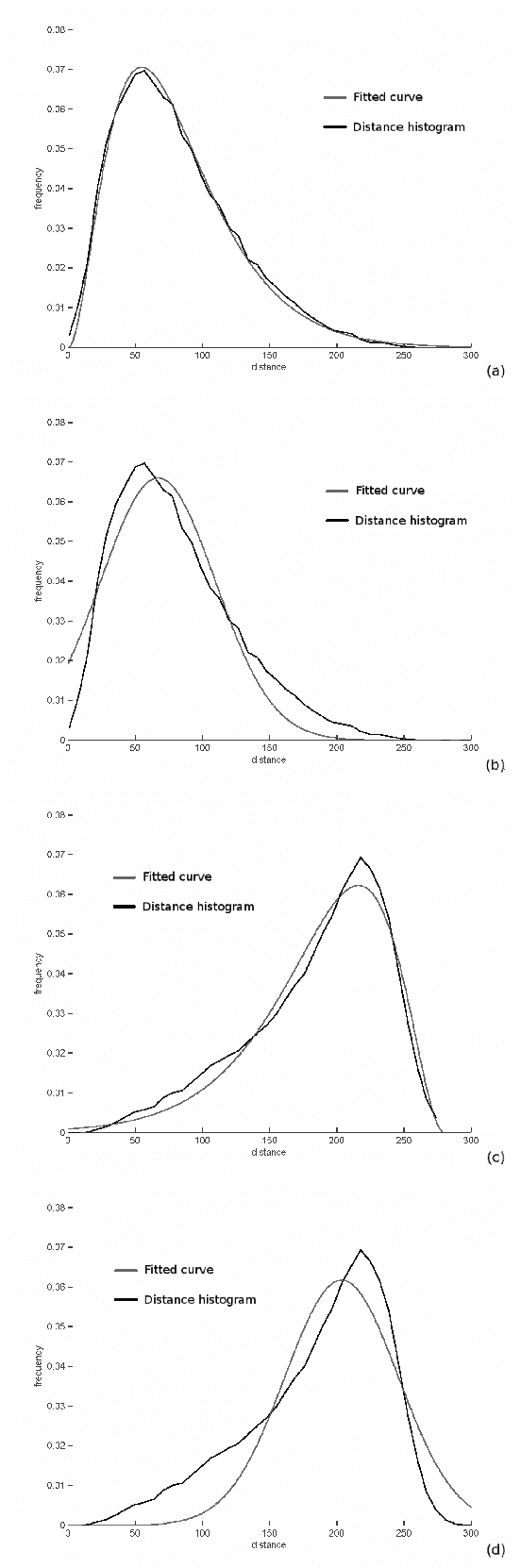

In this paper we propose a bayesian approach for near-duplicate image detection, and investigate how different probabilistic models affect the performance obtained. The task of identifying an image whose metadata are missing is often demanded for a myriad of applications: metadata retrieval in cultural institutions, detection of copyright violations, investigation of latent cross-links in archives and libraries, duplicate elimination in storage management, etc. The majority of current solutions are based either on voting algorithms, which are very precise, but expensive; either on the use of visual dictionaries, which are efficient, but less precise. Our approach, uses local descriptors in a novel way, which by a careful application of decision theory, allows a very fine control of the compromise between precision and efficiency. In addition, the method attains a great compromise between those two axes, with more than 99% accuracy with less than 10 database operations.
