 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RePose: Learning Deep Kinematic Priors for Fast Human Pose Estimation
Feb 10, 2020

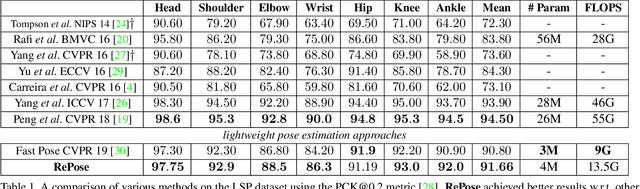
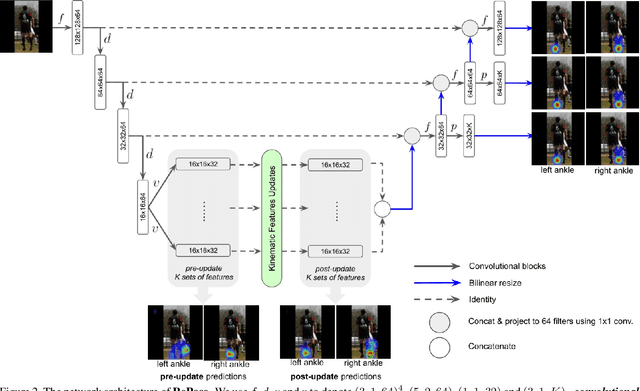
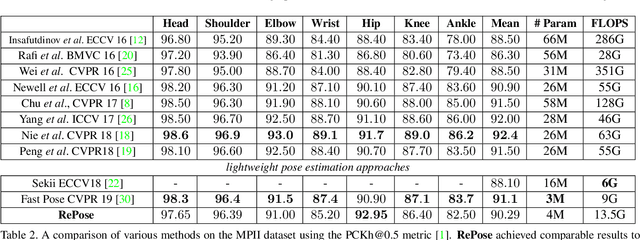
We propose a novel efficient and lightweight model for human pose estimation from a single image. Our model is designed to achieve competitive results at a fraction of the number of parameters and computational cost of various state-of-the-art methods. To this end, we explicitly incorporate part-based structural and geometric priors in a hierarchical prediction framework. At the coarsest resolution, and in a manner similar to classical part-based approaches, we leverage the kinematic structure of the human body to propagate convolutional feature updates between the keypoints or body parts. Unlike classical approaches, we adopt end-to-end training to learn this geometric prior through feature updates from data. We then propagate the feature representation at the coarsest resolution up the hierarchy to refine the predicted pose in a coarse-to-fine fashion. The final network effectively models the geometric prior and intuition within a lightweight deep neural network, yielding state-of-the-art results for a model of this size on two standard datasets, Leeds Sports Pose and MPII Human Pose.
Fast 3D Pose Refinement with RGB Images
Nov 17, 2019
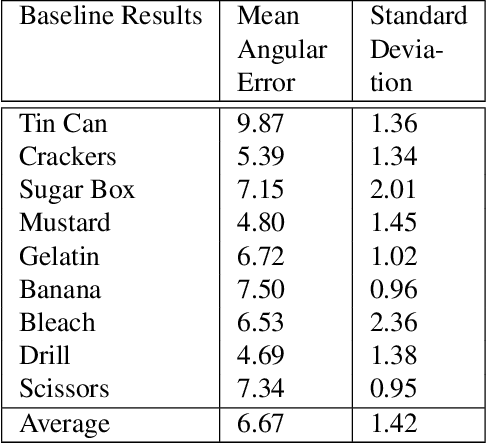

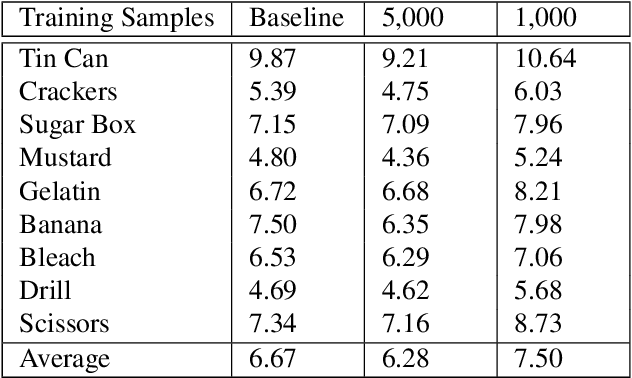
Pose estimation is a vital step in many robotics and perception tasks such as robotic manipulation, autonomous vehicle navigation, etc. Current state-of-the-art pose estimation methods rely on deep neural networks with complicated structures and long inference times. While highly robust, they require computing power often unavailable on mobile robots. We propose a CNN-based pose refinement system which takes a coarsely estimated 3D pose from a computationally cheaper algorithm along with a bounding box image of the object, and returns a highly refined pose. Our experiments on the YCB-Video dataset show that our system can refine 3D poses to an extremely high precision with minimal training data.
