 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Road Mapping in Low Data Environments with OpenStreetMap
Jun 14, 2020
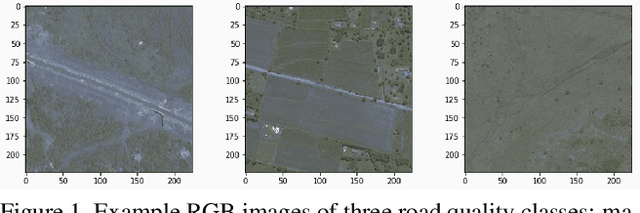
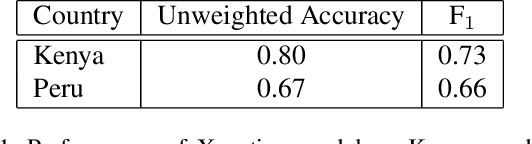
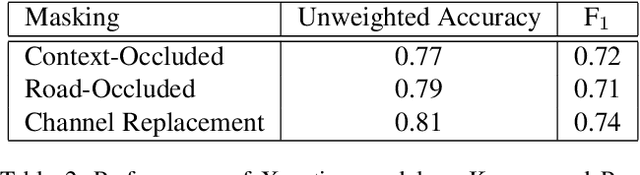
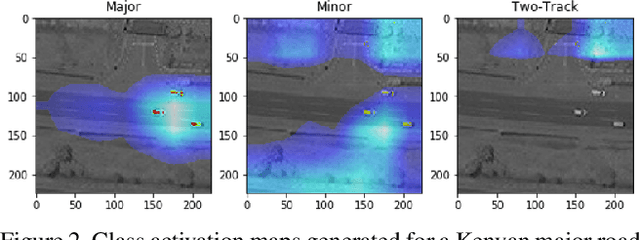
Roads are among the most essential components of any country's infrastructure. By facilitating the movement and exchange of people, ideas, and goods, they support economic and cultural activity both within and across local and international borders. A comprehensive, up-to-date mapping of the geographical distribution of roads and their quality thus has the potential to act as an indicator for broader economic development. Such an indicator has a variety of high-impact applications, particularly in the planning of rural development projects where up-to-date infrastructure information is not available. This work investigates the viability of high resolution satellite imagery and crowd-sourced resources like OpenStreetMap in the construction of such a mapping. We experiment with state-of-the-art deep learning methods to explore the utility of OpenStreetMap data in road classification and segmentation tasks. We also compare the performance of models in different mask occlusion scenarios as well as out-of-country domains. Our comparison raises important pitfalls to consider in image-based infrastructure classification tasks, and shows the need for local training data specific to regions of interest for reliable performance.
Geodesic-HOF: 3D Reconstruction Without Cutting Corners
Jun 14, 2020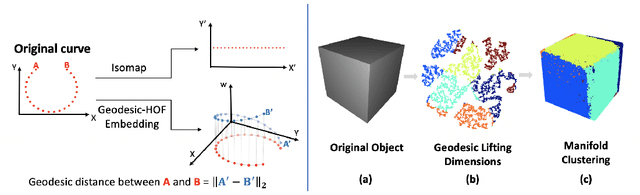
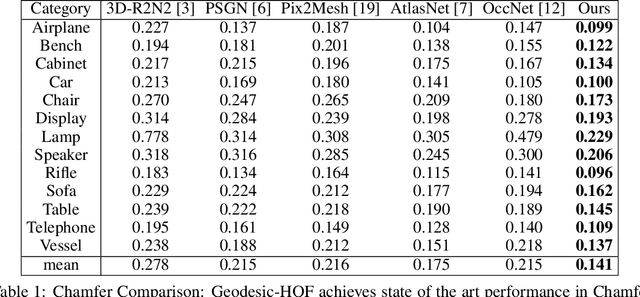
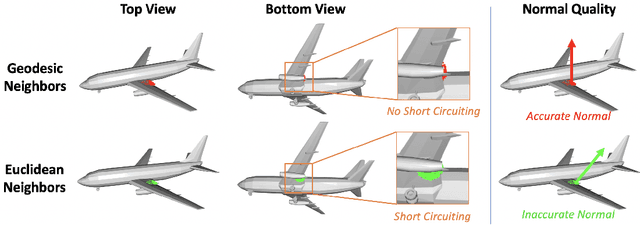
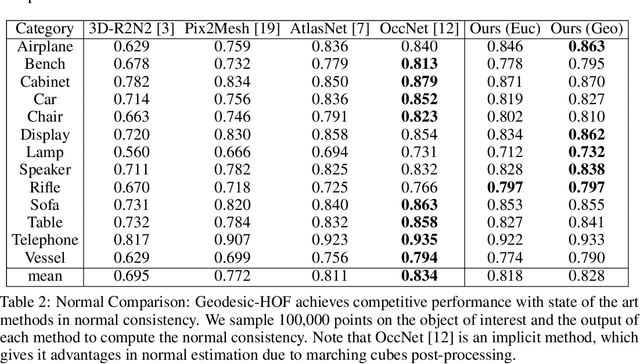
Single-view 3D object reconstruction is a challenging fundamental problem in computer vision, largely due to the morphological diversity of objects in the natural world. In particular, high curvature regions are not always captured effectively by methods trained using only set-based loss functions, resulting in reconstructions short-circuiting the