Non-uniqueness phenomenon of object representation in modelling IT cortex by deep convolutional neural network (DCNN)
Jun 06, 2019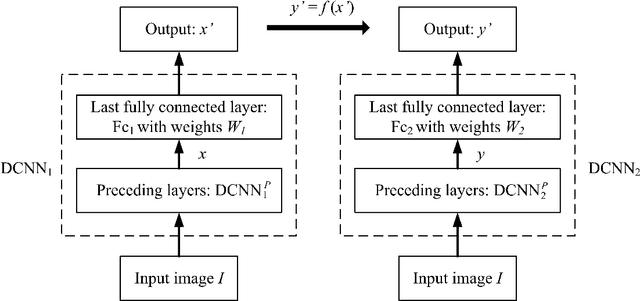
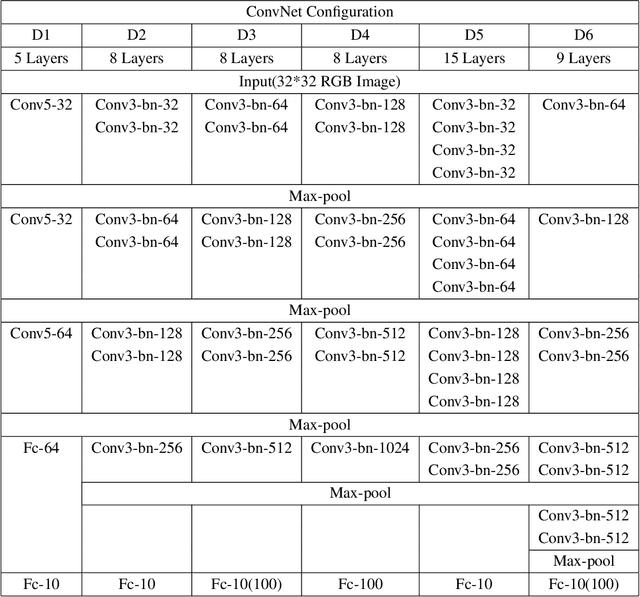
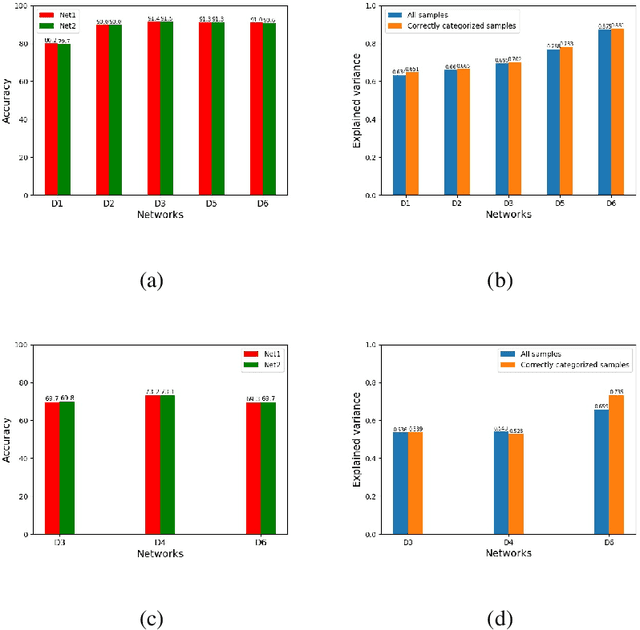
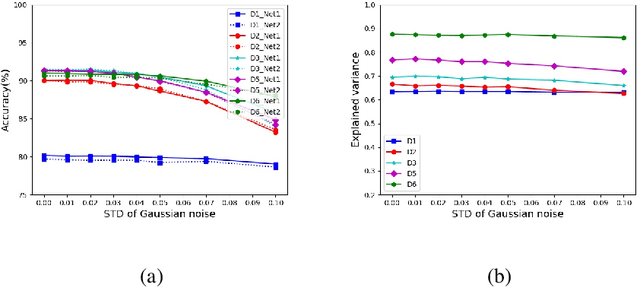
Recently DCNN (Deep Convolutional Neural Network) has been advocated as a general and promising modelling approach for neural object representation in primate inferotemporal cortex. In this work, we show that some inherent non-uniqueness problem exists in the DCNN-based modelling of image object representations. This non-uniqueness phenomenon reveals to some extent the theoretical limitation of this general modelling approach, and invites due attention to be taken in practice.
An Innovative Skin Detection Approach Using Color Based Image Retrieval Technique
Jul 06, 2012From The late 90th, "Skin Detection" becomes one of the major problems in image processing. If "Skin Detection" will be done in high accuracy, it can be used in many cases as face recognition, Human Tracking and etc. Until now so many methods were presented for solving this problem. In most of these methods, color space was used to extract feature vector for classifying pixels, but the most of them have not good accuracy in detecting types of skin. The proposed approach in this paper is based on "Color based image retrieval" (CBIR) technique. In this method, first by means of CBIR method and image tiling and considering the relation between pixel and its neighbors, a feature vector would be defined and then with using a training step, detecting the skin in the test stage. The result shows that the presenting approach, in addition to its high accuracy in detecting type of skin, has no sensitivity to illumination intensity and moving face orientation.
