 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Simultaneous Feature Aggregating and Hashing for Large-scale Image Search
Apr 04, 2017

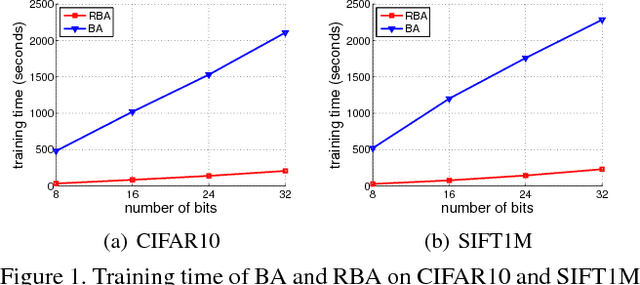
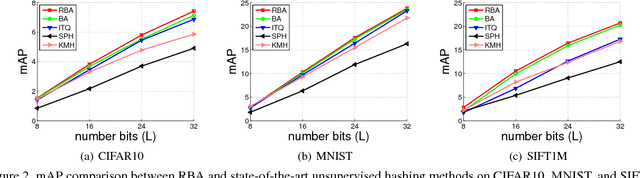
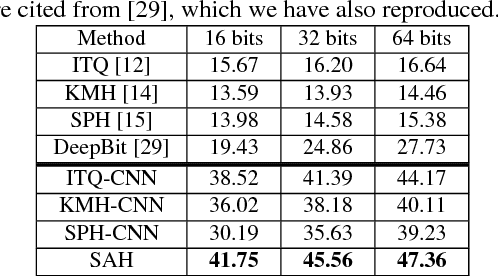
In most state-of-the-art hashing-based visual search systems, local image descriptors of an image are first aggregated as a single feature vector. This feature vector is then subjected to a hashing function that produces a binary hash code. In previous work, the aggregating and the hashing processes are designed independently. In this paper, we propose a novel framework where feature aggregating and hashing are designed simultaneously and optimized jointly. Specifically, our joint optimization produces aggregated representations that can be better reconstructed by some binary codes. This leads to more discriminative binary hash codes and improved retrieval accuracy. In addition, we also propose a fast version of the recently-proposed Binary Autoencoder to be used in our proposed framework. We perform extensive retrieval experiments on several benchmark datasets with both SIFT and convolutional features. Our results suggest that the proposed framework achieves significant improvements over the state of the art.
Improving Query Efficiency of Black-box Adversarial Attack
Sep 25, 2020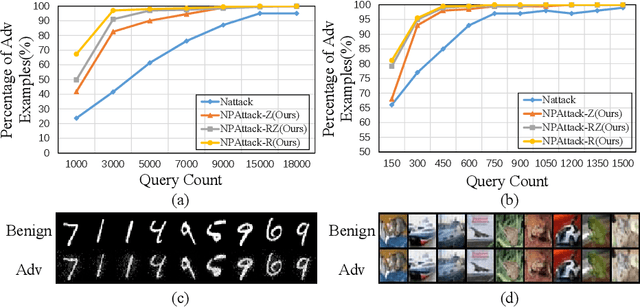
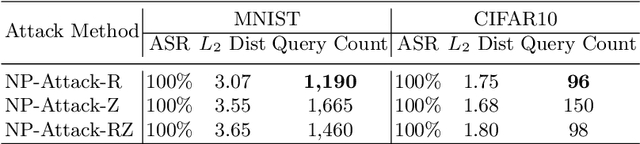
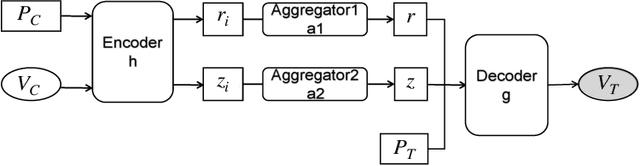
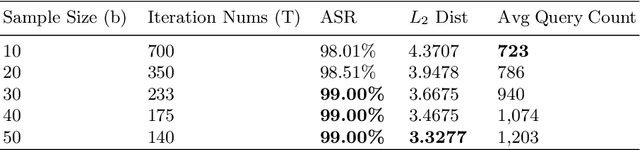
Deep neural networks (DNNs) have demonstrated excellent performance on various tasks, however they are under the risk of adversarial examples that can be easily generated when the target model is accessible to an attacker (white-box setting). As plenty of machine learning models have been deployed via online services that only provide query outputs from inaccessible models (e.g. Google Cloud Vision API2), black-box adversarial attacks (inaccessible target model) are of critical security concerns in practice rather than white-box ones. However, existing query-based black-box adversarial attacks often require excessive model queries to maintain a high attack success rate. Therefore, in order to improve query efficiency, we explore the distribution of adversarial examples around benign inputs with the help of image structure information characterized by a Neural Process, and propose a Neural Process based black-box adversarial attack (NP-Attack) in this paper. Extensive experiments show that NP-Attack could greatly decrease the query counts under the black-box setting.
