 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Underexplored Dilemma between Confidence and Calibration in Quantized Neural Networks
Dec 02, 2021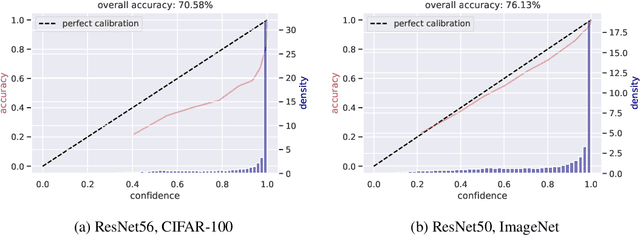
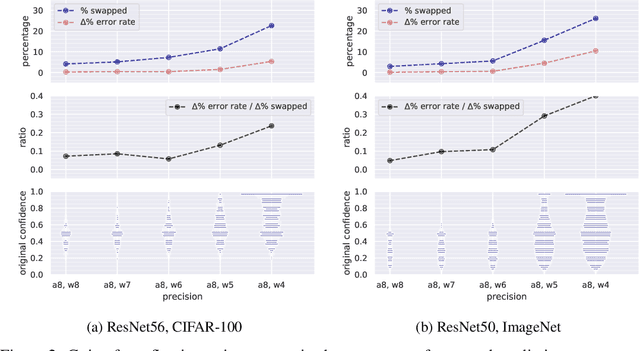
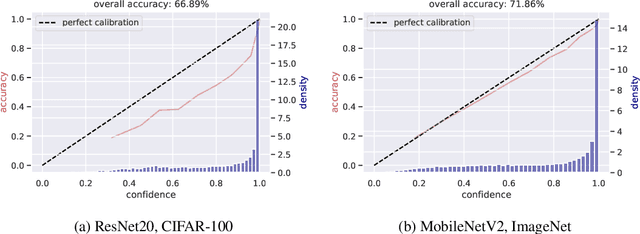
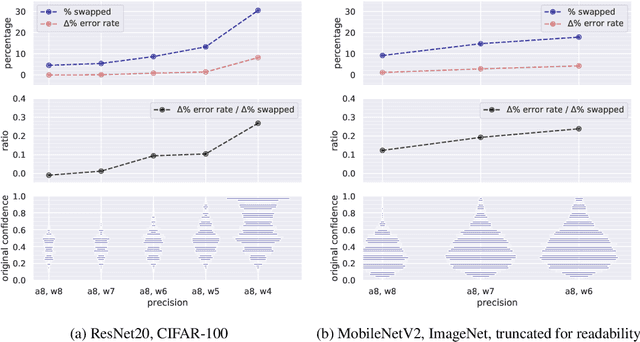
Modern convolutional neural networks (CNNs) are known to be overconfident in terms of their calibration on unseen input data. That is to say, they are more confident than they are accurate. This is undesirable if the probabilities predicted are to be used for downstream decision making. When considering accuracy, CNNs are also surprisingly robust to compression techniques, such as quantization, which aim to reduce computational and memory costs. We show that this robustness can be partially explained by the calibration behavior of modern CNNs, and may be improved with overconfidence. This is due to an intuitive result: low confidence predictions are more likely to change post-quantization, whilst being less accurate. High confidence predictions will be more accurate, but more difficult to change. Thus, a minimal drop in post-quantization accuracy is incurred. This presents a potential conflict in neural network design: worse calibration from overconfidence may lead to better robustness to quantization. We perform experiments applying post-training quantization to a variety of CNNs, on the CIFAR-100 and ImageNet datasets.