* 9 Pages, 4 Figures
Modular Generative Adversarial Networks
Apr 10, 2018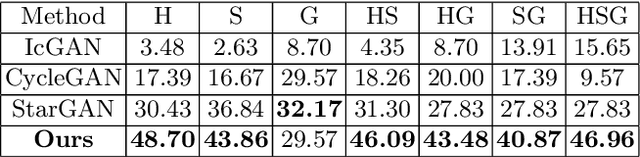
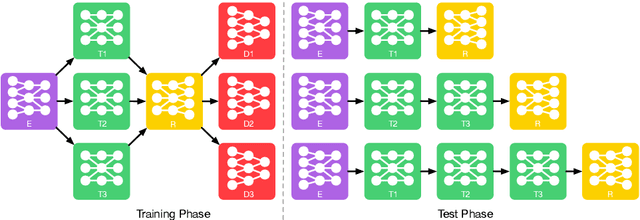
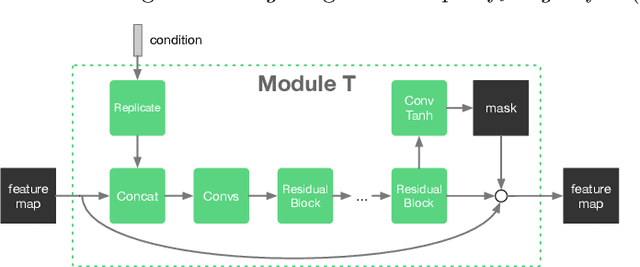
Existing methods for multi-domain image-to-image translation (or generation) attempt to directly map an input image (or a random vector) to an image in one of the output domains. However, most existing methods have limited scalability and robustness, since they require building independent models for each pair of domains in question. This leads to two significant shortcomings: (1) the need to train exponential number of pairwise models, and (2) the inability to leverage data from other domains when training a particular pairwise mapping. Inspired by recent work on module networks, this paper proposes ModularGAN for multi-domain image generation and image-to-image translation. ModularGAN consists of several reusable and composable modules that carry on different functions (e.g., encoding, decoding, transformations). These modules can be trained simultaneously, leveraging data from all domains, and then combined to construct specific GAN networks at test time, according to the specific image translation task. This leads to ModularGAN's superior flexibility of generating (or translating to) an image in any desired domain. Experimental results demonstrate that our model not only presents compelling perceptual results but also outperforms state-of-the-art methods on multi-domain facial attribute transfer.