The Surprising Effectiveness of Linear Models for Visual Foresight in Object Pile Manipulation
Feb 21, 2020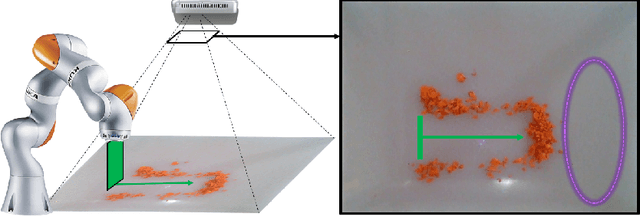


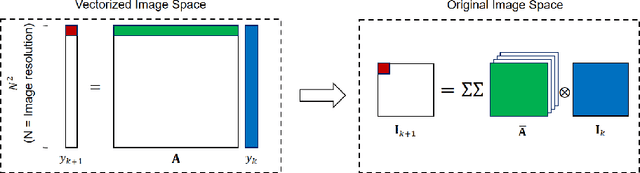
In this paper, we tackle the problem of pushing piles of small objects into a desired target set using visual feedback. Unlike conventional single-object manipulation pipelines, which estimate the state of the system parametrized by pose, the underlying physical state of this system is difficult to observe from images. Thus, we take the approach of reasoning directly in the space of images, and acquire the dynamics of visual measurements in order to synthesize a visual-feedback policy. We present a simple controller using an image-space Lyapunov function, and evaluate the closed-loop performance using three different class of models for image prediction: deep-learning-based models for image-to-image translation, an object-centric model obtained from treating each pixel as a particle, and a switched-linear system where an action-dependent linear map is used. Through results in simulation and experiment, we show that for this task, a linear model works surprisingly well -- achieving better prediction error, downstream task performance, and generalization to new environments than the deep models we trained on the same amount of data. We believe these results provide an interesting example in the spectrum of models that are most useful for vision-based feedback in manipulation, considering both the quality of visual prediction, as well as compatibility with rigorous methods for control design and analysis.