surface or cutting corners. In particular, high curvature regions are not always captured effectively by methods trained using only set-based loss functions, resulting in reconstructions short-circuiting the surface or cutting corners. To address this issue, we propose learning an image-conditioned mapping function from a canonical sampling domain to a high dimensional space where the Euclidean distance is equal to the geodesic distance on the object. The first three dimensions of a mapped sample correspond to its 3D coordinates. The additional lifted components contain information about the underlying geodesic structure. Our results show that taking advantage of these learned lifted coordinates yields better performance for estimating surface normals and generating surfaces than using point cloud reconstructions alone. Further, we find that this learned geodesic embedding space provides useful information for applications such as unsupervised object decomposition.
Small-brain neural networks rapidly solve inverse problems with vortex Fourier encoders
May 15, 2020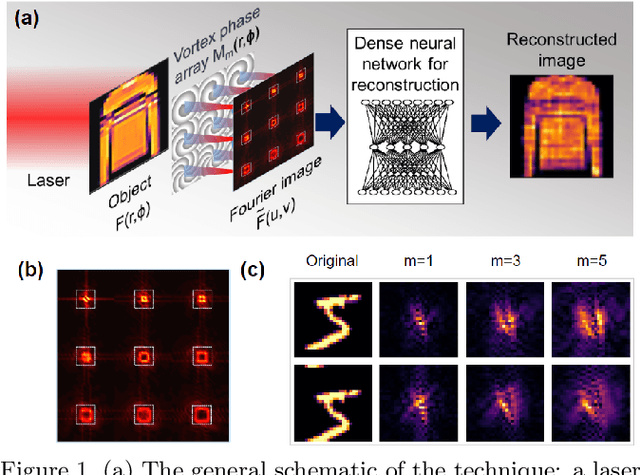

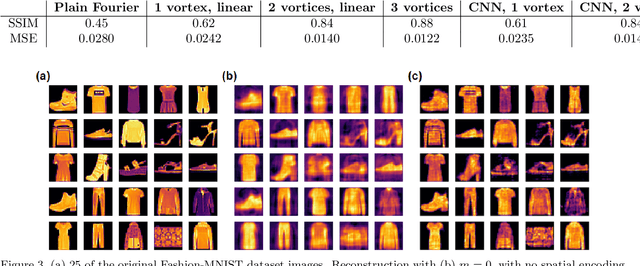
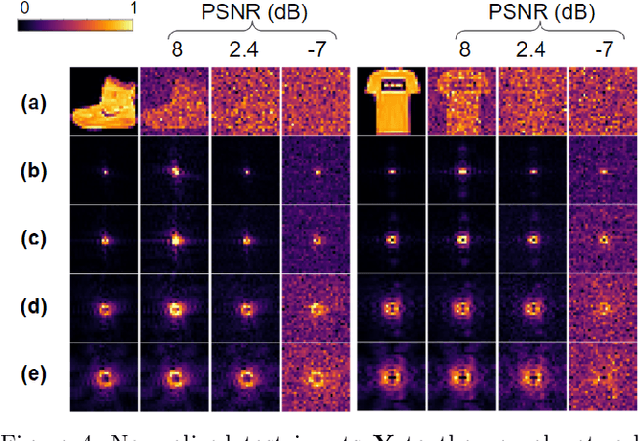
We introduce a vortex phase transform with a lenslet-array to accompany shallow, dense, ``small-brain'' neural networks for high-speed and low-light imaging. Our single-shot ptychographic approach exploits the coherent diffraction, compact representation, and edge enhancement of Fourier-tranformed spiral-phase gradients. With vortex spatial encoding, a small brain is trained to deconvolve images at rates 5-20 times faster than those achieved with random encoding schemes, where greater advantages are gained in the presence of noise. Once trained, the small brain reconstructs an object from intensity-only data, solving an inverse mapping without performing iterations on each image and without deep-learning schemes. With this hybrid, optical-digital, vortex Fourier encoded, small-brain scheme, we reconstruct MNIST Fashion objects illuminated with low-light flux (5 nJ/cm$^2$) at a rate of several thousand frames per second on a 15 W central processing unit, two orders of magnitude faster than convolutional neural networks.
