 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automated fetal brain extraction from clinical Ultrasound volumes using 3D Convolutional Neural Networks
Nov 19, 2019
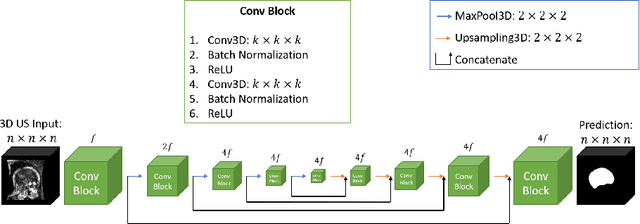
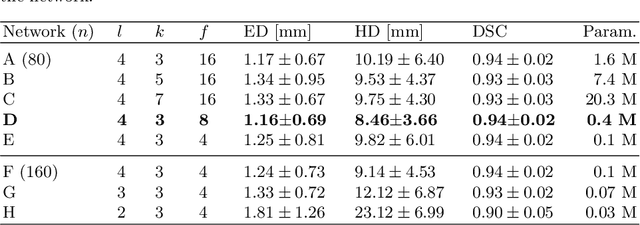
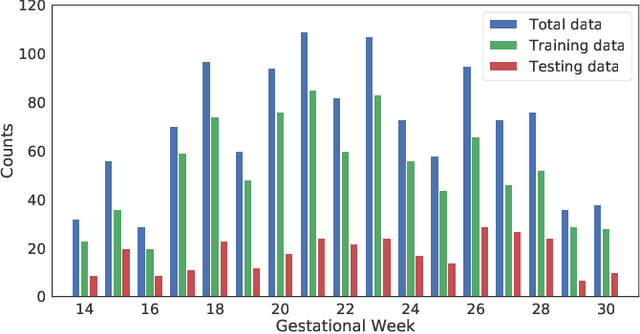
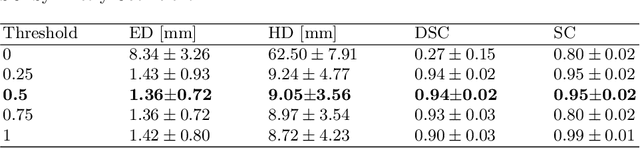
To improve the performance of most neuroimiage analysis pipelines, brain extraction is used as a fundamental first step in the image processing. But in the case of fetal brain development, there is a need for a reliable US-specific tool. In this work we propose a fully automated 3D CNN approach to fetal brain extraction from 3D US clinical volumes with minimal preprocessing. Our method accurately and reliably extracts the brain regardless of the large data variation inherent in this imaging modality. It also performs consistently throughout a gestational age range between 14 and 31 weeks, regardless of the pose variation of the subject, the scale, and even partial feature-obstruction in the image, outperforming all current alternatives.
