 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Body Shape and Pose from Dense Correspondences
Jul 27, 2019
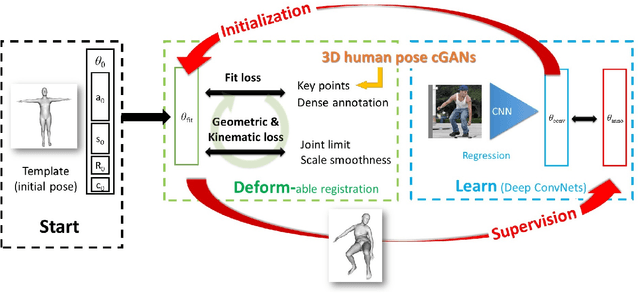

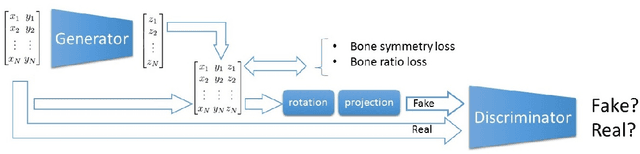

In this paper, we address the problem of learning 3D human pose and body shape from 2D image dataset, without having to use 3D dataset (body shape and pose). The idea is to use dense correspondences between image points and a body surface, which can be annotated on in-the wild 2D images, and extract and aggregate 3D information from them. To do so, we propose a training strategy called ``deform-and-learn" where we alternate deformable surface registration and training of deep convolutional neural networks (ConvNets). Unlike previous approaches, our method does not require 3D pose annotations from a motion capture (MoCap) system or human intervention to validate 3D pose annotations.
Active Convolution: Learning the Shape of Convolution for Image Classification
Mar 27, 2017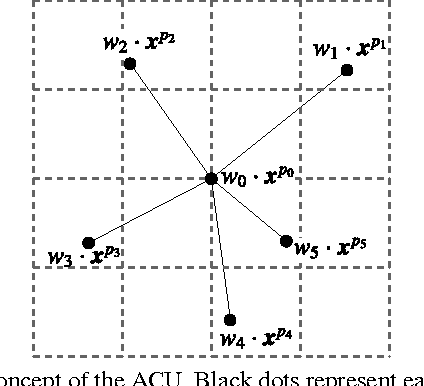
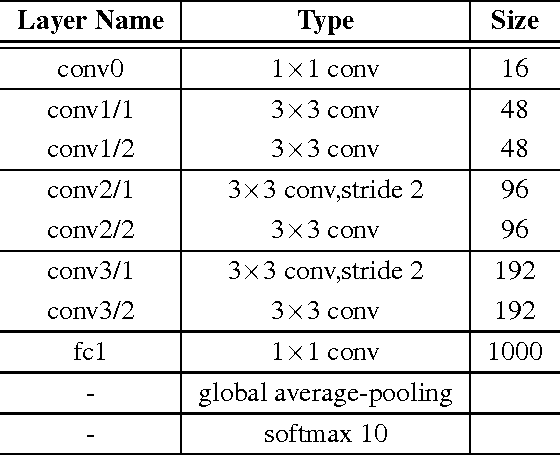
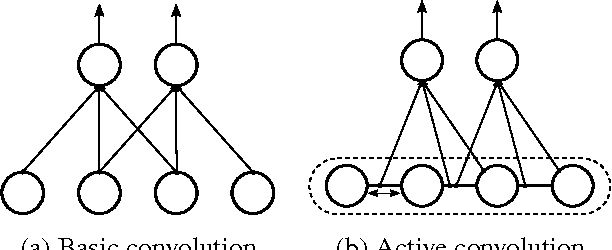

In recent years, deep learning has achieved great success in many computer vision applications. Convolutional neural networks (CNNs) have lately emerged as a major approach to image classification. Most research on CNNs thus far has focused on developing architectures such as the Inception and residual networks. The convolution layer is the core of the CNN, but few studies have addressed the convolution unit itself. In this paper, we introduce a convolution unit called the active convolution unit (ACU). A new convolution has no fixed shape, because of which we can define any form of convolution. Its shape can be learned through backpropagation during training. Our proposed unit has a few advantages. First, the ACU is a generalization of convolution; it can define not only all conventional convolutions, but also convolutions with fractional pixel coordinates. We can freely change the shape of the convolution, which provides greater freedom to form CNN structures. Second, the shape of the convolution is learned while training and there is no need to tune it by hand. Third, the ACU can learn better than a conventional unit, where we obtained the improvement simply by changing the conventional convolution to an ACU. We tested our proposed method on plain and residual networks, and the results showed significant improvement using our method on various datasets and architectures in comparison with the baseline.