Evaluating Multimodal Representations on Visual Semantic Textual Similarity
Apr 04, 2020

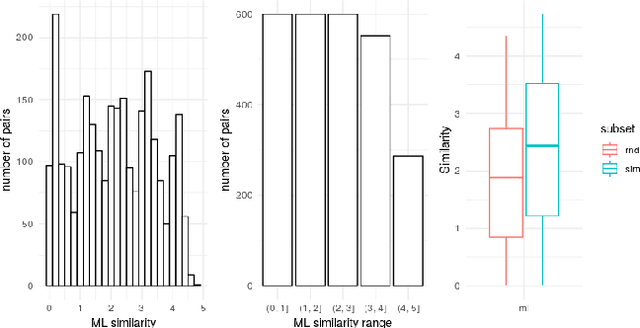
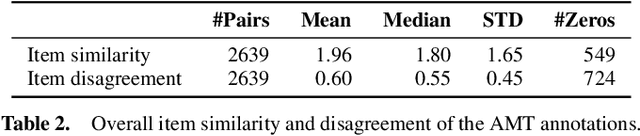
The combination of visual and textual representations has produced excellent results in tasks such as image captioning and visual question answering, but the inference capabilities of multimodal representations are largely untested. In the case of textual representations, inference tasks such as Textual Entailment and Semantic Textual Similarity have been often used to benchmark the quality of textual representations. The long term goal of our research is to devise multimodal representation techniques that improve current inference capabilities. We thus present a novel task, Visual Semantic Textual Similarity (vSTS), where such inference ability can be tested directly. Given two items comprised each by an image and its accompanying caption, vSTS systems need to assess the degree to which the captions in context are semantically equivalent to each other. Our experiments using simple multimodal representations show that the addition of image representations produces better inference, compared to text-only representations. The improvement is observed both when directly computing the similarity between the representations of the two items, and when learning a siamese network based on vSTS training data. Our work shows, for the first time, the successful contribution of visual information to textual inference, with ample room for benchmarking more complex multimodal representation options.
Block-matching in FPGA
Jun 24, 2020
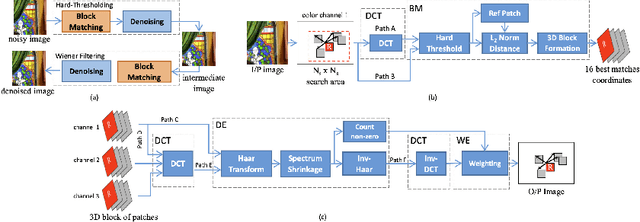
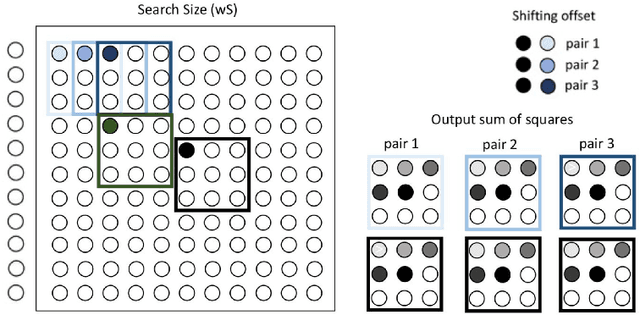
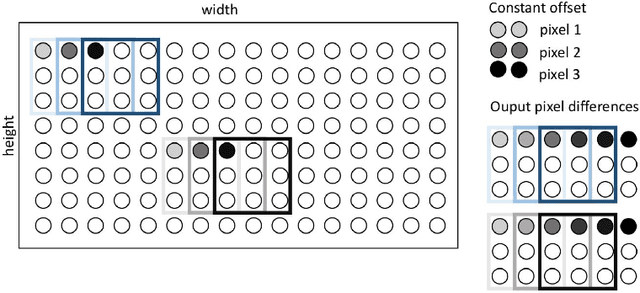
Block-matching and 3D filtering (BM3D) is an image denoising algorithm that works in two similar steps. Both of these steps need to perform grouping by block-matching. We implement the block-matching in an FPGA, leveraging its ability to perform parallel computations. Our goal is to enable other researchers to use our solution in the future for real-time video denoising in video cameras that use FPGAs (such as the AXIOM Beta).
