 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
COR-GAN: Correlation-Capturing Convolutional Neural Networks for Generating Synthetic Healthcare Records
Jan 25, 2020

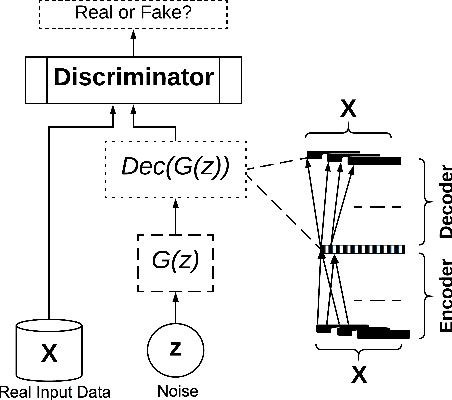


Deep learning models have demonstrated high-quality performance in areas such as image classification and speech processing. However, creating a deep learning model using electronic health record (EHR) data, requires addressing particular privacy challenges that are unique to researchers in this domain. This matter focuses attention on generating realistic synthetic data while ensuring privacy. In this paper, we propose a novel framework called correlation-capturing Generative Adversarial Network (corGAN), to generate synthetic healthcare records. In corGAN we utilize Convolutional Neural Networks to capture the correlations between adjacent medical features in the data representation space by combining Convolutional Generative Adversarial Networks and Convolutional Autoencoders. To demonstrate the model fidelity, we show that corGAN generates synthetic data with performance similar to that of real data in various Machine Learning settings such as classification and prediction. We also give a privacy assessment and report on statistical analysis regarding realistic characteristics of the synthetic data. The software of this work is open-source and is available at: https://github.com/astorfi/cor-gan.
Pedestrian re-identification based on Tree branch network with local and global learning
Mar 31, 2019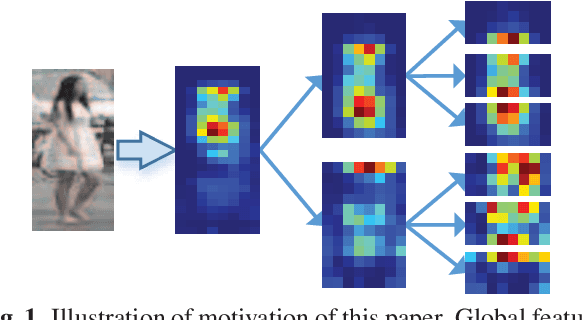
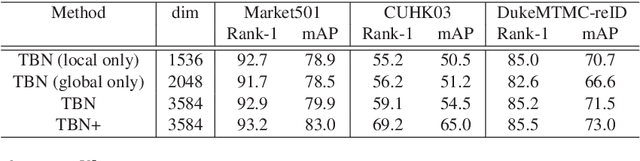
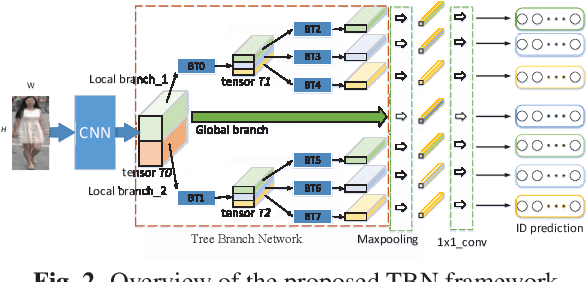
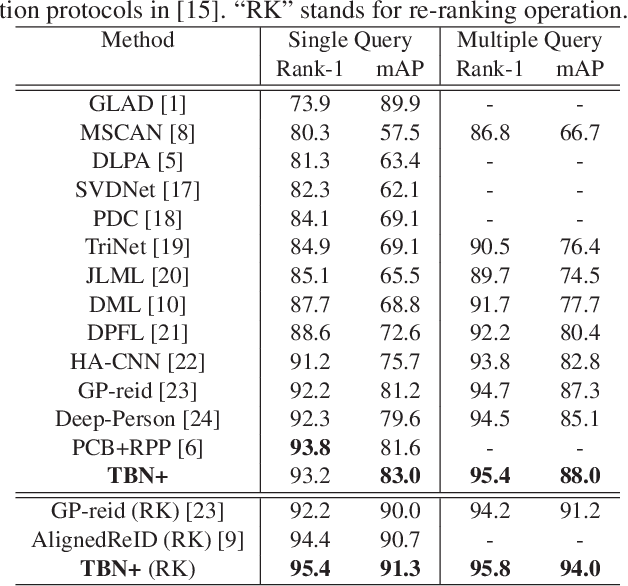
Deep part-based methods in recent literature have revealed the great potential of learning local part-level representation for pedestrian image in the task of person re-identification. However, global features that capture discriminative holistic information of human body are usually ignored or not well exploited. This motivates us to investigate joint learning global and local features from pedestrian images. Specifically, in this work, we propose a novel framework termed tree branch network (TBN) for person re-identification. Given a pedestrain image, the feature maps generated by the backbone CNN, are partitioned recursively into several pieces, each of which is followed by a bottleneck structure that learns finer-grained features for each level in the hierarchical tree-like framework. In this way, representations are learned in a coarse-to-fine manner and finally assembled to produce more discriminative image descriptions. Experimental results demonstrate the effectiveness of the global and local feature learning method in the proposed TBN framework. We also show significant improvement in performance over state-of-the-art methods on three public benchmarks: Market-1501, CUHK-03 and DukeMTMC.
