 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Including Images into Message Veracity Assessment in Social Media
Jul 20, 2020

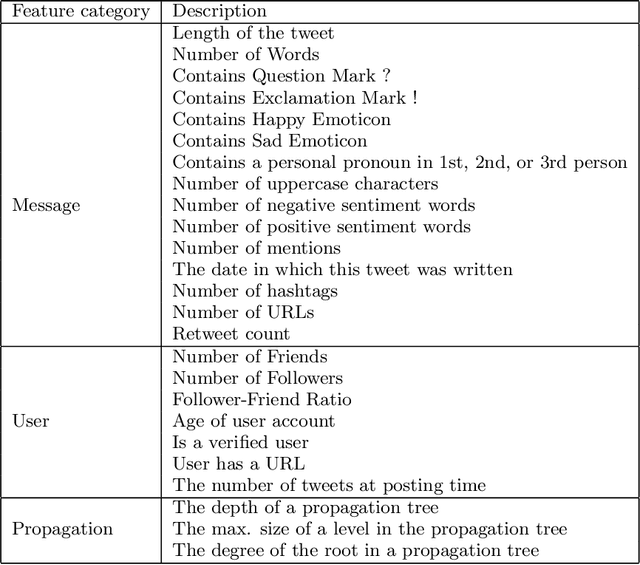
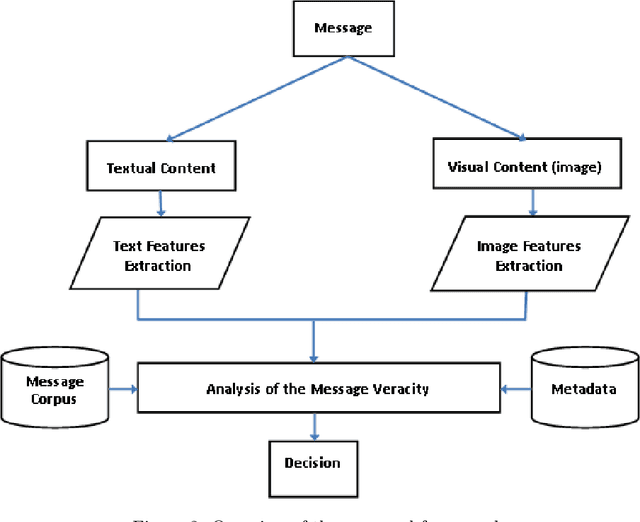

The extensive use of social media in the diffusion of information has also laid a fertile ground for the spread of rumors, which could significantly affect the credibility of social media. An ever-increasing number of users post news including, in addition to text, multimedia data such as images and videos. Yet, such multimedia content is easily editable due to the broad availability of simple and effective image and video processing tools. The problem of assessing the veracity of social network posts has attracted a lot of attention from researchers in recent years. However, almost all previous works have focused on analyzing textual contents to determine veracity, while visual contents, and more particularly images, remains ignored or little exploited in the literature. In this position paper, we propose a framework that explores two novel ways to assess the veracity of messages published on social networks by analyzing the credibility of both their textual and visual contents.