A2D2: Audi Autonomous Driving Dataset
Apr 14, 2020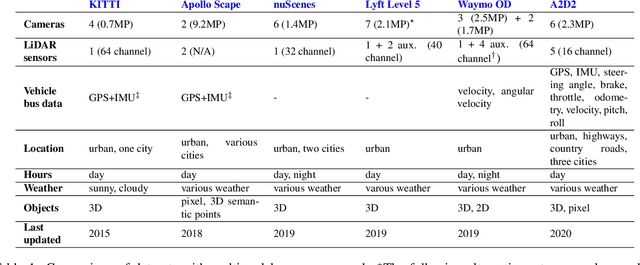



Research in machine learning, mobile robotics, and autonomous driving is accelerated by the availability of high quality annotated data. To this end, we release the Audi Autonomous Driving Dataset (A2D2). Our dataset consists of simultaneously recorded images and 3D point clouds, together with 3D bounding boxes, semantic segmentation, instance segmentation, and data extracted from the automotive bus. Our sensor suite consists of six cameras and five LiDAR units, providing full 360 degree coverage. The recorded data is time synchronized and mutually registered. Annotations are for non-sequential frames: 41,277 frames with semantic segmentation image and point cloud labels, of which 12,497 frames also have 3D bounding box annotations for objects within the field of view of the front camera. In addition, we provide 392,556 sequential frames of unannotated sensor data for recordings in three cities in the south of Germany. These sequences contain several loops. Faces and vehicle number plates are blurred due to GDPR legislation and to preserve anonymity. A2D2 is made available under the CC BY-ND 4.0 license, permitting commercial use subject to the terms of the license. Data and further information are available at http://www.a2d2.audi.
Soft-Label Dataset Distillation and Text Dataset Distillation
Nov 12, 2019

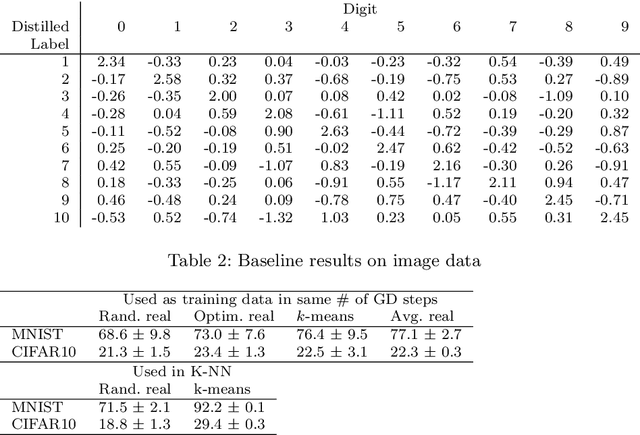
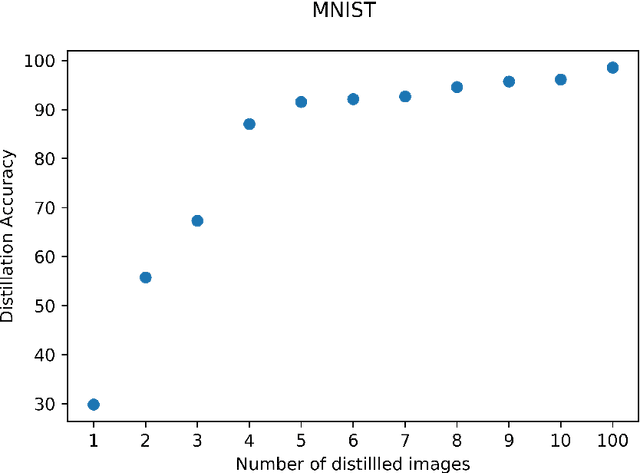
Dataset distillation is a method for reducing dataset sizes by learning a small number of synthetic samples containing all the information of a large dataset. This has several benefits like speeding up model training, reducing energy consumption, and reducing required storage space. Currently, each synthetic sample is assigned a single `hard' label, and also, dataset distillation can currently only be used with image data. We propose to simultaneously distill both images and their labels, thus assigning each synthetic sample a `soft' label (a distribution of labels). Our algorithm increases accuracy by 2-4% over the original algorithm