Hierarchical Expert Networks for Meta-Learning
Oct 31, 2019

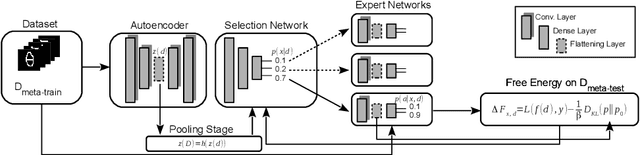
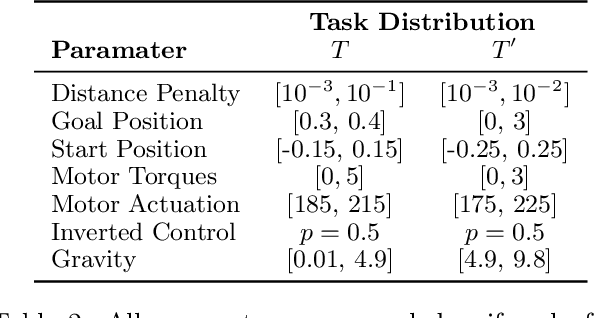
The goal of meta-learning is to train a model on a variety of learning tasks, such that it can adapt to new problems within only a few iterations. Here we propose a principled information-theoretic model that optimally partitions the underlying problem space such that the resulting partitions are processed by specialized expert decision-makers. To drive this specialization we impose the same kind of information processing constraints both on the partitioning and the expert decision-makers. We argue that this specialization leads to efficient adaptation to new tasks. To demonstrate the generality of our approach we evaluate on three meta-learning domains: image classification, regression, and reinforcement learning.
Controllable Descendant Face Synthesis
Feb 26, 2020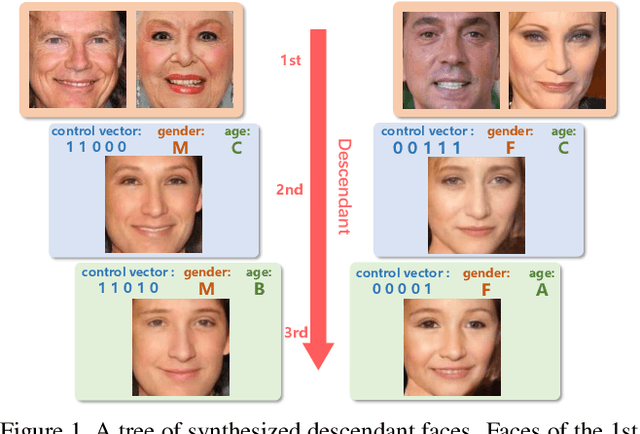
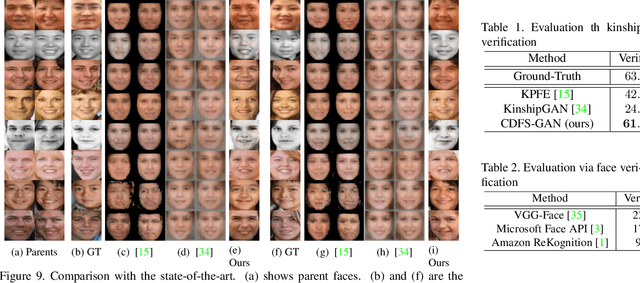
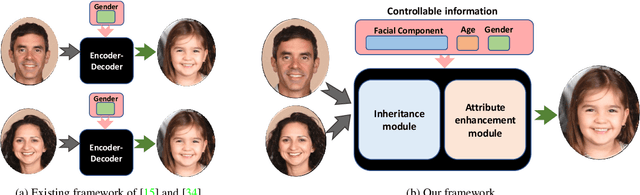
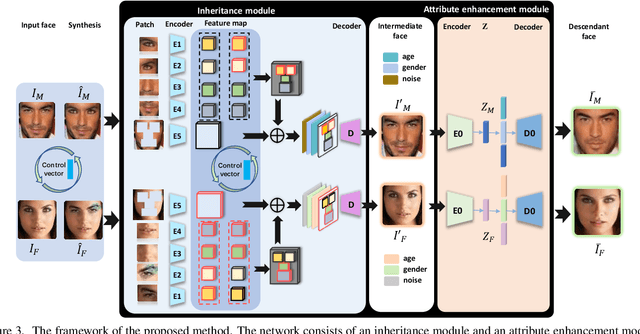
Kinship face synthesis is an interesting topic raised to answer questions like "what will your future children look like?". Published approaches to this topic are limited. Most of the existing methods train models for one-versus-one kin relation, which only consider one parent face and one child face by directly using an auto-encoder without any explicit control over the resemblance of the synthesized face to the parent face. In this paper, we propose a novel method for controllable