Conditional GANs for Multi-Illuminant Color Constancy: Revolution or Yet Another Approach?
Nov 15, 2018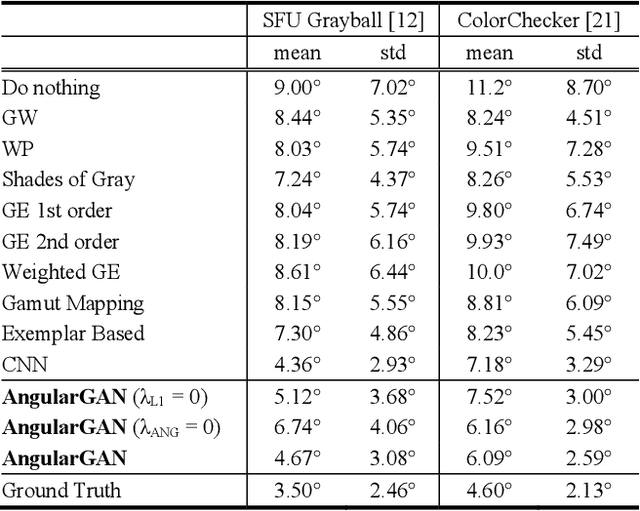
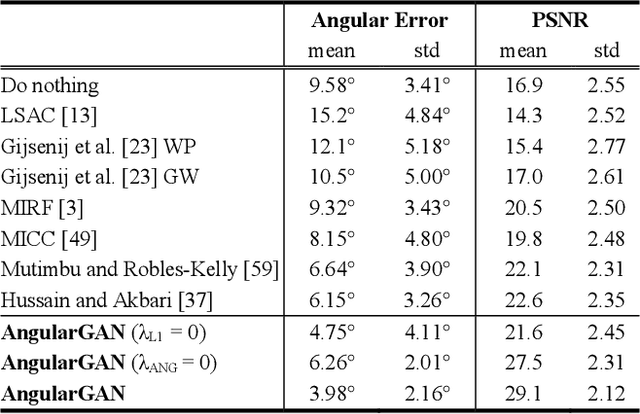
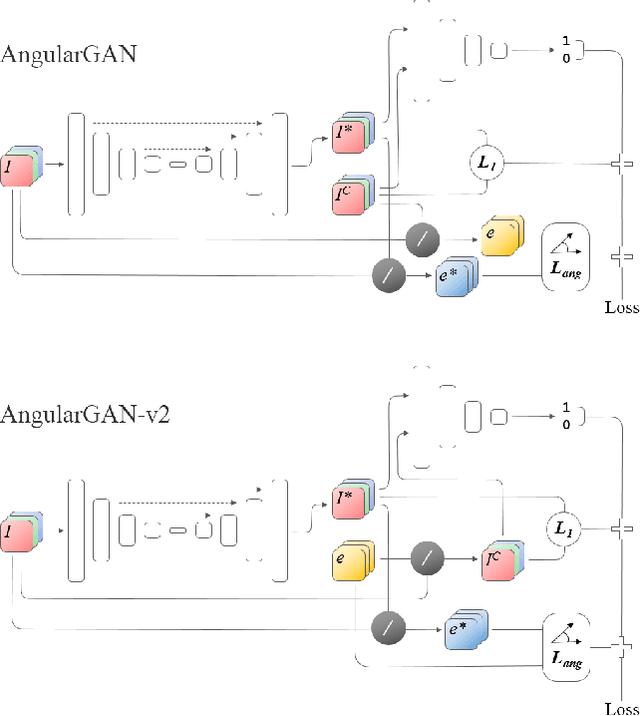

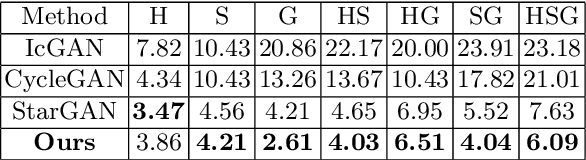
Non-uniform and multi-illuminant color constancy are important tasks, the solution of which will allow to discard information about lighting conditions in the image. Non-uniform illumination and shadows distort colors of real-world objects and mostly do not contain valuable information. Thus, many computer vision and image processing techniques would benefit from automatic discarding of this information at the pre-processing step. In this work we propose novel view on this classical problem via generative end-to-end algorithm, namely image conditioned Generative Adversarial Network. We also demonstrate the potential of the given approach for joint shadow detection and removal. Forced by the lack of training data, we render the largest existing shadow removal dataset and make it publicly available. It consists of approximately 6,000 pairs of wide field of view synthetic images with and without shadows.
