 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Crossmodal Voice Conversion
Apr 09, 2019
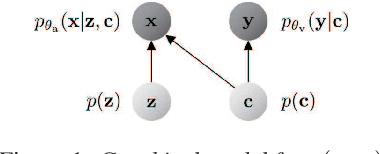
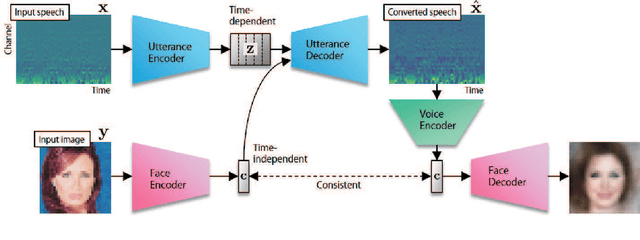
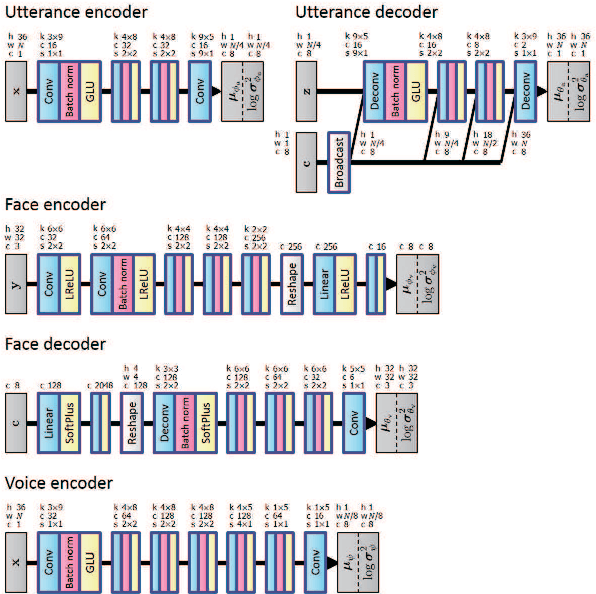
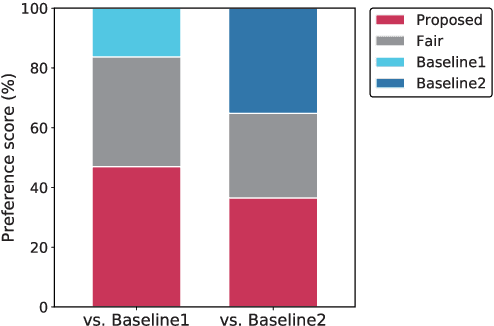
Humans are able to imagine a person's voice from the person's appearance and imagine the person's appearance from his/her voice. In this paper, we make the first attempt to develop a method that can convert speech into a voice that matches an input face image and generate a face image that matches the voice of the input speech by leveraging the correlation between faces and voices. We propose a model, consisting of a speech converter, a face encoder/decoder and a voice encoder. We use the latent code of an input face image encoded by the face encoder as the auxiliary input into the speech converter and train the speech converter so that the original latent code can be recovered from the generated speech by the voice encoder. We also train the face decoder along with the face encoder to ensure that the latent code will contain sufficient information to reconstruct the input face image. We confirmed experimentally that a speech converter trained in this way was able to convert input speech into a voice that matched an input face image and that the voice encoder and face decoder can be used to generate a face image that matches the voice of the input speech.