Probing the State of the Art: A Critical Look at Visual Representation Evaluation
Nov 30, 2019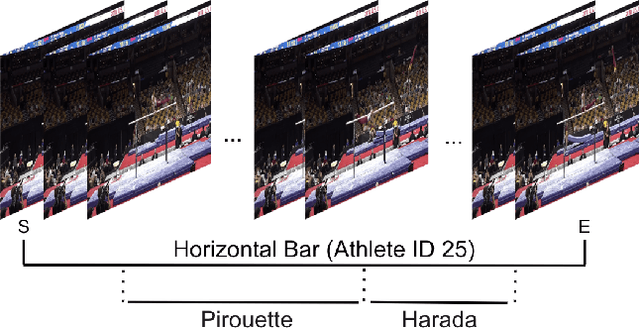
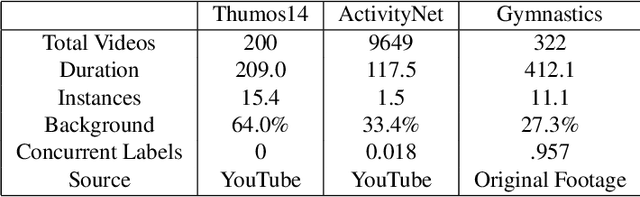
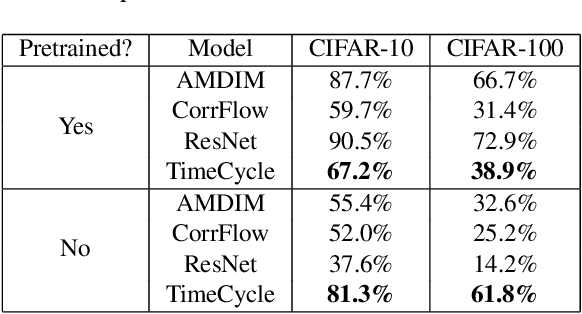
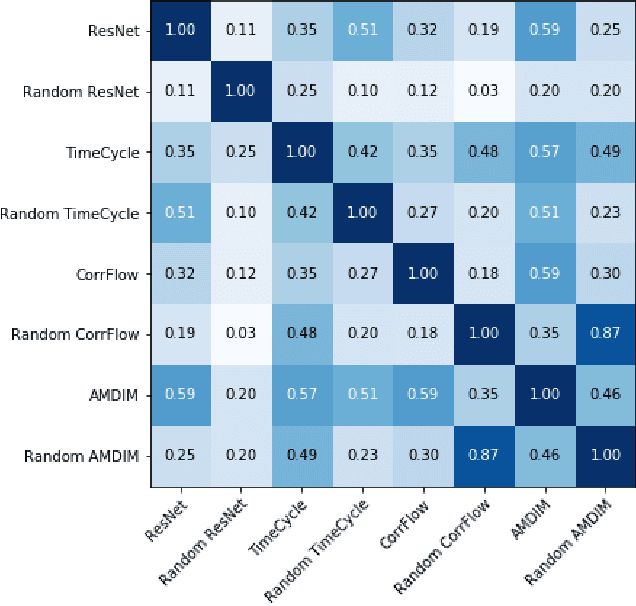
Self-supervised research improved greatly over the past half decade, with much of the growth being driven by objectives that are hard to quantitatively compare. These techniques include colorization, cyclical consistency, and noise-contrastive estimation from image patches. Consequently, the field has settled on a handful of measurements that depend on linear probes to adjudicate which approaches are the best. Our first contribution is to show that this test is insufficient and that models which perform poorly (strongly) on linear classification can perform strongly (weakly) on more involved tasks like temporal activity localization. Our second contribution is to analyze the capabilities of five different representations. And our third contribution is a much needed new dataset for temporal activity localization.
