 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Network for Low-Memory IoT Devices and MNIST Image Recognition Using Kernels Based on Logistic Map
Jun 04, 2020
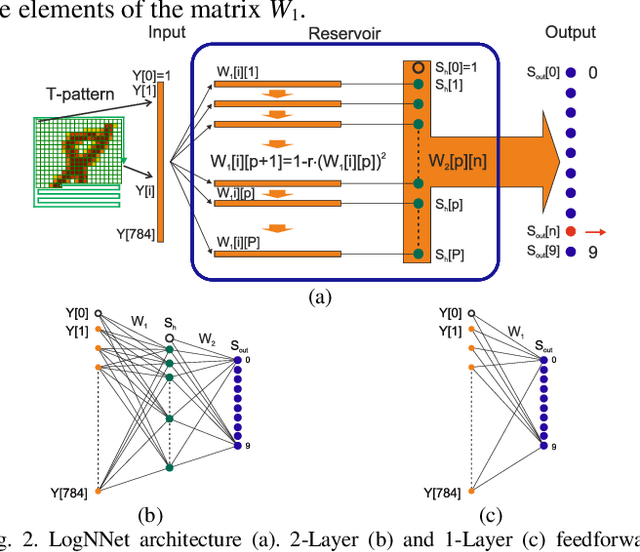
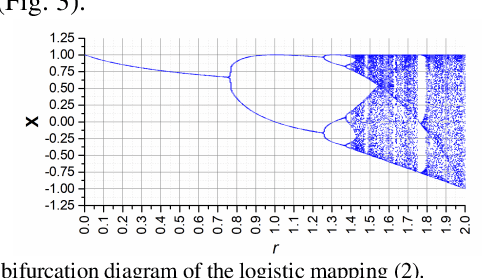
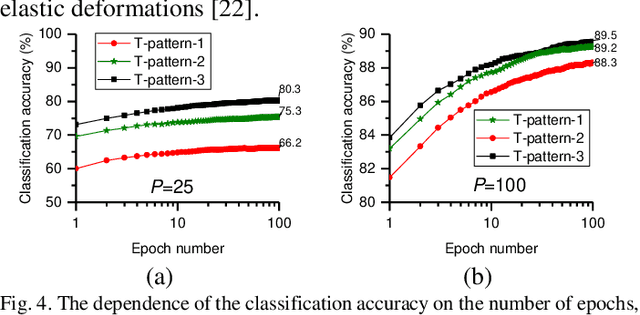
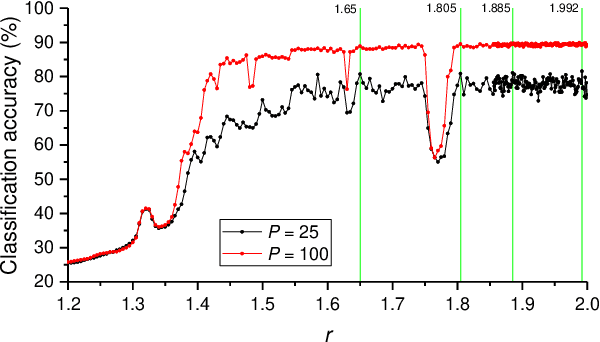
The study presents a neural network, which uses filters based on logistic mapping (LogNNet). LogNNet has a feedforward network structure, but possesses the properties of reservoir neural networks. The input weight matrix, set by a recurrent logistic mapping, forms the kernels that transform the input space to the higher-dimensional feature space. The most effective MNIST handwritten digit recognition occurs under chaotic behavior of logistic map. An advantage of LogNNet implementation on IoT Devices is the significant savings in used memory (more than 10 times) compared to other neural networks. The presented network architecture uses an array of weights with a total memory size from 1 kB to 29 kB and achieves a classification accuracy of 80.3-96.3 %.
