 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Effect of Visual Design in Image Classification
Jul 22, 2019
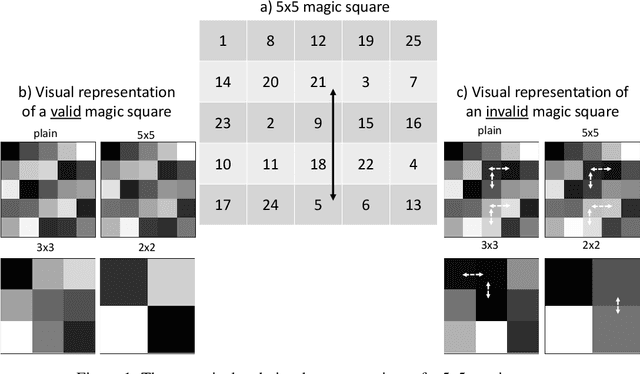
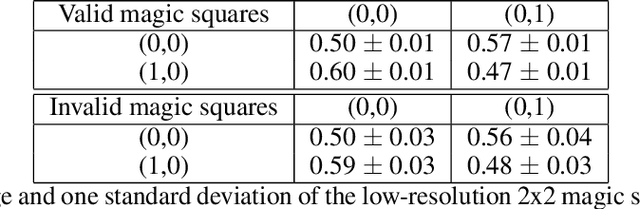
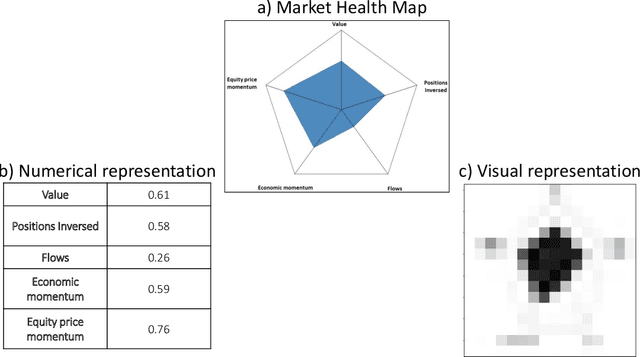
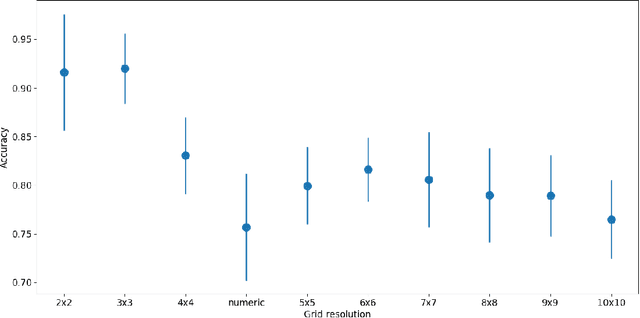
Financial companies continuously analyze the state of the markets to rethink and adjust their investment strategies. While the analysis is done on the digital form of data, decisions are often made based on graphical representations in white papers or presentation slides. In this study, we examine whether binary decisions are better to be decided based on the numeric or the visual representation of the same data. Using two data sets, a matrix of numerical data with spatial dependencies and financial data describing the state of the S&P index, we compare the results of supervised classification based on the original numerical representation and the visual transformation of the same data. We show that, for these data sets, the visual transformation results in higher predictability skill compared to the original form of the data. We suggest thinking of the visual representation of numeric data, effectively, as a combination of dimensional reduction and feature engineering techniques. In particular, if the visual layout encapsulates the full complexity of the data. In this view, thoughtful visual design can guard against overfitting, or introduce new features -- all of which benefit the learning process, and effectively lead to better recognition of meaningful patterns.
