 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bayesian ensemble learning for image denoising
Aug 06, 2013
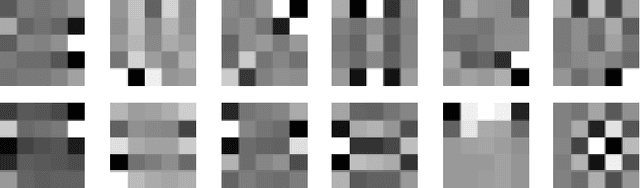


Natural images are often affected by random noise and image denoising has long been a central topic in Computer Vision. Many algorithms have been introduced to remove the noise from the natural images, such as Gaussian, Wiener filtering and wavelet thresholding. However, many of these algorithms remove the fine edges and make them blur. Recently, many promising denoising algorithms have been introduced such as Non-local Means, Fields of Experts, and BM3D. In this paper, we explore Bayesian method of ensemble learning for image denoising. Ensemble methods seek to combine multiple different algorithms to retain the strengths of all methods and the weaknesses of none. Bayesian ensemble models are Non-local Means and Fields of Experts, the very successful recent algorithms. The Non-local Means presumes that the image contains an extensive amount of self-similarity. The approach of the Fields of Experts model extends traditional Markov Random Field model by learning potential functions over extended pixel neighborhoods. The two models are implemented and image denoising is performed on natural images. The experimental results obtained are used to compare with the single algorithm and discuss the ensemble learning and their approaches. Comparing to the results of Non-local Means and Fields of Experts, Ensemble learning showed improvement nearly 1dB.
A Diffractive Neural Network with Weight-Noise-Injection Training
Jun 10, 2020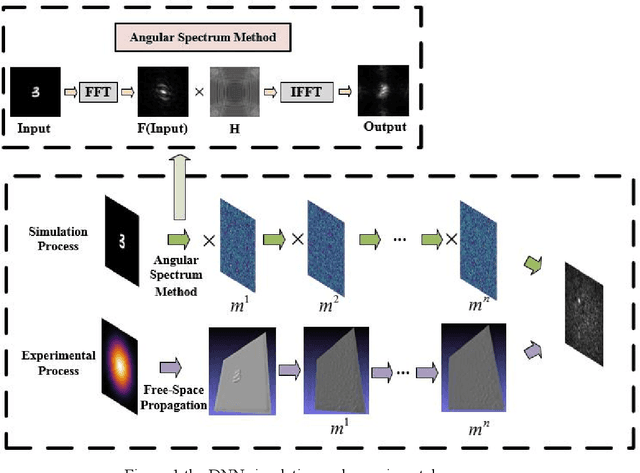
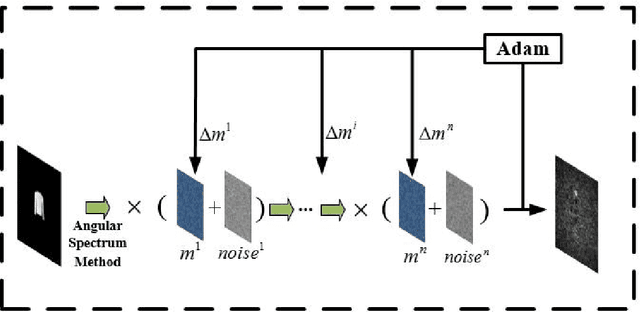
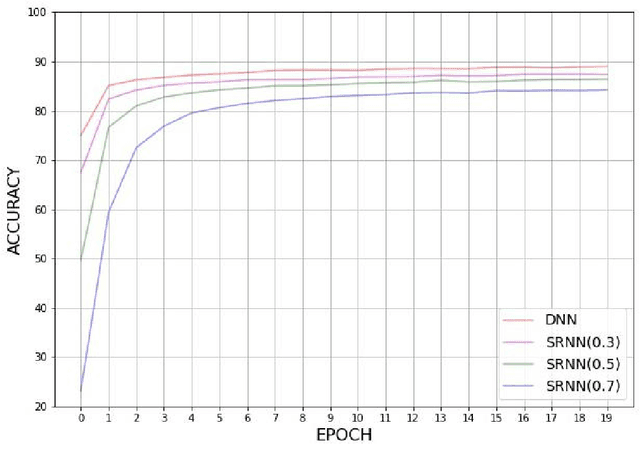