Computing Topology Preservation of RBF Transformations for Landmark-Based Image Registration
Oct 13, 2014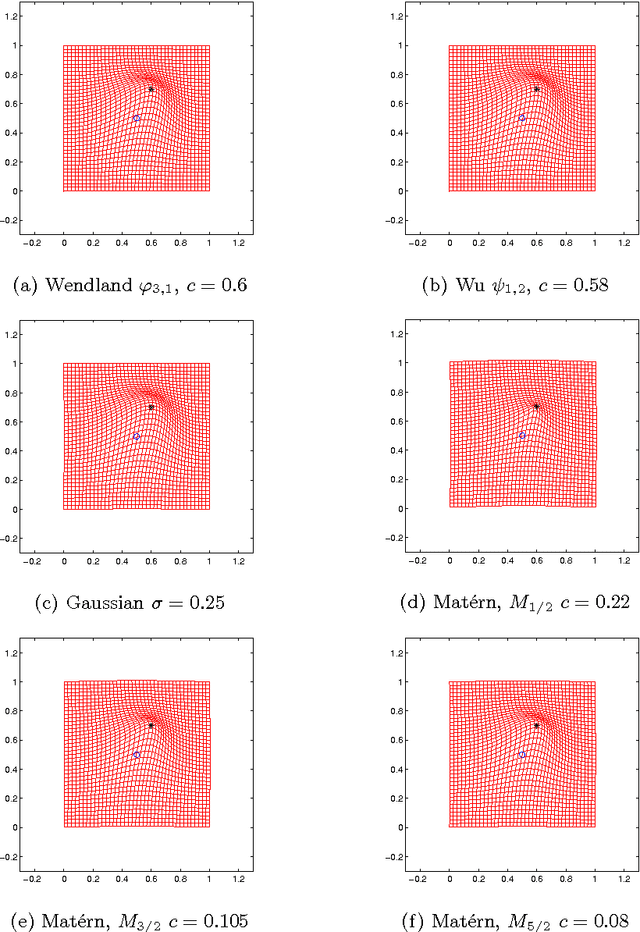
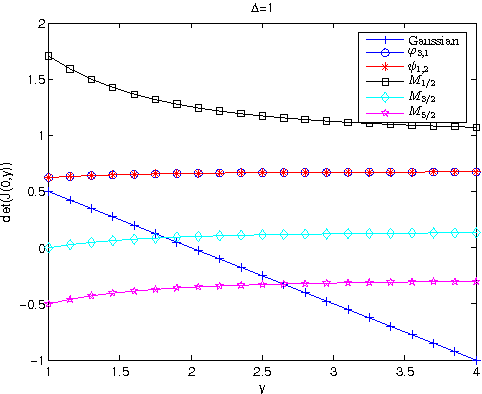
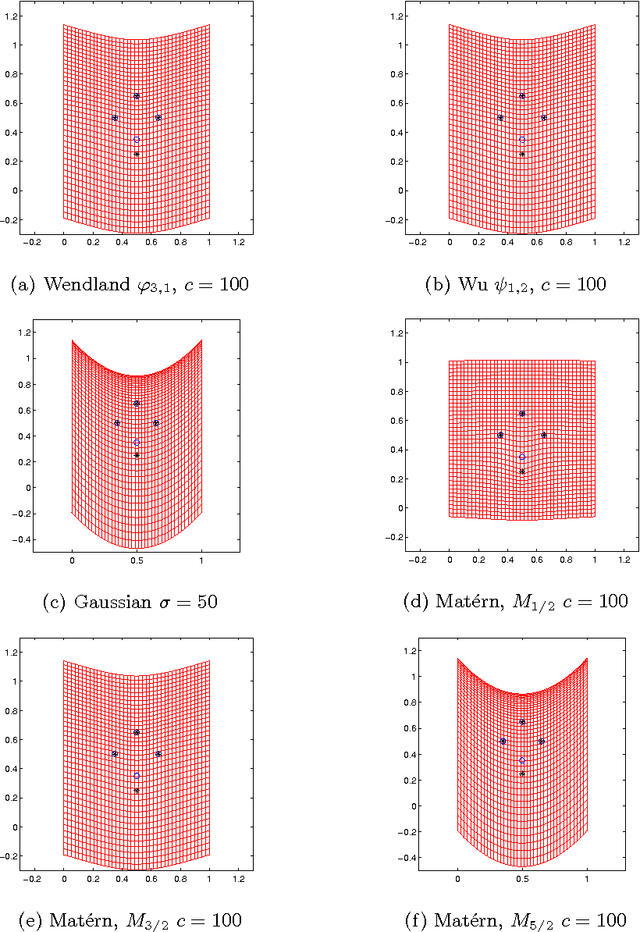
In image registration, a proper transformation should be topology preserving. Especially for landmark-based image registration, if the displacement of one landmark is larger enough than those of neighbourhood landmarks, topology violation will be occurred. This paper aim to analyse the topology preservation of some Radial Basis Functions (RBFs) which are used to model deformations in image registration. Mat\'{e}rn functions are quite common in the statistic literature (see, e.g. \cite{Matern86,Stein99}). In this paper, we use them to solve the landmark-based image registration problem. We present the topology preservation properties of RBFs in one landmark and four landmarks model respectively. Numerical results of three kinds of Mat\'{e}rn transformations are compared with results of Gaussian, Wendland's, and Wu's functions.