Fast Interactive Image Retrieval using large-scale unlabeled data
Feb 12, 2018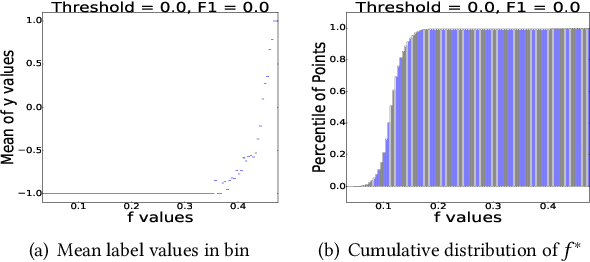
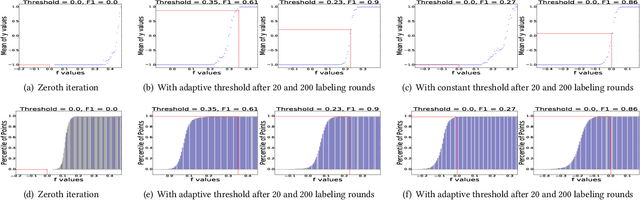
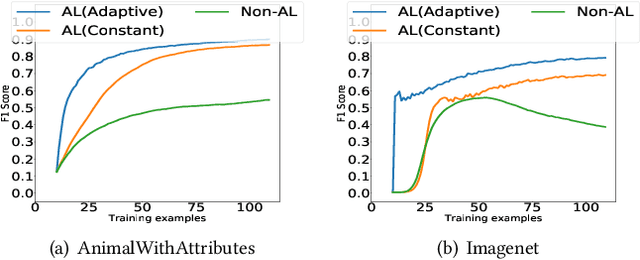
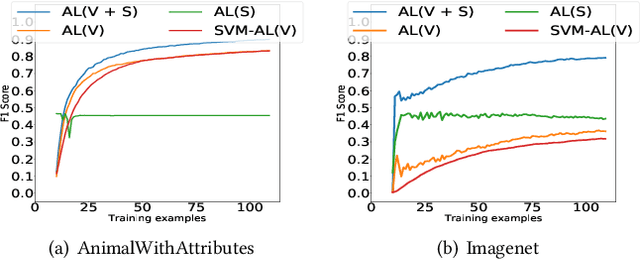
An interactive image retrieval system learns which images in the database belong to a user's query concept, by analyzing the example images and feedback provided by the user. The challenge is to retrieve the relevant images with minimal user interaction. In this work, we propose to solve this problem by posing it as a binary classification task of classifying all images in the database as being relevant or irrelevant to the user's query concept. Our method combines active learning with graph-based semi-supervised learning (GSSL) to tackle this problem. Active learning reduces the number of user interactions by querying the labels of the most informative points and GSSL allows to use abundant unlabeled data along with the limited labeled data provided by the user. To efficiently find the most informative point, we use an uncertainty sampling based method that queries the label of the point nearest to the decision boundary of the classifier. We estimate this decision boundary using our heuristic of adaptive threshold. To utilize huge volumes of unlabeled data we use an efficient approximation based method that reduces the complexity of GSSL from $O(n^3)$ to $O(n)$, making GSSL scalable. We make the classifier robust to the diversity and noisy labels associated with images in large databases by incorporating information from multiple modalities such as visual information extracted from deep learning based models and semantic information extracted from the WordNet. High F1 scores within few relevance feedback rounds in our experiments with concepts defined on AnimalWithAttributes and Imagenet (1.2 million images) datasets indicate the effectiveness and scalability of our approach.
When Weak Becomes Strong: Robust Quantification of White Matter Hyperintensities in Brain MRI scans
Apr 12, 2020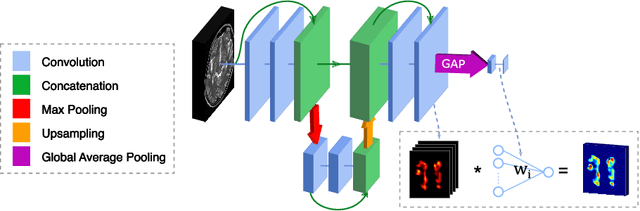
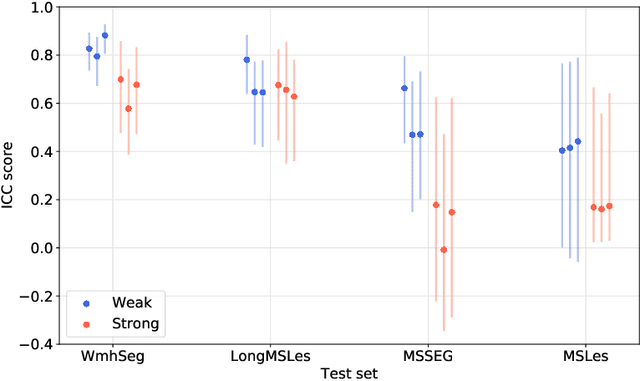
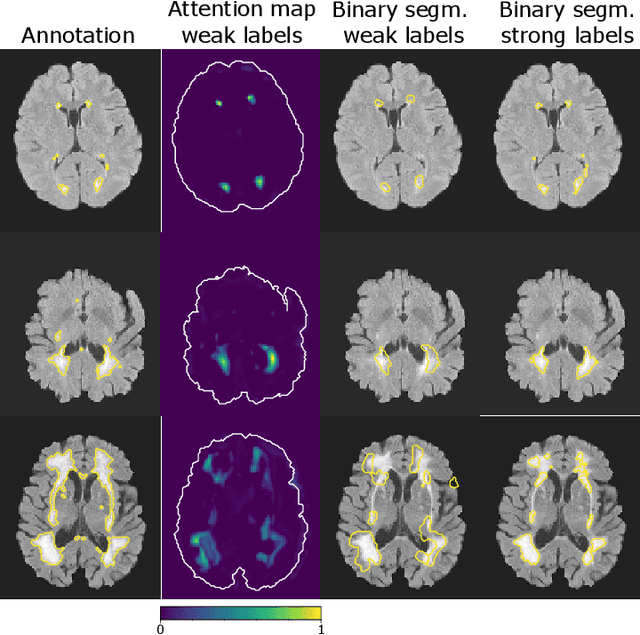
To measure the volume of specific image structures, a typical approach is to first segment those structures using a neural network trained on voxel-wise (strong) labels and subsequently compute the volume from the segmentation. A more straightforward approach would be to predict the volume directly using a neural network based regression approach, trained on image-level (weak) labels indicating volume. In this article, we compared networks optimized with weak and strong labels, and