for several image classification tasks. Using `soft' labels also enables distilled datasets to consist of fewer samples than there are classes as each sample can encode information for multiple classes. For example, training a LeNet model with 10 distilled images (one per class) results in over 96% accuracy on MNIST, and almost 92% accuracy when trained on just 5 distilled images. We also extend the dataset distillation algorithm to distill sequential datasets including texts. We demonstrate that text distillation outperforms other methods across multiple datasets. For example, models attain almost their original accuracy on the IMDB sentiment analysis task using just 20 distilled sentences.
Face Liveness Detection Based on Client Identity Using Siamese Network
Mar 13, 2019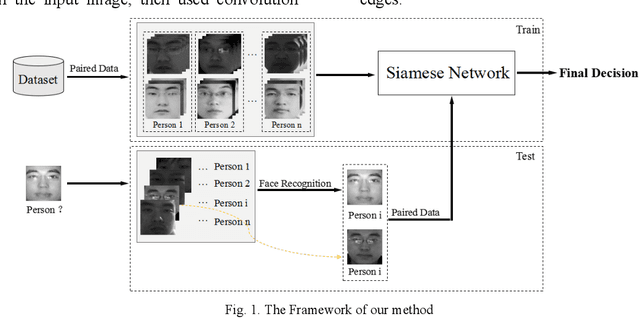
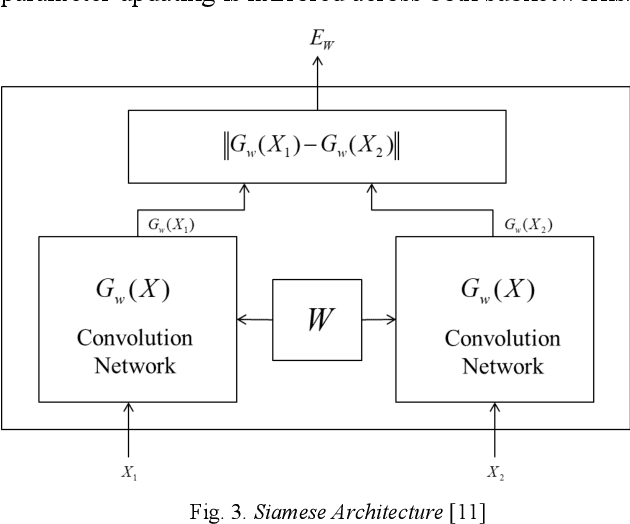
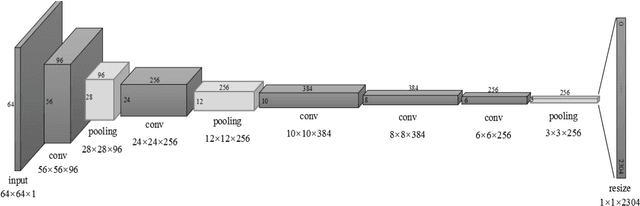

Face liveness detection is an essential prerequisite for face recognition applications. Previous face liveness detection methods usually train a binary classifier to differentiate between a fake face and a real face before face recognition. The client identity information is not utilized in previous face liveness detection methods. However, in practical face recognition applications, face spoofing attacks are always aimed at a specific client, and the client identity information can provide useful clues for face liveness detection. In this paper, we propose a face liveness detection method based on the client identity using Siamese network. We detect face liveness after face recognition instead of before face recognition, that is, we detect face liveness with the client identity information. We train a Siamese network with image pairs. Each image pair consists of two real face images or one real and one fake face images. The face images in each pair come from a same client. Given a test face image, the face image is firstly recognized by face recognition system, then the real face image of the identified client is retrieved to help the face liveness detection. Experiment results demonstrate the effectiveness of our method.