A Cyclically-Trained Adversarial Network for Invariant Representation Learning
Jun 21, 2019
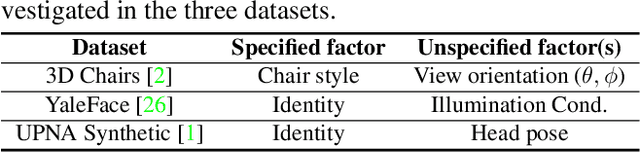
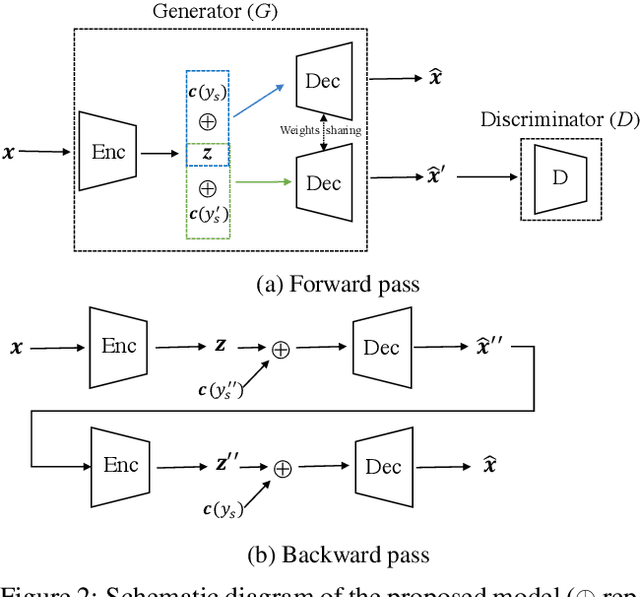
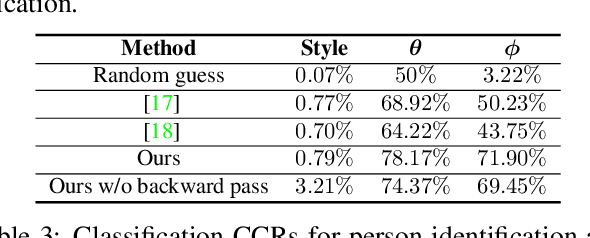
We propose a cyclically-trained adversarial network to learn mappings from image space to a latent representation space and back such that the latent representation is invariant to a specified factor of variation (e.g., identity). The learned mappings also assure that the synthesized image is not only realistic, but has the same values for unspecified factors (e.g., pose and illumination) as the original image and a desired value of the specified factor. We encourage invariance to a specified factor, by applying adversarial training using a variational autoencoder in the image space as opposed to the latent space. We strengthen this invariance by introducing a cyclic training process (forward and backward pass). We also propose a new method to evaluate conditional generative networks. It compares how well different factors of variation can be predicted from the synthesized, as opposed to real, images. We demonstrate the effectiveness of our approach on factors such as identity, pose, illumination or style on three datasets and compare it with state-of-the-art methods. Our network produces good quality synthetic images and, interestingly, can be used to perform face morphing in latent space.
Long Range 3D with Quadocular Thermal (LWIR) Camera
Nov 20, 2019
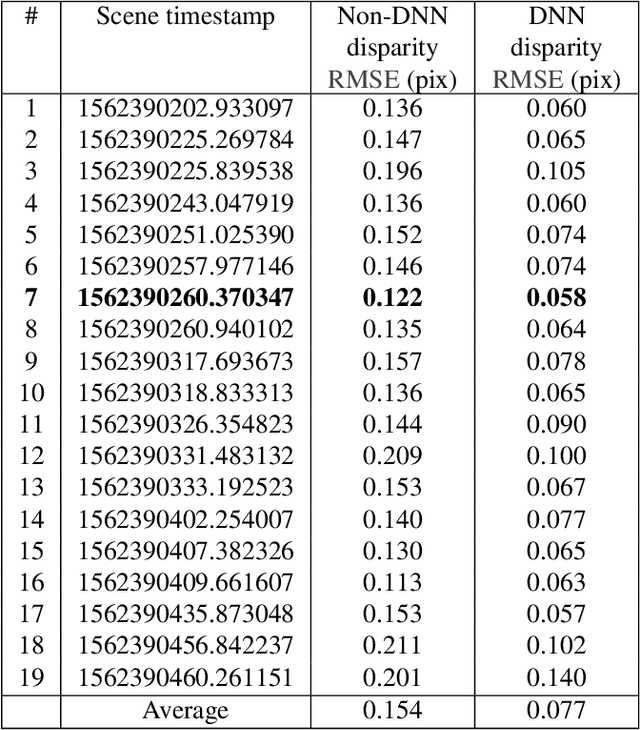


Long Wave Infrared (LWIR) cameras provide images regardles of the ambient illumination, they tolerate fog and are not blinded by the incoming car headlights. These features make LWIR cameras attractive for autonomous navigation, security and military applications. Thermal images can be used similarly to the visible range ones, including 3D scene reconstruction with two or more such cameras mounted on a rigid frame. There are two additional challenges for this spectral range: lower image resolution and lower contrast of the textures. In this work, we demonstrate quadocular LWIR camera setup, calibration, image capturing and processing that result in long range 3D perception with 0.077 pix disparity error over 90% of the depth map. With low resolution (160 x 120) LWIR sensors we achieved 10% range accuracy at 28 m with 56 degrees horizontal field of view (HFoV) and 150 mm baseline. Scaled to the now-standard 640 x 512 resolution and 200 mm baseline suitable for head-mounted application the result would be 10% accuracy at 130 m.