Noise Robust Generative Adversarial Networks
Nov 26, 2019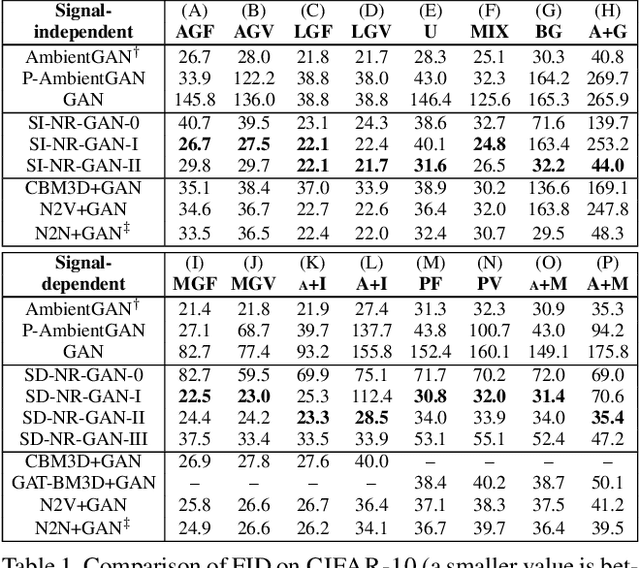

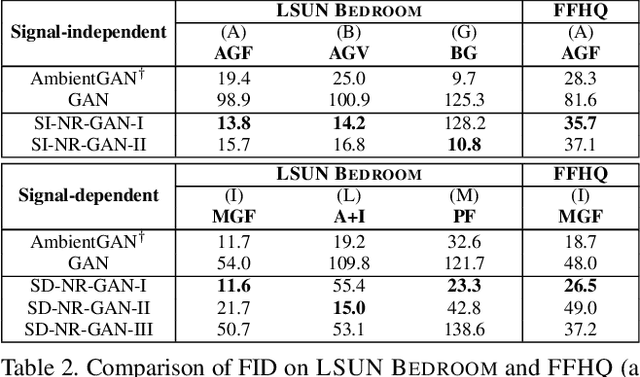
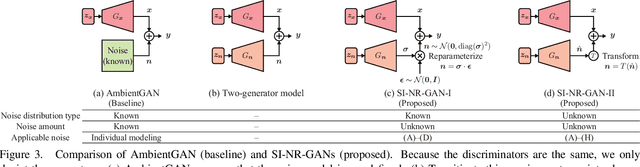
Generative adversarial networks (GANs) are neural networks that learn data distributions through adversarial training. In intensive studies, recent GANs have shown promising results for reproducing training data. However, in spite of noise, they reproduce data with fidelity. As an alternative, we propose a novel family of GANs called noise-robust GANs (NR-GANs), which can learn a clean image generator even when training data are noisy. In particular, NR-GANs can solve this problem without having complete noise information (e.g., the noise distribution type, noise amount, or signal-noise relation). To achieve this, we introduce a noise generator and train it along with a clean image generator. As it is difficult to generate an image and a noise separately without constraints, we propose distribution and transformation constraints that encourage the noise generator to capture only the noise-specific components. In particular, considering such constraints under different assumptions, we devise two variants of NR-GANs for signal-independent noise and three variants of NR-GANs for signal-dependent noise. On three benchmark datasets, we demonstrate the effectiveness of NR-GANs in noise robust image generation. Furthermore, we show the applicability of NR-GANs in image denoising.