Contact Area Detector using Cross View Projection Consistency for COVID-19 Projects
Aug 18, 2020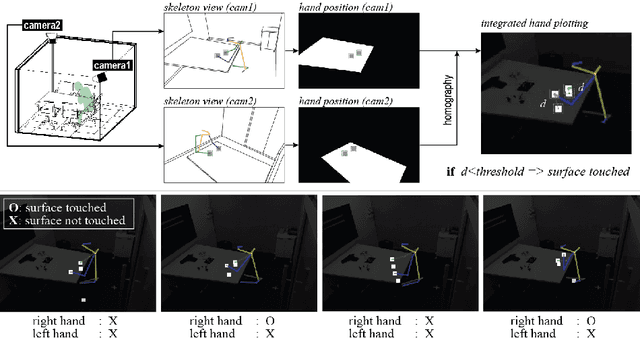

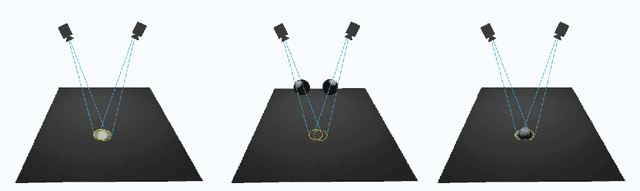
The ability to determine what parts of objects and surfaces people touch as they go about their daily lives would be useful in understanding how the COVID-19 virus spreads. To determine whether a person has touched an object or surface using visual data, images, or videos, is a hard problem. Computer vision 3D reconstruction approaches project objects and the human body from the 2D image domain to 3D and perform 3D space intersection directly. However, this solution would not meet the accuracy requirement in applications due to projection error. Another standard approach is to train a neural network to infer touch actions from the collected visual data. This strategy would require significant amounts of training data to generalize over scale and viewpoint variations. A different approach to this problem is to identify whether a person has touched a defined object. In this work, we show that the solution to this problem can be straightforward. Specifically, we show that the contact between an object and a static surface can be identified by projecting the object onto the static surface through two different viewpoints and analyzing their 2D intersection. The object contacts the surface when the projected points are close to each other; we call this cross view projection consistency. Instead of doing 3D scene reconstruction or transfer learning from deep networks, a mapping from the surface in the two camera views to the surface space is the only requirement. For planar space, this mapping is the Homography transformation. This simple method can be easily adapted to real-life applications. In this paper, we apply our method to do office occupancy detection for studying the COVID-19 transmission pattern from an office desk in a meeting room using the contact information.