Grounding Language in Play
May 15, 2020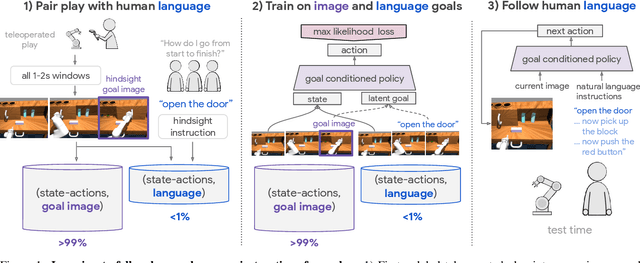
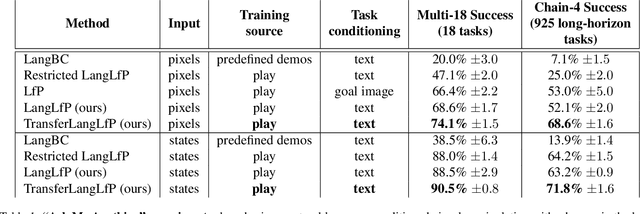
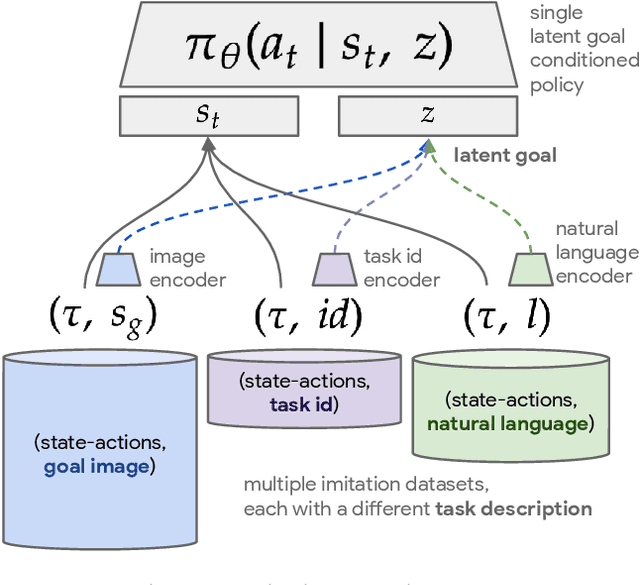

Natural language is perhaps the most versatile and intuitive way for humans to communicate tasks to a robot. Prior work on Learning from Play (LfP) [Lynch et al, 2019] provides a simple approach for learning a wide variety of robotic behaviors from general sensors. However, each task must be specified with a goal image---something that is not practical in open-world environments. In this work we present a simple and scalable way to condition policies on human language instead. We extend LfP by pairing short robot experiences from play with relevant human language after-the-fact. To make this efficient, we introduce multicontext imitation, which allows us to train a single agent to follow image or language goals, then use just language conditioning at test time. This reduces the cost of language pairing to less than 1% of collected robot experience, with the majority of control still learned via self-supervised imitation. At test time, a single agent trained in this manner can perform many different robotic manipulation skills in a row in a 3D environment, directly from images, and specified only with natural language (e.g. "open the drawer...now pick up the block...now press the green button..."). Finally, we introduce a simple technique that transfers knowledge from large unlabeled text corpora to robotic learning. We find that transfer significantly improves downstream robotic manipulation. It also allows our agent to follow thousands of novel instructions at test time in zero shot, in 16 different languages. See videos of our experiments at language-play.github.io