Passport-aware Normalization for Deep Model Protection
Nov 03, 2020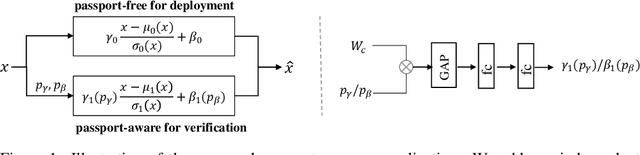

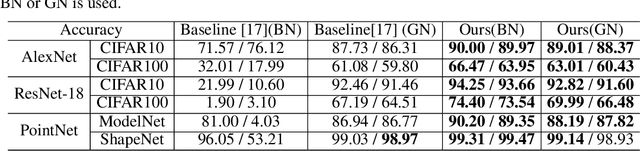
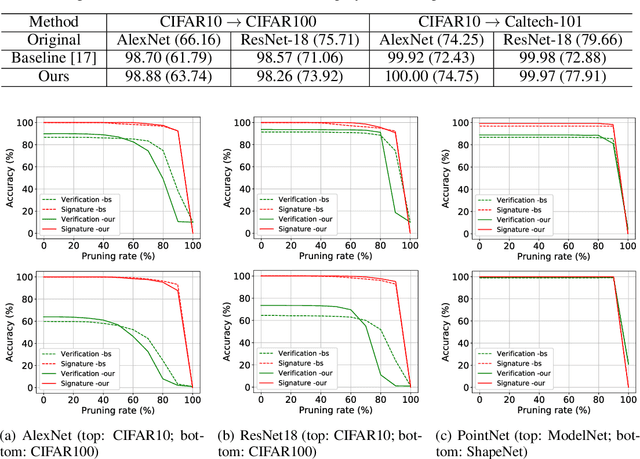
Despite tremendous success in many application scenarios, deep learning faces serious intellectual property (IP) infringement threats. Considering the cost of designing and training a good model, infringements will significantly infringe the interests of the original model owner. Recently, many impressive works have emerged for deep model IP protection. However, they either are vulnerable to ambiguity attacks, or require changes in the target network structure by replacing its original normalization layers and hence cause significant performance drops. To this end, we propose a new passport-aware normalization formulation, which is generally applicable to most existing normalization layers and only needs to add another passport-aware branch for IP protection. This new branch is jointly trained with the target model but discarded in the inference stage. Therefore it causes no structure change in the target model. Only when the model IP is suspected to be stolen by someone, the private passport-aware branch is added back for ownership verification. Through extensive experiments, we verify its effectiveness in both image and 3D point recognition models. It is demonstrated to be robust not only to common attack techniques like fine-tuning and model compression, but also to ambiguity attacks. By further combining it with trigger-set based methods, both black-box and white-box verification can be achieved for enhanced security of deep learning models deployed in real systems. Code can be found at https://github.com/ZJZAC/Passport-aware-Normalization.
xUnit: Learning a Spatial Activation Function for Efficient Image Restoration
Mar 25, 2018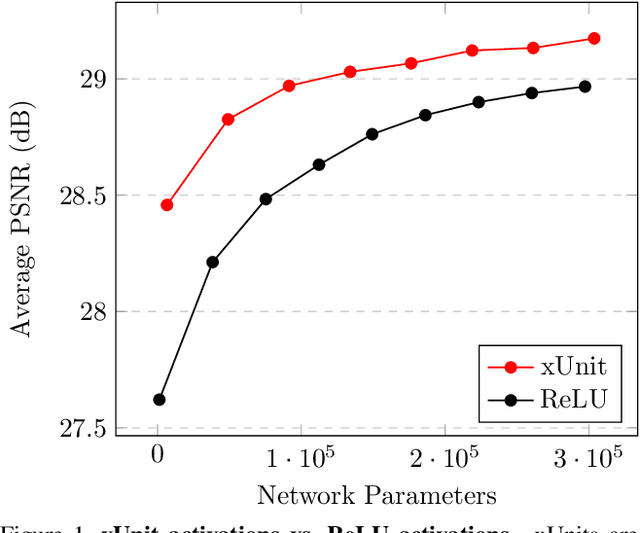

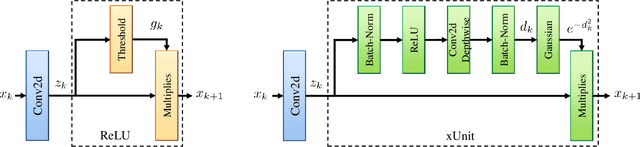
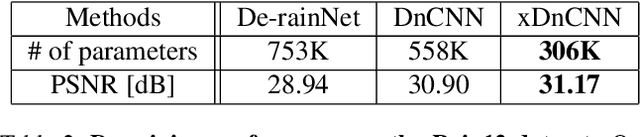
In recent years, deep neural networks (DNNs) achieved unprecedented performance in many low-level vision tasks. However, state-of-the-art results are typically achieved by very deep networks, which can reach tens of layers with tens of millions of parameters. To make DNNs implementable on platforms with limited resources, it is necessary to weaken the tradeoff between performance and efficiency. In this paper, we propose a new activation unit, which is particularly suitable for image restoration problems. In contrast to the widespread per-pixel activation units, like ReLUs and sigmoids, our unit implements a learnable nonlinear function with spatial connections. This enables the net to capture much more complex features, thus requiring a significantly smaller number of layers in order to reach the same performance. We illustrate the effectiveness of our units through experiments with state-of-the-art nets for denoising, de-raining, and super resolution, which are already considered to be very small. With our approach, we are able to further reduce these models by nearly 50% without incurring any degradation in performance.