Deep Hashing Learning for Visual and Semantic Retrieval of Remote Sensing Images
Sep 10, 2019
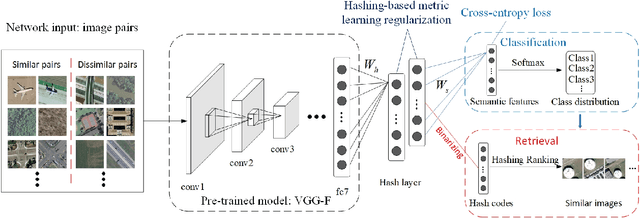


Driven by the urgent demand for managing remote sensing big data, large-scale remote sensing image retrieval (RSIR) attracts increasing attention in the remote sensing field. In general, existing retrieval methods can be regarded as visual-based retrieval approaches which search and return a set of similar images from a database to a given query image. Although retrieval methods have achieved great success, there is still a question that needs to be responded to: Can we obtain the accurate semantic labels of the returned similar images to further help analyzing and processing imagery? Inspired by the above question, in this paper, we redefine the image retrieval problem as visual and semantic retrieval of images. Specifically, we propose a novel deep hashing convolutional neural network (DHCNN) to simultaneously retrieve the similar images and classify their semantic labels in a unified framework. In more detail, a convolutional neural network (CNN) is used to extract high-dimensional deep features. Then, a hash layer is perfectly inserted into the network to transfer the deep features into compact hash codes. In addition, a fully connected layer with a softmax function is performed on hash layer to generate class distribution. Finally, a loss function is elaborately designed to simultaneously consider the label loss of each image and similarity loss of pairs of images. Experimental results on two remote sensing datasets demonstrate that the proposed method achieves the state-of-art retrieval and classification performance.
Patient-Specific Domain Adaptation for Fast Optical Flow Based on Teacher-Student Knowledge Transfer
Jul 09, 2020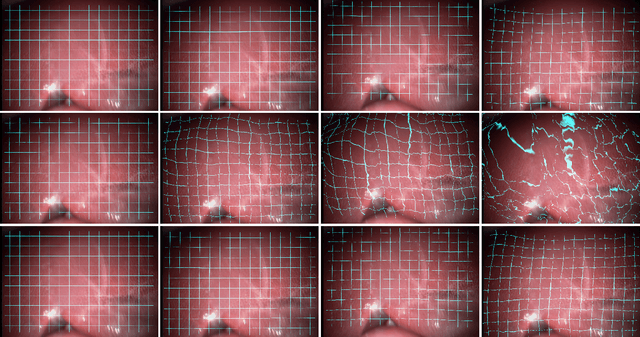

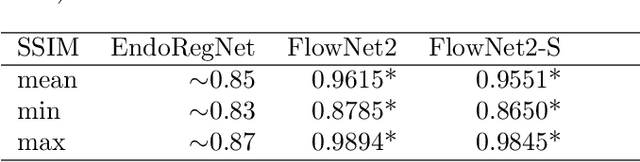
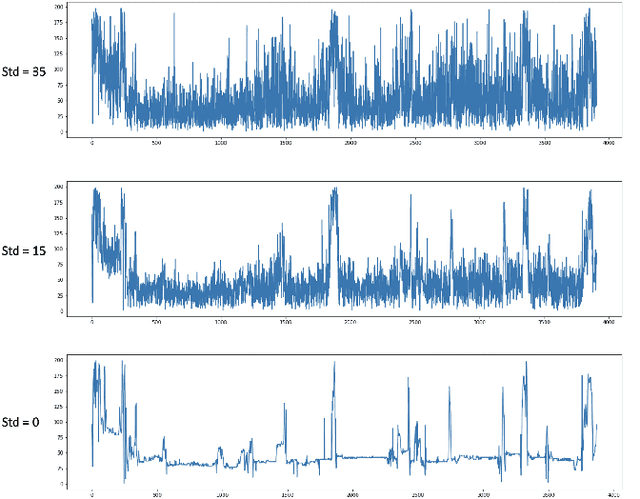
Fast motion feedback is crucial in computer-aided surgery (CAS) on moving tissue. Image-assistance in safety-critical vision applications requires a dense tracking of tissue motion. This can be done using optical flow (OF). Accurate motion predictions at high processing rates lead to higher patient safety. Current deep learning OF models show the common speed vs. accuracy trade-off. To achieve high accuracy at high processing rates, we propose patient-specific fine-tuning of a fast model. This minimizes the domain gap between training and application data, while reducing the target domain to the capability of the lower complex, fast model. We propose to obtain training sequences pre-operatively in the operation room. We handle missing ground truth, by employing teacher-student learning. Using flow estimations from teacher model FlowNet2 we specialize a fast student model FlowNet2S on the patient-specific domain. Evaluation is performed on sequences from the Hamlyn dataset. Our student model shows very good performance after fine-tuning. Tracking accuracy is comparable to the teacher model at a speed up of factor six. Fine-tuning can be performed within minutes, making it feasible for the operation room. Our method allows to use a real-time capable model that was previously not suited for this task. This method is laying the path for improved patient-specific motion estimation in CAS.