M3D-RPN: Monocular 3D Region Proposal Network for Object Detection
Aug 11, 2019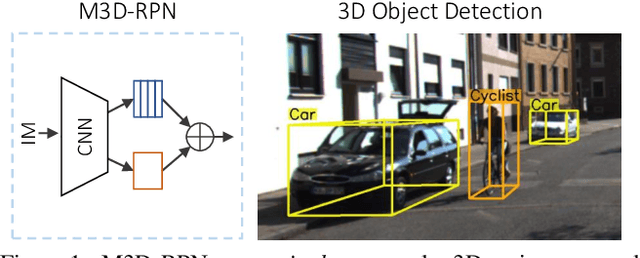

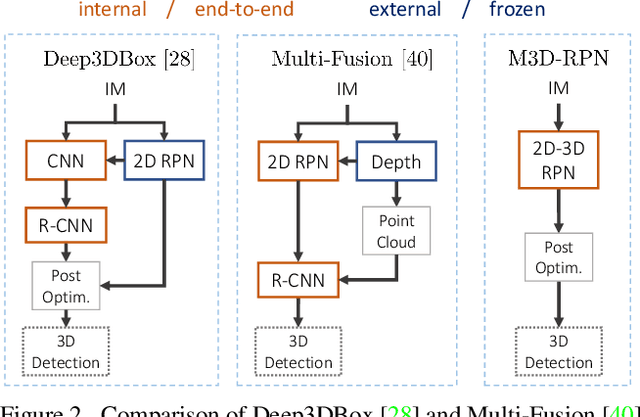

Understanding the world in 3D is a critical component of urban autonomous driving. Generally, the combination of expensive LiDAR sensors and stereo RGB imaging has been paramount for successful 3D object detection algorithms, whereas monocular image-only methods experience drastically reduced performance. We propose to reduce the gap by reformulating the monocular 3D detection problem as a standalone 3D region proposal network. We leverage the geometric relationship of 2D and 3D perspectives, allowing 3D boxes to utilize well-known and powerful convolutional features generated in the image-space. To help address the strenuous 3D parameter estimations, we further design depth-aware convolutional layers which enable location specific feature development and in consequence improved 3D scene understanding. Compared to prior work in monocular 3D detection, our method consists of only the proposed 3D region proposal network rather than relying on external networks, data, or multiple stages. M3D-RPN is able to significantly improve the performance of both monocular 3D Object Detection and Bird's Eye View tasks within the KITTI urban autonomous driving dataset, while efficiently using a shared multi-class model.
On Leveraging Pretrained GANs for Limited-Data Generation
Feb 26, 2020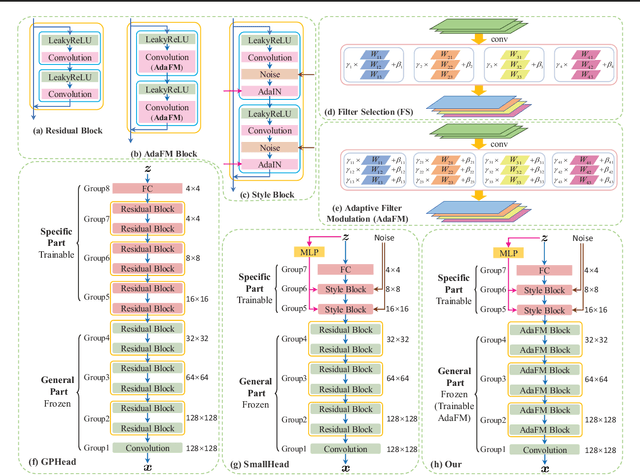
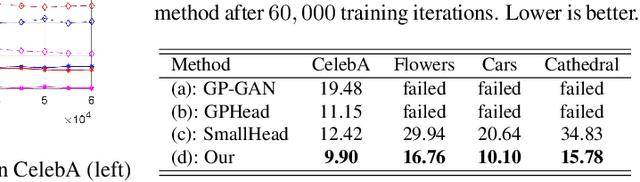

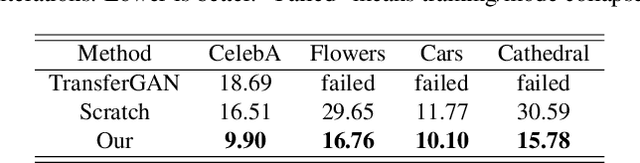
Recent work has shown GANs can generate highly realistic images that are indistinguishable by human. Of particular interest here is the empirical observation that most generated images are not contained in training datasets, indicating potential generalization with GANs. That generalizability makes it appealing to exploit GANs to help applications with limited available data, e.g., augment training data to alleviate overfitting. To better facilitate training a GAN on limited data, we propose to leverage already-available GAN models pretrained on large-scale datasets (like ImageNet) to introduce additional common knowledge (which may not exist within the limited data) following the transfer learning idea. Specifically, exampled by natural image generation tasks, we reveal the fact that low-level filters (those close to observations) of both the generator and discriminator of pretrained GANs can be transferred to help the target limited-data generation. For better adaption of the transferred filters to the target domain, we introduce a new technique named adaptive filter modulation (AdaFM), which provides boosted performance over baseline methods. Unifying the transferred filters and the introduced techniques, we present our method and conduct extensive experiments to demonstrate its training efficiency and better performance on limited-data generation.