V-variable image compression
Nov 28, 2014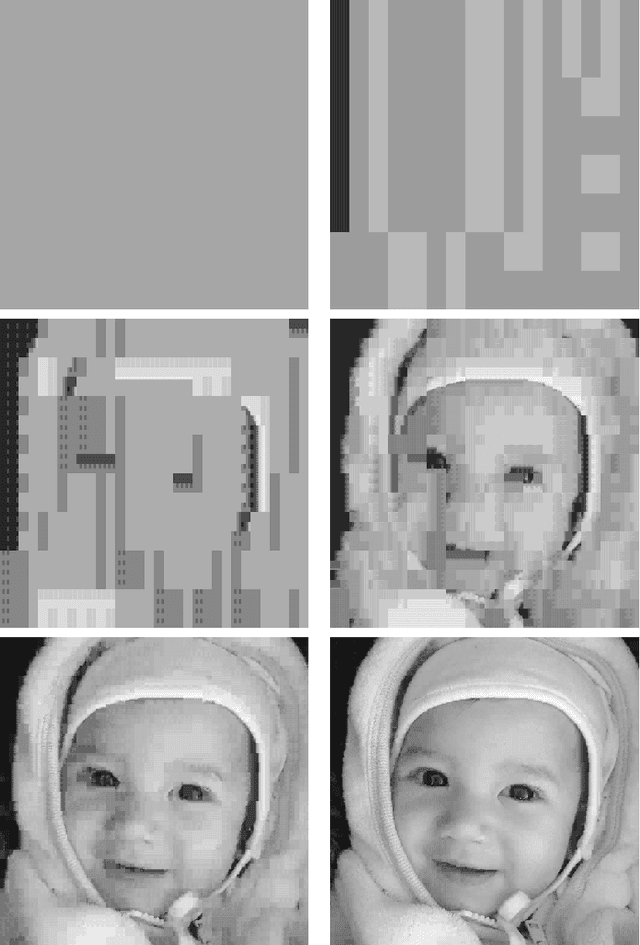
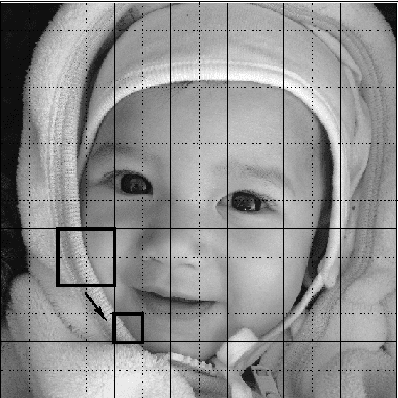


V-variable fractals, where $V$ is a positive integer, are intuitively fractals with at most $V$ different "forms" or "shapes" at all levels of magnification. In this paper we describe how V-variable fractals can be used for the purpose of image compression.
* 15 pages, 22 figures
SteReFo: Efficient Image Refocusing with Stereo Vision
Sep 29, 2019



Whether to attract viewer attention to a particular object, give the impression of depth or simply reproduce human-like scene perception, shallow depth of field images are used extensively by professional and amateur photographers alike. To this end, high quality optical systems are used in DSLR cameras to focus on a specific depth plane while producing visually pleasing bokeh. We propose a physically motivated pipeline to mimic this effect from all-in-focus stereo images, typically retrieved by mobile cameras. It is capable to change the focal plane a posteriori at 76 FPS on KITTI images to enable real-time applications. As our portmanteau suggests, SteReFo interrelates stereo-based depth estimation and refocusing efficiently. In contrast to other approaches, our pipeline is simultaneously fully differentiable, physically motivated, and agnostic to scene content. It also enables computational video focus tracking for moving objects in addition to refocusing of static images. We evaluate our approach on the publicly available datasets SceneFlow, KITTI, CityScapes and quantify the quality of architectural changes.
W2S: A Joint Denoising and Super-Resolution Dataset
Mar 12, 2020



Denoising and super-resolution (SR) are fundamental tasks in imaging. These two restoration tasks are well covered in the literature, however, only separately. Given a noisy low-resolution (LR) input image, it is yet unclear what the best approach would be in order to obtain a noise-free high-resolution (HR) image. In order to study joint denoising and super-resolution (JDSR), a dataset containing pairs of noisy LR images and the corresponding HR images is fundamental. We propose such a novel JDSR dataset, Wieldfield2SIM (W2S), acquired using microscopy equipment and techniques. W2S is comprised of 144,000 real fluorescence microscopy images, used to form a total of 360 sets of images. A set is comprised of noisy LR images with different noise levels, a noise-free LR image, and a corresponding high-quality HR image. W2S allows us to benchmark the combinations of 6 denoising methods and 6 SR methods. We show that state-of-the-art SR networks perform very poorly on noisy inputs, with a loss reaching 14dB relative to noise-free inputs. Our evaluation also shows that applying the best denoiser in terms of reconstruction error followed by the best SR method does not yield the best result. The best denoising PSNR can, for instance, come at the expense of a loss in high frequencies, which is detrimental for SR methods. We lastly demonstrate that a light-weight SR network with a novel texture loss, trained specifically for JDSR, outperforms any combination of state-of-the-art deep denoising and SR networks.