On Efficient Uncertainty Estimation for Resource-Constrained Mobile Applications
Dec 01, 2021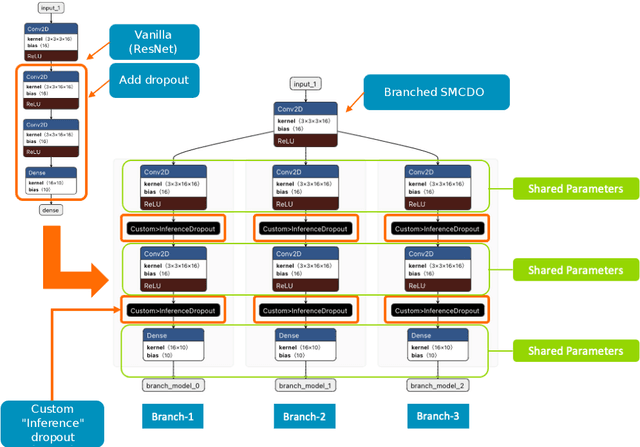

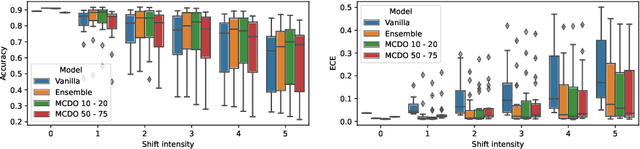
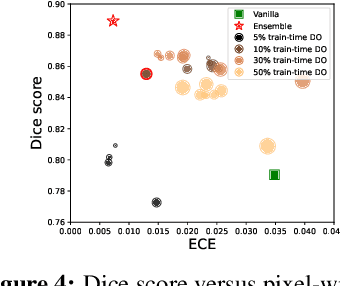
Deep neural networks have shown great success in prediction quality while reliable and robust uncertainty estimation remains a challenge. Predictive uncertainty supplements model predictions and enables improved functionality of downstream tasks including embedded and mobile applications, such as virtual reality, augmented reality, sensor fusion, and perception. These applications often require a compromise in complexity to obtain uncertainty estimates due to very limited memory and compute resources. We tackle this problem by building upon Monte Carlo Dropout (MCDO) models using the Axolotl framework; specifically, we diversify sampled subnetworks, leverage dropout patterns, and use a branching technique to improve predictive performance while maintaining fast computations. We conduct experiments on (1) a multi-class classification task using the CIFAR10 dataset, and (2) a more complex human body segmentation task. Our results show the effectiveness of our approach by reaching close to Deep Ensemble prediction quality and uncertainty estimation, while still achieving faster inference on resource-limited mobile platforms.
Towards Efficient Point Cloud Graph Neural Networks Through Architectural Simplification
Aug 13, 2021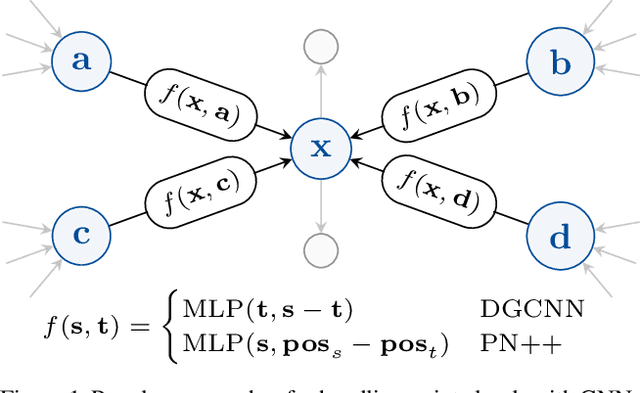
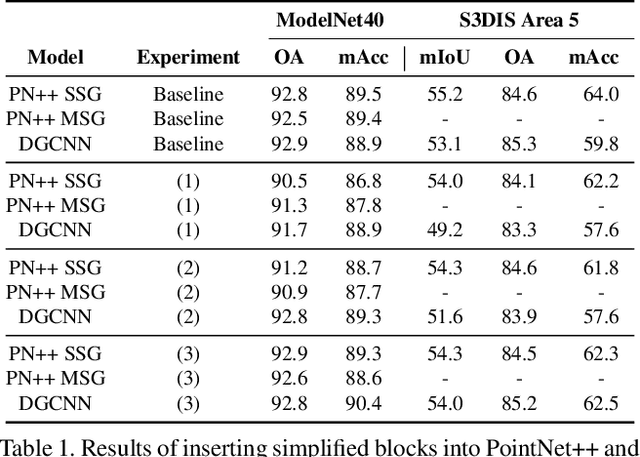

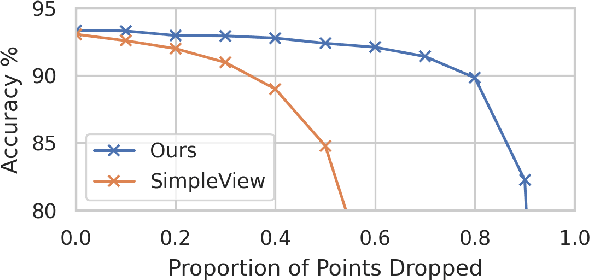