Decentralized decision making and navigation strategy for tracking intruders in a cluttered area by a group of mobile robots
Jun 13, 2020
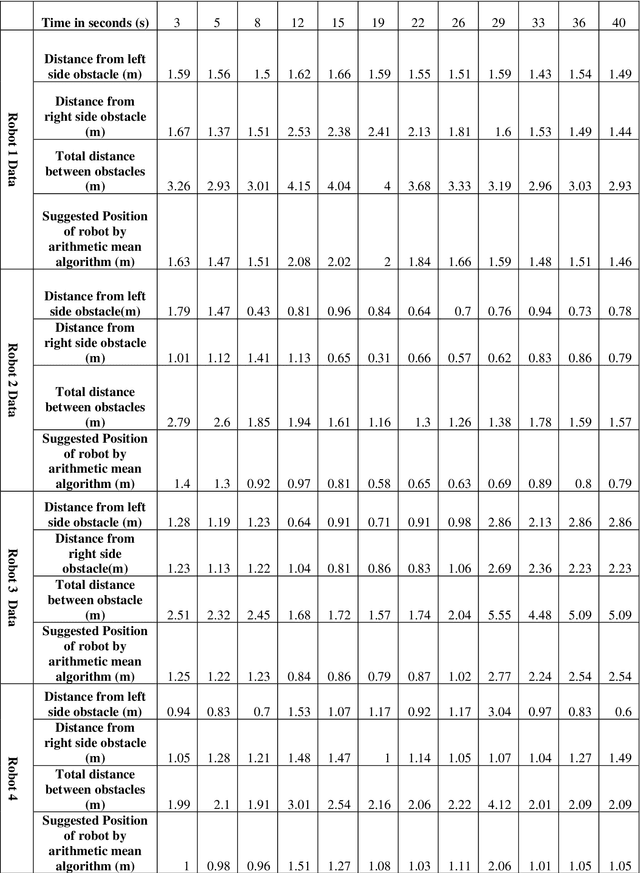
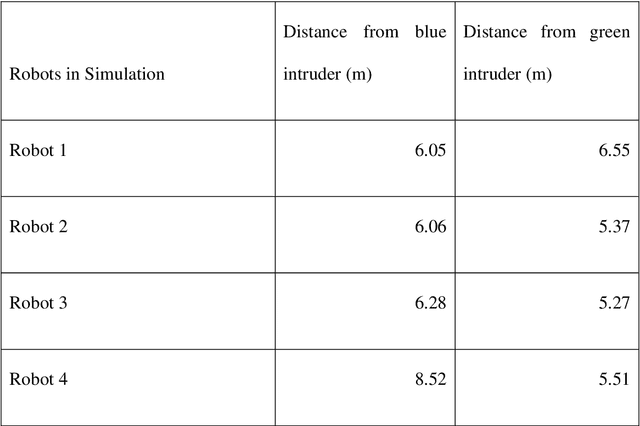
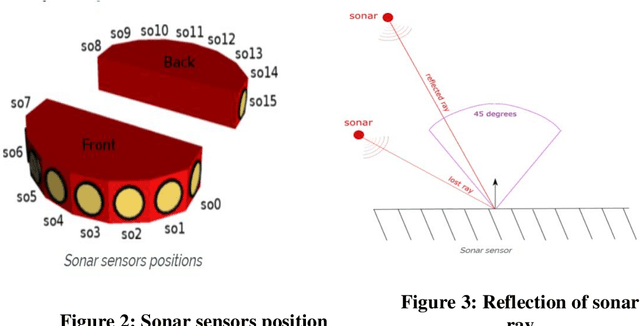
In the current era of the industrial revolution, mobile robots are playing a pivotal role in helping out mankind in many complex and hazardous environments for performing tasks like search and rescue, obstacle avoidance, mining and security surveillance, etc. A lot of navigation algorithms have been developed in recent years but novel challenges still exist in autonomous path planning of multiple robots to track and follow multiple intruders. This report demonstrates a decentralized strategy of arithmetic mean based navigation algorithm for a group of mobile robots to navigate through an unknown environment filled with obstacles to detect and follow multiple invading intruders. The suggested navigation strategy ensures that mobile robots safely move right in the middle of surrounding obstacles to maintain a safe distance and to avoid collision with obstacles and each other. The conventional method of color recognition is used to detect dynamic intruders and calculate pixel values using the Microsoft Kinect sensor camera. A probability of danger algorithm is introduced to ensure that all the intruders present in the environment are being followed by friendly robots on the bases of the minimum distance between an intruder and its follower. The mobile robots follow intruders movement on the bases of their pixel values. The low pixel