 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropic alternatives to initialization
Jul 28, 2021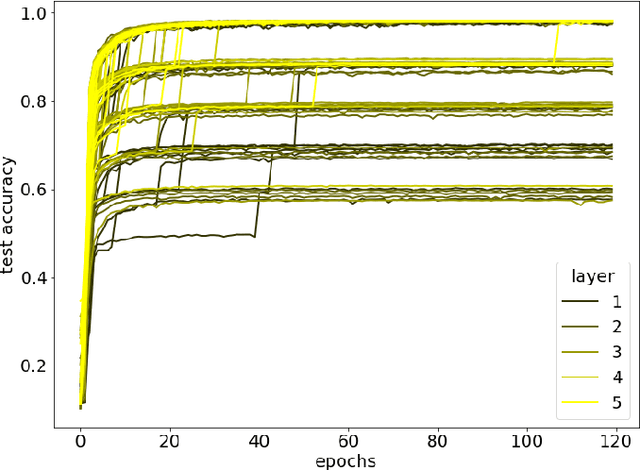
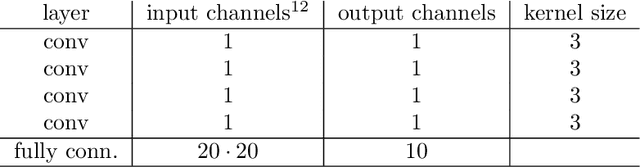
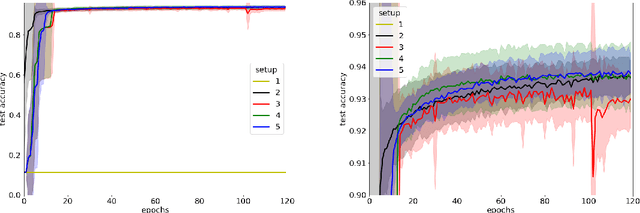
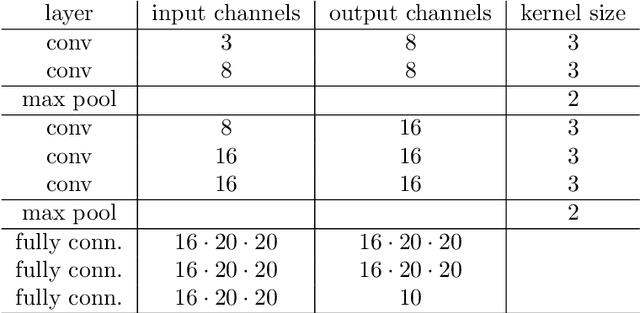
Local entropic loss functions provide a versatile framework to define architecture-aware regularization procedures. Besides the possibility of being anisotropic in the synaptic space, the local entropic smoothening of the loss function can vary during training, thus yielding a tunable model complexity. A scoping protocol where the regularization is strong in the early-stage of the training and then fades progressively away constitutes an alternative to standard initialization procedures for deep convolutional neural networks, nonetheless, it has wider applicability. We analyze anisotropic, local entropic smoothenings in the language of statistical physics and information theory, providing insight into both their interpretation and workings. We comment some aspects related to the physics of renormalization and the spacetime structure of convolutional networks.