In recent years graph neural network (GNN)-based approaches have become a popular strategy for processing point cloud data, regularly achieving state-of-the-art performance on a variety of tasks. To date, the research community has primarily focused on improving model expressiveness, with secondary thought given to how to design models that can run efficiently on resource constrained mobile devices including smartphones or mixed reality headsets. In this work we make a step towards improving the efficiency of these models by making the observation that these GNN models are heavily limited by the representational power of their first, feature extracting, layer. We find that it is possible to radically simplify these models so long as the feature extraction layer is retained with minimal degradation to model performance; further, we discover that it is possible to improve performance overall on ModelNet40 and S3DIS by improving the design of the feature extractor. Our approach reduces memory consumption by 20$\times$ and latency by up to 9.9$\times$ for graph layers in models such as DGCNN; overall, we achieve speed-ups of up to 4.5$\times$ and peak memory reductions of 72.5%.
Stochastic-Shield: A Probabilistic Approach Towards Training-Free Adversarial Defense in Quantized CNNs
May 13, 2021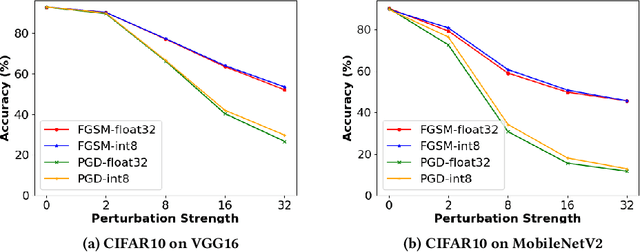
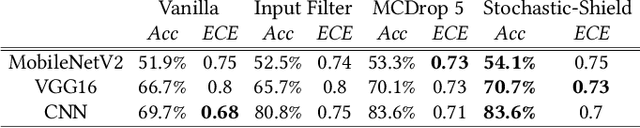
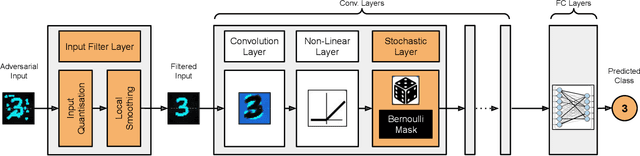
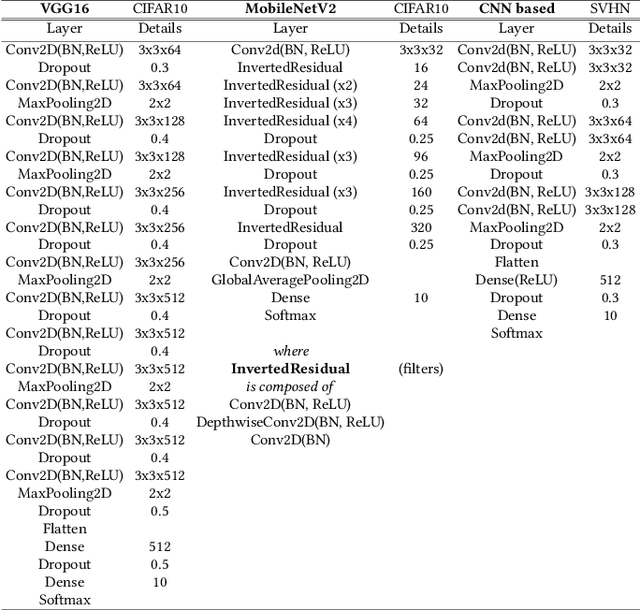
Quantized neural networks (NN) are the common standard to efficiently deploy deep learning models on tiny hardware platforms. However, we notice that quantized NNs are as vulnerable to adversarial attacks as the full-precision models. With the proliferation of neural networks on small devices that we carry or surround us, there is a need for efficient models without sacrificing trust in the prediction in presence of malign perturbations. Current mitigation approaches often need adversarial training or are bypassed when the strength