study their ability to generalize to other datasets. We experimented with white matter hyperintensity (WMH) volume prediction in brain MRI scans. Neural networks were trained on a large local dataset and their performance was evaluated on four independent public datasets. We showed that networks optimized using only weak labels reflecting WMH volume generalized better for WMH volume prediction than networks optimized with voxel-wise segmentations of WMH. The attention maps of networks trained with weak labels did not seem to delineate WMHs, but highlighted instead areas with smooth contours around or near WMHs. By correcting for possible confounders we showed that networks trained on weak labels may have learnt other meaningful features that are more suited to generalization to unseen data. Our results suggest that for imaging biomarkers that can be derived from segmentations, training networks to predict the biomarker directly may provide more robust results than solving an intermediate segmentation step.
PrivEdge: From Local to Distributed Private Training and Prediction
Apr 12, 2020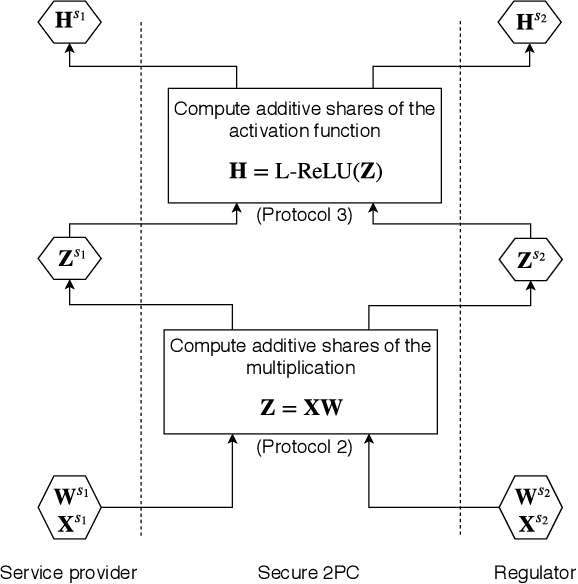


Machine Learning as a Service (MLaaS) operators provide model training and prediction on the cloud. MLaaS applications often rely on centralised collection and aggregation of user data, which could lead to significant privacy concerns when dealing with sensitive personal data. To address this problem, we propose PrivEdge, a technique for privacy-preserving MLaaS that safeguards the privacy of users who provide their data for training, as well as users who use the prediction service. With PrivEdge, each user independently uses their private data to locally train a one-class reconstructive adversarial network that succinctly represents their training data. As sending the model parameters to the service provider in the clear would reveal private information, PrivEdge secret-shares the parameters among two non-colluding MLaaS providers, to then provide cryptographically private prediction services through secure multi-party computation techniques. We quantify the benefits of PrivEdge and compare its performance with state-of-the-art centralised architectures on three privacy-sensitive image-based tasks: individual identification, writer identification, and handwritten letter recognition. Experimental results show that PrivEdge has high precision and recall in preserving privacy, as well as in distinguishing between private and non-private images. Moreover, we show the robustness of PrivEdge to image compression and biased training data. The source code is available at https://github.com/smartcameras/PrivEdge.