value means that intruder is far away and high pixel value represents that intruder is closer to the friendly robots. All the algorithms and image processing techniques are implemented and tested in WEBOTS simulation environment using C programming language and the results show the success of proposed arithmetic mean based navigation and probability of danger based intruders following algorithms.
Stochasticity in Neural ODEs: An Empirical Study
Feb 22, 2020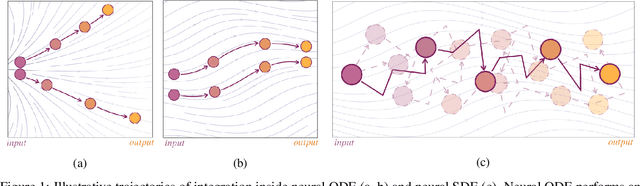
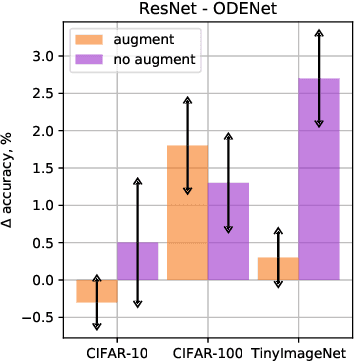
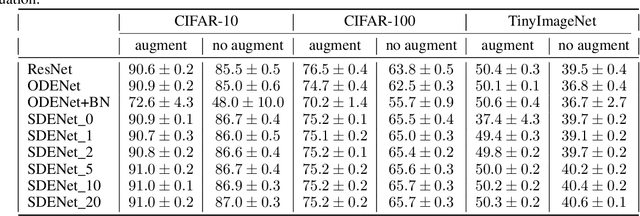
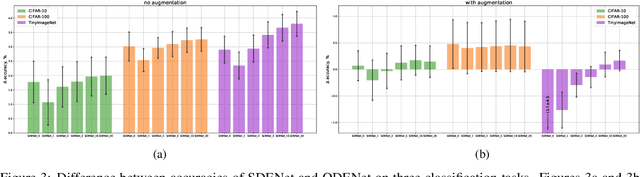
Stochastic regularization of neural networks (e.g. dropout) is a wide-spread technique in deep learning that allows for better generalization. Despite its success, continuous-time models, such as neural ordinary differential equation (ODE), usually rely on a completely deterministic feed-forward operation. This work provides an empirical study of stochastically regularized neural ODE on several image-classification tasks (CIFAR-10, CIFAR-100, TinyImageNet). Building upon the formalism of stochastic differential equations (SDEs), we demonstrate that neural SDE is able to outperform its deterministic counterpart. Further, we show that data augmentation during the training improves the performance of both deterministic and stochastic versions of the same model. However, the improvements obtained by the data augmentation completely eliminate the empirical gains of the stochastic regularization, making the difference in the performance of neural ODE and neural SDE negligible.