Improving Sample Efficiency in Model-Free Reinforcement Learning from Images
Oct 07, 2019
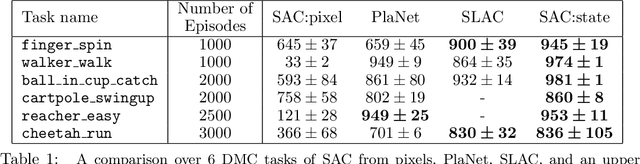
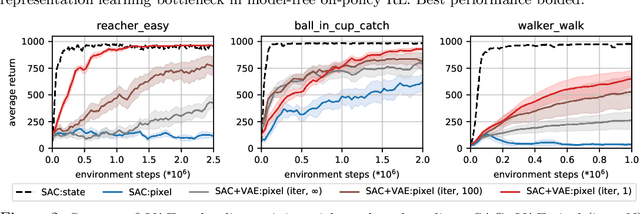
Training an agent to solve control tasks directly from high-dimensional images with model-free reinforcement learning (RL) has proven difficult. The agent needs to learn a latent representation together with a control policy to perform the task. Fitting a high-capacity encoder using a scarce reward signal is not only sample inefficient, but also prone to suboptimal convergence. Two ways to improve sample efficiency are to extract relevant features for the task and use off-policy algorithms. We dissect various approaches of learning good latent features, and conclude that the image reconstruction loss is the essential ingredient that enables efficient and stable representation learning in image-based RL. Following these findings, we devise an off-policy actor-critic algorithm with an auxiliary decoder that trains end-to-end and matches state-of-the-art performance across both model-free and model-based algorithms on many challenging control tasks. We release our code to encourage future research on image-based RL.
Estimating semantic structure for the VQA answer space
Jun 10, 2020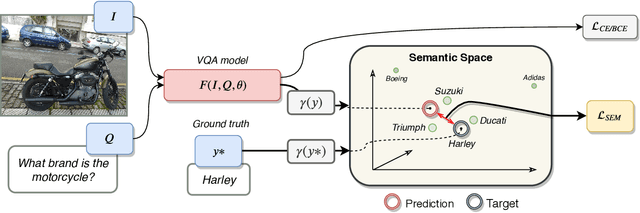
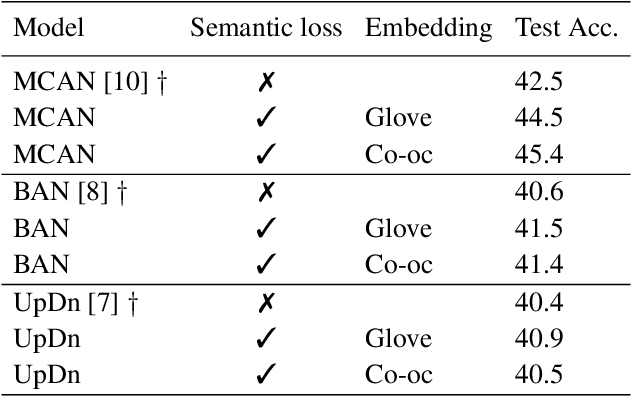

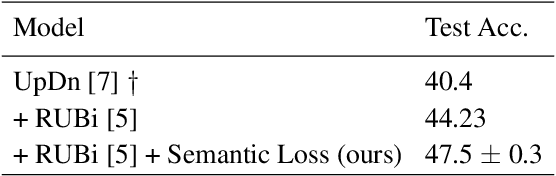
Since its appearance, Visual Question Answering (VQA, i.e. answering a question posed over an image), has always been treated as a classification problem over a set of predefined answers. Despite its convenience, this classification approach poorly reflects the semantics of the problem limiting the answering to a choice between independent proposals, without taking into account the similarity between them (e.g. equally penalizing for answering cat or German shepherd instead of dog). We address this issue by proposing (1) two measures of proximity between VQA classes, and (2) a corresponding loss which takes into account the estimated proximity. This significantly improves the generalization of VQA models by reducing their language bias. In particular, we show that our approach is completely model-agnostic since it allows consistent improvements with three different VQA models. Finally, by combining our method with a language bias reduction approach, we report SOTA-level performance on the challenging VQAv2-CP dataset.