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Jul 26, 2020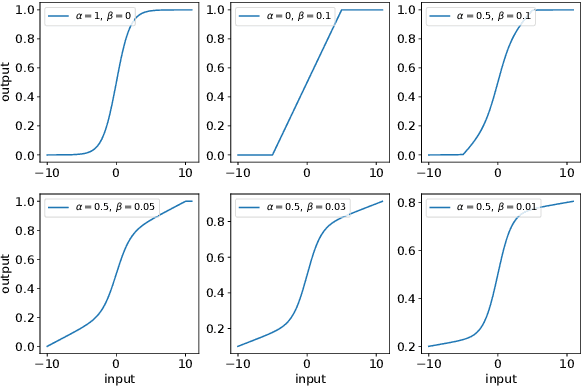
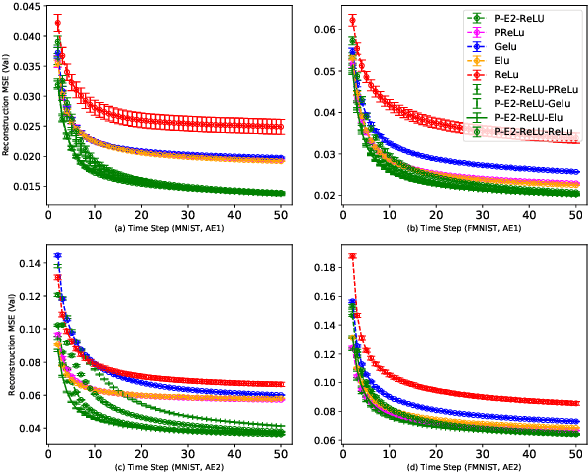
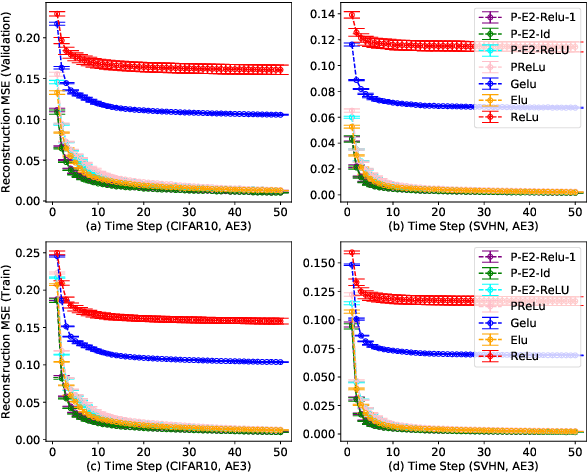
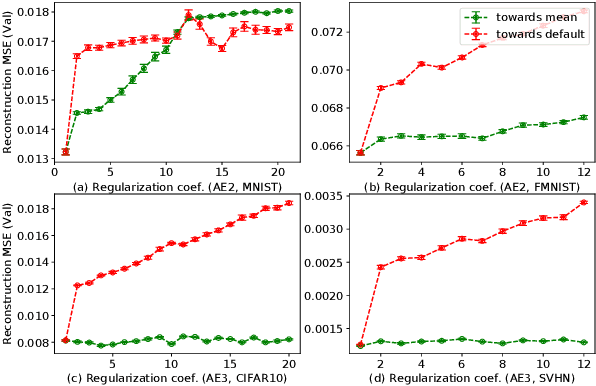
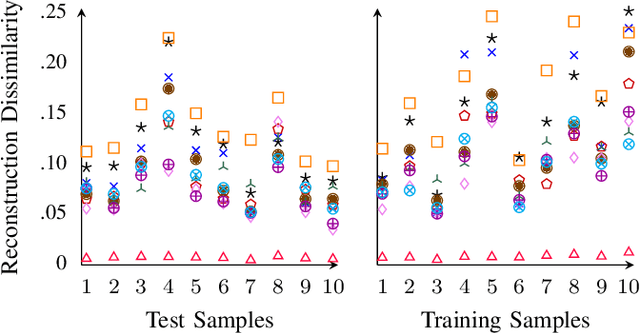
Activation in deep neural networks is fundamental to achieving non-linear mappings. Traditional studies mainly focus on finding fixed activations for a particular set of learning tasks or model architectures. The research on flexible activation is quite limited in both designing philosophy and application scenarios. In this study, three principles of choosing flexible activation components are proposed and a general combined form of flexible activation functions is implemented. Based on this, a novel family of flexible activation functions that can replace sigmoid or tanh in LSTM cells are implemented, as well as a new family by combining ReLU and ELUs. Also, two new regularisation terms based on assumptions as prior knowledge are introduced. It has been shown that LSTM models with proposed flexible activations P-Sig-Ramp provide significant improvements in time series forecasting, while the proposed P-E2-ReLU achieves better and more stable performance on lossy image compression tasks with convolutional auto-encoders. In addition, the proposed regularization terms improve the convergence, performance and stability of the models with flexible activation functions.