3D deformable registration of longitudinal abdominopelvic CT images using unsupervised deep learning
May 15, 2020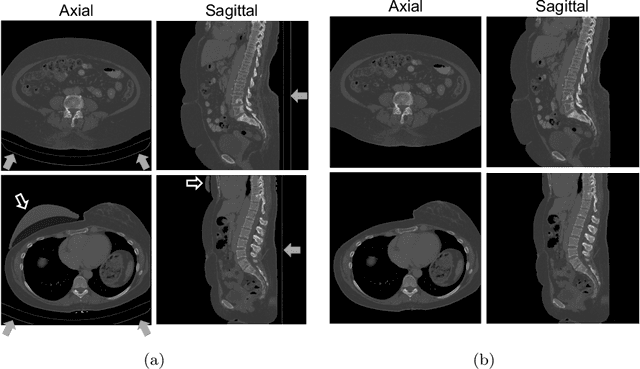
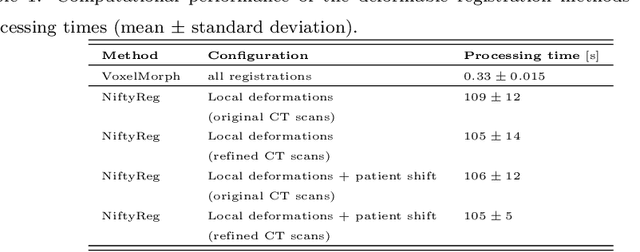
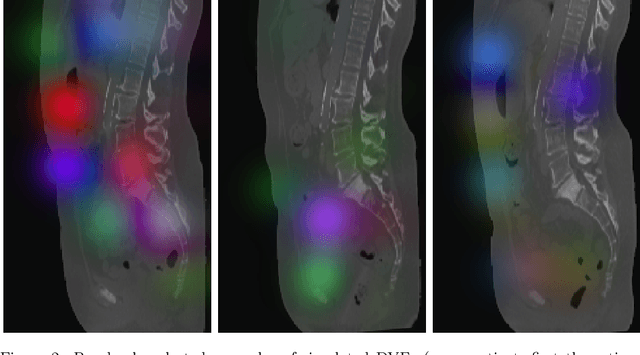
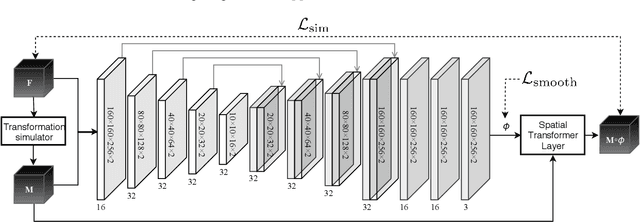
This study investigates the use of the unsupervised deep learning framework VoxelMorph for deformable registration of longitudinal abdominopelvic CT images acquired in patients with bone metastases from breast cancer. The CT images were refined prior to registration by automatically removing the CT table and all other extra-corporeal components. To improve the learning capabilities of VoxelMorph when only a limited amount of training data is available, a novel incremental training strategy is proposed based on simulated deformations of consecutive CT images. In a 4-fold cross-validation scheme, the incremental training strategy achieved significantly better registration performance compared to training on a single volume. Although our deformable image registration method did not outperform iterative registration using NiftyReg (considered as a benchmark) in terms of registration quality, the registrations were approximately 300 times faster. This study showed the feasibility of deep learning based deformable registration of longitudinal abdominopelvic CT images via a novel incremental training strategy based on simulated deformations.