LiDAR guided Small obstacle Segmentation
Mar 12, 2020
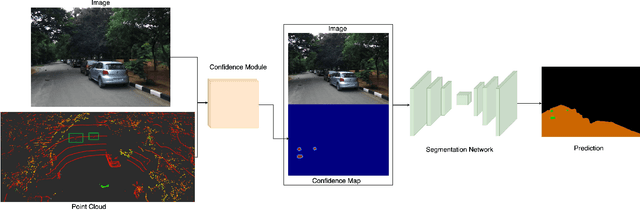
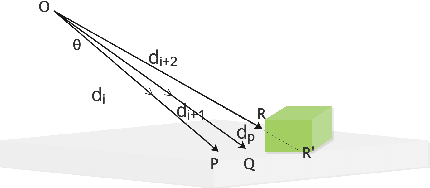
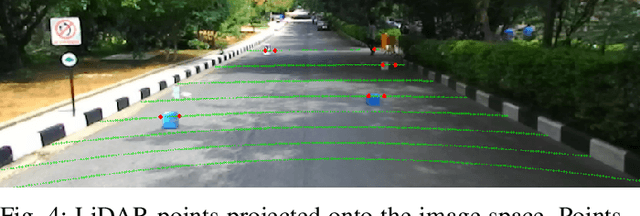
Detecting small obstacles on the road is critical for autonomous driving. In this paper, we present a method to reliably detect such obstacles through a multi-modal framework of sparse LiDAR(VLP-16) and Monocular vision. LiDAR is employed to provide additional context in the form of confidence maps to monocular segmentation networks. We show significant performance gains when the context is fed as an additional input to monocular semantic segmentation frameworks. We further present a new semantic segmentation dataset to the community, comprising of over 3000 image frames with corresponding LiDAR observations. The images come with pixel-wise annotations of three classes off-road, road, and small obstacle. We stress that precise calibration between LiDAR and camera is crucial for this task and thus propose a novel Hausdorff distance based calibration refinement method over extrinsic parameters. As a first benchmark over this dataset, we report our results with 73% instance detection up to a distance of 50 meters on challenging scenarios. Qualitatively by showcasing accurate segmentation of obstacles less than 15 cms at 50m depth and quantitatively through favourable comparisons vis a vis prior art, we vindicate the method's efficacy. Our project-page and Dataset is hosted at https://small-obstacle-dataset.github.io/
FIRE: Unsupervised bi-directional inter-modality registration using deep networks
Jul 11, 2019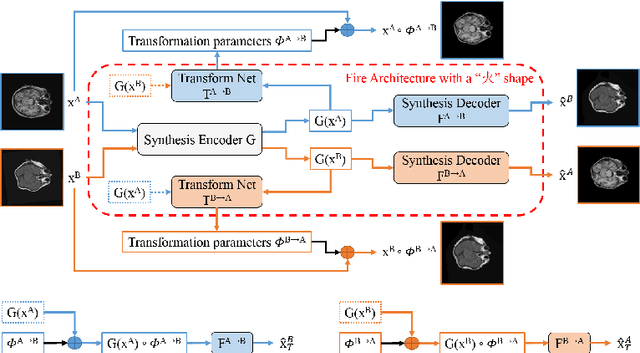
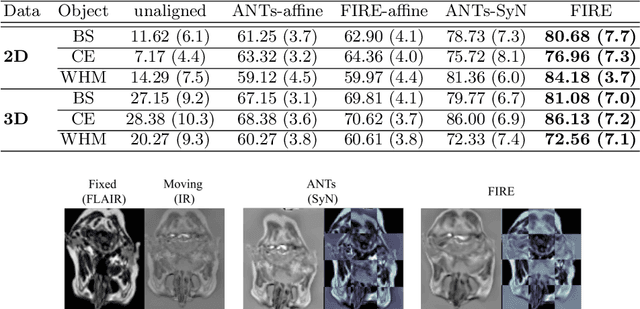
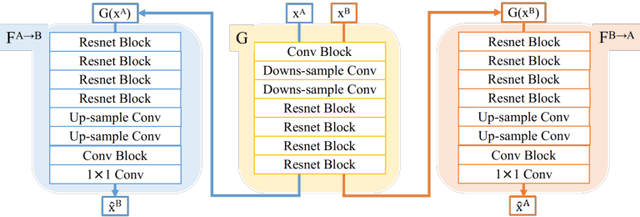

Inter-modality image registration is an critical preprocessing step for many applications within the routine clinical pathway. This paper presents an unsupervised deep inter-modality registration network that can learn the optimal affine and non-rigid transformations simultaneously. Inverse-consistency is an