of adversarial examples is increased. In this work, we investigate how a probabilistic framework would assist in overcoming the aforementioned limitations for quantized deep learning models. We explore Stochastic-Shield: a flexible defense mechanism that leverages input filtering and a probabilistic deep learning approach materialized via Monte Carlo Dropout. We show that it is possible to jointly achieve efficiency and robustness by accurately enabling each module without the burden of re-retraining or ad hoc fine-tuning.
On the Effects of Quantisation on Model Uncertainty in Bayesian Neural Networks
Feb 22, 2021
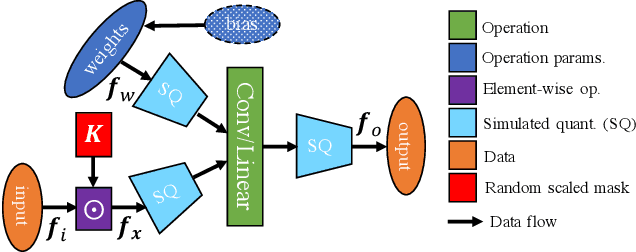
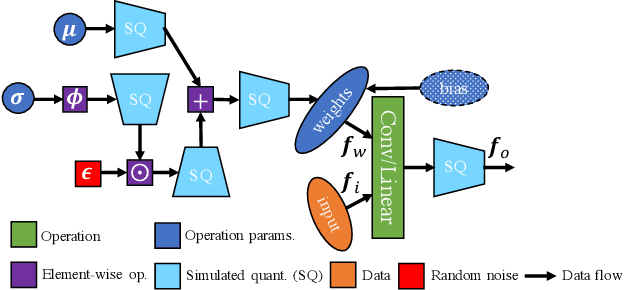
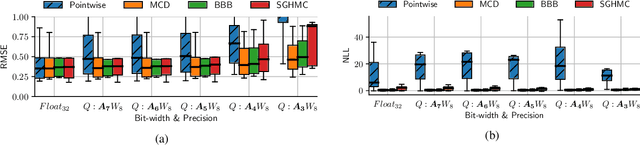
Bayesian neural networks (BNNs) are making significant progress in many research areas where decision making needs to be accompanied by uncertainty estimation. Being able to quantify uncertainty while making decisions is essential for understanding when the model is over-/under-confident, and hence BNNs are attracting interest in safety-critical applications, such as autonomous driving, healthcare and robotics. Nevertheless, BNNs have not been as widely used in industrial practice, mainly because of their increased memory and compute costs. In this work, we investigate quantisation of BNNs by compressing 32-bit floating-point weights and activations to their integer counterparts, that has already been successful in reducing the compute demand in standard pointwise neural networks. We study three types of quantised BNNs, we evaluate them under a wide range of different settings, and we empirically demonstrate that an uniform quantisation scheme applied to BNNs does not substantially decrease their quality of uncertainty estimation.