Explanation by Progressive Exaggeration
Nov 01, 2019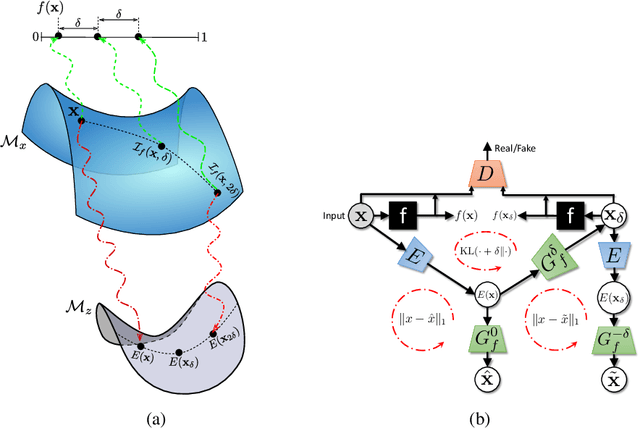

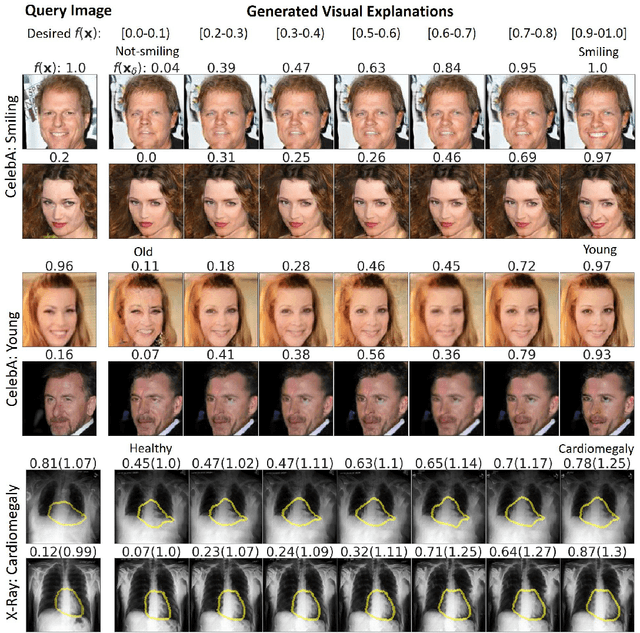

As machine learning methods see greater adoption and implementation in high stakes applications such as medical image diagnosis, the need for model interpretability and explanation has become more critical. Classical approaches that assess feature importance (\eg saliency maps) do not explain how and why a particular region of an image is relevant to the prediction. We propose a method that explains the outcome of a classification black-box by gradually exaggerating the semantic effect of a given class. Given a query input to a classifier, our method produces a progressive set of plausible variations of that query, which gradually changes the posterior probability from its original class to its negation. These counter-factually generated samples preserve features unrelated to the classification decision, such that a user can employ our method as a "tuning knob" to traverse a data manifold while crossing the decision boundary. Our method is model agnostic and only requires the output value and gradient of the predictor with respect to its input.
