 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Contextual Uncertainty of Visual Data for Efficient Training of Deep Models
Nov 04, 2024Objects, in the real world, rarely occur in isolation and exhibit typical arrangements governed by their independent utility, and their expected interaction with humans and other objects in the context. For example, a chair is expected near a table, and a computer is expected on top. Humans use this spatial context and relative placement as an important cue for visual recognition in case of ambiguities. Similar to human's, DNN's exploit contextual information from data to learn representations. Our research focuses on harnessing the contextual aspects of visual data to optimize data annotation and enhance the training of deep networks. Our contributions can be summarized as follows: (1) We introduce the notion of contextual diversity for active learning CDAL and show its applicability in three different visual tasks semantic segmentation, object detection and image classification, (2) We propose a data repair algorithm to curate contextually fair data to reduce model bias, enabling the model to detect objects out of their obvious context, (3) We propose Class-based annotation, where contextually relevant classes are selected that are complementary for model training under domain shift. Understanding the importance of well-curated data, we also emphasize the necessity of involving humans in the loop to achieve accurate annotations and to develop novel interaction strategies that allow humans to serve as fact-checkers. In line with this we are working on developing image retrieval system for wildlife camera trap images and reliable warning system for poor quality rural roads. For large-scale annotation, we are employing a strategic combination of human expertise and zero-shot models, while also integrating human input at various stages for continuous feedback.