Stochastic-YOLO: Efficient Probabilistic Object Detection under Dataset Shifts
Sep 07, 2020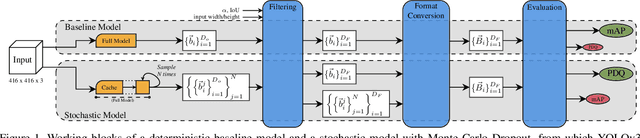
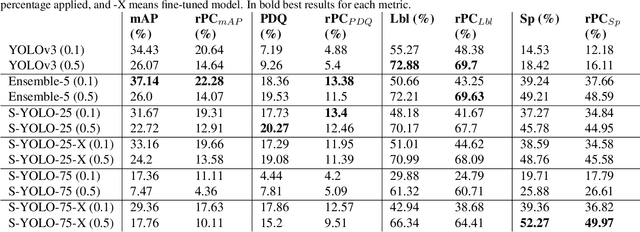
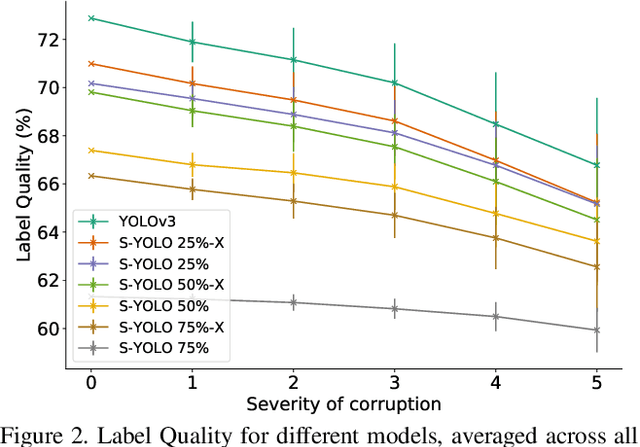
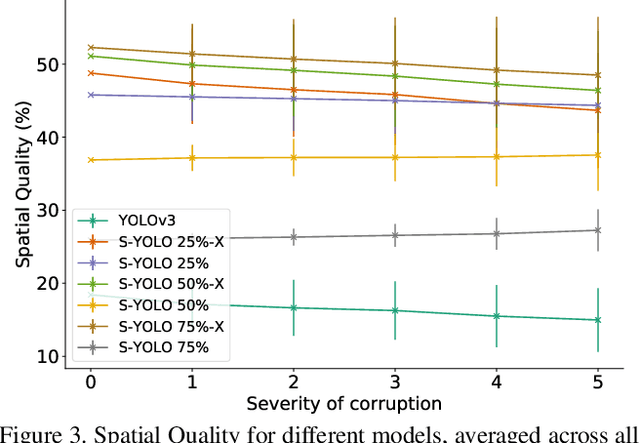
In image classification tasks, the evaluation of models' robustness to increased dataset shifts with a probabilistic framework is very well studied. However, Object Detection (OD) tasks pose other challenges for uncertainty estimation and evaluation. For example, one needs to evaluate both the quality of the label uncertainty (i.e., what?) and spatial uncertainty (i.e., where?) for a given bounding box, but that evaluation cannot be performed with more traditional average precision metrics (e.g., mAP). In this paper, we adapt the well-established YOLOv3 architecture to generate uncertainty estimations by introducing stochasticity in the form of Monte Carlo Dropout (MC-Drop), and evaluate it across different levels of dataset shift. We call this novel architecture Stochastic-YOLO, and provide an efficient implementation to effectively reduce the burden of the MC-Drop sampling mechanism at inference time. Finally, we provide some sensitivity analyses, while arguing that Stochastic-YOLO is a sound approach that improves different components of uncertainty estimations, in particular spatial uncertainties.