Partial local entropy and anisotropy in deep weight spaces
Jul 17, 2020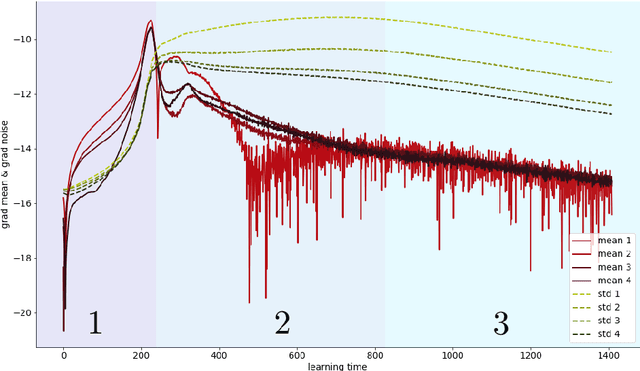
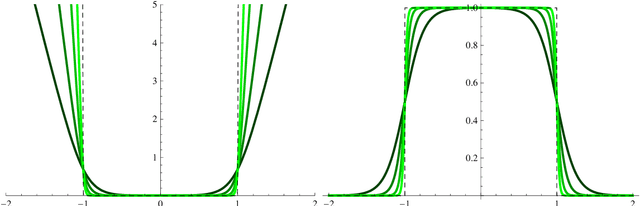
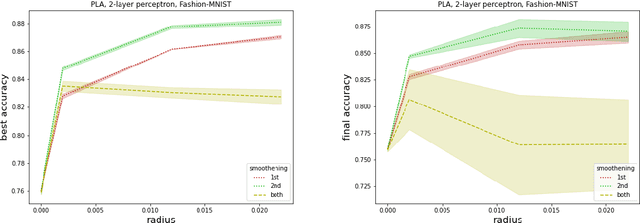
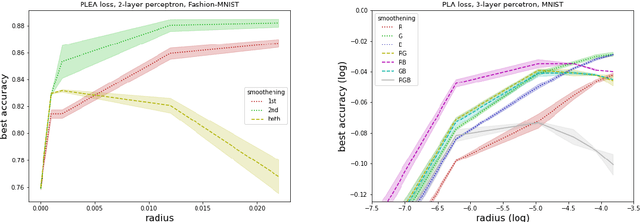
We refine a recently-proposed class of local entropic loss functions by restricting the smoothening regularization to only a subset of weights. The new loss functions are referred to as partial local entropies. They can adapt to the weight-space anisotropy, thus outperforming their isotropic counterparts. We support the theoretical analysis with experiments on image classification tasks performed with multi-layer, fully-connected neural networks. The present study suggests how to better exploit the anisotropic nature of deep landscapes and provides direct probes of the shape of the wide flat minima encountered by stochastic gradient descent algorithms. As a by-product, we observe an asymptotic dynamical regime at late training times where the temperature of all the layers obeys a common scaling rule.
Stochastic gradient descent with random learning rate
Apr 10, 2020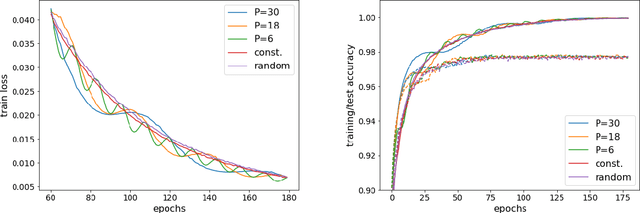
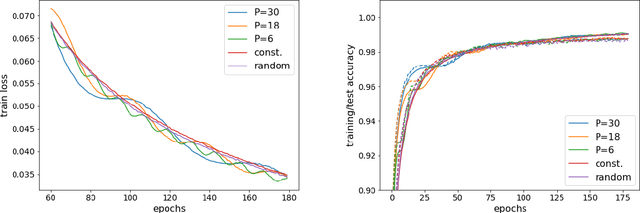
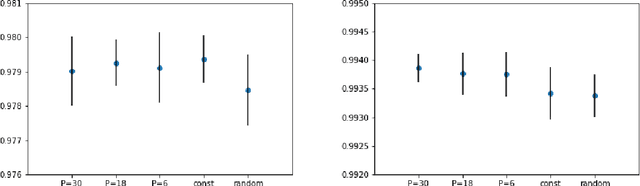
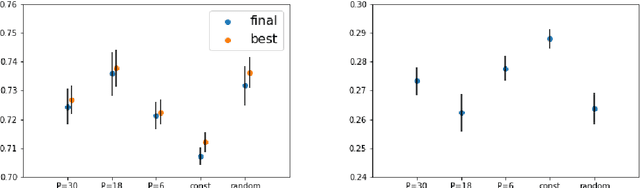
We propose to optimize neural networks with a uniformly-distributed random learning rate. The associated stochastic gradient descent algorithm can be approximated by continuous stochastic equations and analyzed with the Fokker-Planck formalism. In the small learning rate approximation, the training process is characterized by an effective temperature which depends on the average learning rate, the mini-batch size and the momentum of the optimization algorithm. By comparing the random learning rate protocol with cyclic and constant protocols, we suggest that the random choice is generically the best strategy in the small learning rate regime, yielding better regularization without extra computational cost. We provide supporting evidence through experiments on both shallow, fully-connected and deep, convolutional neural networks for image classification on the MNIST and CIFAR10 datasets.