Learning from Irregularly Sampled Data for Endomicroscopy Super-resolution: A Comparative Study of Sparse and Dense Approaches
Nov 29, 2019
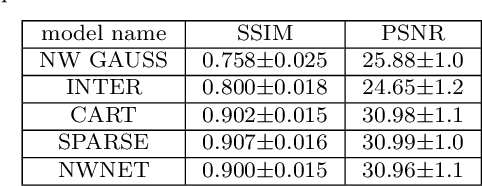
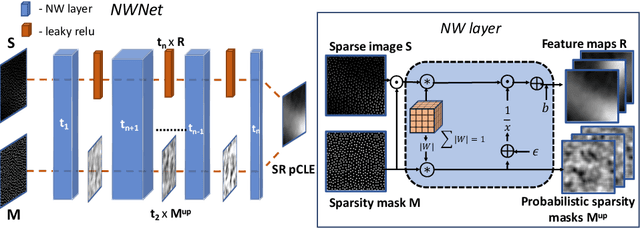
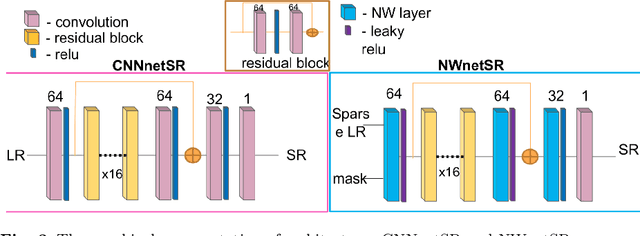
Purpose: Probe-based Confocal Laser Endomicroscopy (pCLE) enables performing an optical biopsy, providing real-time microscopic images, via a probe. pCLE probes consist of multiple optical fibres arranged in a bundle, which taken together generate signals in an irregularly sampled pattern. Current pCLE reconstruction is based on interpolating irregular signals onto an over-sampled Cartesian grid, using a naive linear interpolation. It was shown that Convolutional Neural Networks (CNNs) could improve pCLE image quality. Although classical CNNs were applied to pCLE, input data were limited to reconstructed images in contrast to irregular data produced by pCLE. Methods: We compare pCLE reconstruction and super-resolution (SR) methods taking irregularly sampled or reconstructed pCLE images as input. We also propose to embed a Nadaraya-Watson (NW) kernel regression into the CNN framework as a novel trainable CNN layer. Using the NW layer and exemplar-based super-resolution, we design an NWNetSR architecture that allows for reconstructing high-quality pCLE images directly from the irregularly sampled input data. We created synthetic sparse pCLE images to evaluate our methodology. Results: The results were validated through an image quality assessment based on a combination of the following metrics: Peak signal-to-noise ratio, the Structural Similarity Index. Conclusion: Both dense and sparse CNNs outperform the reconstruction method currently used in the clinic. The main contributions of our study are a comparison of sparse and dense approach in pCLE image reconstruction, implementing trainable generalised NW kernel regression, and adaptation of synthetic data for training pCLE SR.