We propose a diffractive neural network with strong robustness based on Weight Noise Injection training, which achieves accurate and fast optical-based classification while diffraction layers have a certain amount of surface shape error. To the best of our knowledge, it is the first time that using injection weight noise during training to reduce the impact of external interference on deep learning inference results. In the proposed method, the diffractive neural network learns the mapping between the input image and the label in Weight Noise Injection mode, making the network's weight insensitive to modest changes, which improve the network's noise resistance at a lower cost. By comparing the accuracy of the network under different noise, it is verified that the proposed network (SRNN) still maintains a higher accuracy under serious noise.
NeuroMask: Explaining Predictions of Deep Neural Networks through Mask Learning
Aug 05, 2019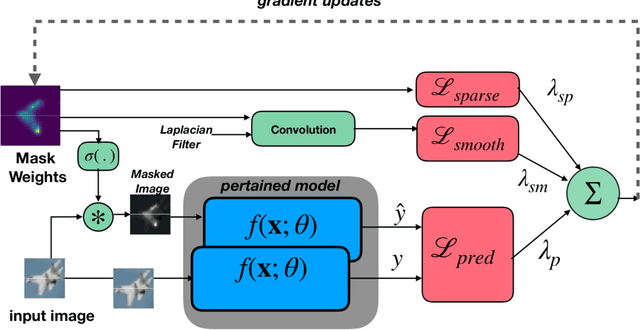



Deep Neural Networks (DNNs) deliver state-of-the-art performance in many image recognition and understanding applications. However, despite their outstanding performance, these models are black-boxes and it is hard to understand how they make their decisions. Over the past few years, researchers have studied the problem of providing explanations of why DNNs predicted their results. However, existing techniques are either obtrusive, requiring changes in model training, or suffer from low output quality. In this paper, we present a novel method, NeuroMask, for generating an interpretable explanation of classification model results. When applied to image classification models, NeuroMask identifies the image parts that are most important to classifier results by applying a mask that hides/reveals different parts of the image, before feeding it back into the model. The mask values are tuned by minimizing a properly designed cost function that preserves the classification result and encourages producing an interpretable mask. Experiments using state-of-the-art Convolutional Neural Networks for image recognition on different datasets (CIFAR-10 and ImageNet) show that NeuroMask successfully localizes the parts of the input image which are most relevant to the DNN decision. By showing a visual quality comparison between NeuroMask explanations and those of other methods, we find NeuroMask to be both accurate and interpretable.
Self-Supervised Siamese Learning on Stereo Image Pairs for Depth Estimation in Robotic Surgery
May 17, 2017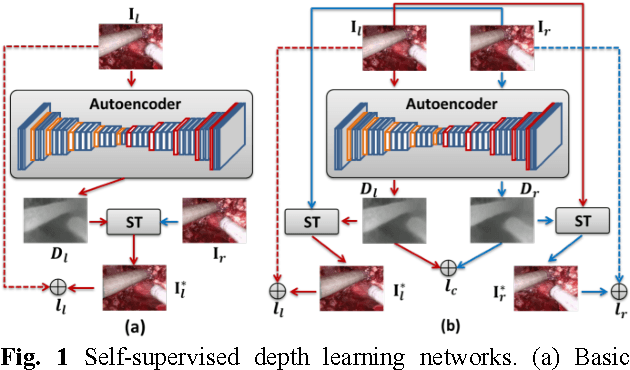
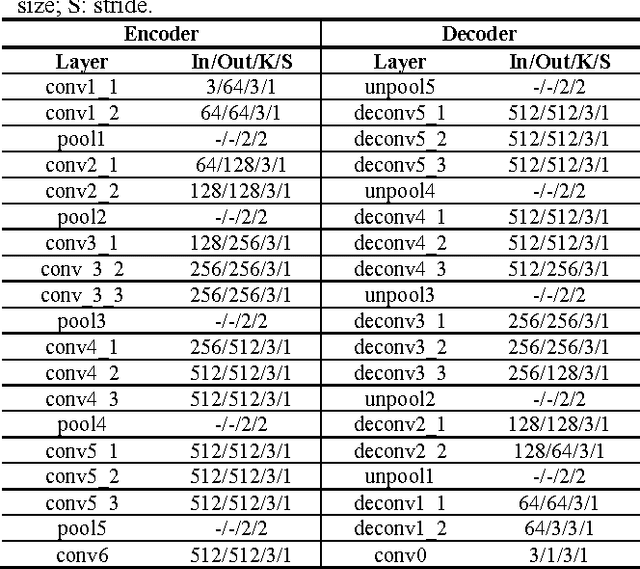
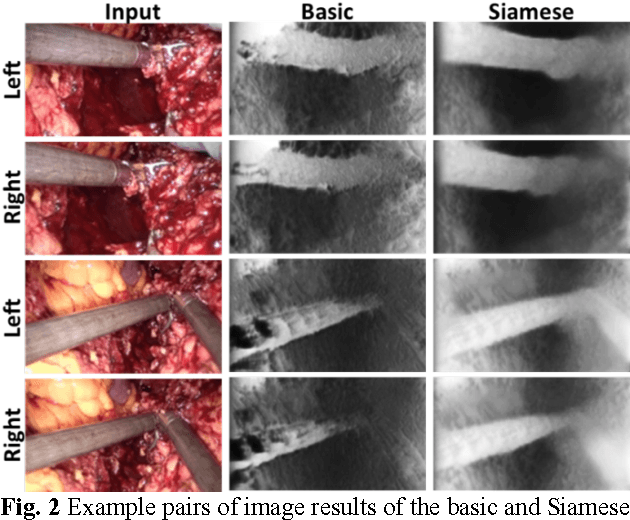