descendant face synthesis, which models two-versus-one kin relation between two parent faces and one child face. Our model consists of an inheritance module and an attribute enhancement module, where the former is designed for accurate control over the resemblance between the synthesized face and parent faces, and the latter is designed for control over age and gender. As there is no large scale database with father-mother-child kinship annotation, we propose an effective strategy to train the model without using the ground truth descendant faces. No carefully designed image pairs are required for learning except only age and gender labels of training faces. We conduct comprehensive experimental evaluations on three public benchmark databases, which demonstrates encouraging results.
Overcoming Forgetting in Federated Learning on Non-IID Data
Oct 17, 2019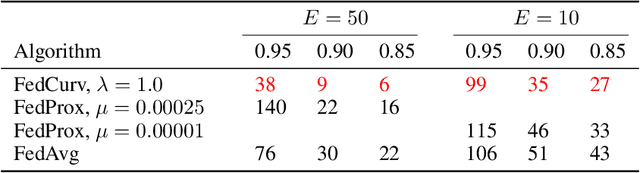
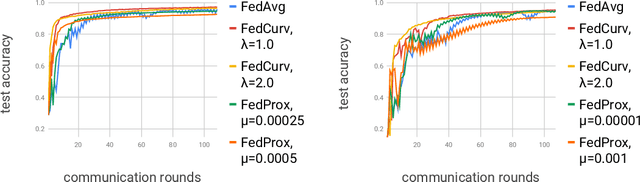
We tackle the problem of Federated Learning in the non i.i.d. case, in which local models drift apart, inhibiting learning. Building on an analogy with Lifelong Learning, we adapt a solution for catastrophic forgetting to Federated Learning. We add a penalty term to the loss function, compelling all local models to converge to a shared optimum. We show that this can be done efficiently for communication (adding no further privacy risks), scaling with the number of nodes in the distributed setting. Our experiments show that this method is superior to competing ones for image recognition on the MNIST dataset.