Low Dose CT Denoising via Joint Bilateral Filtering and Intelligent Parameter Optimization
Jul 09, 2020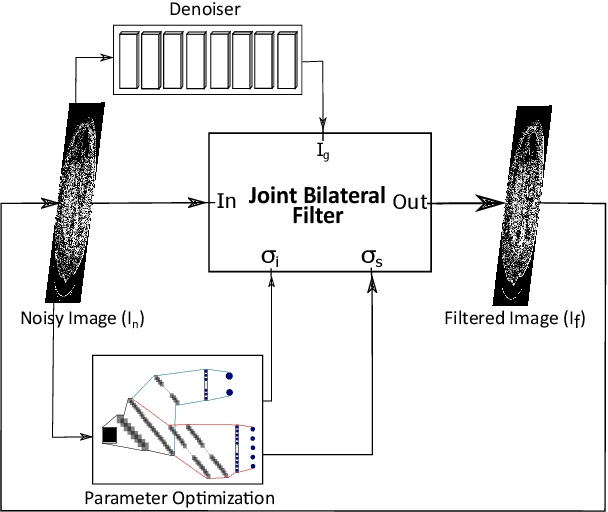
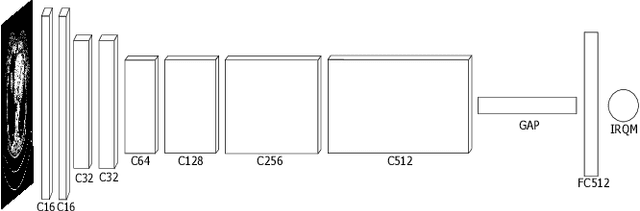
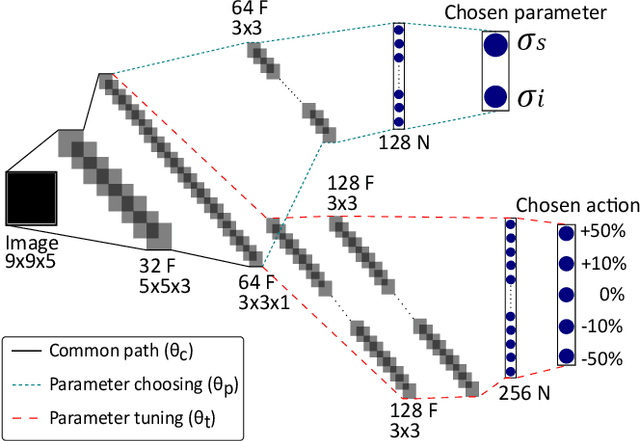
Denoising of clinical CT images is an active area for deep learning research. Current clinically approved methods use iterative reconstruction methods to reduce the noise in CT images. Iterative reconstruction techniques require multiple forward and backward projections, which are time-consuming and computationally expensive. Recently, deep learning methods have been successfully used to denoise CT images. However, conventional deep learning methods suffer from the 'black box' problem. They have low accountability, which is necessary for use in clinical imaging situations. In this paper, we use a Joint Bilateral Filter (JBF) to denoise our CT images. The guidance image of the JBF is estimated using a deep residual convolutional neural network (CNN). The range smoothing and spatial smoothing parameters of the JBF are tuned by a deep reinforcement learning task. Our actor first chooses a parameter, and subsequently chooses an action to tune the value of the parameter. A reward network is designed to direct the reinforcement learning task. Our denoising method demonstrates good denoising performance, while retaining structural information. Our method significantly outperforms state of the art deep neural networks. Moreover, our method has only two parameters, which makes it significantly more interpretable and reduces the 'black box' problem. We experimentally measure the impact of our intelligent parameter optimization and our reward network. Our studies show that our current setup yields the best results in terms of structural preservation.