Robotic surgery has become a powerful tool for performing minimally invasive procedures, providing advantages in dexterity, precision, and 3D vision, over traditional surgery. One popular robotic system is the da Vinci surgical platform, which allows preoperative information to be incorporated into live procedures using Augmented Reality (AR). Scene depth estimation is a prerequisite for AR, as accurate registration requires 3D correspondences between preoperative and intraoperative organ models. In the past decade, there has been much progress on depth estimation for surgical scenes, such as using monocular or binocular laparoscopes [1,2]. More recently, advances in deep learning have enabled depth estimation via Convolutional Neural Networks (CNNs) [3], but training requires a large image dataset with ground truth depths. Inspired by [4], we propose a deep learning framework for surgical scene depth estimation using self-supervision for scalable data acquisition. Our framework consists of an autoencoder for depth prediction, and a differentiable spatial transformer for training the autoencoder on stereo image pairs without ground truth depths. Validation was conducted on stereo videos collected in robotic partial nephrectomy.
3D Model Assisted Image Segmentation
Feb 09, 2012



The problem of segmenting a given image into coherent regions is important in Computer Vision and many industrial applications require segmenting a known object into its components. Examples include identifying individual parts of a component for process control work in a manufacturing plant and identifying parts of a car from a photo for automatic damage detection. Unfortunately most of an object's parts of interest in such applications share the same pixel characteristics, having similar colour and texture. This makes segmenting the object into its components a non-trivial task for conventional image segmentation algorithms. In this paper, we propose a "Model Assisted Segmentation" method to tackle this problem. A 3D model of the object is registered over the given image by optimising a novel gradient based loss function. This registration obtains the full 3D pose from an image of the object. The image can have an arbitrary view of the object and is not limited to a particular set of views. The segmentation is subsequently performed using a level-set based method, using the projected contours of the registered 3D model as initialisation curves. The method is fully automatic and requires no user interaction. Also, the system does not require any prior training. We present our results on photographs of a real car.
* 18 LaTeX pages, 11 figures, 1 algorithm, 1 table
Depthwise-STFT based separable Convolutional Neural Networks
Jan 27, 2020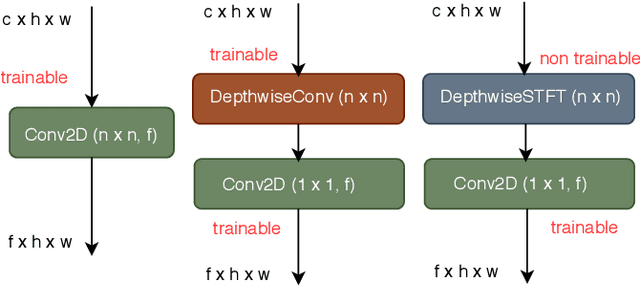