Automatic Image De-fencing System
Oct 21, 2016
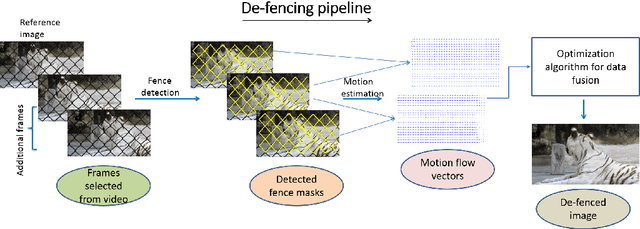


Tourists and Wild-life photographers are often hindered in capturing their cherished images or videos by a fence that limits accessibility to the scene of interest. The situation has been exacerbated by growing concerns of security at public places and a need exists to provide a tool that can be used for post-processing such fenced videos to produce a de-fenced image. There are several challenges in this problem, we identify them as Robust detection of fence/occlusions and Estimating pixel motion of background scenes and Filling in the fence/occlusions by utilizing information in multiple frames of the input video. In this work, we aim to build an automatic post-processing tool that can efficiently rid the input video of occlusion artifacts like fences. Our work is distinguished by two major contributions. The first is the introduction of learning based technique to detect the fences patterns with complicated backgrounds. The second is the formulation of objective function and further minimization through loopy belief propagation to fill-in the fence pixels. We observe that grids of Histogram of oriented gradients descriptor using Support vector machines based classifier significantly outperforms detection accuracy of texels in a lattice. We present results of experiments using several real-world videos to demonstrate the effectiveness of the proposed fence detection and de-fencing algorithm.
Can AI help in screening Viral and COVID-19 pneumonia?
Mar 29, 2020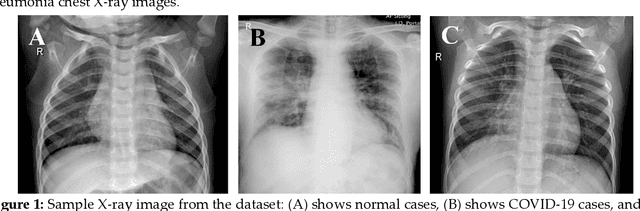
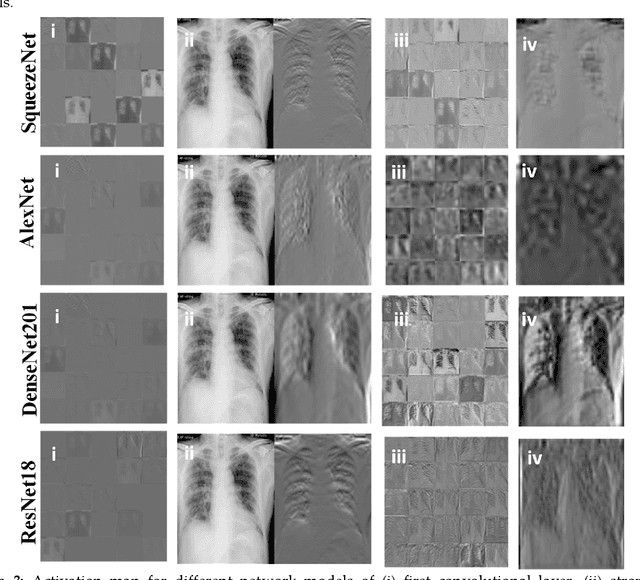
Coronavirus disease (COVID-19) is a pandemic disease, which has already infected more than half a million people and caused fatalities of above 30 thousand. The aim of this paper is to automatically detect COVID-19 pneumonia patients using digital x-ray images while maximizing the accuracy in detection using image pre-processing and deep-learning techniques. A public database was created by the authors using three public databases and also by collecting images from recently published articles. The database contains a mixture of 190 COVID-19, 1345 viral pneumonia, and 1341 normal chest x-ray images. An image augmented training set was created with 2500 images of each category for training and validating four