How low can you go? Privacy-preserving people detection with an omni-directional camera
Jul 09, 2020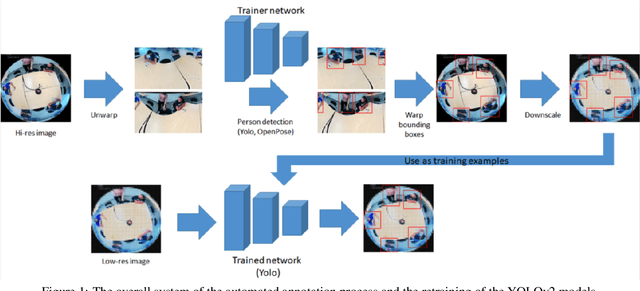
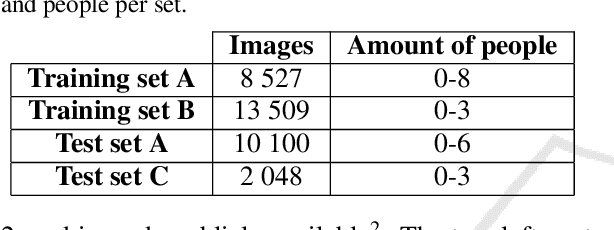

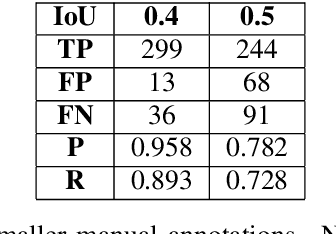
In this work, we use a ceiling-mounted omni-directional camera to detect people in a room. This can be used as a sensor to measure the occupancy of meeting rooms and count the amount of flex-desk working spaces available. If these devices can be integrated in an embedded low-power sensor, it would form an ideal extension of automated room reservation systems in office environments. The main challenge we target here is ensuring the privacy of the people filmed. The approach we propose is going to extremely low image resolutions, such that it is impossible to recognise people or read potentially confidential documents. Therefore, we retrained a single-shot low-resolution person detection network with automatically generated ground truth. In this paper, we prove the functionality of this approach and explore how low we can go in resolution, to determine the optimal trade-off between recognition accuracy and privacy preservation. Because of the low resolution, the result is a lightweight network that can potentially be deployed on embedded hardware. Such embedded implementation enables the development of a decentralised smart camera which only outputs the required meta-data (i.e. the number of persons in the meeting room).
Rethinking CNN Models for Audio Classification
Jul 22, 2020
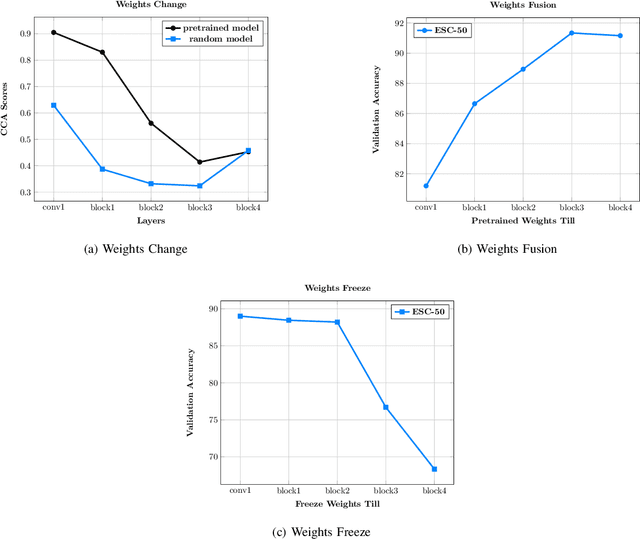
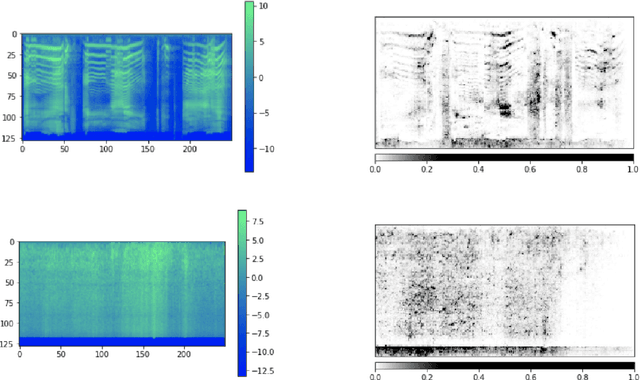
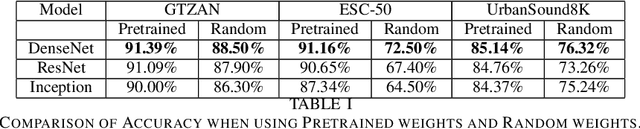
In this paper, we show that ImageNet-Pretrained standard deep CNN models can be used as strong baseline networks for audio classification. Even though there is a significant difference between audio Spectrogram and standard ImageNet image samples, transfer learning assumptions still hold firmly. To understand what enables the ImageNet pretrained models to learn useful audio representations, we systematically study how much of pretrained weights is useful for learning spectrograms. We show (1) that for a given standard model using pretrained weights is better than using randomly initialized weights (2) qualitative results of what the CNNs learn from the spectrograms by visualizing the gradients. Besides, we show that even though we use the pretrained model weights for initialization, there is variance in performance in various output runs of the same model. This variance in performance is due to the random initialization of linear classification layer and random mini-batch orderings in multiple runs. This brings significant diversity to build stronger ensemble models with an overall improvement in accuracy. An ensemble of ImageNet pretrained DenseNet achieves 92.89% validation accuracy on the ESC-50 dataset and 87.42% validation accuracy on the UrbanSound8K dataset which is the current state-of-the-art on both of these datasets.
