 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reliability Does Matter: An End-to-End Weakly Supervised Semantic Segmentation Approach
Nov 19, 2019
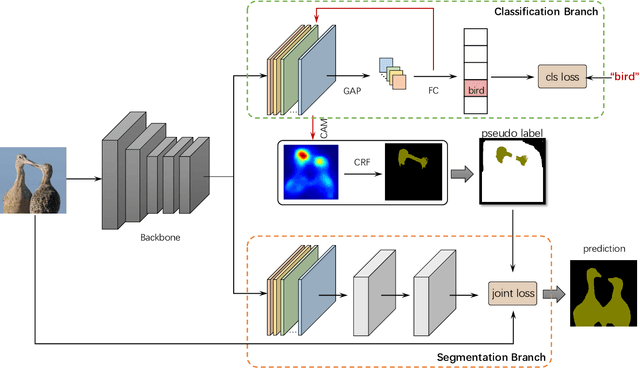

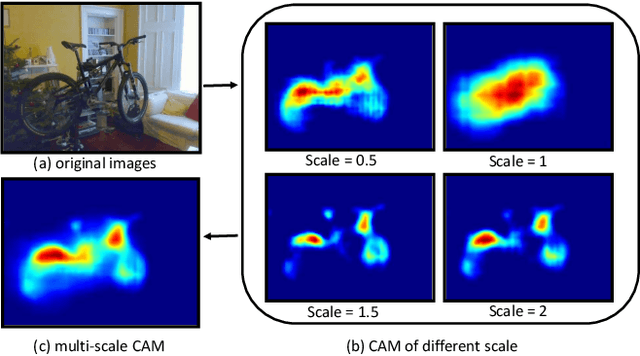
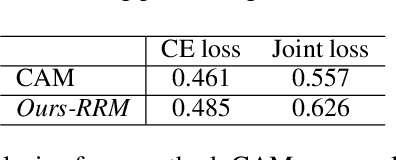
Weakly supervised semantic segmentation is a challenging task as it only takes image-level information as supervision for training but produces pixel-level predictions for testing. To address such a challenging task, most recent state-of-the-art approaches propose to adopt two-step solutions, \emph{i.e. } 1) learn to generate pseudo pixel-level masks, and 2) engage FCNs to train the semantic segmentation networks with the pseudo masks. However, the two-step solutions usually employ many bells and whistles in producing high-quality pseudo masks, making this kind of methods complicated and inelegant. In this work, we harness the image-level labels to produce reliable pixel-level annotations and design a fully end-to-end network to learn to predict segmentation maps. Concretely, we firstly leverage an image classification branch to generate class activation maps for the annotated categories, which are further pruned into confident yet tiny object/background regions. Such reliable regions are then directly served as ground-truth labels for the parallel segmentation branch, where a newly designed dense energy loss function is adopted for optimization. Despite its apparent simplicity, our one-step solution achieves competitive mIoU scores (\emph{val}: 62.6, \emph{test}: 62.9) on Pascal VOC compared with those two-step state-of-the-arts. By extending our one-step method to two-step, we get a new state-of-the-art performance on the Pascal VOC (\emph{val}: 66.3, \emph{test}: 66.5).
LANCE: Efficient Low-Precision Quantized Winograd Convolution for Neural Networks Based on Graphics Processing Units
Mar 20, 2020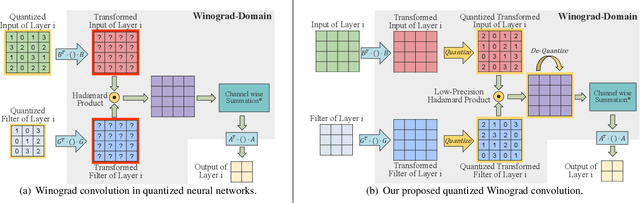
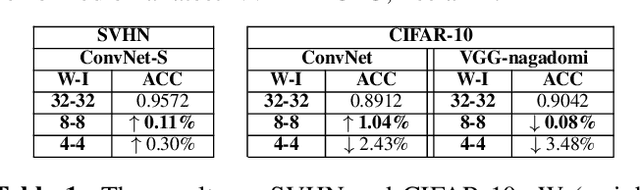
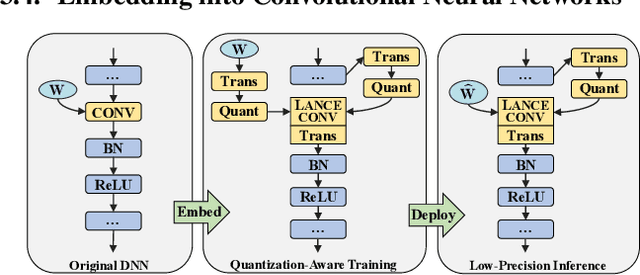

Accelerating deep convolutional neural networks has become an active topic and sparked an interest in academia and industry. In this paper, we propose an efficient low-precision quantized Winograd convolution algorithm, called LANCE, which combines the advantages of fast convolution and quantization techniques. By embedding linear quantization operations into the Winograd-domain, the fast convolution can be performed efficiently under low-precision computation on graphics processing units. We test neural network models with LANCE on representative image classification datasets, including SVHN, CIFAR, and ImageNet. The experimental results show that our 8-bit quantized Winograd convolution improves the performance by up to 2.40x over the full-precision convolution with trivial accuracy loss.