different pre-trained deep Convolutional Neural Networks (CNNs). These networks were tested for the classification of two different schemes (normal and COVID-19 pneumonia; normal, viral and COVID-19 pneumonia). The classification accuracy, sensitivity, specificity and precision for both the schemes were 98.3%, 96.7%, 100%, 100% and 98.3%, 96.7%, 99%, 100%, respectively. The high accuracy of this computer-aided diagnostic tool can significantly improve the speed and accuracy of diagnosing cases with COVID-19. This would be highly useful in this pandemic where disease burden and need for preventive measures are at odds with available resources.
Combining 3D Model Contour Energy and Keypoints for Object Tracking
Feb 04, 2020

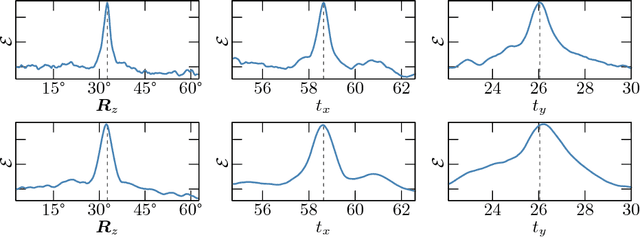

We present a new combined approach for monocular model-based 3D tracking. A preliminary object pose is estimated by using a keypoint-based technique. The pose is then refined by optimizing the contour energy function. The energy determines the degree of correspondence between the contour of the model projection and the image edges. It is calculated based on both the intensity and orientation of the raw image gradient. For optimization, we propose a technique and search area constraints that allow overcoming the local optima and taking into account information obtained through keypoint-based pose estimation. Owing to its combined nature, our method eliminates numerous issues of keypoint-based and edge-based approaches. We demonstrate the efficiency of our method by comparing it with state-of-the-art methods on a public benchmark dataset that includes videos with various lighting conditions, movement patterns, and speed.
Multi-scale Interaction for Real-time LiDAR Data Segmentation on an Embedded Platform
Aug 20, 2020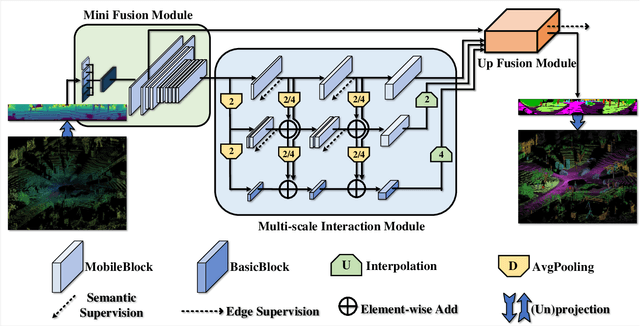
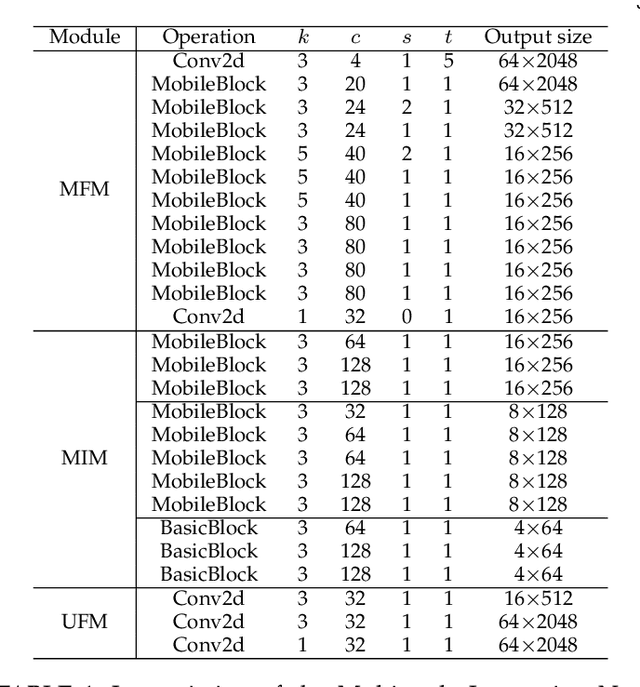
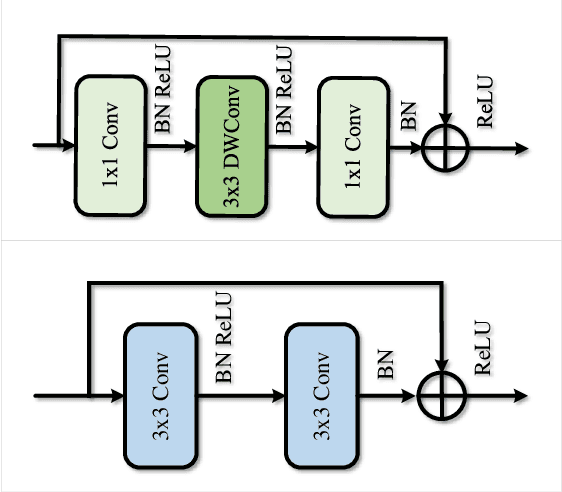

Real-time semantic segmentation of LiDAR data is crucial for autonomously driving vehicles, which are usually equipped with an embedded platform and have limited computational resources. Approaches that operate directly on the point cloud use complex spatial aggregation operations, which are very expensive and difficult to optimize for embedded platforms. They are therefore not suitable for real-time applications with embedded systems. As