Efficient Winograd or Cook-Toom Convolution Kernel Implementation on Widely Used Mobile CPUs
Mar 04, 2019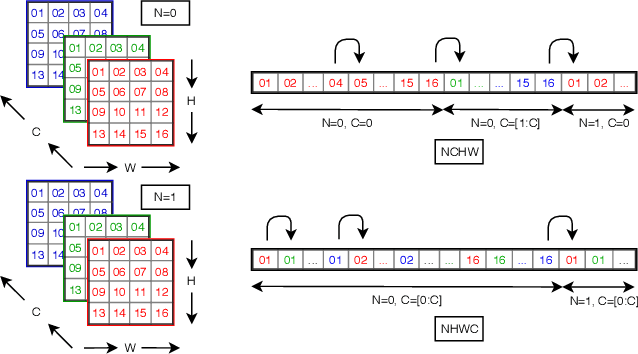

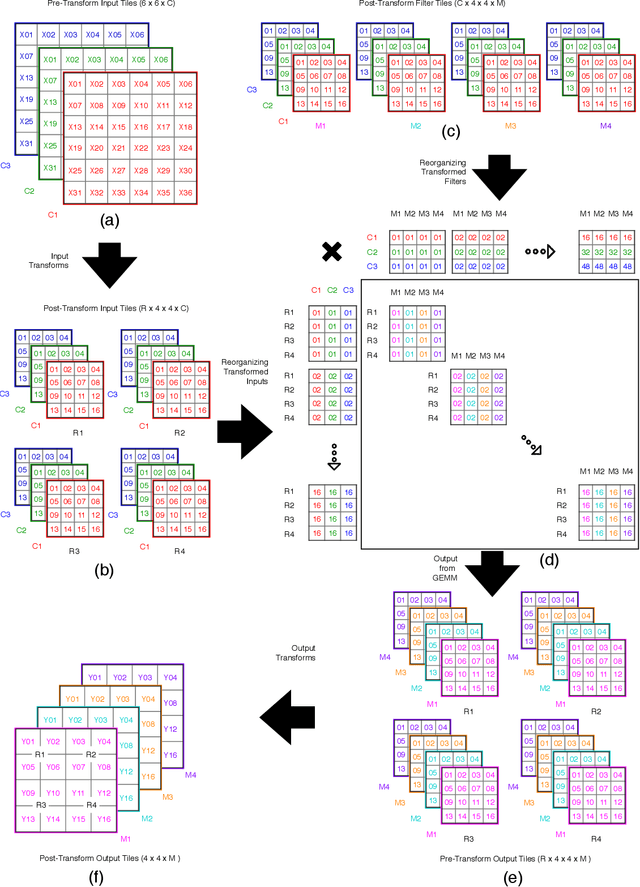
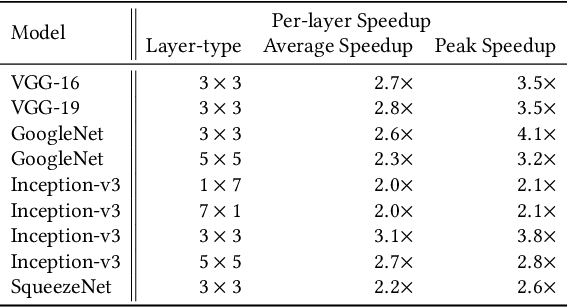
The Winograd or Cook-Toom class of algorithms help to reduce the overall compute complexity of many modern deep convolutional neural networks (CNNs). Although there has been a lot of research done on model and algorithmic optimization of CNN, little attention has been paid to the efficient implementation of these algorithms on embedded CPUs, which usually have very limited memory and low power budget. This paper aims to fill this gap and focuses on the efficient implementation of Winograd or Cook-Toom based convolution on modern Arm Cortex-A CPUs, widely used in mobile devices today. Specifically, we demonstrate a reduction in inference latency by using a set of optimization strategies that improve the utilization of computational resources, and by effectively leveraging the ARMv8-A NEON SIMD instruction set. We evaluated our proposed region-wise multi-channel implementations on Arm Cortex-A73 platform using several representative CNNs. The results show significant performance improvements in full network, up to 60%, over existing im2row/im2col based optimization techniques