SeCo: Exploring Sequence Supervision for Unsupervised Representation Learning
Aug 03, 2020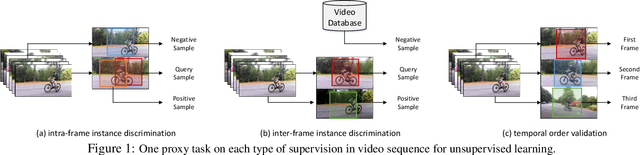
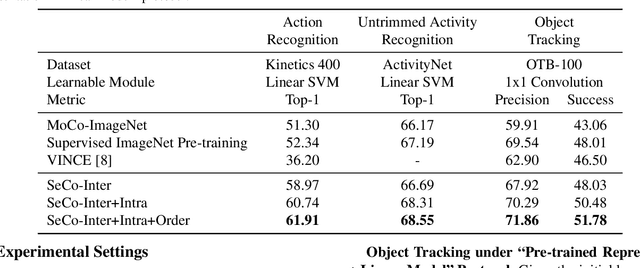
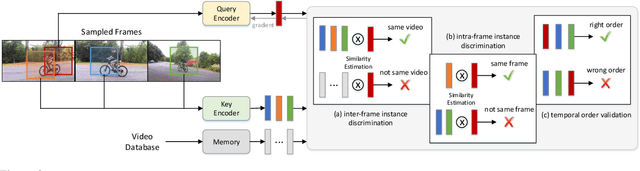
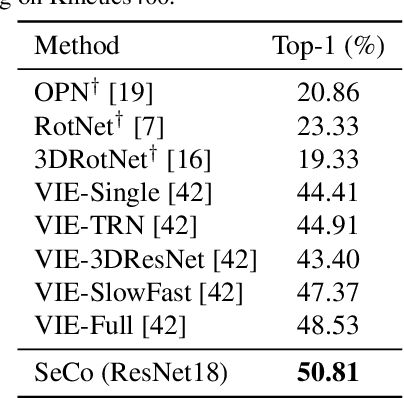
A steady momentum of innovations and breakthroughs has convincingly pushed the limits of unsupervised image representation learning. Compared to static 2D images, video has one more dimension (time). The inherent supervision existing in such sequential structure offers a fertile ground for building unsupervised learning models. In this paper, we compose a trilogy of exploring the basic and generic supervision in the sequence from spatial, spatiotemporal and sequential perspectives. We materialize the supervisory signals through determining whether a pair of samples is from one frame or from one video, and whether a triplet of samples is in the correct temporal order. We uniquely regard the signals as the foundation in contrastive learning and derive a particular form named Sequence Contrastive Learning (SeCo). SeCo shows superior results under the linear protocol on action recognition (Kinetics), untrimmed activity recognition (ActivityNet) and object tracking (OTB-100). More remarkably, SeCo demonstrates considerable improvements over recent unsupervised pre-training techniques, and leads the accuracy by 2.96% and 6.47% against fully-supervised ImageNet pre-training in action recognition task on UCF101 and HMDB51, respectively.
Frame-To-Frame Consistent Semantic Segmentation
Aug 03, 2020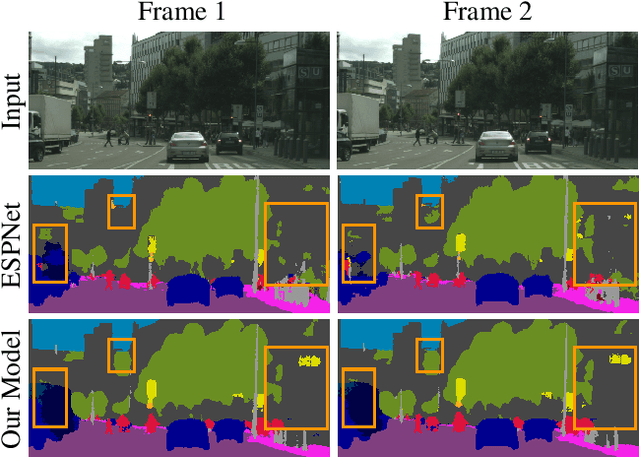
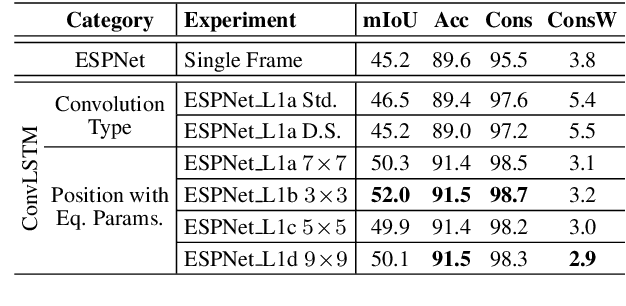
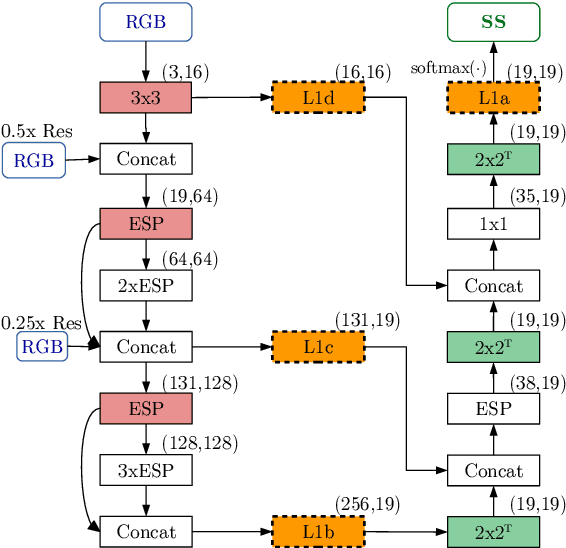
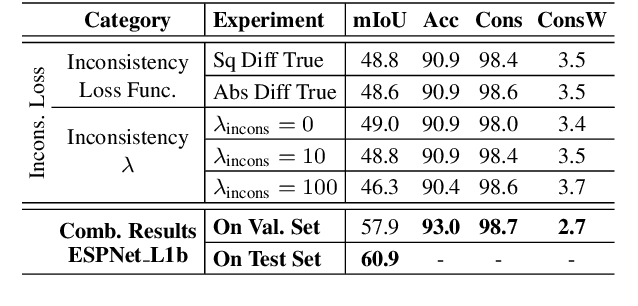
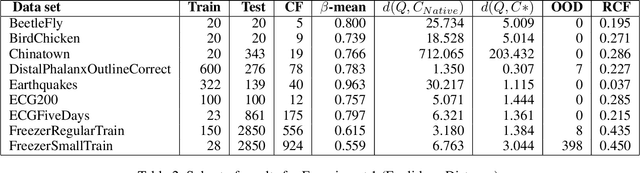
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing.