Stochastic-YOLO: Efficient Probabilistic Object Detection under Dataset Shifts
Sep 07, 2020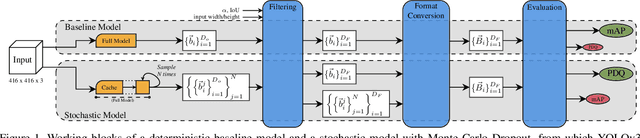
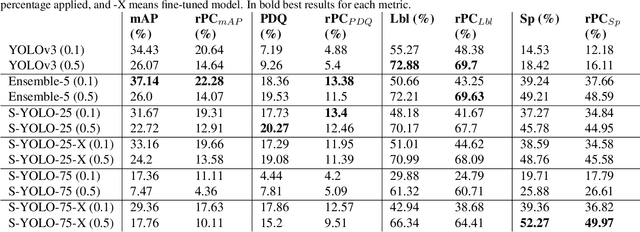
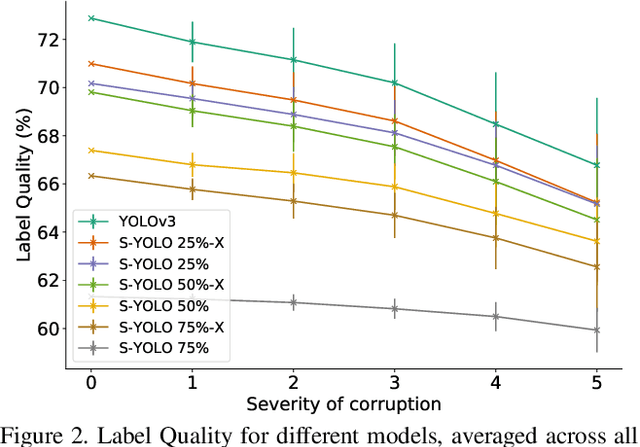
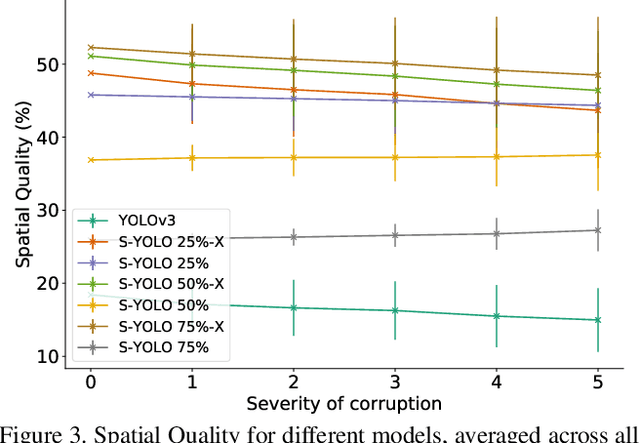
In image classification tasks, the evaluation of models' robustness to increased dataset shifts with a probabilistic framework is very well studied. However, Object Detection (OD) tasks pose other challenges for uncertainty estimation and evaluation. For example, one needs to evaluate both the quality of the label uncertainty (i.e., what?) and spatial uncertainty (i.e., where?) for a given bounding box, but that evaluation cannot be performed with more traditional average precision metrics (e.g., mAP). In this paper, we adapt the well-established YOLOv3 architecture to generate uncertainty estimations by introducing stochasticity in the form of Monte Carlo Dropout (MC-Drop), and evaluate it across different levels of dataset shift. We call this novel architecture Stochastic-YOLO, and provide an efficient implementation to effectively reduce the burden of the MC-Drop sampling mechanism at inference time. Finally, we provide some sensitivity analyses, while arguing that Stochastic-YOLO is a sound approach that improves different components of uncertainty estimations, in particular spatial uncertainties.