Third-Person Visual Imitation Learning via Decoupled Hierarchical Controller
Nov 21, 2019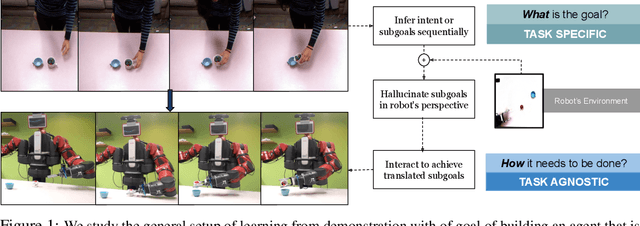

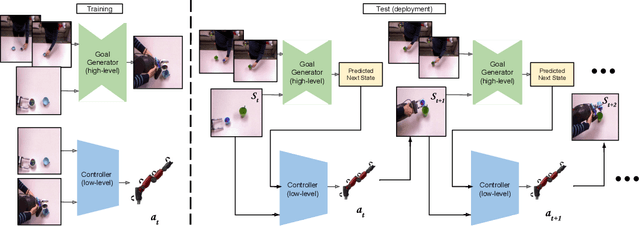
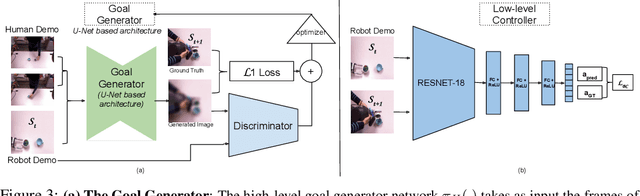
We study a generalized setup for learning from demonstration to build an agent that can manipulate novel objects in unseen scenarios by looking at only a single video of human demonstration from a third-person perspective. To accomplish this goal, our agent should not only learn to understand the intent of the demonstrated third-person video in its context but also perform the intended task in its environment configuration. Our central insight is to enforce this structure explicitly during learning by decoupling what to achieve (intended task) from how to perform it (controller). We propose a hierarchical setup where a high-level module learns to generate a series of first-person sub-goals conditioned on the third-person video demonstration, and a low-level controller predicts the actions to achieve those sub-goals. Our agent acts from raw image observations without any access to the full state information. We show results on a real robotic platform using Baxter for the manipulation tasks of pouring and placing objects in a box. Project video and code are at https://pathak22.github.io/hierarchical-imitation/
AdaFilter: Adaptive Filter Fine-tuning for Deep Transfer Learning
Nov 21, 2019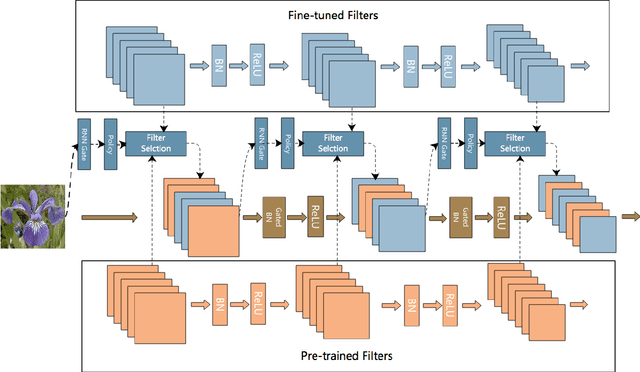
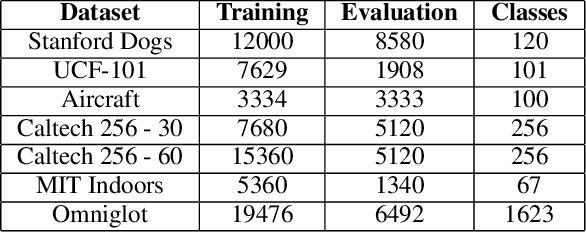
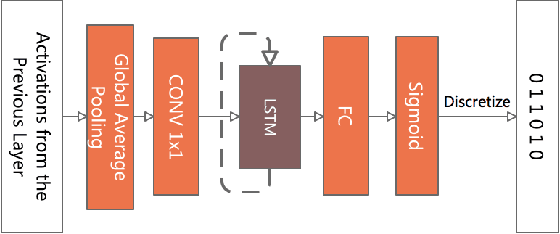

There is an increasing number of pre-trained deep neural network models. However, it is still unclear how to effectively use these models for a new task. Transfer learning, which aims to transfer knowledge from source tasks to a target task, is an effective solution to this problem. Fine-tuning is a popular transfer learning technique for deep neural networks where a few rounds of training are applied to the parameters of a pre-trained model to adapt them to a new task. Despite its popularity, in this paper, we show that fine-tuning suffers from several drawbacks. We propose an adaptive fine-tuning approach, called AdaFilter, which selects only a part of the convolutional filters in the pre-trained model to optimize on a per-example basis. We use a recurrent gated network to selectively fine-tune convolutional filters based on the activations of the previous layer. We experiment with 7 public image classification datasets and the results show that AdaFilter can reduce the average classification error of the standard fine-tuning by 2.54%.