End-to-End Learning for Image Burst Deblurring
Sep 06, 2016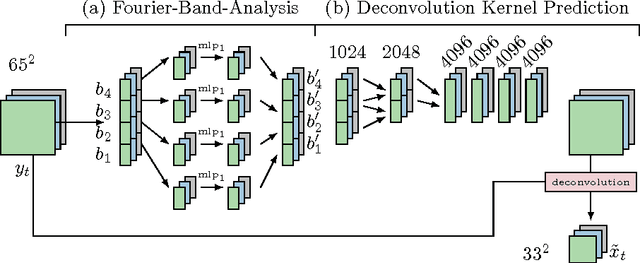
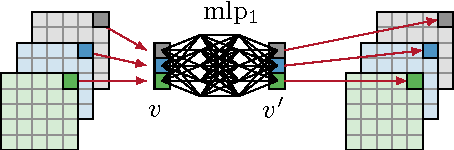

We present a neural network model approach for multi-frame blind deconvolution. The discriminative approach adopts and combines two recent techniques for image deblurring into a single neural network architecture. Our proposed hybrid-architecture combines the explicit prediction of a deconvolution filter and non-trivial averaging of Fourier coefficients in the frequency domain. In order to make full use of the information contained in all images in one burst, the proposed network embeds smaller networks, which explicitly allow the model to transfer information between images in early layers. Our system is trained end-to-end using standard backpropagation on a set of artificially generated training examples, enabling competitive performance in multi-frame blind deconvolution, both with respect to quality and runtime.
Contextual Diversity for Active Learning
Aug 13, 2020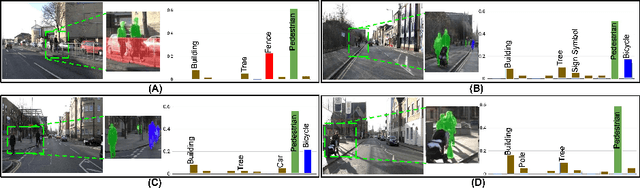
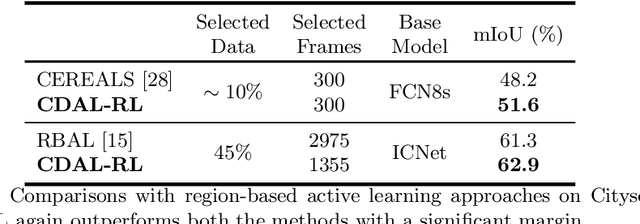
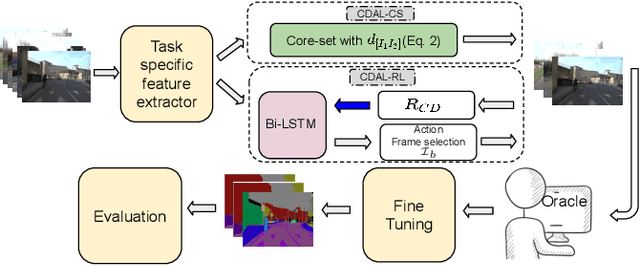

Requirement of large annotated datasets restrict the use of deep convolutional neural networks (CNNs) for many practical applications. The problem can be mitigated by using active learning (AL) techniques which, under a given annotation budget, allow to select a subset of data that yields maximum accuracy upon fine tuning. State of the art AL approaches typically rely on measures of visual diversity or prediction uncertainty, which are unable to effectively capture the variations in spatial context. On the other hand, modern CNN architectures make heavy use of spatial context for achieving highly