Artificial Intelligence to Assist in Exclusion of Coronary Atherosclerosis during CCTA Evaluation of Chest-Pain in the Emergency Department: Preparing an Application for Real-World Use
Aug 10, 2020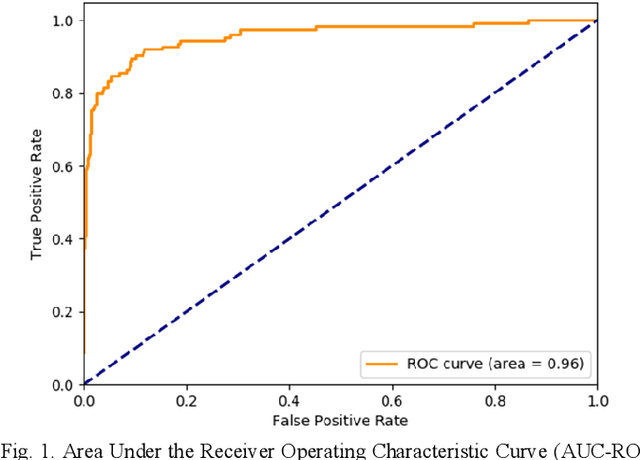
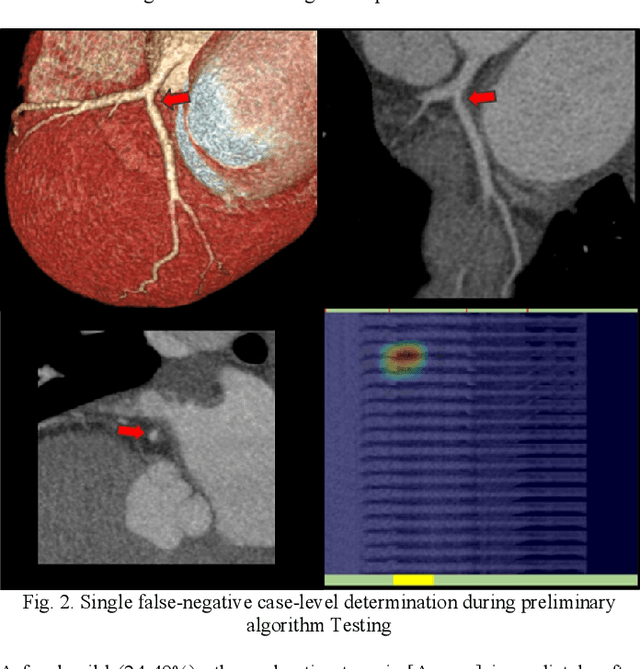
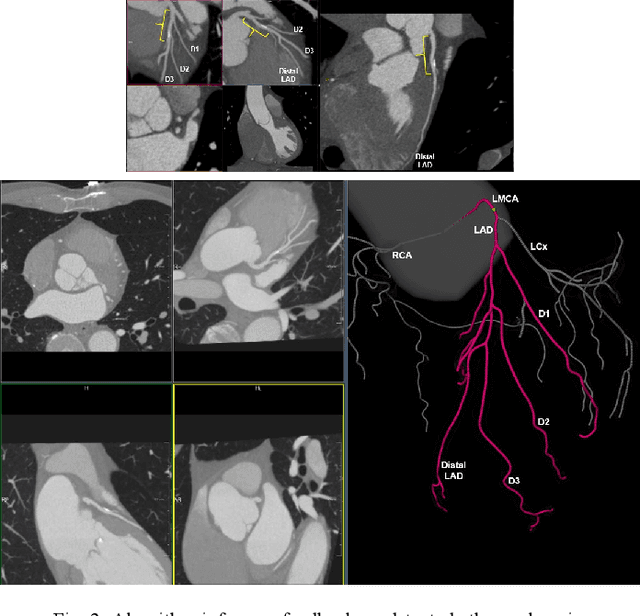
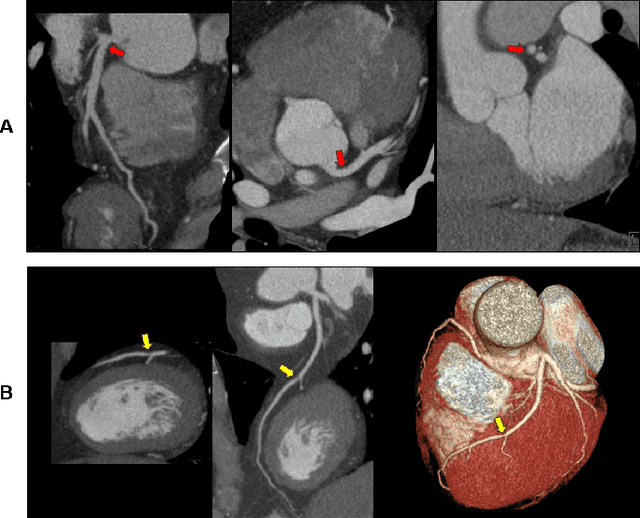
Coronary Computed Tomography Angiography (CCTA) evaluation of chest-pain patients in an Emergency Department (ED) is considered appropriate. While a negative CCTA interpretation supports direct patient discharge from an ED, labor-intensive analyses are required, with accuracy in jeopardy from distractions. We describe the development of an Artificial Intelligence (AI) algorithm and workflow for assisting interpreting physicians in CCTA screening for the absence of coronary atherosclerosis. The two-phase approach consisted of (1) Phase 1 - focused on the development and preliminary testing of an algorithm for vessel-centerline extraction classification in a balanced study population (n = 500 with 50% disease prevalence) derived by retrospective random case selection; and (2) Phase 2 - concerned with simulated-clinical Trialing of the developed algorithm on a per-case basis in a more real-world study population (n = 100 with 28% disease prevalence) from an ED chest-pain series. This allowed pre-deployment evaluation of the AI-based CCTA screening application which provides a vessel-by-vessel graphic display of algorithm inference results integrated into a clinically capable viewer. Algorithm performance evaluation used Area Under the Receiver-Operating-Characteristic Curve (AUC-ROC); confusion matrices reflected ground-truth vs AI determinations. The vessel-based algorithm demonstrated strong performance with AUC-ROC = 0.96. In both Phase 1 and Phase 2, independent of disease prevalence differences, negative predictive values at the case level were very high at 95%. The rate of completion of the algorithm workflow process (96% with inference results in 55-80 seconds) in Phase 2 depended on adequate image quality. There is potential for this AI application to assist in CCTA interpretation to help extricate atherosclerosis from chest-pain presentations.