important property commonly ignored in recent deep learning based inter-modality registration algorithms. We address this issue through the proposed multi-task architecture and the new comprehensive transformation network. Specifically, the proposed model learns a modality-independent latent representation to perform cycle-consistent cross-modality synthesis, and use an inverse-consistent loss to learn a pair of transformations to align the synthesized image with the target. We name this proposed framework as FIRE due to the shape of its structure. Our method shows comparable and better performances with the popular baseline method in experiments on multi-sequence brain MR data and intra-modality 4D cardiac Cine-MR data.
LU-Net: An Efficient Network for 3D LiDAR Point Cloud Semantic Segmentation Based on End-to-End-Learned 3D Features and U-Net
Aug 30, 2019
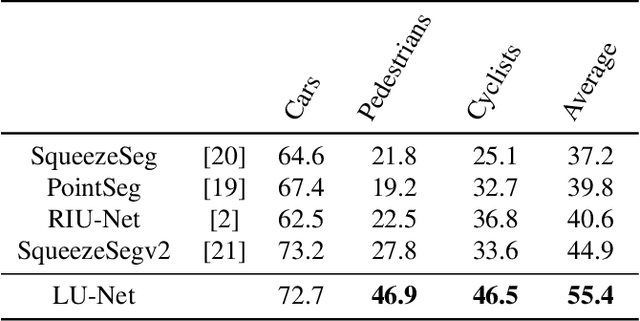

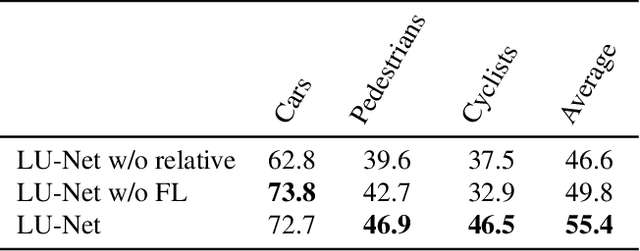
We propose LU-Net -- for LiDAR U-Net, a new method for the semantic segmentation of a 3D LiDAR point cloud. Instead of applying some global 3D segmentation method such as PointNet, we propose an end-to-end architecture for LiDAR point cloud semantic segmentation that efficiently solves the problem as an image processing problem. We first extract high-level 3D features for each point given its 3D neighbors. Then, these features are projected into a 2D multichannel range-image by considering the topology of the sensor. Thanks to these learned features and this projection, we can finally perform the segmentation using a simple U-Net segmentation network, which performs very well while being very efficient. In this way, we can exploit both the 3D nature of the data and the specificity of the LiDAR sensor. This approach outperforms the state-of-the-art by a large margin on the KITTI dataset, as our experiments show. Moreover, this approach operates at 24fps on a single GPU. This is above the acquisition rate of common LiDAR sensors which makes it suitable for real-time applications.