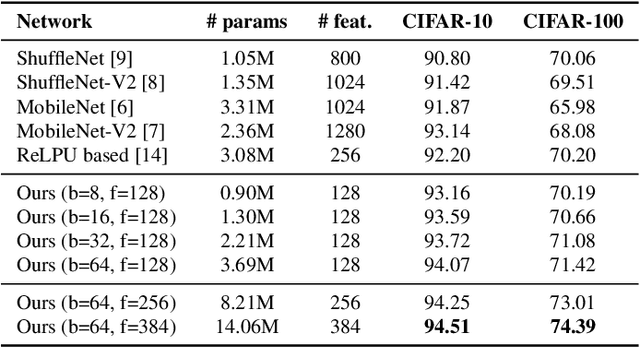
In this paper, we propose a new convolutional layer called Depthwise-STFT Separable layer that can serve as an alternative to the standard depthwise separable convolutional layer. The construction of the proposed layer is inspired by the fact that the Fourier coefficients can accurately represent important features such as edges in an image. It utilizes the Fourier coefficients computed (channelwise) in the 2D local neighborhood (e.g., 3x3) of each position of the input map to obtain the feature maps. The Fourier coefficients are computed using 2D Short Term Fourier Transform (STFT) at multiple fixed low frequency points in the 2D local neighborhood at each position. These feature maps at different frequency points are then linearly combined using trainable pointwise (1x1) convolutions. We show that the proposed layer outperforms the standard depthwise separable layer-based models on the CIFAR-10 and CIFAR-100 image classification datasets with reduced space-time complexity.
NUBIA: NeUral Based Interchangeability Assessor for Text Generation
Apr 30, 2020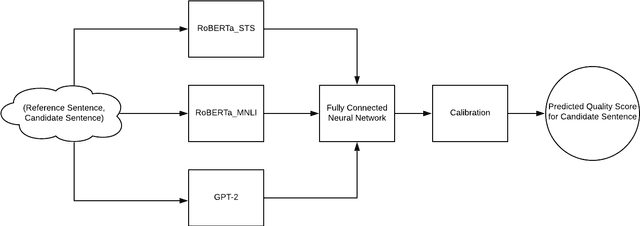

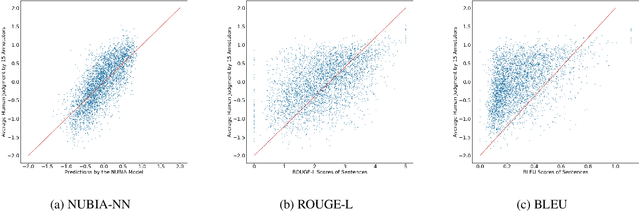
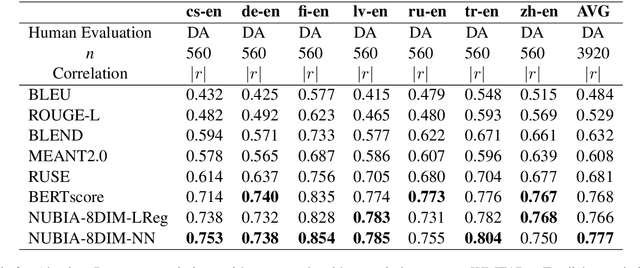
We present NUBIA, a methodology to build automatic evaluation metrics for text generation using only machine learning models as core components. A typical NUBIA model is composed of three modules: a neural feature extractor, an aggregator and a calibrator. We demonstrate an implementation of NUBIA which outperforms metrics currently used to evaluate machine translation, summaries and slightly exceeds/matches state of the art metrics on correlation with human judgement on the WMT segment-level Direct Assessment task, sentence-level ranking and image captioning evaluation. The model implemented is modular, explainable and set to continuously improve over time.
Image classification by visual bag-of-words refinement and reduction
Jan 18, 2015