Learning Hierarchical Discrete Linguistic Units from Visually-Grounded Speech
Nov 21, 2019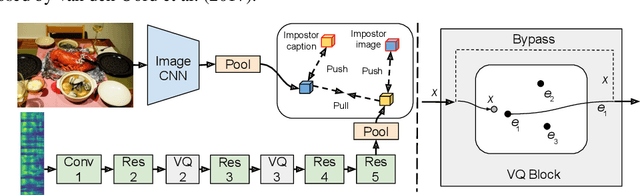
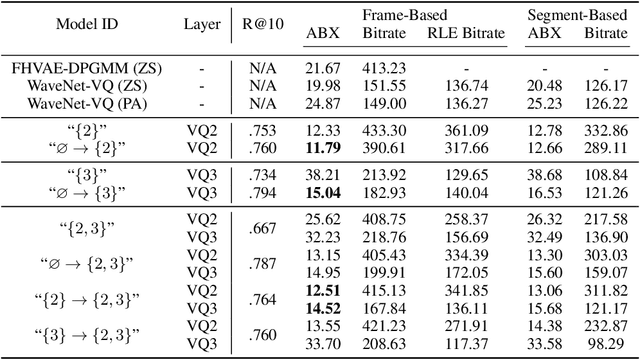
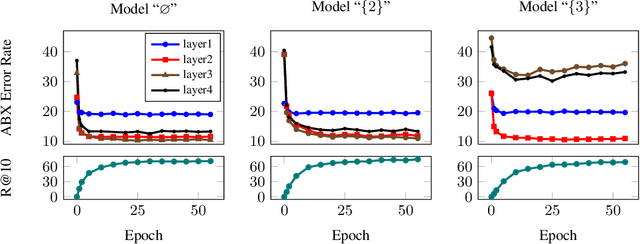
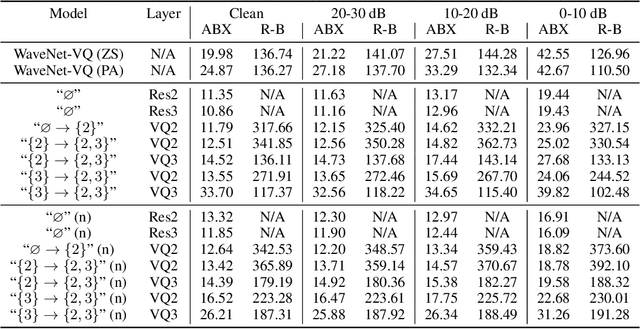
In this paper, we present a method for learning discrete linguistic units by incorporating vector quantization layers into neural models of visually grounded speech. We show that our method is capable of capturing both word-level and sub-word units, depending on how it is configured. What differentiates this paper from prior work on speech unit learning is the choice of training objective. Rather than using a reconstruction-based loss, we use a discriminative, multimodal grounding objective which forces the learned units to be useful for semantic image retrieval. We evaluate the sub-word units on the ZeroSpeech 2019 challenge, achieving a 27.3\% reduction in ABX error rate over the top-performing submission, while keeping the bitrate approximately the same. We also present experiments demonstrating the noise robustness of these units. Finally, we show that a model with multiple quantizers can simultaneously learn phone-like detectors at a lower layer and word-like detectors at a higher layer. We show that these detectors are highly accurate, discovering 279 words with an F1 score of greater than 0.5.