Stochastic gradient descent with random learning rate
Apr 10, 2020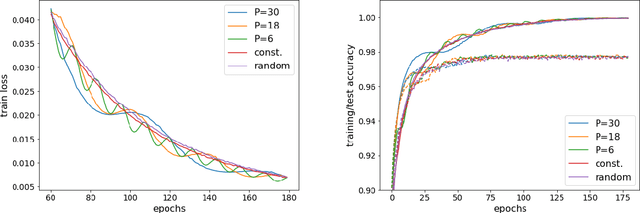
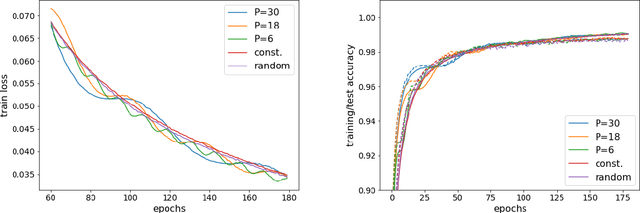
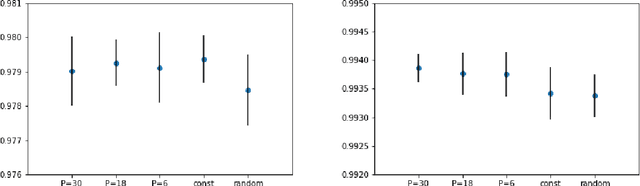
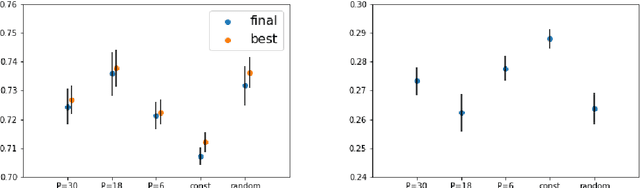
We propose to optimize neural networks with a uniformly-distributed random learning rate. The associated stochastic gradient descent algorithm can be approximated by continuous stochastic equations and analyzed with the Fokker-Planck formalism. In the small learning rate approximation, the training process is characterized by an effective temperature which depends on the average learning rate, the mini-batch size and the momentum of the optimization algorithm. By comparing the random learning rate protocol with cyclic and constant protocols, we suggest that the random choice is generically the best strategy in the small learning rate regime, yielding better regularization without extra computational cost. We provide supporting evidence through experiments on both shallow, fully-connected and deep, convolutional neural networks for image classification on the MNIST and CIFAR10 datasets.
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
Apr 20, 2020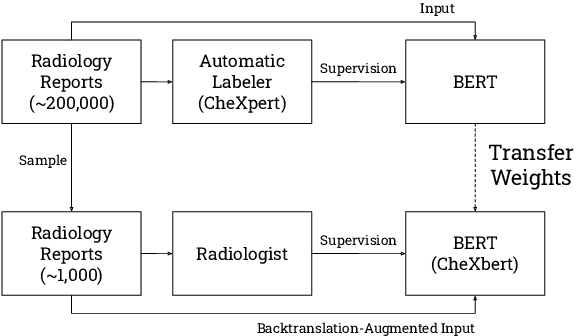
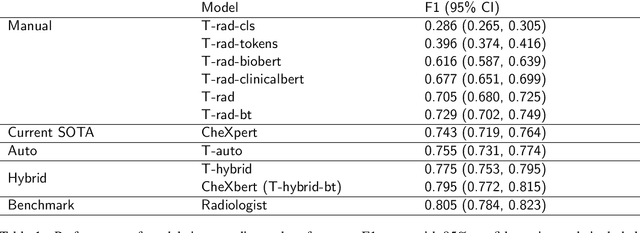
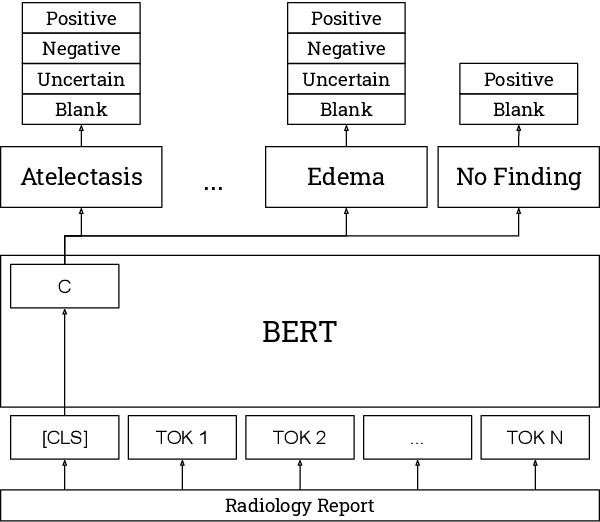
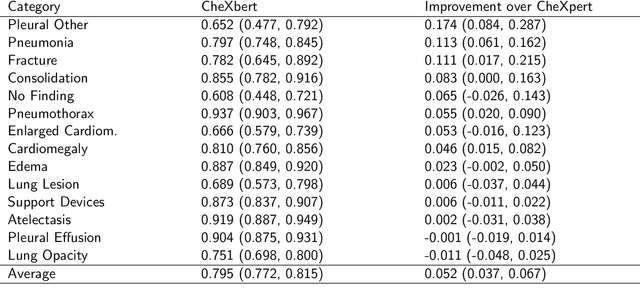
The extraction of labels from radiology text reports enables large-scale training of medical imaging models. Existing approaches to report labeling typically rely either on sophisticated feature engineering based on medical domain knowledge or manual annotations by experts. In this work, we investigate BERT-based approaches to medical image report labeling that exploit both the scale of available rule-based systems and the quality of expert annotations. We demonstrate superior performance of a BERT model first trained on annotations of a rule-based labeler and then finetuned on a small set of expert annotations augmented with automated backtranslation. We find that our final model, CheXbert, is able to outperform the previous best rules-based labeler with statistical significance, setting a new SOTA for report labeling on one of the largest datasets of chest x-rays.