Deep Face Super-Resolution with Iterative Collaboration between Attentive Recovery and Landmark Estimation
Mar 29, 2020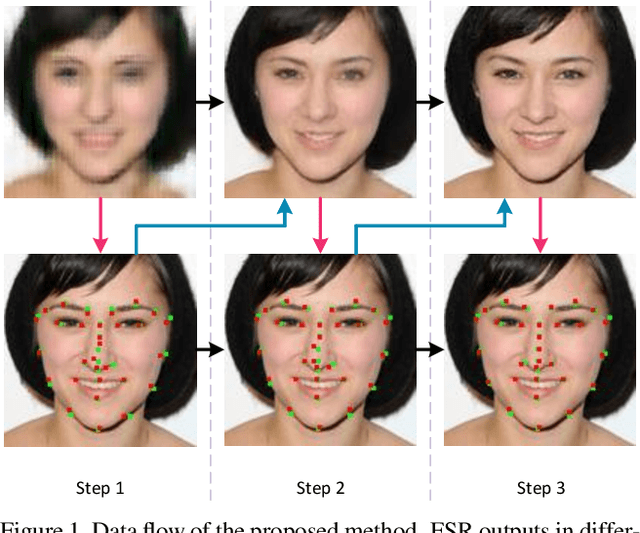
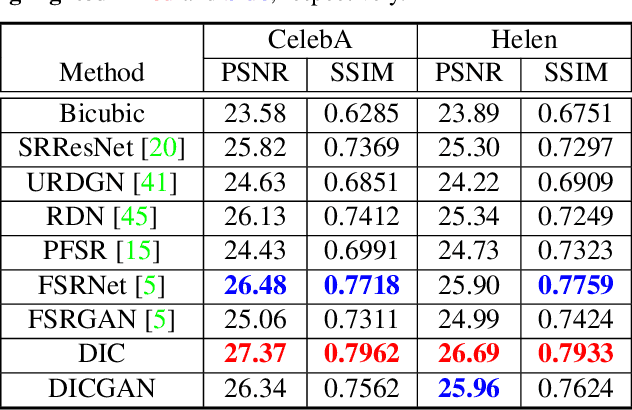
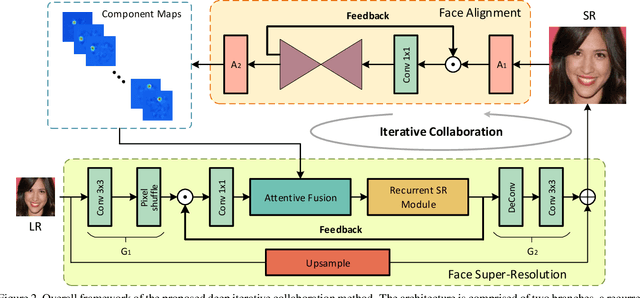
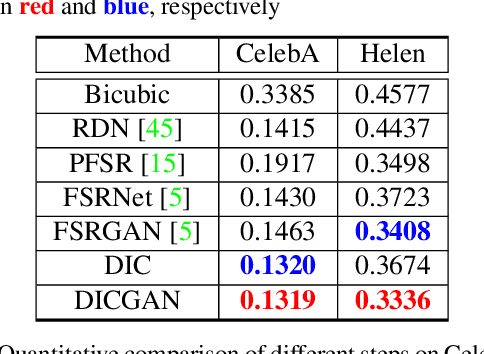
Recent works based on deep learning and facial priors have succeeded in super-resolving severely degraded facial images. However, the prior knowledge is not fully exploited in existing methods, since facial priors such as landmark and component maps are always estimated by low-resolution or coarsely super-resolved images, which may be inaccurate and thus affect the recovery performance. In this paper, we propose a deep face super-resolution (FSR) method with iterative collaboration between two recurrent networks which focus on facial image recovery and landmark estimation respectively. In each recurrent step, the recovery branch utilizes the prior knowledge of landmarks to yield higher-quality images which facilitate more accurate landmark estimation in turn. Therefore, the iterative information interaction between two processes boosts the performance of each other progressively. Moreover, a new attentive fusion module is designed to strengthen the guidance of landmark maps, where facial components are generated individually and aggregated attentively for better restoration. Quantitative and qualitative experimental results show the proposed method significantly outperforms state-of-the-art FSR methods in recovering high-quality face images.