Reducing Annotation Effort by Identifying and Labeling Contextually Diverse Classes for Semantic Segmentation Under Domain Shift
Oct 13, 2022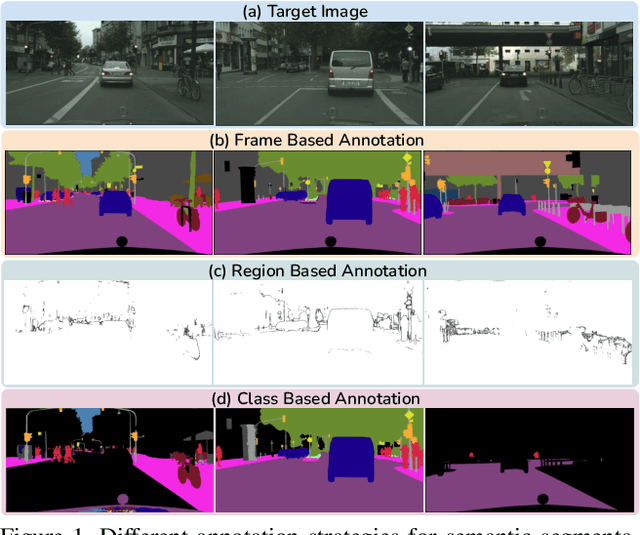
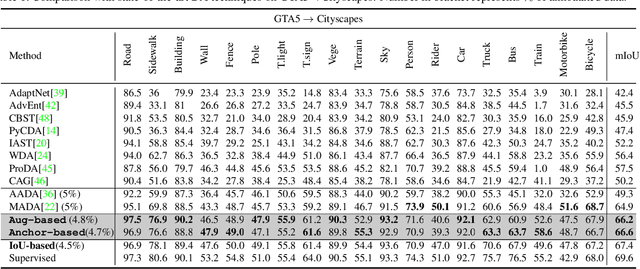
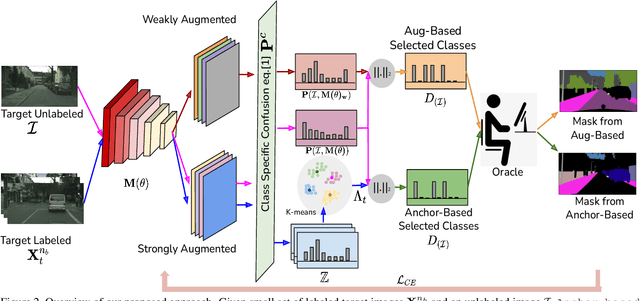
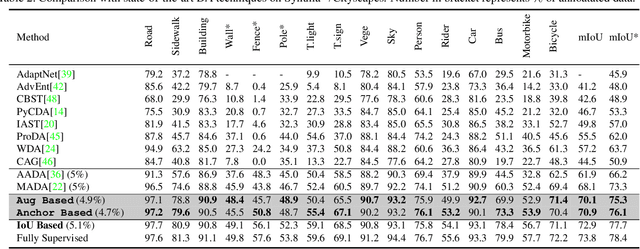
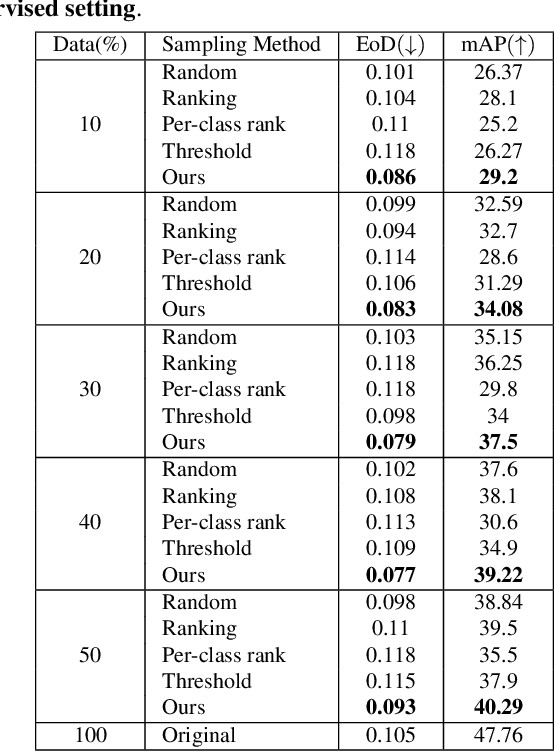
In Active Domain Adaptation (ADA), one uses Active Learning (AL) to select a subset of images from the target domain, which are then annotated and used for supervised domain adaptation (DA). Given the large performance gap between supervised and unsupervised DA techniques, ADA allows for an excellent trade-off between annotation cost and performance. Prior art makes use of measures of uncertainty or disagreement of models to identify `regions' to be annotated by the human oracle. However, these regions frequently comprise of pixels at object boundaries which are hard and tedious to annotate. Hence, even if the fraction of image pixels annotated reduces, the overall annotation time and the resulting cost still remain high. In this work, we propose an ADA strategy, which given a frame, identifies a set of classes that are hardest for the model to predict accurately, thereby recommending semantically meaningful regions to be annotated in a selected frame. We show that these set of `hard' classes are context-dependent and typically vary across frames, and when annotated help the model generalize better. We propose two ADA techniques: the Anchor-based and Augmentation-based approaches to select complementary and diverse regions in the context of the current training set. Our approach achieves 66.6 mIoU on GTA to Cityscapes dataset with an annotation budget of 4.7% in comparison to 64.9 mIoU by MADA using 5% of annotations. Our technique can also be used as a decorator for any existing frame-based AL technique, e.g., we report 1.5% performance improvement for CDAL on Cityscapes using our approach.