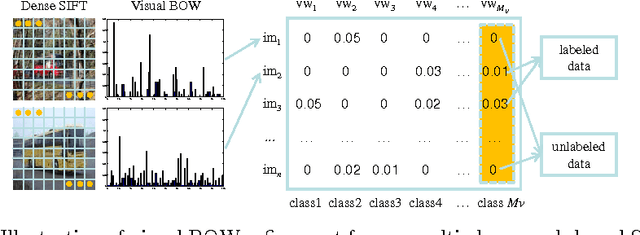

This paper presents a new framework for visual bag-of-words (BOW) refinement and reduction to overcome the drawbacks associated with the visual BOW model which has been widely used for image classification. Although very influential in the literature, the traditional visual BOW model has two distinct drawbacks. Firstly, for efficiency purposes, the visual vocabulary is commonly constructed by directly clustering the low-level visual feature vectors extracted from local keypoints, without considering the high-level semantics of images. That is, the visual BOW model still suffers from the semantic gap, and thus may lead to significant performance degradation in more challenging tasks (e.g. social image classification). Secondly, typically thousands of visual words are generated to obtain better performance on a relatively large image dataset. Due to such large vocabulary size, the subsequent image classification may take sheer amount of time. To overcome the first drawback, we develop a graph-based method for visual BOW refinement by exploiting the tags (easy to access although noisy) of social images. More notably, for efficient image classification, we further reduce the refined visual BOW model to a much smaller size through semantic spectral clustering. Extensive experimental results show the promising performance of the proposed framework for visual BOW refinement and reduction.
STEER : Simple Temporal Regularization For Neural ODEs
Jun 18, 2020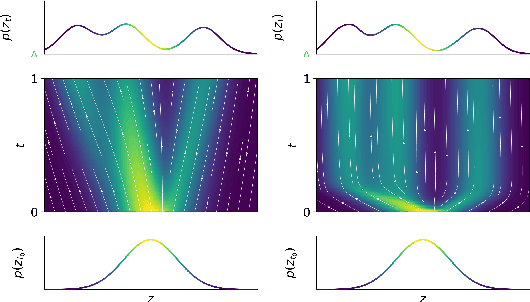
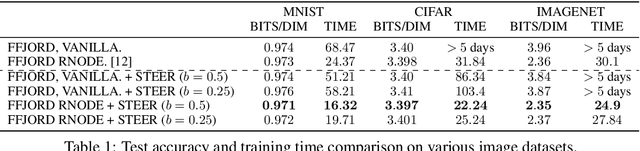
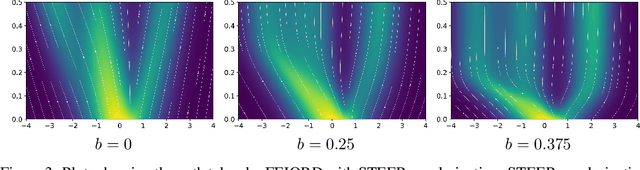
Training Neural Ordinary Differential Equations (ODEs) is often computationally expensive. Indeed, computing the forward pass of such models involves solving an ODE which can become arbitrarily complex during training. Recent works have shown that regularizing the dynamics of the ODE can partially alleviate this. In this paper we propose a new regularization technique: randomly sampling the end time of the ODE during training. The proposed regularization is simple to implement, has negligible overhead and is effective across a wide variety of tasks. Further, the technique is orthogonal to several other methods proposed to regularize the dynamics of ODEs and as such can be used in conjunction with them. We show through experiments on normalizing flows, time series models and image recognition that the proposed regularization can significantly decrease training time and even improve performance over baseline models.
Dialog Policy Learning for Joint Clarification and Active Learning Queries
Jun 09, 2020
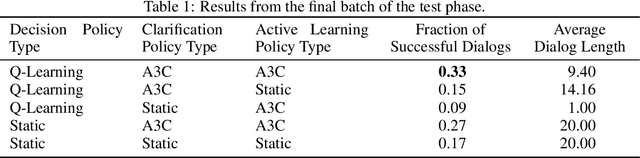

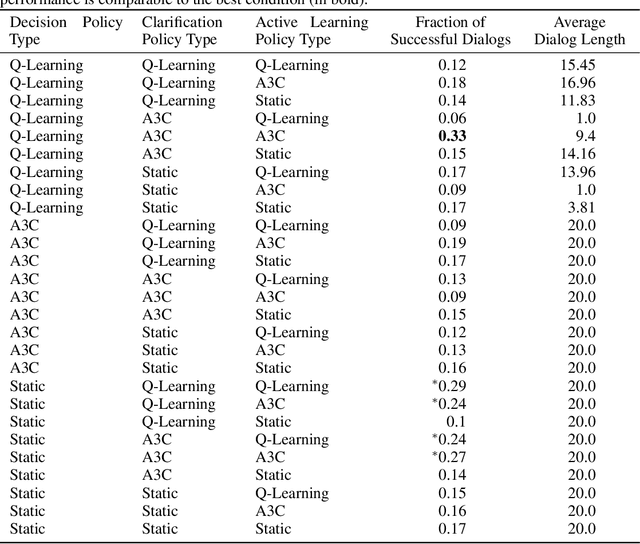
Intelligent systems need to be able to recover from mistakes, resolve uncertainty, and adapt to novel concepts not seen during training. Dialog interaction can enable this by the use of clarifications for correction and resolving uncertainty, and active learning queries to learn new concepts encountered during operation. Prior work on dialog systems has either focused on exclusively learning how to perform clarification/ information seeking, or to perform active learning. In this work, we train a hierarchical dialog policy to jointly perform {\it both} clarification and active learning in the context of an interactive language-based image retrieval task motivated by an on-line shopping application, and demonstrate that jointly learning dialog policies for clarification and active learning is more effective than the use of static dialog policies for one or both of these functions.