PILOT: Physics-Informed Learned Optimal Trajectories for Accelerated MRI
Sep 12, 2019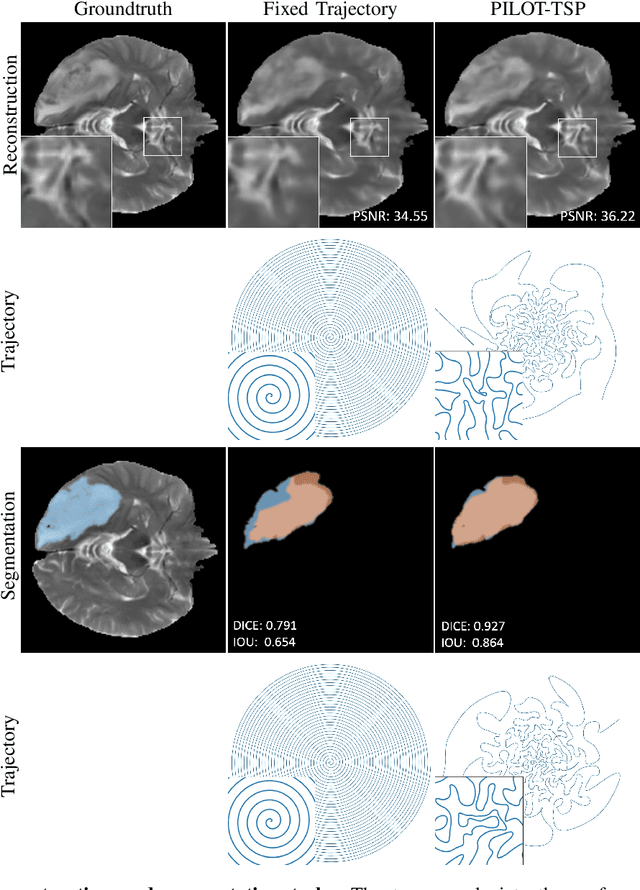

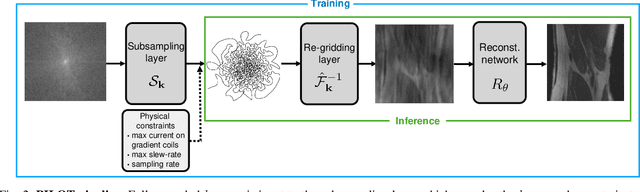
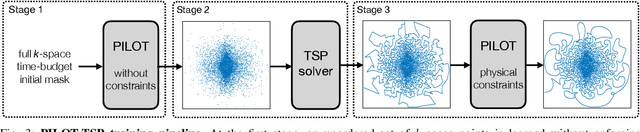
Magnetic Resonance Imaging (MRI) has long been considered to be among "the gold standards" of diagnostic medical imaging. The long acquisition times, however, render MRI prone to motion artifacts, let alone their adverse contribution to the relative high costs of MRI examination. Over the last few decades, multiple studies have focused on the development of both physical and post-processing methods for accelerated acquisition of MRI scans. These two approaches, however, have so far been addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of concurrent learning-based design of data acquisition and image reconstruction schemes. In this work, we propose a novel approach to the learning of optimal schemes for conjoint acquisition and reconstruction of MRI scans, with the optimization carried out simultaneously with respect to the time-efficiency of data acquisition and the quality of resulting reconstructions. To be of a practical value, the schemes are encoded in the form of general k-space trajectories, whose associated magnetic gradients are constrained to obey a set of predefined hardware requirements (as defined in terms of, e.g., peak currents and maximum slew rates of magnetic gradients). With this proviso in mind, we propose a novel algorithm for the end-to-end training of a combined acquisition-reconstruction pipeline using a deep neural network with differentiable forward- and back-propagation operators. We also demonstrate the effectiveness of the proposed solution in application to both image reconstruction and image segmentation, reporting substantial improvements in terms of acceleration factors as well as the quality of these end tasks.