CPOT: Channel Pruning via Optimal Transport
May 21, 2020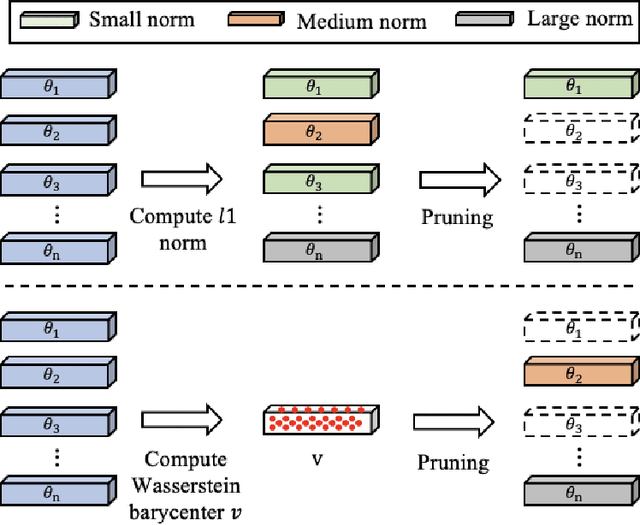

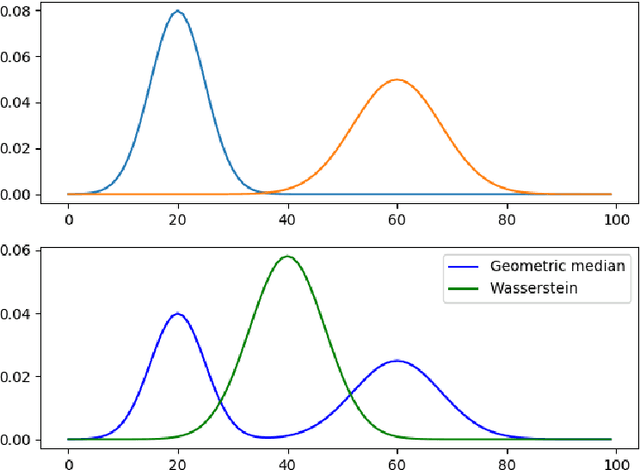
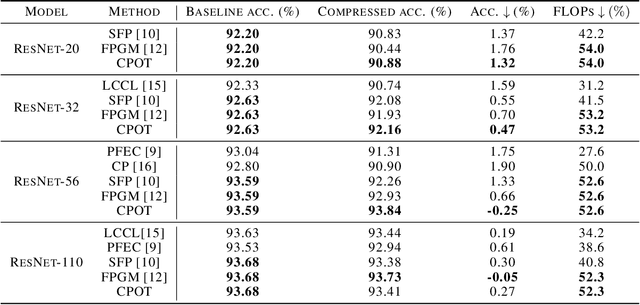
Recent advances in deep neural networks (DNNs) lead to tremendously growing network parameters, making the deployments of DNNs on platforms with limited resources extremely difficult. Therefore, various pruning methods have been developed to compress the deep network architectures and accelerate the inference process. Most of the existing channel pruning methods discard the less important filters according to well-designed filter ranking criteria. However, due to the limited interpretability of deep learning models, designing an appropriate ranking criterion to distinguish redundant filters is difficult. To address such a challenging issue, we propose a new technique of Channel Pruning via Optimal Transport, dubbed CPOT. Specifically, we locate the Wasserstein barycenter for channels of each layer in the deep models, which is the mean of a set of probability distributions under the optimal transport metric. Then, we prune the redundant information located by Wasserstein barycenters. At last, we empirically demonstrate that, for classification tasks, CPOT outperforms the state-of-the-art methods on pruning ResNet-20, ResNet-32, ResNet-56, and ResNet-110. Furthermore, we show that the proposed CPOT technique is good at compressing the StarGAN models by pruning in the more difficult case of image-to-image translation tasks.