Accurate and Fast reconstruction of Porous Media from Extremely Limited Information Using Conditional Generative Adversarial Network
Apr 04, 2019


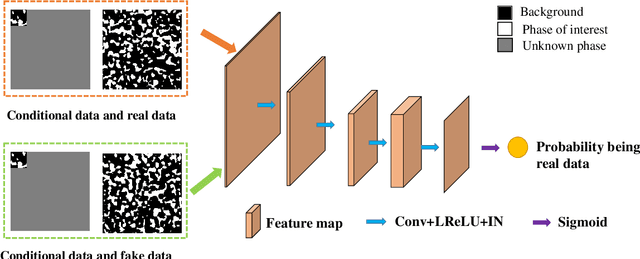
Porous media are ubiquitous in both nature and engineering applications, thus their modelling and understanding is of vital importance. In contrast to direct acquisition of three-dimensional (3D) images of such medium, obtaining its sub-region (s) like two-dimensional (2D) images or several small areas could be much feasible. Therefore, reconstructing whole images from the limited information is a primary technique in such cases. Specially, in practice the given data cannot generally be determined by users and may be incomplete or partially informed, thus making existing reconstruction methods inaccurate or even ineffective. To overcome this shortcoming, in this study we proposed a deep learning-based framework for reconstructing full image from its much smaller sub-area(s). Particularly, conditional generative adversarial network (CGAN) is utilized to learn the mapping between input (partial image) and output (full image). To preserve the reconstruction accuracy, two simple but effective objective functions are proposed and then coupled with the other two functions to jointly constrain the training procedure. Due to the inherent essence of this ill-posed problem, a Gaussian noise is introduced for producing reconstruction diversity, thus allowing for providing multiple candidate outputs. Extensively tested on a variety of porous materials and demonstrated by both visual inspection and quantitative comparison, the method is shown to be accurate, stable yet fast ($\sim0.08s$ for a $128 \times 128$ image reconstruction). We highlight that the proposed approach can be readily extended, such as incorporating any user-define conditional data and an arbitrary number of object functions into reconstruction, and being coupled with other reconstruction methods.
Equivariant Transformer Networks
Jan 25, 2019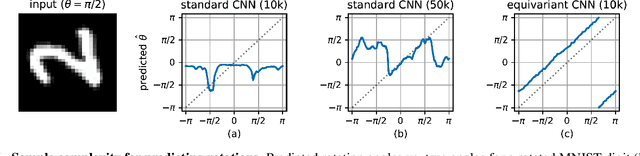
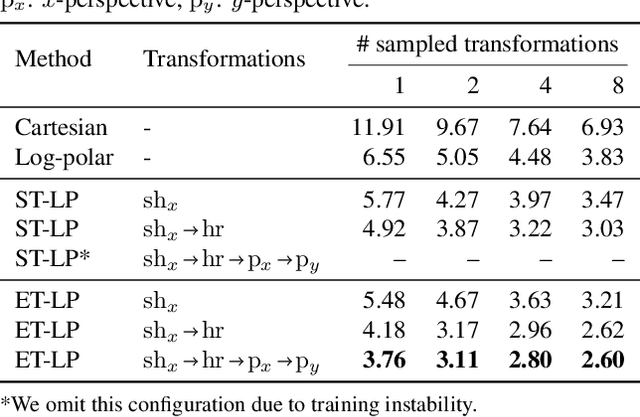
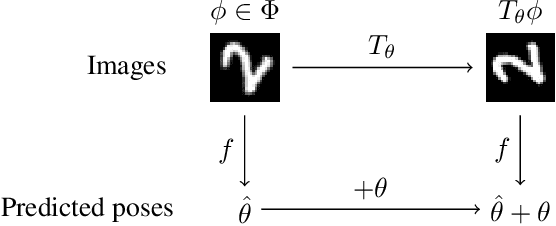
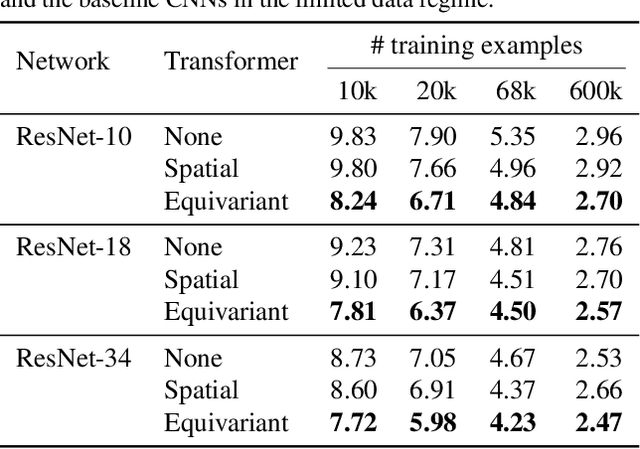
How can prior knowledge on the transformation invariances of a domain be incorporated into the architecture of a neural network? We propose Equivariant Transformers (ETs), a family of differentiable image-to-image mappings that improve the robustness of models towards pre-defined continuous transformation groups. Through the use of specially-derived canonical coordinate systems, ETs incorporate functions that are equivariant by construction with respect to these transformations. We show empirically that ETs can be flexibly composed to improve model robustness towards more complicated transformation groups in several parameters. On a real-world image classification task, ETs improve the sample efficiency of ResNet classifiers, achieving relative improvements in error rate of up to 15% in the limited data regime while increasing model parameter count by less than 1%.