Understanding and Improving Information Transfer in Multi-Task Learning
May 02, 2020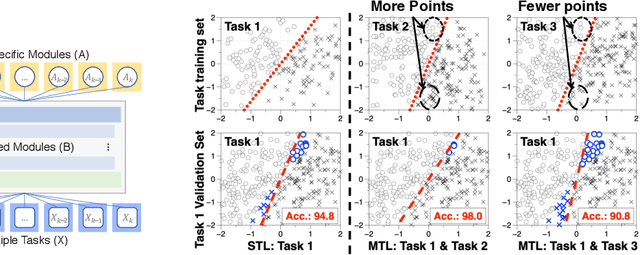

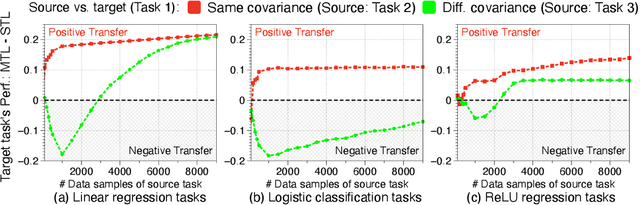
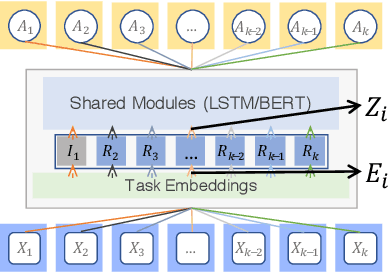
We investigate multi-task learning approaches that use a shared feature representation for all tasks. To better understand the transfer of task information, we study an architecture with a shared module for all tasks and a separate output module for each task. We study the theory of this setting on linear and ReLU-activated models. Our key observation is that whether or not tasks' data are well-aligned can significantly affect the performance of multi-task learning. We show that misalignment between task data can cause negative transfer (or hurt performance) and provide sufficient conditions for positive transfer. Inspired by the theoretical insights, we show that aligning tasks' embedding layers leads to performance gains for multi-task training and transfer learning on the GLUE benchmark and sentiment analysis tasks; for example, we obtain a 2.35% GLUE score average improvement on 5 GLUE tasks over BERT-LARGE using our alignment method. We also design an SVD-based task reweighting scheme and show that it improves the robustness of multi-task training on a multi-label image dataset.
Force-Ultrasound Fusion: Bringing Spine Robotic-US to the Next "Level"
Feb 26, 2020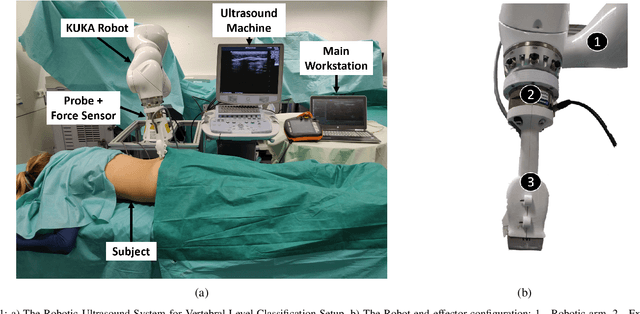
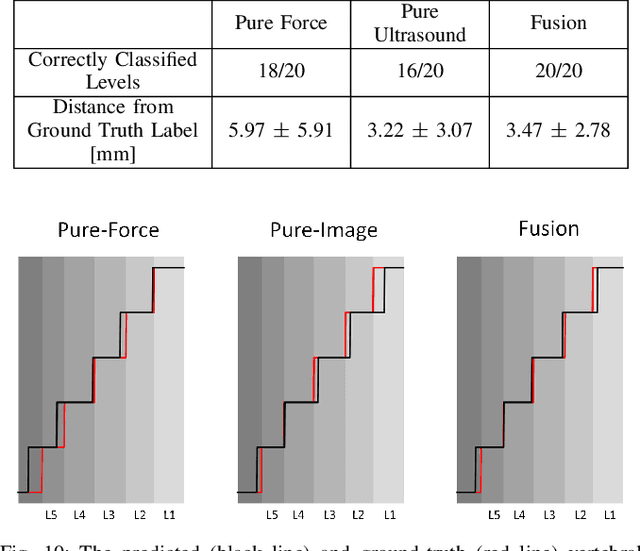
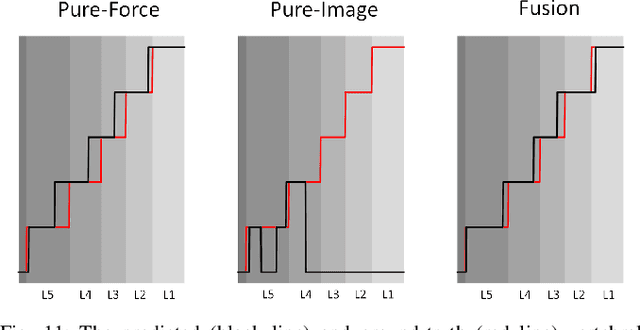
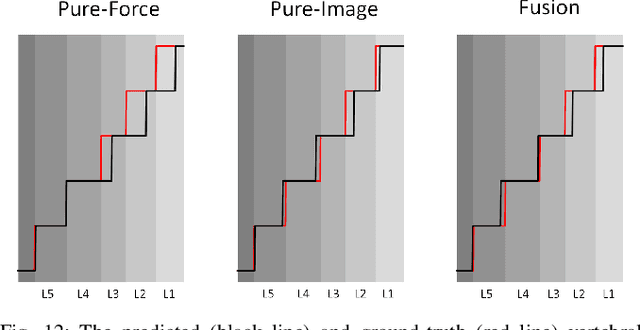