Does Data Repair Lead to Fair Models? Curating Contextually Fair Data To Reduce Model Bias
Oct 20, 2021
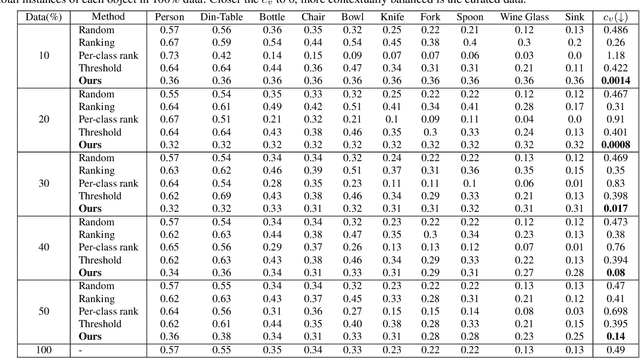
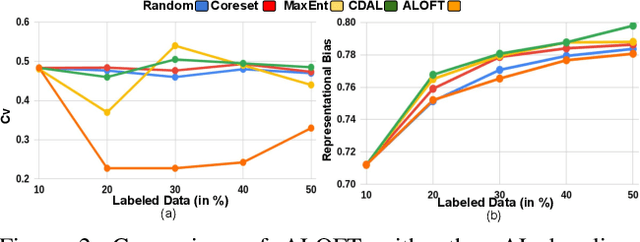
Contextual information is a valuable cue for Deep Neural Networks (DNNs) to learn better representations and improve accuracy. However, co-occurrence bias in the training dataset may hamper a DNN model's generalizability to unseen scenarios in the real world. For example, in COCO, many object categories have a much higher co-occurrence with men compared to women, which can bias a DNN's prediction in favor of men. Recent works have focused on task-specific training strategies to handle bias in such scenarios, but fixing the available data is often ignored. In this paper, we propose a novel and more generic solution to address the contextual bias in the datasets by selecting a subset of the samples, which is fair in terms of the co-occurrence with various classes for a protected attribute. We introduce a data repair algorithm using the coefficient of variation, which can curate fair and contextually balanced data for a protected class(es). This helps in training a fair model irrespective of the task, architecture or training methodology. Our proposed solution is simple, effective, and can even be used in an active learning setting where the data labels are not present or being generated incrementally. We demonstrate the effectiveness of our algorithm for the task of object detection and multi-label image classification across different datasets. Through a series of experiments, we validate that curating contextually fair data helps make model predictions fair by balancing the true positive rate for the protected class across groups without compromising on the model's overall performance.
Contextual Diversity for Active Learning
Aug 13, 2020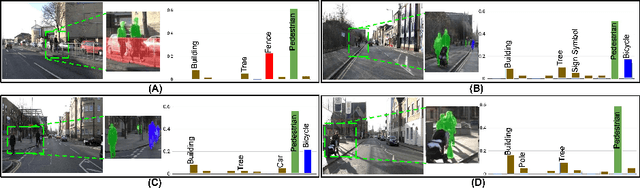
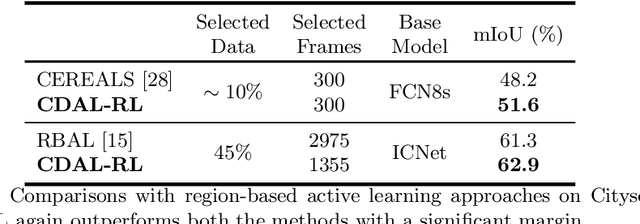
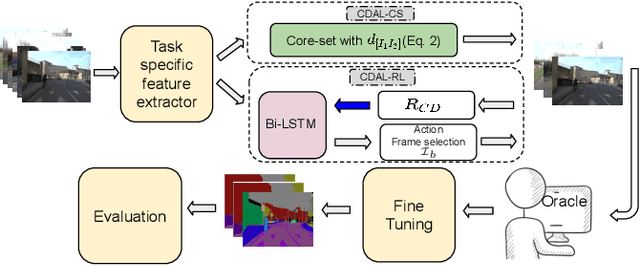

Requirement of large annotated datasets restrict the use of deep convolutional neural networks (CNNs) for many practical applications. The problem can be mitigated by using active learning (AL) techniques which, under a given annotation budget, allow to select a subset of data that yields maximum accuracy upon fine tuning. State of the art AL approaches typically rely on measures of visual diversity or prediction uncertainty, which are unable to effectively capture the variations in spatial context. On the other hand, modern CNN architectures make heavy use of spatial context for achieving highly accurate predictions. Since the context is difficult to evaluate in the absence of ground-truth labels, we introduce the notion of contextual diversity that captures the confusion associated with spatially co-occurring classes. Contextual Diversity (CD) hinges on a crucial observation that the probability vector predicted by a CNN for a region of interest typically contains information from a larger receptive field. Exploiting this observation, we use the proposed CD measure within two AL frameworks: (1) a core-set based strategy and (2) a reinforcement learning based policy, for active frame selection. Our extensive empirical evaluation establish state of the art results for active learning on benchmark datasets of Semantic Segmentation, Object Detection and Image Classification. Our ablation studies show clear advantages of using contextual diversity for active learning. The source code and additional results are available at https://github.com/sharat29ag/CDAL.