Autoregressive Models: What Are They Good For?
Oct 17, 2019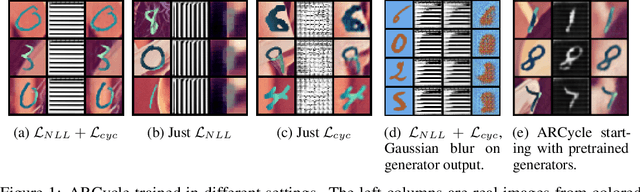
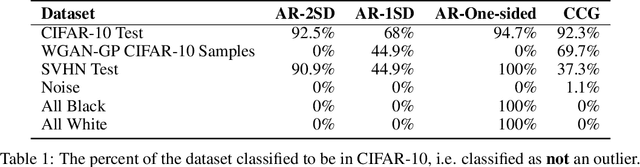


Autoregressive (AR) models have become a popular tool for unsupervised learning, achieving state-of-the-art log likelihood estimates. We investigate the use of AR models as density estimators in two settings -- as a learning signal for image translation, and as an outlier detector -- and find that these density estimates are much less reliable than previously thought. We examine the underlying optimization issues from both an empirical and theoretical perspective, and provide a toy example that illustrates the problem. Overwhelmingly, we find that density estimates do not correlate with perceptual quality and are unhelpful for downstream tasks.
deepCR: Cosmic Ray Rejection with Deep Learning
Aug 29, 2019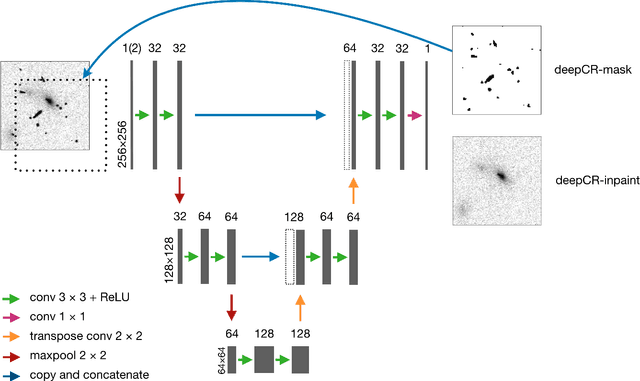
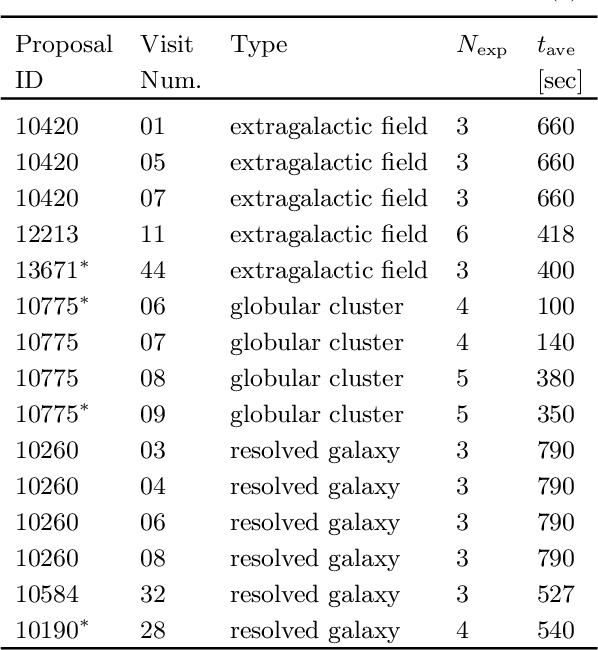

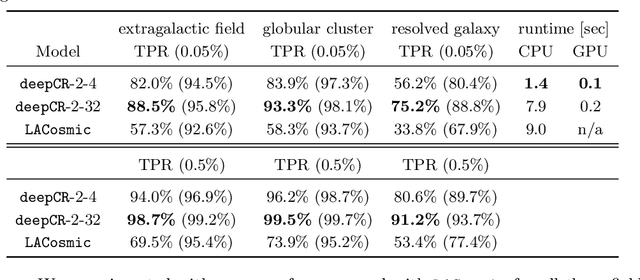
Cosmic ray (CR) identification and replacement are critical components of imaging and spectroscopic reduction pipelines involving solid-state detectors. We present deepCR, a deep learning based framework for CR identification and subsequent image inpainting based on the predicted CR mask. To demonstrate the effectiveness of this framework, we train and evaluate models on Hubble Space Telescope ACS/WFC images of sparse extragalactic fields, globular clusters, and resolved galaxies. We demonstrate that at a false positive rate of 0.5%, deepCR achieves close to 100% detection rates in both extragalactic and globular cluster fields, and 91% in resolved galaxy fields, which is a significant improvement over the current state-of-the-art method LACosmic. Compared to a multicore CPU implementation of LACosmic, deepCR CR mask predictions run up to 6.5 times faster on CPU and 90 times faster on a single GPU. For image inpainting, the mean squared errors of deepCR predictions are 20 times lower in globular cluster fields, 5 times lower in resolved galaxy fields, and 2.5 times lower in extragalactic fields, compared to the best performing non-neural technique tested. We present our framework and the trained models as an open-source Python project, with a simple-to-use API. To facilitate reproducibility of the results we also provide a benchmarking codebase.