Deep Nearest Neighbor Anomaly Detection
Feb 24, 2020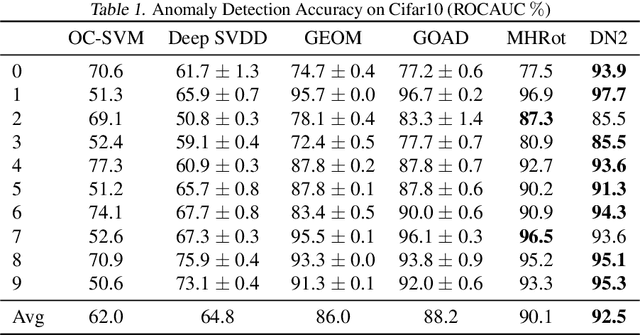
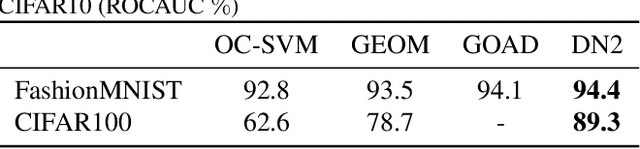
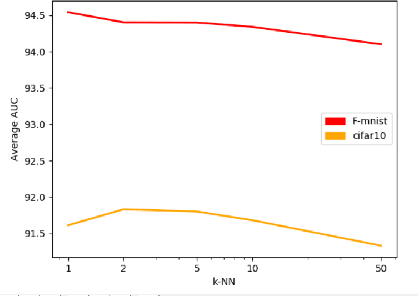
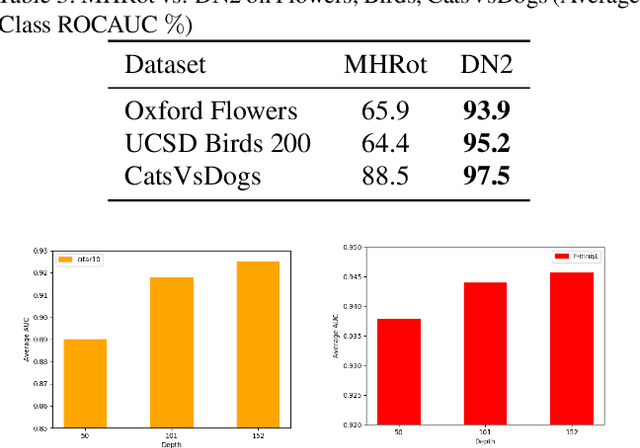
Nearest neighbors is a successful and long-standing technique for anomaly detection. Significant progress has been recently achieved by self-supervised deep methods (e.g. RotNet). Self-supervised features however typically under-perform Imagenet pre-trained features. In this work, we investigate whether the recent progress can indeed outperform nearest-neighbor methods operating on an Imagenet pretrained feature space. The simple nearest-neighbor based-approach is experimentally shown to outperform self-supervised methods in: accuracy, few shot generalization, training time and noise robustness while making fewer assumptions on image distributions.