accurate predictions. Since the context is difficult to evaluate in the absence of ground-truth labels, we introduce the notion of contextual diversity that captures the confusion associated with spatially co-occurring classes. Contextual Diversity (CD) hinges on a crucial observation that the probability vector predicted by a CNN for a region of interest typically contains information from a larger receptive field. Exploiting this observation, we use the proposed CD measure within two AL frameworks: (1) a core-set based strategy and (2) a reinforcement learning based policy, for active frame selection. Our extensive empirical evaluation establish state of the art results for active learning on benchmark datasets of Semantic Segmentation, Object Detection and Image Classification. Our ablation studies show clear advantages of using contextual diversity for active learning. The source code and additional results are available at https://github.com/sharat29ag/CDAL.
TACO: Trash Annotations in Context for Litter Detection
Mar 16, 2020
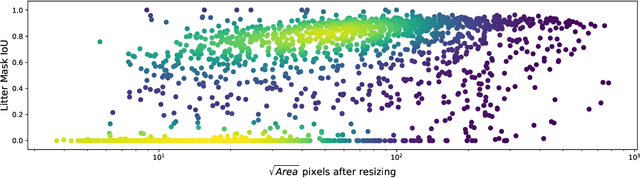


TACO is an open image dataset for litter detection and segmentation, which is growing through crowdsourcing. Firstly, this paper describes this dataset and the tools developed to support it. Secondly, we report instance segmentation performance using Mask R-CNN on the current version of TACO. Despite its small size (1500 images and 4784 annotations), our results are promising on this challenging problem. However, to achieve satisfactory trash detection in the wild for deployment, TACO still needs much more manual annotations. These can be contributed using: http://tacodataset.org/
Efficient training-image based geostatistical simulation and inversion using a spatial generative adversarial neural network