an alternative, projection-based methods are more efficient and can run on embedded platforms. However, the current state-of-the-art projection-based methods do not achieve the same accuracy as point-based methods and use millions of parameters. In this paper, we therefore propose a projection-based method, called Multi-scale Interaction Network (MINet), which is very efficient and accurate. The network uses multiple paths with different scales and balances the computational resources between the scales. Additional dense interactions between the scales avoid redundant computations and make the network highly efficient. The proposed network outperforms point-based, image-based, and projection-based methods in terms of accuracy, number of parameters, and runtime. Moreover, the network processes more than 24 scans per second on an embedded platform, which is higher than the framerates of LiDAR sensors. The network is therefore suitable for autonomous vehicles.
High Accurate Unhealthy Leaf Detection
Aug 14, 2019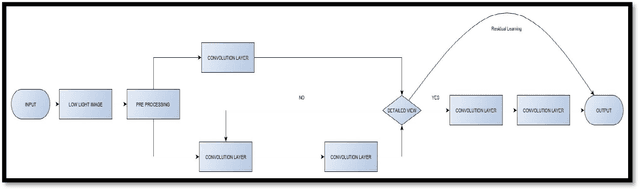



India is an agriculture-dependent country. As we all know that farming is the backbone of our country it is our responsibility to preserve the crops. However, we cannot stop the destruction of crops by natural calamities at least we have to try to protect our crops from diseases. To, detect a plant disease we need a fast automatic way. So, this paper presents a model to identify the particular disease of plant leaves at early stages so that we can prevent or take a remedy to stop spreading of the disease. This proposed model is made into five sessions. Image preprocessing includes the enhancement of the low light image done using inception modules in CNN. Low-resolution image enhancement is done using an Adversarial Neural Network. This also includes Conversion of RGB Image to YCrCb color space. Next, this paper presents a methodology for image segmentation which is an important aspect for identifying the disease symptoms. This segmentation is done using the genetic algorithm. Due to this process the segmentation of the leaf Image this helps in detection of the leaf mage automatically and classifying. Texture extraction is done using the statistical model called GLCM and finally, the classification of the diseases is done using the SVM using Different Kernels with the high accuracy.