 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Trust We Survive: Emergent Trust Learning
Mar 18, 2026We introduce Emergent Trust Learning (ETL), a lightweight, trust-based control algorithm that can be plugged into existing AI agents. It enables these to reach cooperation in competitive game environments under shared resources. Each agent maintains a compact internal trust state, which modulates memory, exploration, and action selection. ETL requires only individual rewards and local observations and incurs negligible computational and communication overhead. We evaluate ETL in three environments: In a grid-based resource world, trust-based agents reduce conflicts and prevent long-term resource depletion while achieving competitive individual returns. In a hierarchical Tower environment with strong social dilemmas and randomised floor assignments, ETL sustains high survival rates and recovers cooperation even after extended phases of enforced greed. In the Iterated Prisoner's Dilemma, the algorithm generalises to a strategic meta-game, maintaining cooperation with reciprocal opponents while avoiding long-term exploitation by defectors. Code will be released upon publication.
When Visual Evidence is Ambiguous: Pareidolia as a Diagnostic Probe for Vision Models
Mar 04, 2026When visual evidence is ambiguous, vision models must decide whether to interpret face-like patterns as meaningful. Face pareidolia, the perception of faces in non-face objects, provides a controlled probe of this behavior. We introduce a representation-level diagnostic framework that analyzes detection, localization, uncertainty, and bias across class, difficulty, and emotion in face pareidolia images. Under a unified protocol, we evaluate six models spanning four representational regimes: vision-language models (VLMs; CLIP-B/32, CLIP-L/14, LLaVA-1.5-7B), pure vision classification (ViT), general object detection (YOLOv8), and face detection (RetinaFace). Our analysis reveals three mechanisms of interpretation under ambiguity. VLMs exhibit semantic overactivation, systematically pulling ambiguous non-human regions toward the Human concept, with LLaVA-1.5-7B producing the strongest and most confident over-calls, especially for negative emotions. ViT instead follows an uncertainty-as-abstention strategy, remaining diffuse yet largely unbiased. Detection-based models achieve low bias through conservative priors that suppress pareidolia responses even when localization is controlled. These results show that behavior under ambiguity is governed more by representational choices than score thresholds, and that uncertainty and bias are decoupled: low uncertainty can signal either safe suppression, as in detectors, or extreme over-interpretation, as in VLMs. Pareidolia therefore provides a compact diagnostic and a source of ambiguity-aware hard negatives for probing and improving the semantic robustness of vision-language systems. Code will be released upon publication.
Investigating the Gestalt Principle of Closure in Deep Convolutional Neural Networks
Nov 01, 2024

Deep neural networks perform well in object recognition, but do they perceive objects like humans? This study investigates the Gestalt principle of closure in convolutional neural networks. We propose a protocol to identify closure and conduct experiments using simple visual stimuli with progressively removed edge sections. We evaluate well-known networks on their ability to classify incomplete polygons. Our findings reveal a performance degradation as the edge removal percentage increases, indicating that current models heavily rely on complete edge information for accurate classification. The data used in our study is available on Github.
Have Large Vision-Language Models Mastered Art History?
Sep 05, 2024The emergence of large Vision-Language Models (VLMs) has recently established new baselines in image classification across multiple domains. However, the performance of VLMs in the specific task of artwork classification, particularly art style classification of paintings - a domain traditionally mastered by art historians - has not been explored yet. Artworks pose a unique challenge compared to natural images due to their inherently complex and diverse structures, characterized by variable compositions and styles. Art historians have long studied the unique aspects of artworks, with style prediction being a crucial component of their discipline. This paper investigates whether large VLMs, which integrate visual and textual data, can effectively predict the art historical attributes of paintings. We conduct an in-depth analysis of four VLMs, namely CLIP, LLaVA, OpenFlamingo, and GPT-4o, focusing on zero-shot classification of art style, author and time period using two public benchmarks of artworks. Additionally, we present ArTest, a well-curated test set of artworks, including pivotal paintings studied by art historians.
BackFlip: The Impact of Local and Global Data Augmentations on Artistic Image Aesthetic Assessment
Aug 26, 2024Assessing the aesthetic quality of artistic images presents unique challenges due to the subjective nature of aesthetics and the complex visual characteristics inherent to artworks. Basic data augmentation techniques commonly applied to natural images in computer vision may not be suitable for art images in aesthetic evaluation tasks, as they can change the composition of the art images. In this paper, we explore the impact of local and global data augmentation techniques on artistic image aesthetic assessment (IAA). We introduce BackFlip, a local data augmentation technique designed specifically for artistic IAA. We evaluate the performance of BackFlip across three artistic image datasets and four neural network architectures, comparing it with the commonly used data augmentation techniques. Then, we analyze the effects of components within the BackFlip pipeline through an ablation study. Our findings demonstrate that local augmentations, such as BackFlip, tend to outperform global augmentations on artistic IAA in most cases, probably because they do not perturb the composition of the art images. These results emphasize the importance of considering both local and global augmentations in future computational aesthetics research.