3D-LaneNet: end-to-end 3D multiple lane detection
Nov 27, 2018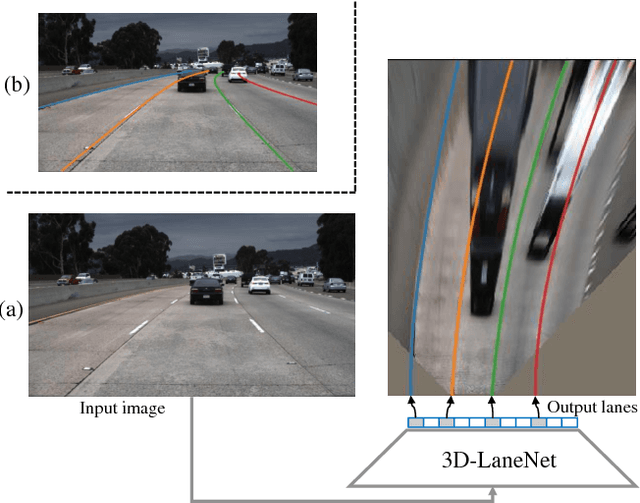
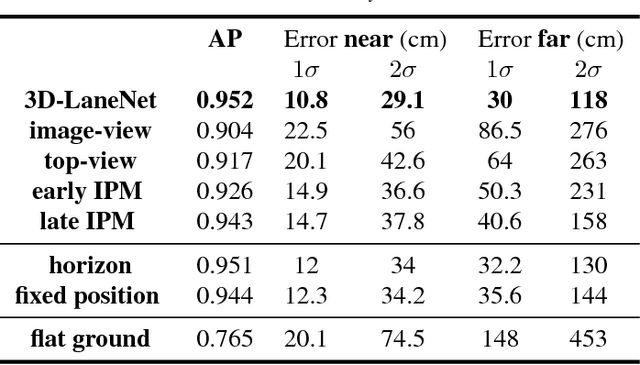
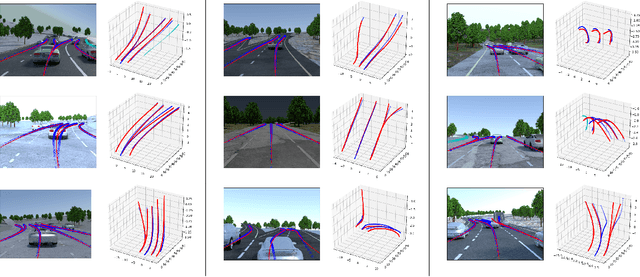

We introduce a network that directly predicts the 3D layout of lanes in a road scene from a single image. This work marks a first attempt to address this task with on-board sensing instead of relying on pre-mapped environments. Our network architecture, 3D-LaneNet, applies two new concepts: intra-network inverse-perspective mapping (IPM) and anchor-based lane representation. The intra-network IPM projection facilitates a dual-representation information flow in both regular image-view and top-view. An anchor-per-column output representation enables our end-to-end approach replacing common heuristics such as clustering and outlier rejection. In addition, our approach explicitly handles complex situations such as lane merges and splits. Promising results are shown on a new 3D lane synthetic dataset. For comparison with existing methods, we verify our approach on the image-only tuSimple lane detection benchmark and reach competitive performance.
Geometric Abstraction from Noisy Image-Based 3D Reconstructions
Apr 19, 2014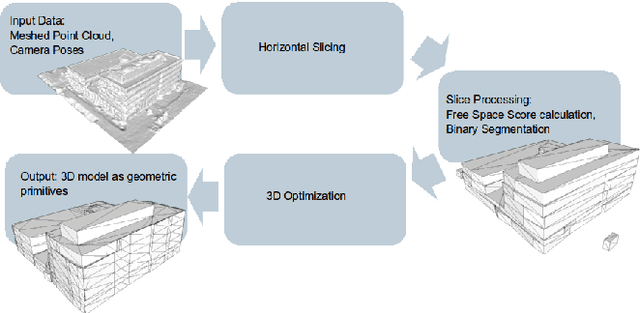

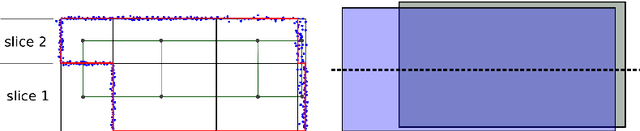

Creating geometric abstracted models from image-based scene reconstructions is difficult due to noise and irregularities in the reconstructed model. In this paper, we present a geometric modeling method for noisy reconstructions dominated by planar horizontal and orthogonal vertical structures. We partition the scene into horizontal slices and create an inside/outside labeling represented by a floor plan for each slice by solving an energy minimization problem. Consecutively, we create an irregular discretization of the volume according to the individual floor plans and again label each cell as inside/outside by minimizing an energy function. By adjusting the smoothness parameter, we introduce different levels of detail. In our experiments, we show results with varying regularization levels using synthetically generated and real-world data.