 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusing Pre-Training Data at Test Time is a Compute Multiplier
Nov 06, 2025



Large language models learn from their vast pre-training corpora, gaining the ability to solve an ever increasing variety of tasks; yet although researchers work to improve these datasets, there is little effort to understand how efficient the pre-training apparatus is at extracting ideas and knowledge from the data. In this work, we use retrieval augmented generation along with test-time compute as a way to quantify how much dataset value was left behind by the process of pre-training, and how this changes across scale. We demonstrate that pre-training then retrieving from standard and largely open-sourced datasets results in significant accuracy gains in MMLU, Math-500, and SimpleQA, which persist through decontamination. For MMLU we observe that retrieval acts as a ~5x compute multiplier versus pre-training alone. We show that these results can be further improved by leveraging additional compute at test time to parse the retrieved context, demonstrating a 10 percentage point improvement on MMLU for the public LLaMA 3.1 8B model. Overall, our results suggest that today's pre-training methods do not make full use of the information in existing pre-training datasets, leaving significant room for progress.
Learning Soft Labels via Meta Learning
Sep 20, 2020

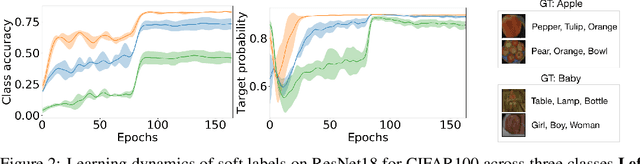

One-hot labels do not represent soft decision boundaries among concepts, and hence, models trained on them are prone to overfitting. Using soft labels as targets provide regularization, but different soft labels might be optimal at different stages of optimization. Also, training with fixed labels in the presence of noisy annotations leads to worse generalization. To address these limitations, we propose a framework, where we treat the labels as learnable parameters, and optimize them along with model parameters. The learned labels continuously adapt themselves to the model's state, thereby providing dynamic regularization. When applied to the task of supervised image-classification, our method leads to consistent gains across different datasets and architectures. For instance, dynamically learned labels improve ResNet18 by 2.1% on CIFAR100. When applied to dataset containing noisy labels, the learned labels correct the annotation mistakes, and improves over state-of-the-art by a significant margin. Finally, we show that learned labels capture semantic relationship between classes, and thereby improve teacher models for the downstream task of distillation.