Instance-Based Counterfactual Explanations for Time Series Classification
Sep 28, 2020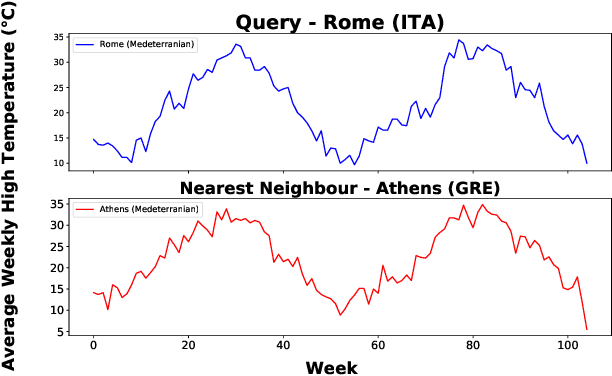

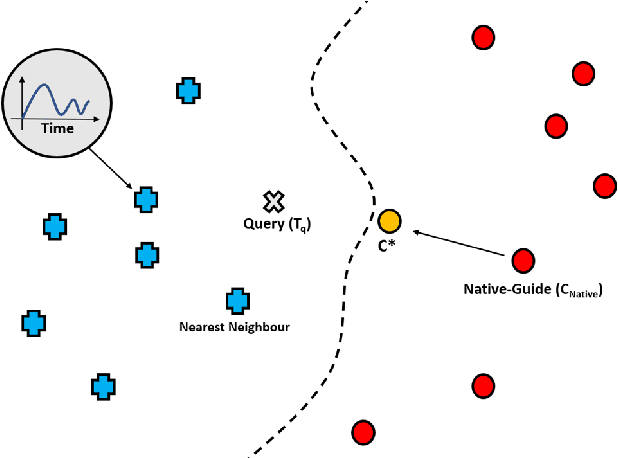
In recent years there has been a cascade of research in attempting to make AI systems more interpretable by providing explanations; so-called Explainable AI (XAI). Most of this research has dealt with the challenges that arise in explaining black-box deep learning systems in classification and regression tasks, with a focus on tabular and image data; for example, there is a rich seam of work on post-hoc counterfactual explanations for a variety of black-box classifiers (e.g., when a user is refused a loan, the counterfactual explanation tells the user about the conditions under which they would get the loan). However, less attention has been paid to the parallel interpretability challenges arising in AI systems dealing with time series data. This paper advances a novel technique, called Native-Guide, for the generation of proximal and plausible counterfactual explanations for instance-based time series classification tasks (e.g., where users are provided with alternative time series to explain how a classification might change). The Native-Guide method retrieves and uses native in-sample counterfactuals that already exist in the training data as "guides" for perturbation in time series counterfactual generation. This method can be coupled with both Euclidean and Dynamic Time Warping (DTW) distance measures. After illustrating the technique on a case study involving a climate classification task, we reported on a comprehensive series of experiments on both real-world and synthetic data sets from the UCR archive. These experiments provide computational evidence of the quality of the counterfactual explanations generated.