Aug 16, 2017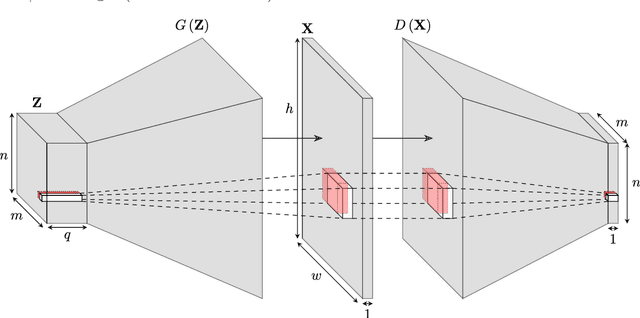
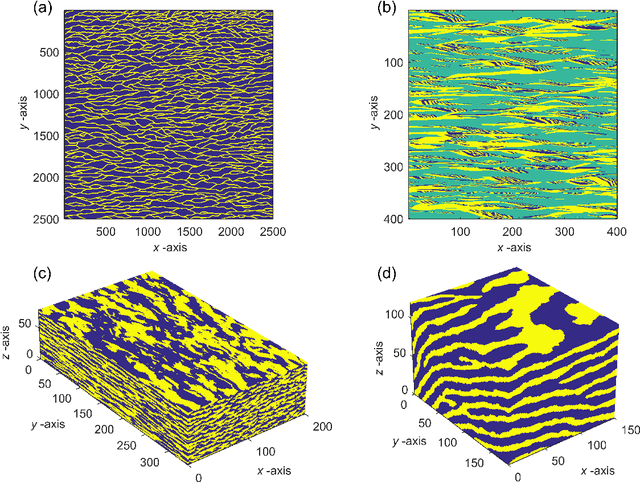
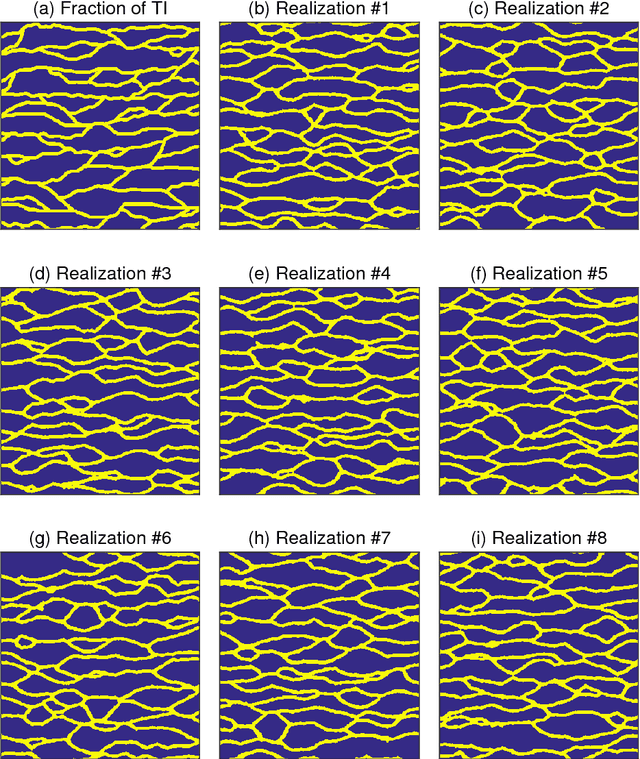
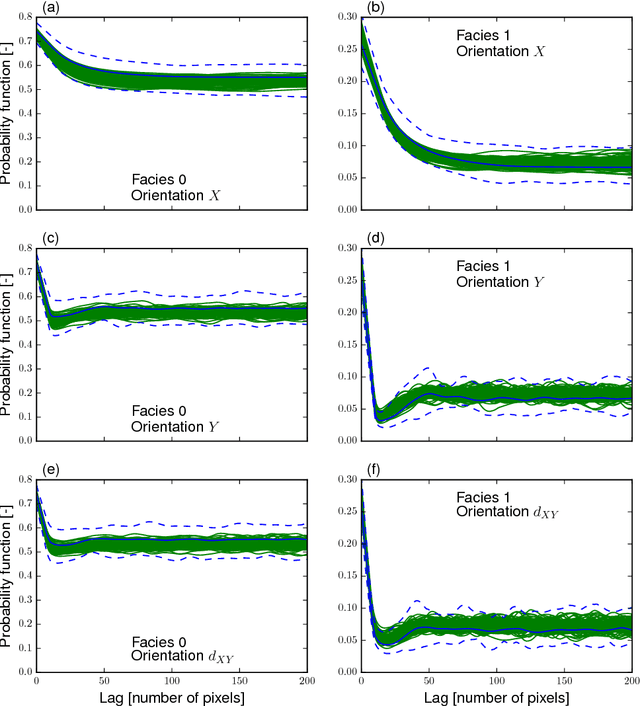
Probabilistic inversion within a multiple-point statistics framework is still computationally prohibitive for large-scale problems. To partly address this, we introduce and evaluate a new training-image based simulation and inversion approach for complex geologic media. Our approach relies on a deep neural network of the spatial generative adversarial network (SGAN) type. After training using a training image (TI), our proposed SGAN can quickly generate 2D and 3D unconditional realizations. A key feature of our SGAN is that it defines a (very) low-dimensional parameterization, thereby allowing for efficient probabilistic (or deterministic) inversion using state-of-the-art Markov chain Monte Carlo (MCMC) methods. A series of 2D and 3D categorical TIs is first used to analyze the performance of our SGAN for unconditional simulation. The speed at which realizations are generated makes it especially useful for simulating over large grids and/or from a complex multi-categorical TI. Subsequently, synthetic inversion case studies involving 2D steady-state flow and 3D transient hydraulic tomography are used to illustrate the effectiveness of our proposed SGAN-based probabilistic inversion. For the 2D case, the inversion rapidly explores the posterior model distribution. For the 3D case, the inversion recovers model realizations that fit the data close to the target level and visually resemble the true model well. Future work will focus on the inclusion of direct conditioning data and application to continuous TIs.