JBFnet -- Low Dose CT Denoising by Trainable Joint Bilateral Filtering
Jul 09, 2020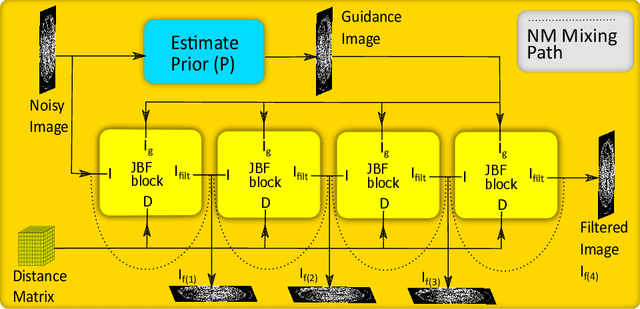
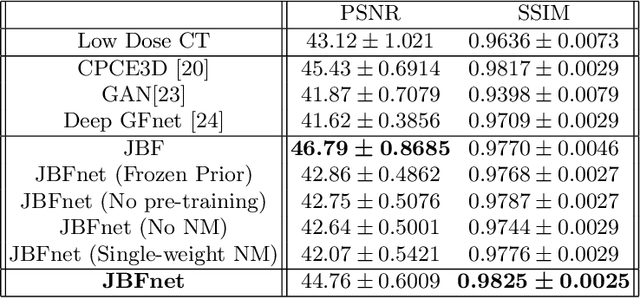
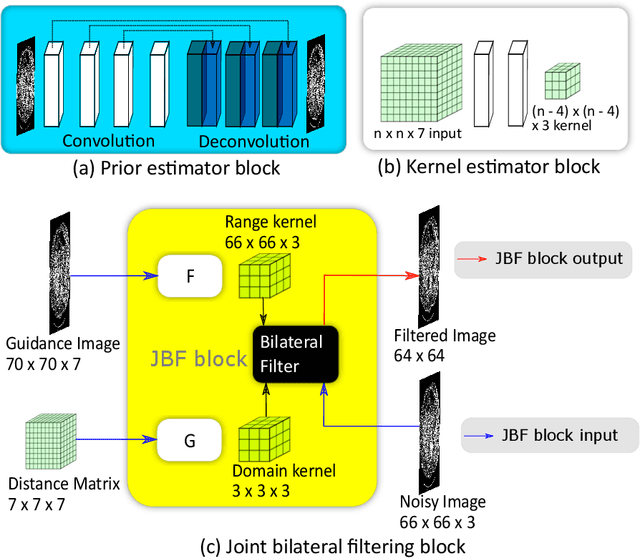
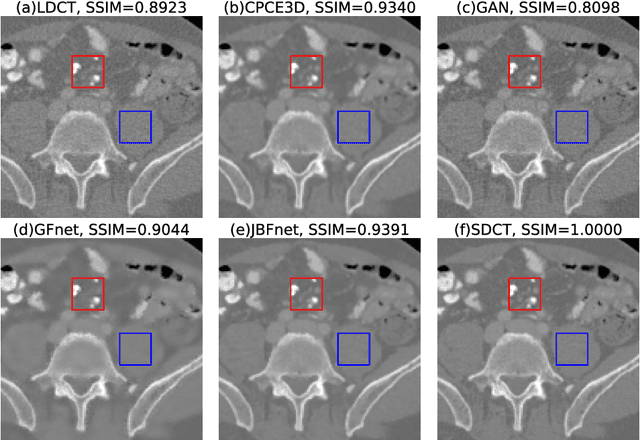
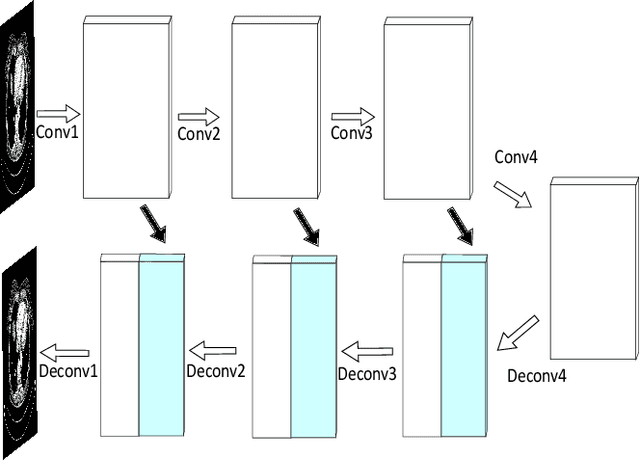
Deep neural networks have shown great success in low dose CT denoising. However, most of these deep neural networks have several hundred thousand trainable parameters. This, combined with the inherent non-linearity of the neural network, makes the deep neural network diffcult to understand with low accountability. In this study we introduce JBFnet, a neural network for low dose CT denoising. The architecture of JBFnet implements iterative bilateral filtering. The filter functions of the Joint Bilateral Filter (JBF) are learned via shallow convolutional networks. The guidance image is estimated by a deep neural network. JBFnet is split into four filtering blocks, each of which performs Joint Bilateral Filtering. Each JBF block consists of 112 trainable parameters, making the noise removal process comprehendable. The Noise Map (NM) is added after filtering to preserve high level features. We train JBFnet with the data from the body scans of 10 patients, and test it on the AAPM low dose CT Grand Challenge dataset. We compare JBFnet with state-of-the-art deep learning networks. JBFnet outperforms CPCE3D, GAN and deep GFnet on the test dataset in terms of noise removal while preserving structures. We conduct several ablation studies to test the performance of our network architecture and training method. Our current setup achieves the best performance, while still maintaining behavioural accountability.