Object-Aware Centroid Voting for Monocular 3D Object Detection
Jul 20, 2020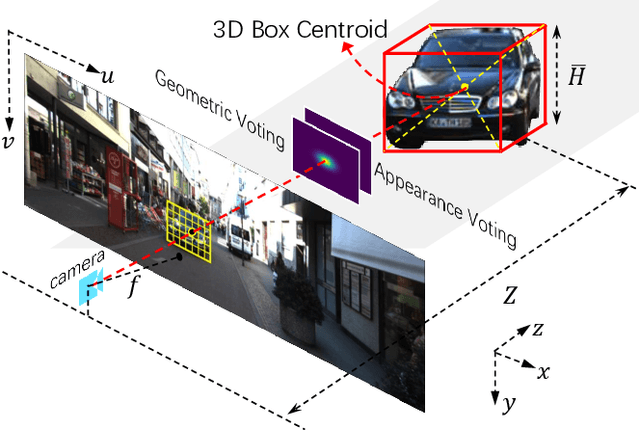
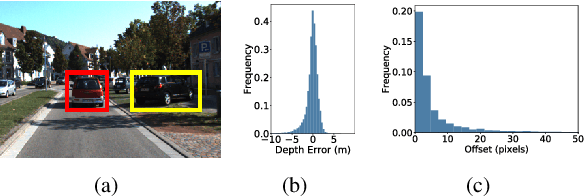
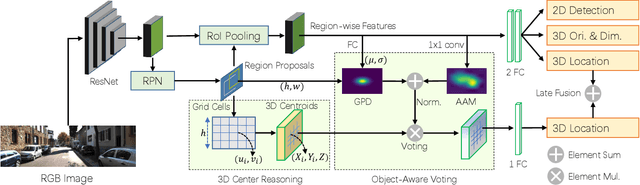
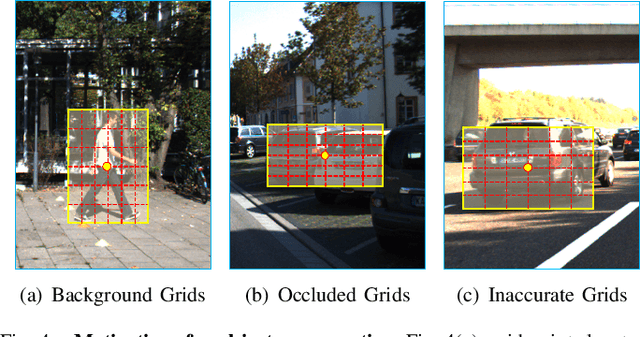
Monocular 3D object detection aims to detect objects in a 3D physical world from a single camera. However, recent approaches either rely on expensive LiDAR devices, or resort to dense pixel-wise depth estimation that causes prohibitive computational cost. In this paper, we propose an end-to-end trainable monocular 3D object detector without learning the dense depth. Specifically, the grid coordinates of a 2D box are first projected back to 3D space with the pinhole model as 3D centroids proposals. Then, a novel object-aware voting approach is introduced, which considers both the region-wise appearance attention and the geometric projection distribution, to vote the 3D centroid proposals for 3D object localization. With the late fusion and the predicted 3D orientation and dimension, the 3D bounding boxes of objects can be detected from a single RGB image. The method is straightforward yet significantly superior to other monocular-based methods. Extensive experimental results on the challenging KITTI benchmark validate the effectiveness of the proposed method.