Finding Closure: A Closer Look at the Gestalt Law of Closure in Convolutional Neural Networks
Aug 22, 2024



The human brain has an inherent ability to fill in gaps to perceive figures as complete wholes, even when parts are missing or fragmented. This phenomenon is known as Closure in psychology, one of the Gestalt laws of perceptual organization, explaining how the human brain interprets visual stimuli. Given the importance of Closure for human object recognition, we investigate whether neural networks rely on a similar mechanism. Exploring this crucial human visual skill in neural networks has the potential to highlight their comparability to humans. Recent studies have examined the Closure effect in neural networks. However, they typically focus on a limited selection of Convolutional Neural Networks (CNNs) and have not reached a consensus on their capability to perform Closure. To address these gaps, we present a systematic framework for investigating the Closure principle in neural networks. We introduce well-curated datasets designed to test for Closure effects, including both modal and amodal completion. We then conduct experiments on various CNNs employing different measurements. Our comprehensive analysis reveals that VGG16 and DenseNet-121 exhibit the Closure effect, while other CNNs show variable results. We interpret these findings by blending insights from psychology and neural network research, offering a unique perspective that enhances transparency in understanding neural networks. Our code and dataset will be made available on GitHub.
Unveiling The Factors of Aesthetic Preferences with Explainable AI
Nov 24, 2023



The allure of aesthetic appeal in images captivates our senses, yet the underlying intricacies of aesthetic preferences remain elusive. In this study, we pioneer a novel perspective by utilizing machine learning models that focus on aesthetic attributes known to influence preferences. Through a data mining approach, our models process these attributes as inputs to predict the aesthetic scores of images. Moreover, to delve deeper and obtain interpretable explanations regarding the factors driving aesthetic preferences, we utilize the popular Explainable AI (XAI) technique known as SHapley Additive exPlanations (SHAP). Our methodology involves employing various machine learning models, including Random Forest, XGBoost, Support Vector Regression, and Multilayer Perceptron, to compare their performances in accurately predicting aesthetic scores, and consistently observing results in conjunction with SHAP. We conduct experiments on three image aesthetic benchmarks, providing insights into the roles of attributes and their interactions. Ultimately, our study aims to shed light on the complex nature of aesthetic preferences in images through machine learning and provides a deeper understanding of the attributes that influence aesthetic judgements.
Multi-task convolutional neural network for image aesthetic assessment
May 16, 2023



As people's aesthetic preferences for images are far from understood, image aesthetic assessment is a challenging artificial intelligence task. The range of factors underlying this task is almost unlimited, but we know that some aesthetic attributes affect those preferences. In this study, we present a multi-task convolutional neural network that takes into account these attributes. The proposed neural network jointly learns the attributes along with the overall aesthetic scores of images. This multi-task learning framework allows for effective generalization through the utilization of shared representations. Our experiments demonstrate that the proposed method outperforms the state-of-the-art approaches in predicting overall aesthetic scores for images in one benchmark of image aesthetics. We achieve near-human performance in terms of overall aesthetic scores when considering the Spearman's rank correlations. Moreover, our model pioneers the application of multi-tasking in another benchmark, serving as a new baseline for future research. Notably, our approach achieves this performance while using fewer parameters compared to existing multi-task neural networks in the literature, and consequently makes our method more efficient in terms of computational complexity.
From paintbrush to pixel: A review of deep neural networks in AI-generated art
Feb 14, 2023This paper delves into the fascinating field of AI-generated art and explores the various deep neural network architectures and models that have been utilized to create it. From the classic convolutional networks to the cutting-edge diffusion models, we examine the key players in the field. We explain the general structures and working principles of these neural networks. Then, we showcase examples of milestones, starting with the dreamy landscapes of DeepDream and moving on to the most recent developments, including Stable Diffusion and DALL-E 2, which produce mesmerizing images. A detailed comparison of these models is provided, highlighting their strengths and limitations. Thus, we examine the remarkable progress that deep neural networks have made so far in a short period of time. With a unique blend of technical explanations and insights into the current state of AI-generated art, this paper exemplifies how art and computer science interact.