Flexible Conditional Image Generation of Missing Data with Learned Mental Maps
Aug 29, 2019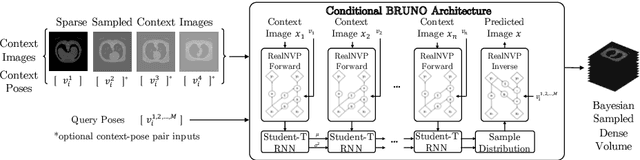
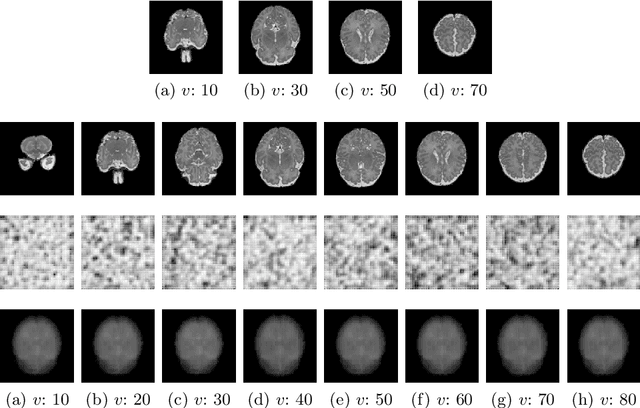
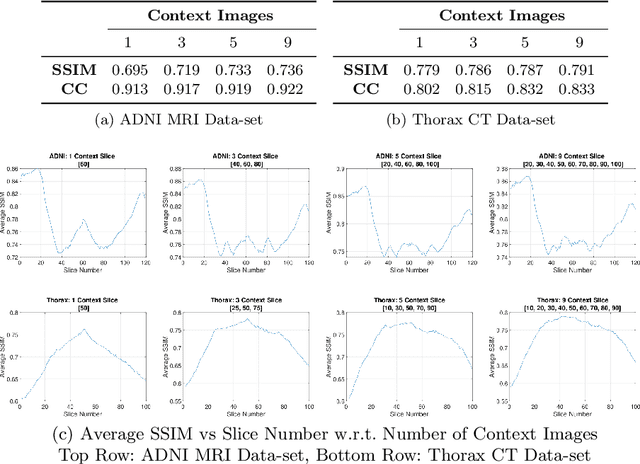
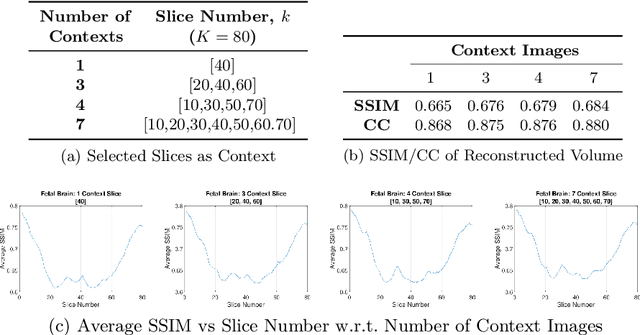
Real-world settings often do not allow acquisition of high-resolution volumetric images for accurate morphological assessment and diagnostic. In clinical practice it is frequently common to acquire only sparse data (e.g. individual slices) for initial diagnostic decision making. Thereby, physicians rely on their prior knowledge (or mental maps) of the human anatomy to extrapolate the underlying 3D information. Accurate mental maps require years of anatomy training, which in the first instance relies on normative learning, i.e. excluding pathology. In this paper, we leverage Bayesian Deep Learning and environment mapping to generate full volumetric anatomy representations from none to a small, sparse set of slices. We evaluate proof of concept implementations based on Generative Query Networks (GQN) and Conditional BRUNO using abdominal CT and brain MRI as well as in a clinical application involving sparse, motion-corrupted MR acquisition for fetal imaging. Our approach allows to reconstruct 3D volumes from 1 to 4 tomographic slices, with a SSIM of 0.7+ and cross-correlation of 0.8+ compared to the 3D ground truth.
Program synthesis performance constrained by non-linear spatial relations in Synthetic Visual Reasoning Test
Nov 18, 2019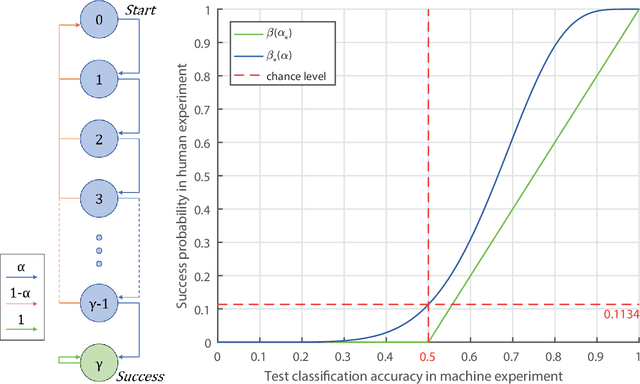

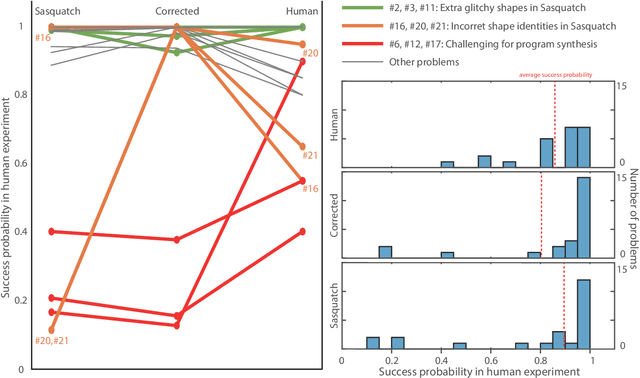

Despite remarkable advances in automated visual recognition by machines, some visual tasks remain challenging for machines. Fleuret et al. (2011) introduced the Synthetic Visual Reasoning Test (SVRT) to highlight this point, which required classification of images consisting of randomly generated shapes based on hidden abstract rules using only a few examples. Ellis et al. (2015) demonstrated that a program synthesis approach could solve some of the SVRT problems with unsupervised, few-shot learning, whereas they remained challenging for several convolutional neural networks trained with thousands of examples. Here we re-considered the human and machine experiments, because they followed different protocols and yielded different statistics. We thus proposed a quantitative reintepretation of the data between the protocols, so that we could make fair comparison between human and machine performance. We