One Weight Bitwidth to Rule Them All
Aug 28, 2020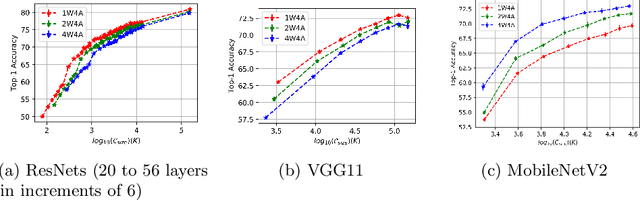

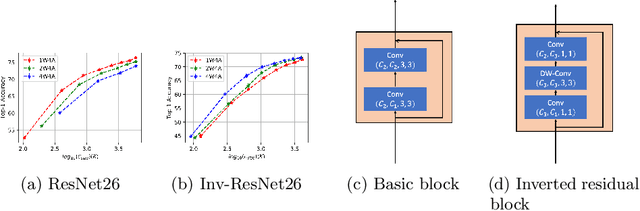
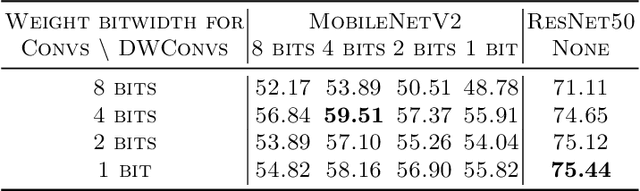
Weight quantization for deep ConvNets has shown promising results for applications such as image classification and semantic segmentation and is especially important for applications where memory storage is limited. However, when aiming for quantization without accuracy degradation, different tasks may end up with different bitwidths. This creates complexity for software and hardware support and the complexity accumulates when one considers mixed-precision quantization, in which case each layer's weights use a different bitwidth. Our key insight is that optimizing for the least bitwidth subject to no accuracy degradation is not necessarily an optimal strategy. This is because one cannot decide optimality between two bitwidths if one has a smaller model size while the other has better accuracy. In this work, we take the first step to understand if some weight bitwidth is better than others by aligning all to the same model size using a width-multiplier. Under this setting, somewhat surprisingly, we show that using a single bitwidth for the whole network can achieve better accuracy compared to mixed-precision quantization targeting zero accuracy degradation when both have the same model size. In particular, our results suggest that when the number of channels becomes a target hyperparameter, a single weight bitwidth throughout the network shows superior results for model compression.
The Criminality From Face Illusion
Jun 06, 2020
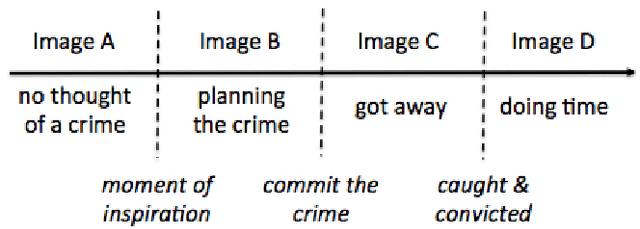

The automatic analysis of face images can generate predictions about a person's gender, age, race, facial expression, body mass index, and various other indices and conditions. A few recent publications have claimed success in analyzing an image of a person's face in order to predict the person's status as Criminal / Non-Criminal. Predicting criminality from face may initially seem similar to other facial analytics, but we argue that attempts to create a criminality-from-face algorithm are necessarily doomed to fail, that apparently promising experimental results in recent publications are an illusion resulting from inadequate experimental design, and that there is potentially a large social cost to belief in the criminality from face illusion.