Visual Dialogue State Tracking for Question Generation
Nov 12, 2019
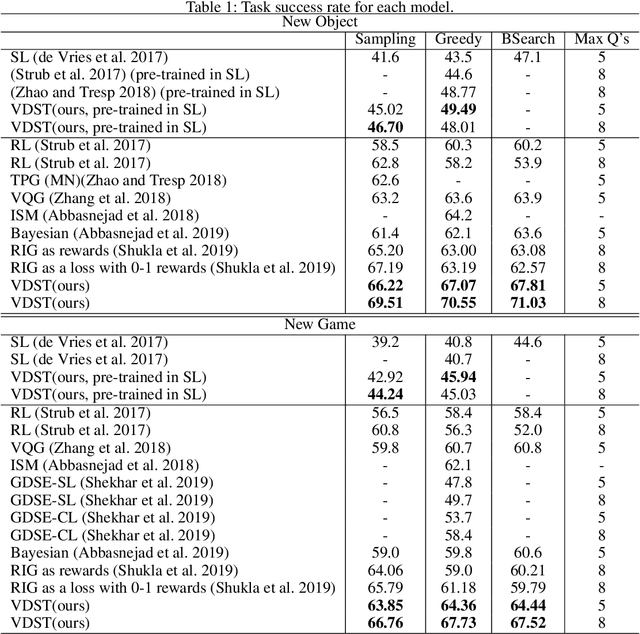
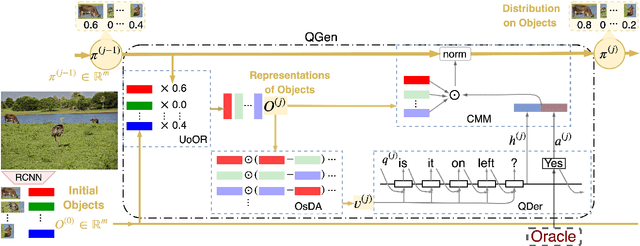
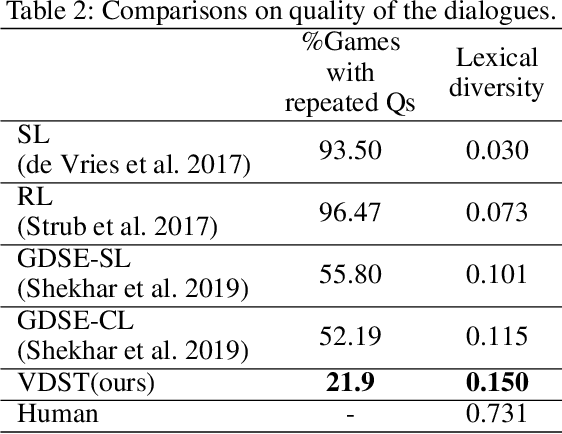
GuessWhat?! is a visual dialogue task between a guesser and an oracle. The guesser aims to locate an object supposed by the oracle oneself in an image by asking a sequence of Yes/No questions. Asking proper questions with the progress of dialogue is vital for achieving successful final guess. As a result, the progress of dialogue should be properly represented and tracked. Previous models for question generation pay less attention on the representation and tracking of dialogue states, and therefore are prone to asking low quality questions such as repeated questions. This paper proposes visual dialogue state tracking (VDST) based method for question generation. A visual dialogue state is defined as the distribution on objects in the image as well as representations of objects. Representations of objects are updated with the change of the distribution on objects. An object-difference based attention is used to decode new question. The distribution on objects is updated by comparing the question-answer pair and objects. Experimental results on GuessWhat?! dataset show that our model significantly outperforms existing methods and achieves new state-of-the-art performance. It is also noticeable that our model reduces the rate of repeated questions from more than 50% to 18.85% compared with previous state-of-the-art methods.