Spine injections are commonly performed in several clinical procedures. The localization of the target vertebral level (i.e. the position of a vertebra in a spine) is typically done by back palpation or under X-ray guidance, yielding either higher chances of procedure failure or exposure to ionizing radiation. Preliminary studies have been conducted in the literature, suggesting that ultrasound imaging may be a precise and safe alternative to X-ray for spine level detection. However, ultrasound data are noisy and complicated to interpret. In this study, a robotic-ultrasound approach for automatic vertebral level detection is introduced. The method relies on the fusion of ultrasound and force data, thus providing both "tactile" and visual feedback during the procedure, which results in higher performances in presence of data corruption. A robotic arm automatically scans the volunteer's back along the spine by using force-ultrasound data to locate vertebral levels. The occurrences of vertebral levels are visible on the force trace as peaks, which are enhanced by properly controlling the force applied by the robot on the patient back. Ultrasound data are processed with a Deep Learning method to extract a 1D signal modelling the probabilities of having a vertebra at each location along the spine. Processed force and ultrasound data are fused using a 1D Convolutional Network to compute the location of the vertebral levels. The method is compared to pure image and pure force-based methods for vertebral level counting, showing improved performance. In particular, the fusion method is able to correctly classify 100% of the vertebral levels in the test set, while pure image and pure force-based method could only classify 80% and 90% vertebrae, respectively. The potential of the proposed method is evaluated in an exemplary simulated clinical application.