Residual-Recursion Autoencoder for Shape Illustration Images
Feb 06, 2020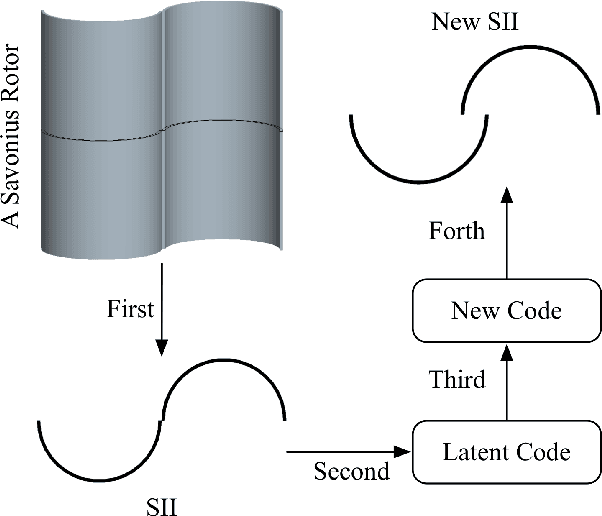
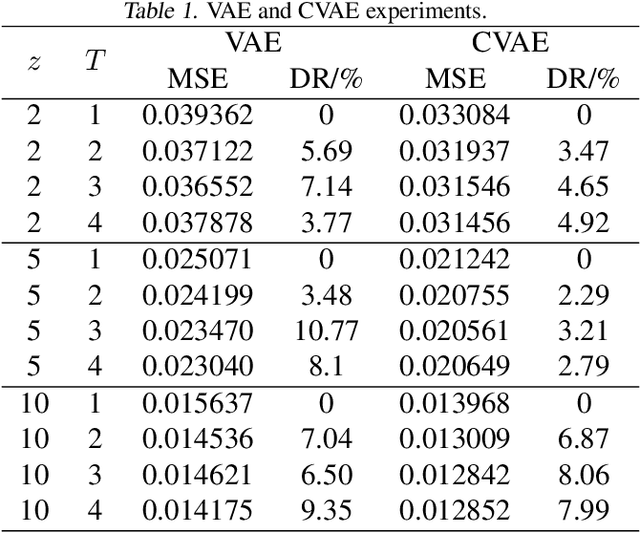
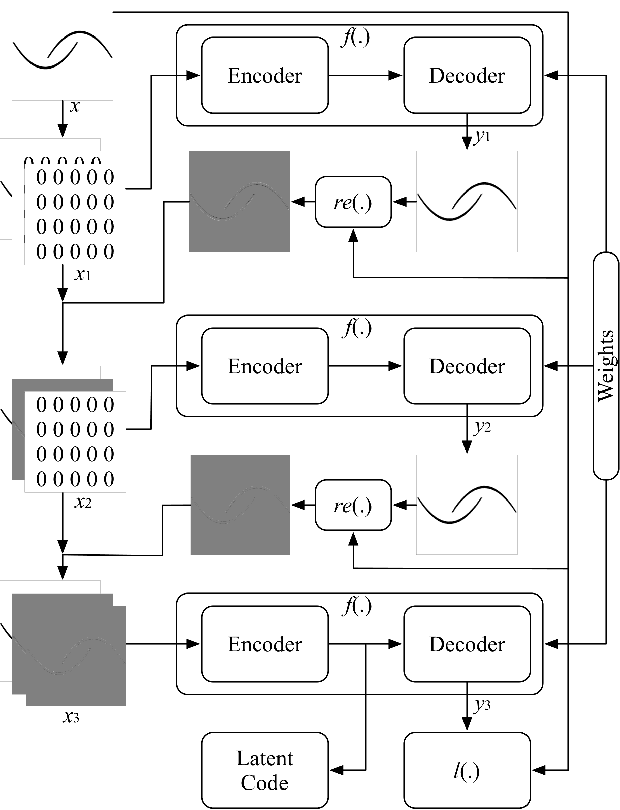
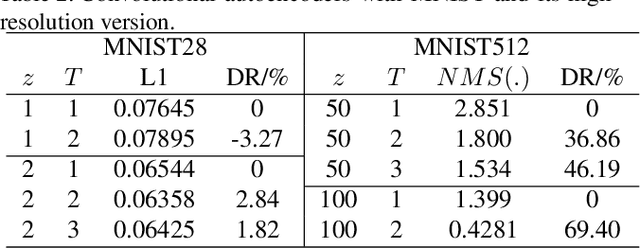
Shape illustration images (SIIs) are common and important in describing the cross-sections of industrial products. Same as MNIST, the handwritten digit images, SIIs are gray or binary and containing shapes that are surrounded by large areas of blanks. In this work, Residual-Recursion Autoencoder (RRAE) has been proposed to extract low-dimensional features from SIIs while maintaining reconstruction accuracy as high as possible. RRAE will try to reconstruct the original image several times and recursively fill the latest residual image to the reserved channel of the encoder's input before the next trial of reconstruction. As a kind of neural network training framework, RRAE can wrap over other autoencoders and increase their performance. From experiment results, the reconstruction loss is decreased by 86.47% for convolutional autoencoder with high-resolution SIIs, 10.77% for variational autoencoder and 8.06% for conditional variational autoencoder with MNIST.