End-to-End Domain Adaptive Attention Network for Cross-Domain Person Re-Identification
May 07, 2020
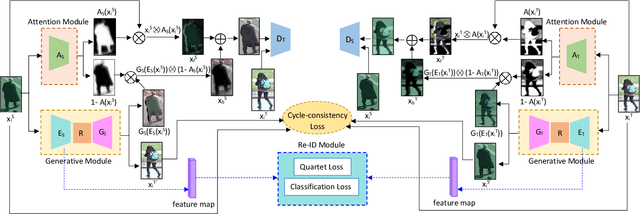
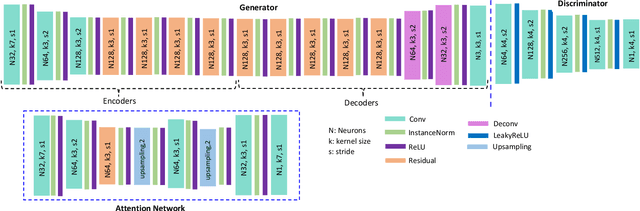

Person re-identification (re-ID) remains challenging in a real-world scenario, as it requires a trained network to generalise to totally unseen target data in the presence of variations across domains. Recently, generative adversarial models have been widely adopted to enhance the diversity of training data. These approaches, however, often fail to generalise to other domains, as existing generative person re-identification models have a disconnect between the generative component and the discriminative feature learning stage. To address the on-going challenges regarding model generalisation, we propose an end-to-end domain adaptive attention network to jointly translate images between domains and learn discriminative re-id features in a single framework. To address the domain gap challenge, we introduce an attention module for image translation from source to target domains without affecting the identity of a person. More specifically, attention is directed to the background instead of the entire image of the person, ensuring identifying characteristics of the subject are preserved. The proposed joint learning network results in a significant performance improvement over state-of-the-art methods on several benchmark datasets.
Learning Soft Labels via Meta Learning
Sep 20, 2020

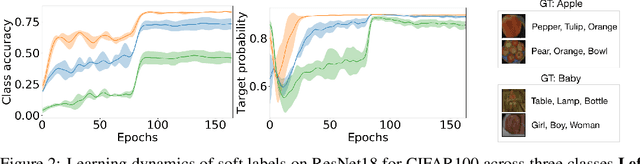

One-hot labels do not represent soft decision boundaries among concepts, and hence, models trained on them are prone to overfitting. Using soft labels as targets provide regularization, but different soft labels might be optimal at different stages of optimization. Also, training with fixed labels in the presence of noisy annotations leads to worse generalization. To address these limitations, we propose a framework, where we treat the labels as learnable parameters, and optimize them along with model parameters. The learned labels continuously adapt themselves to the model's state, thereby providing dynamic regularization. When applied to the task of supervised image-classification, our method leads to consistent gains across different datasets and architectures. For instance, dynamically learned labels improve ResNet18 by 2.1% on CIFAR100. When applied to dataset containing noisy labels, the learned labels correct the annotation mistakes, and improves over state-of-the-art by a significant margin. Finally, we show that learned labels capture semantic relationship between classes, and thereby improve teacher models for the downstream task of distillation.