improved the program synthesis classifier by correcting the image parsings, and compared the results to the performance of other machine agents and human subjects. We grouped the SVRT problems into different types by the two aspects of the core characteristics for classification: shape specification and location relation. We found that the program synthesis classifier could not solve problems involving shape distances, because it relied on symbolic computation which scales poorly with input dimension and adding distances into such computation would increase the dimension combinatorially with the number of shapes in an image. Therefore, although the program synthesis classifier is capable of abstract reasoning, its performance is highly constrained by the accessible information in image parsings.
PCAMs: Weakly Supervised Semantic Segmentation Using Point Supervision
Jul 10, 2020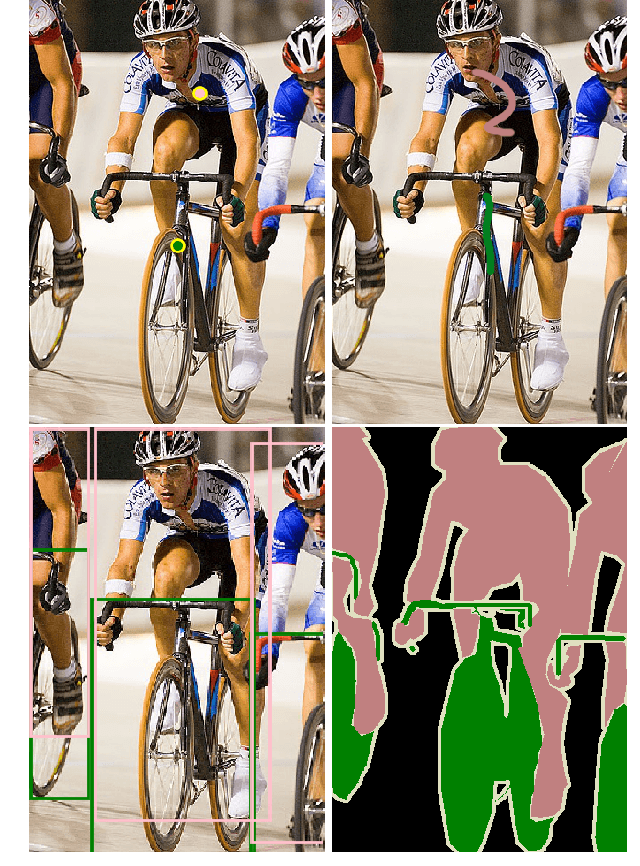
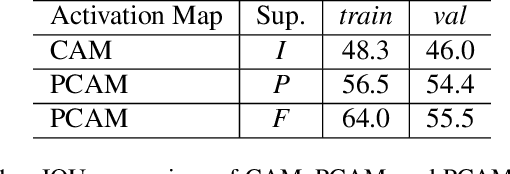
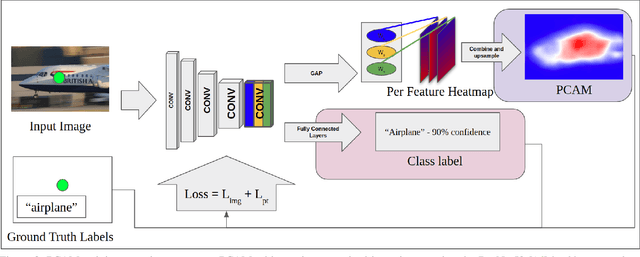

Current state of the art methods for generating semantic segmentation rely heavily on a large set of images that have each pixel labeled with a class of interest label or background. Coming up with such labels, especially in domains that require an expert to do annotations, comes at a heavy cost in time and money. Several methods have shown that we can learn semantic segmentation from less expensive image-level labels, but the effectiveness of point level labels, a healthy compromise between all pixels labelled and none, still remains largely unexplored. This paper presents a novel procedure for producing semantic segmentation from images given some point level annotations. This method includes point annotations in the training of a convolutional neural network (CNN) for producing improved localization and class activation maps. Then, we use another CNN for predicting semantic affinities in order to propagate rough class labels and create pseudo semantic segmentation labels. Finally, we propose training a CNN that is normally fully supervised using our pseudo labels in place of ground truth labels, which further improves performance and simplifies the inference process by requiring just one CNN during inference rather than two. Our method achieves state of the art results for point supervised semantic segmentation on the PASCAL VOC 2012 dataset \cite{everingham2010pascal}, even outperforming state of the art methods for stronger bounding box and squiggle supervision.