Adaptive Densely Connected Super-Resolution Reconstruction
Dec 18, 2019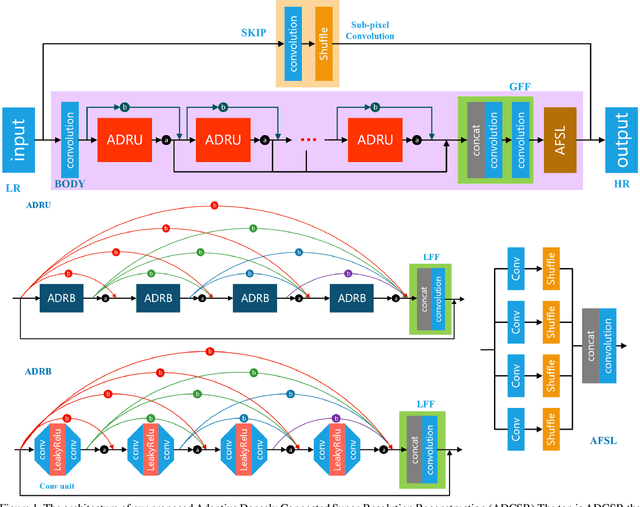
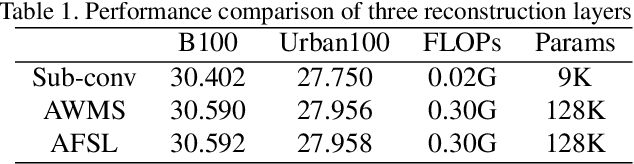
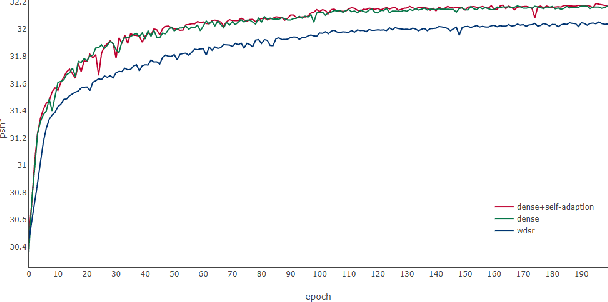
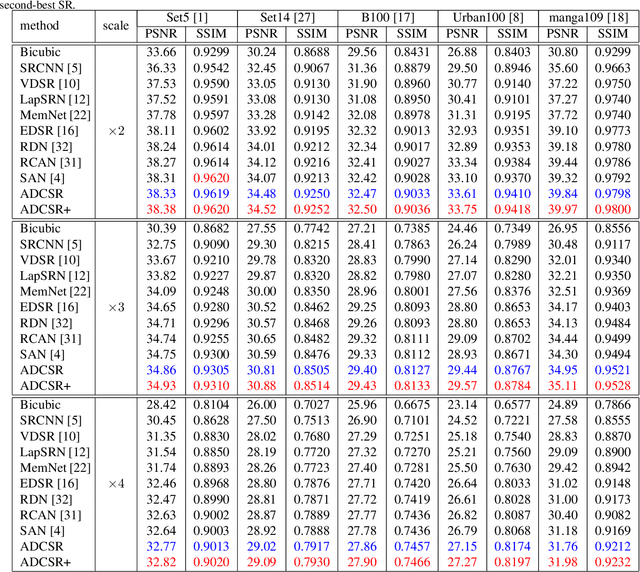
For a better performance in single image super-resolution(SISR), we present an image super-resolution algorithm based on adaptive dense connection (ADCSR). The algorithm is divided into two parts: BODY and SKIP. BODY improves the utilization of convolution features through adaptive dense connections. Also, we develop an adaptive sub-pixel reconstruction layer (AFSL) to reconstruct the features of the BODY output. We pre-trained SKIP to make BODY focus on high-frequency feature learning. The comparison of PSNR, SSIM, and visual effects verify the superiority of our method to the state-of-the-art algorithms.