A Comparison of Optimization Algorithms for Deep Learning
Jul 28, 2020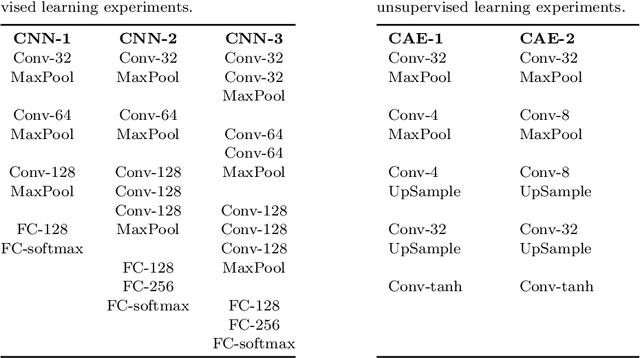
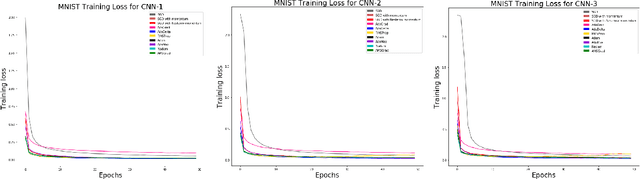
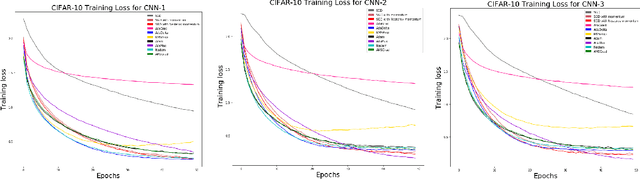
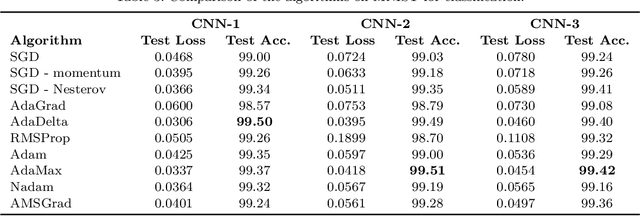
In recent years, we have witnessed the rise of deep learning. Deep neural networks have proved their success in many areas. However, the optimization of these networks has become more difficult as neural networks going deeper and datasets becoming bigger. Therefore, more advanced optimization algorithms have been proposed over the past years. In this study, widely used optimization algorithms for deep learning are examined in detail. To this end, these algorithms called adaptive gradient methods are implemented for both supervised and unsupervised tasks. The behaviour of the algorithms during training and results on four image datasets, namely, MNIST, CIFAR-10, Kaggle Flowers and Labeled Faces in the Wild are compared by pointing out their differences against basic optimization algorithms.
Implicit Feature Networks for Texture Completion from Partial 3D Data
Sep 20, 2020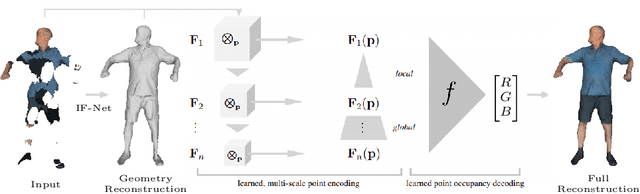
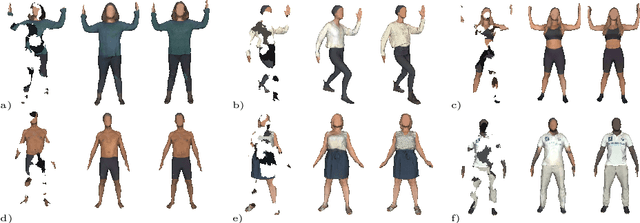

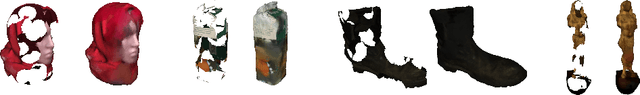
Prior work to infer 3D texture use either texture atlases, which require uv-mappings and hence have discontinuities, or colored voxels, which are memory inefficient and limited in resolution. Recent work, predicts RGB color at every XYZ coordinate forming a texture field, but focus on completing texture given a single 2D image. Instead, we focus on 3D texture and geometry completion from partial and incomplete 3D scans. IF-Nets have recently achieved state-of-the-art results on 3D geometry completion using a multi-scale deep feature encoding, but the outputs lack texture. In this work, we generalize IF-Nets to texture completion from partial textured scans of humans and arbitrary objects. Our key insight is that 3D texture completion benefits from incorporating local and global deep features extracted from both the 3D partial texture and completed geometry. Specifically, given the partial 3D texture and the 3D geometry completed with IF-Nets, our model successfully in-paints the missing texture parts in consistence with the completed geometry. Our model won the SHARP ECCV'20 challenge, achieving highest performance on all challenges.
* SHARP Workshop, European Conference on Computer Vision (ECCV), 2020