 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Label Dataset Distillation and Text Dataset Distillation
Paper and Code
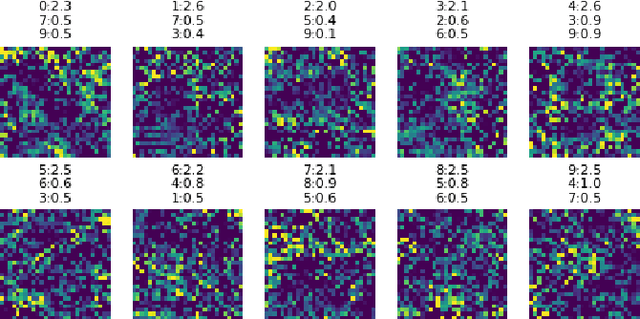

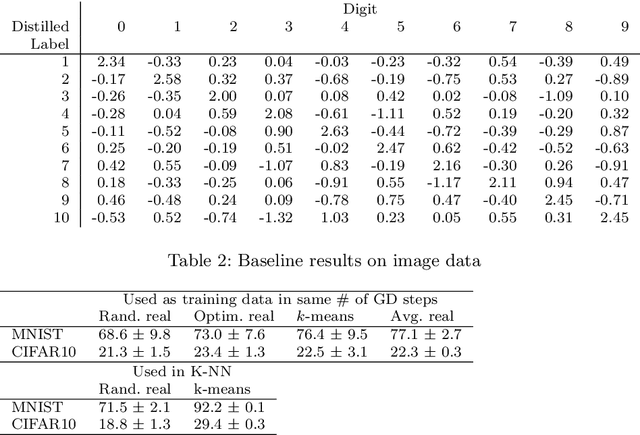
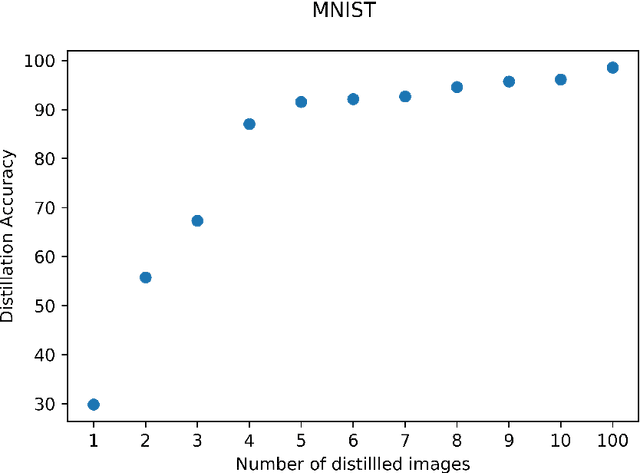
Dataset distillation is a method for reducing dataset sizes by learning a small number of synthetic samples containing all the information of a large dataset. This has several benefits like speeding up model training, reducing energy consumption, and reducing required storage space. Currently, each synthetic sample is assigned a single `hard' label, and also, dataset distillation can currently only be used with image data. We propose to simultaneously distill both images and their labels, thus assigning each synthetic sample a `soft' label (a distribution of labels). Our algorithm increases accuracy by 2-4% over the original algorithm for several image classification tasks. Using `soft' labels also enables distilled datasets to consist of fewer samples than there are classes as each sample can encode information for multiple classes. For example, training a LeNet model with 10 distilled images (one per class) results in over 96% accuracy on MNIST, and almost 92% accuracy when trained on just 5 distilled images. We also extend the dataset distillation algorithm to distill sequential datasets including texts. We demonstrate that text distillation outperforms other methods across multiple datasets. For example, models attain almost their original accuracy on the IMDB sentiment analysis task using just 20 distilled sentences.