HybridPose: 6D Object Pose Estimation under Hybrid Representations
Jan 07, 2020
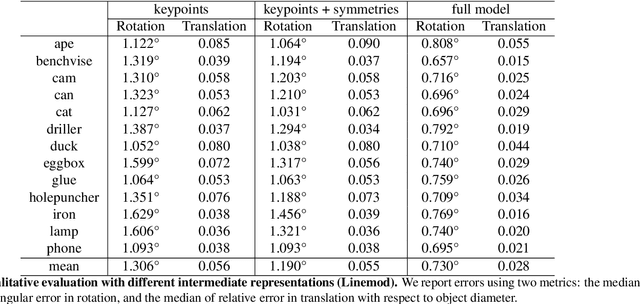
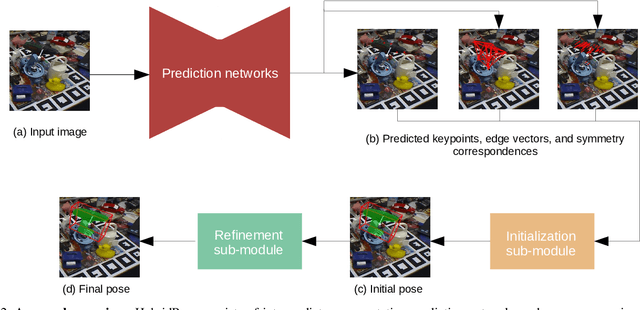
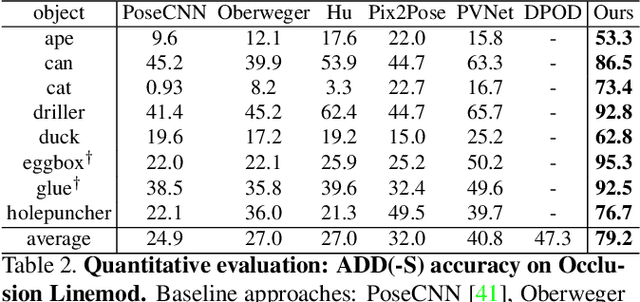
We introduce HybridPose, a novel 6D object pose estimation approach. HybridPose utilizes a hybrid intermediate representation to express different geometric information in the input image, including keypoints, edge vectors, and symmetry correspondences. Compared to a unitary representation, our hybrid representation allows pose regression to exploit more and diverse features when one type of predicted representation is inaccurate (e.g., because of occlusion). HybridPose leverages a robust regression module to filter out outliers in predicted intermediate representation. We show the robustness of HybridPose by demonstrating that all intermediate representations can be predicted by the same simple neural network without sacrificing the overall performance. Compared to state-of-the-art pose estimation approaches, HybridPose is comparable in running time and is significantly more accurate. For example, on Occlusion Linemod dataset, our method achieves a prediction speed of 30 fps with a mean ADD(-S) accuracy of 79.2%, representing a 67.4% improvement from the current state-of-the-art approach. Our implementation of HybridPose is available at https://github.com/chensong1995/HybridPose.