Learning Object Placements For Relational Instructions by Hallucinating Scene Representations
Jan 23, 2020
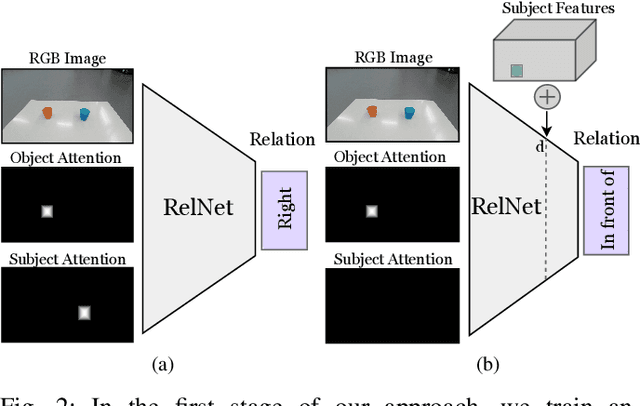
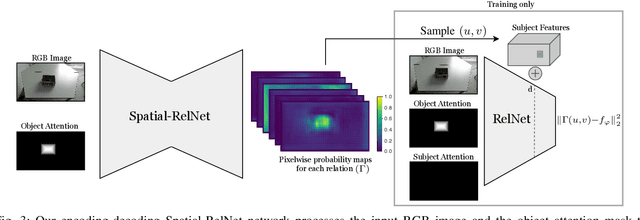

Robots coexisting with humans in their environment and performing services for them need the ability to interact with them. One particular requirement for such robots is that they are able to understand spatial relations and can place objects in accordance with the spatial relations expressed by their user. In this work, we present a convolutional neural network for estimating pixelwise object placement probabilities for a set of spatial relations from a single input image. During training, our network receives the learning signal by classifying hallucinated high-level scene representations as an auxiliary task. Unlike previous approaches, our method does not require ground truth data for the pixelwise relational probabilities or 3D models of the objects, which significantly expands the applicability in practical applications. Our results obtained using real-world data and human-robot experiments demonstrate the effectiveness of our method in reasoning about the best way to place objects to reproduce a spatial relation.
Real-time 3D Deep Multi-Camera Tracking
Mar 26, 2020
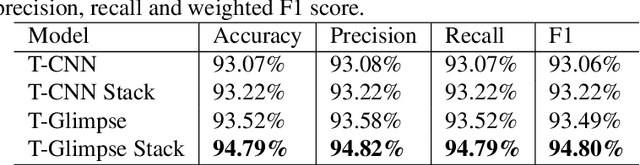
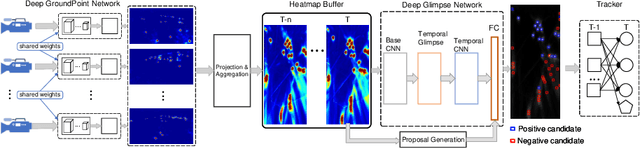

Tracking a crowd in 3D using multiple RGB cameras is a challenging task. Most previous multi-camera tracking algorithms are designed for offline setting and have high computational complexity. Robust real-time multi-camera 3D tracking is still an unsolved problem. In this work, we propose a novel end-to-end tracking pipeline, Deep Multi-Camera Tracking (DMCT), which achieves reliable real-time multi-camera people tracking. Our DMCT consists of 1) a fast and novel perspective-aware Deep GroudPoint Network, 2) a fusion procedure for ground-plane occupancy heatmap estimation, 3) a novel Deep Glimpse Network for person detection and 4) a fast and accurate online tracker. Our design fully unleashes the power of deep neural network to estimate the "ground point" of each person in each color image, which can be optimized to run efficiently and robustly. Our fusion procedure, glimpse network and tracker merge the results from different views, find people candidates using multiple video frames and then track people on the fused heatmap. Our system achieves the state-of-the-art tracking results while maintaining real-time performance. Apart from evaluation on the challenging WILDTRACK dataset, we also collect two more tracking datasets with high-quality labels from two different environments and camera settings. Our experimental results confirm that our proposed real-time pipeline gives superior results to previous approaches.