Unsupervised Adversarial Attacks on Deep Feature-based Retrieval with GAN
Jul 12, 2019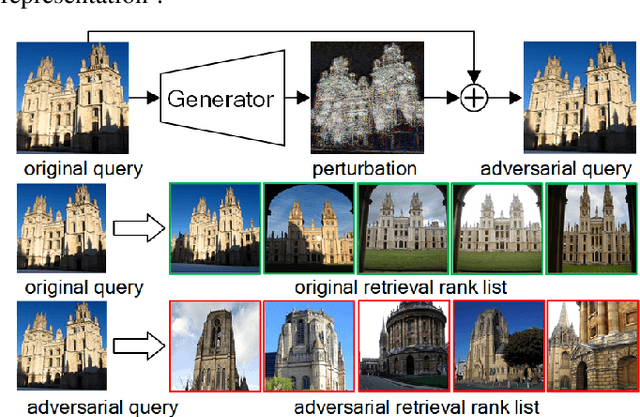
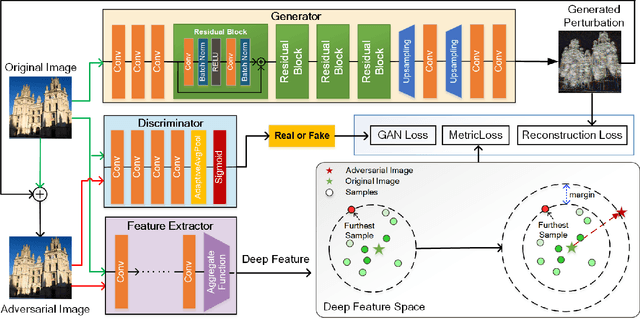
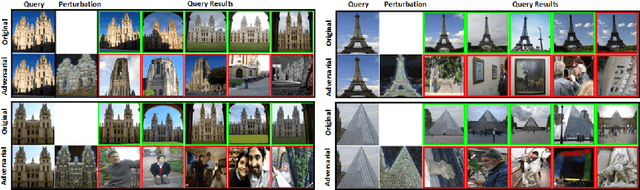

Studies show that Deep Neural Network (DNN)-based image classification models are vulnerable to maliciously constructed adversarial examples. However, little effort has been made to investigate how DNN-based image retrieval models are affected by such attacks. In this paper, we introduce Unsupervised Adversarial Attacks with Generative Adversarial Networks (UAA-GAN) to attack deep feature-based image retrieval systems. UAA-GAN is an unsupervised learning model that requires only a small amount of unlabeled data for training. Once trained, it produces query-specific perturbations for query images to form adversarial queries. The core idea is to ensure that the attached perturbation is barely perceptible to human yet effective in pushing the query away from its original position in the deep feature space. UAA-GAN works with various application scenarios that are based on deep features, including image retrieval, person Re-ID and face search. Empirical results show that UAA-GAN cripples retrieval performance without significant visual changes in the query images. UAA-GAN generated adversarial examples are less distinguishable because they tend to incorporate subtle perturbations in textured or salient areas of the images, such as key body parts of human, dominant structural patterns/textures or edges, rather than in visually insignificant areas (e.g., background and sky). Such tendency indicates that the model indeed learned how to toy with both image retrieval systems and human eyes.