Kernelized information bottleneck leads to biologically plausible 3-factor Hebbian learning in deep networks
Jun 12, 2020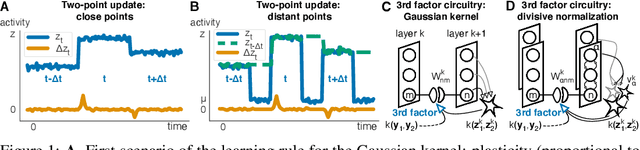
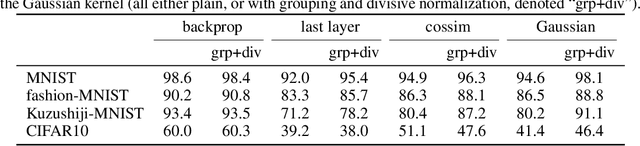
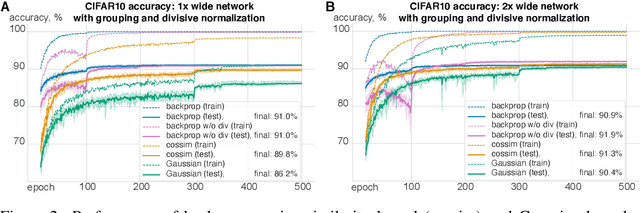

The state-of-the art machine learning approach to training deep neural networks, backpropagation, is implausible for real neural networks: neurons need to know their outgoing weights; training alternates between a forward pass (computation) and a backward pass (learning); and the algorithm needs a large amount of labeled data. Biologically plausible approximations to backpropagation, such as feedback alignment, solve the weight transport problem, but not the other two. Thus, fully biologically plausible learning rules have so far remained elusive. Here we present a family of learning rules that does not suffer from any of these problems. It is motivated by the information bottleneck principle (extended with kernel methods), in which networks learn to squeeze as much information as possible out of the input without sacrificing prediction of the output. The resulting rules have a 3-factor Hebbian structure: they require pre- and post-synaptic firing rates and a global error signal - the third factor - that can be supplied by a neuromodulator. Moreover, they do not require precise labels; instead, they rely on the similarity between the desired outputs. They thus solve all three implausibility issues of backpropagation. Moreover, to obtain good performance on hard problems and retain biologically plausible learning rules, our rules need divisive normalization - a known feature of biological networks. Finally, simulations show that our rule performs nearly as well as backpropagation on image classification tasks.
Study on performance improvement of oil paint image filter algorithm using parallel pattern library
Mar 19, 2014This paper gives a detailed study on the performance of oil paint image filter algorithm with various parameters applied on an image of RGB model. Oil Paint image processing, being very performance hungry, current research tries to find improvement using parallel pattern library. With increasing kernel-size, the processing time of oil paint image filter algorithm increases exponentially.
Discrete Laplace Operator Estimation for Dynamic 3D Reconstruction