Application of multilayer perceptron with data augmentation in nuclear physics
May 16, 2022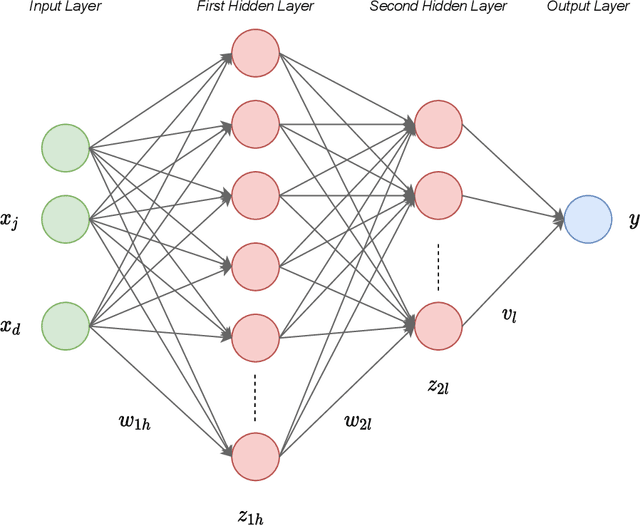
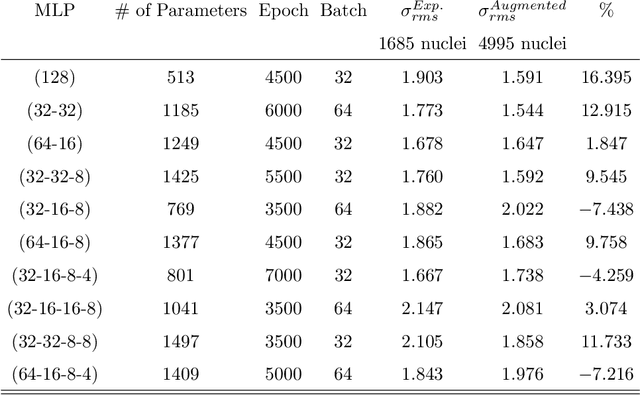
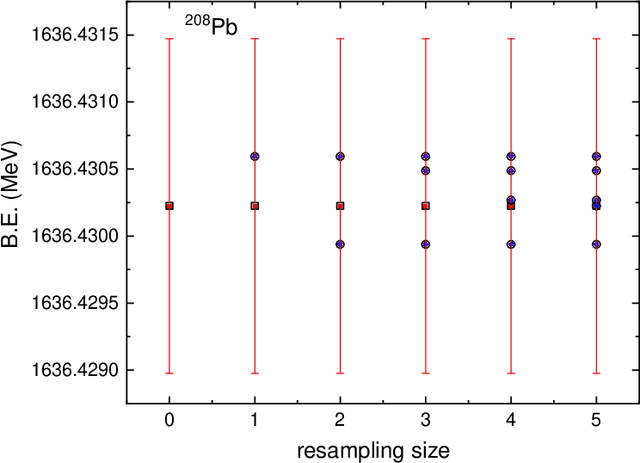
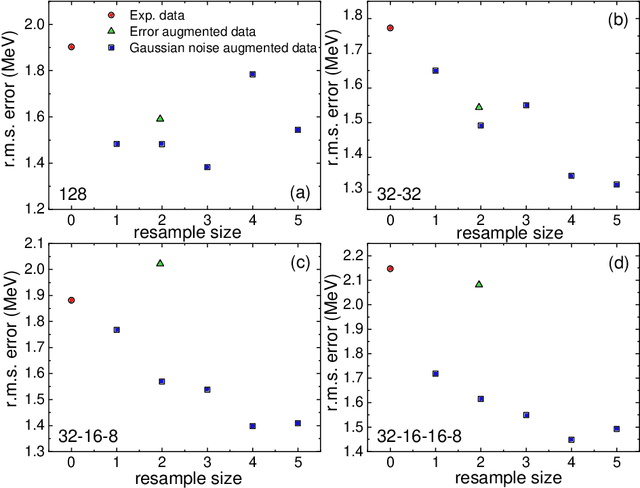
Neural networks have become popular in many fields of science since they serve as reliable and powerful tools. Application of the neural networks to the nuclear physics studies has also become popular in recent years because of their success in the prediction of nuclear properties. In this work, we study the effect of the data augmentation on the predictive power of the neural network models. Even though there are various data augmentation techniques used for classification tasks in the literature, this area is still very limited for regression problems. As predicting the binding energies is statistically defined as a regression problem, in addition to using data augmentation for nuclear physics, this study contributes to this field for regression in general. Using the experimental uncertainties for data augmentation, the size of training data set is artificially boosted and the changes in the root-mean-square error between the model predictions on test set and the experimental data are investigated. As far as we know, this is the first time that data augmentation techniques have been implemented for nuclear physics research. Our results show that the data augmentation decreases the prediction errors, stabilizes the model and prevents overfitting. The extrapolation capabilities of the MLP models with different depths are also tested for newly measured nuclei in AME2020 mass table.