Aug 29, 2019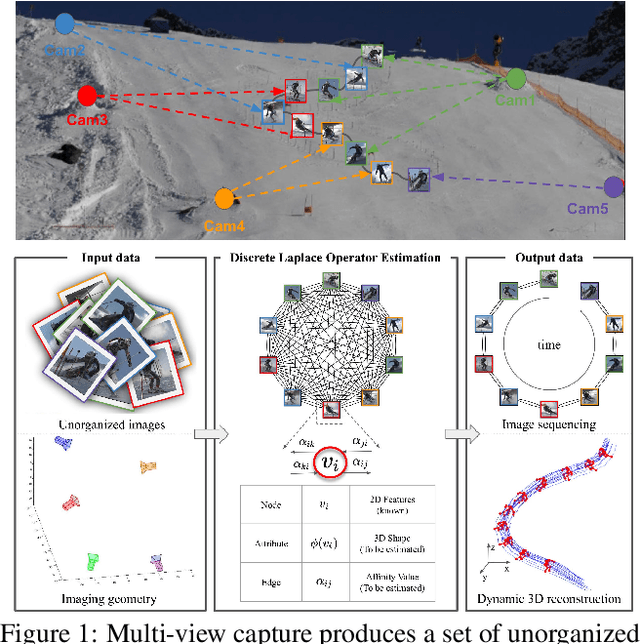
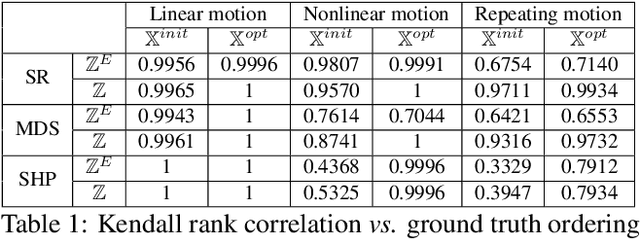
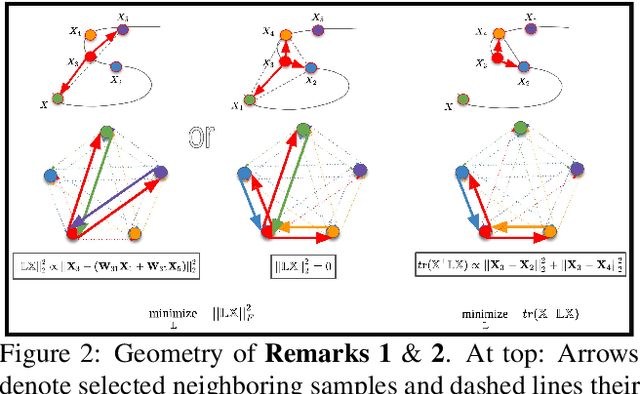
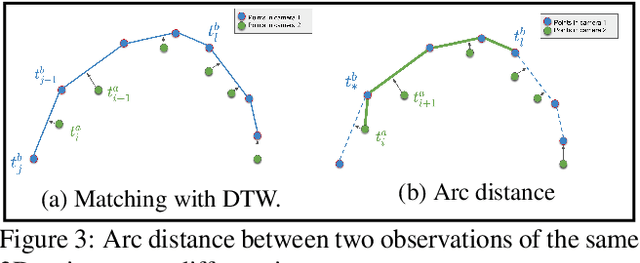
We present a general paradigm for dynamic 3D reconstruction from multiple independent and uncontrolled image sources having arbitrary temporal sampling density and distribution. Our graph-theoretic formulation models the Spatio-temporal relationships among our observations in terms of the joint estimation of their 3D geometry and its discrete Laplace operator. Towards this end, we define a tri-convex optimization framework that leverages the geometric properties and dependencies found among a Euclideanshape-space and the discrete Laplace operator describing its local and global topology. We present a reconstructability analysis, experiments on motion capture data and multi-view image datasets, as well as explore applications to geometry-based event segmentation and data association.
Classification Representations Can be Reused for Downstream Generations
Apr 16, 2020
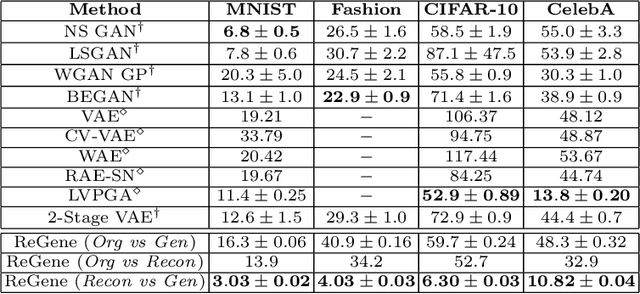
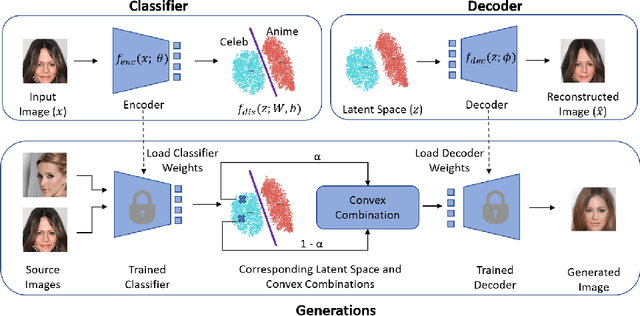

Contrary to the convention of using supervision for class-conditioned $\it{generative}$ $\it{modeling}$, this work explores and demonstrates the feasibility of a learned supervised representation space trained on a discriminative classifier for the $\it{downstream}$ task of sample generation. Unlike generative modeling approaches that aim to $\it{model}$ the manifold distribution, we directly $\it{represent}$ the given data manifold in the classification space and leverage properties of latent space representations to generate new representations that are guaranteed to be in the same class. Interestingly, such representations allow for controlled sample generations for any given class from existing samples and do not require enforcing prior distribution. We show that these latent space representations can be smartly manipulated (using convex combinations of $n$ samples, $n\geq2$) to yield meaningful sample generations. Experiments on image datasets of varying resolutions demonstrate that downstream generations have higher classification accuracy than existing conditional generative models while being competitive in terms of FID.