Zero-Shot Human-Object Interaction Recognition via Affordance Graphs
Sep 02, 2020

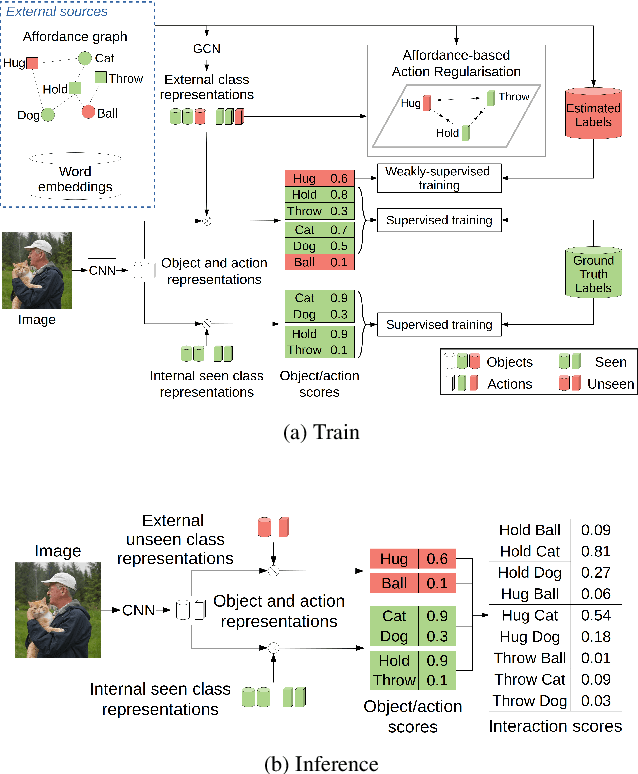
We propose a new approach for Zero-Shot Human-Object Interaction Recognition in the challenging setting that involves interactions with unseen actions (as opposed to just unseen combinations of seen actions and objects). Our approach makes use of knowledge external to the image content in the form of a graph that models affordance relations between actions and objects, i.e., whether an action can be performed on the given object or not. We propose a loss function with the aim of distilling the knowledge contained in the graph into the model, while also using the graph to regularise learnt representations by imposing a local structure on the latent space. We evaluate our approach on several datasets (including the popular HICO and HICO-DET) and show that it outperforms the current state of the art.
Is Robustness the Cost of Accuracy? -- A Comprehensive Study on the Robustness of 18 Deep Image Classification Models
Aug 05, 2018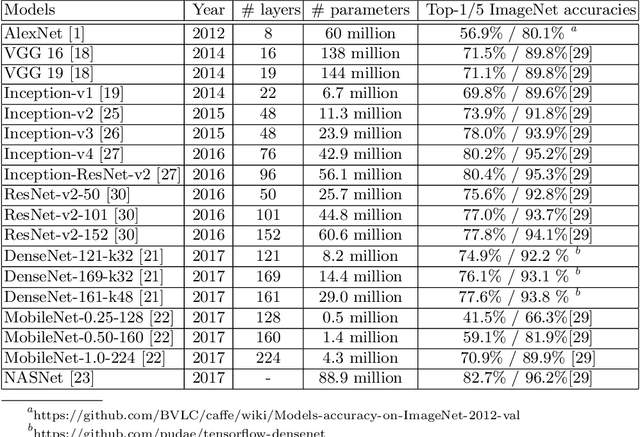
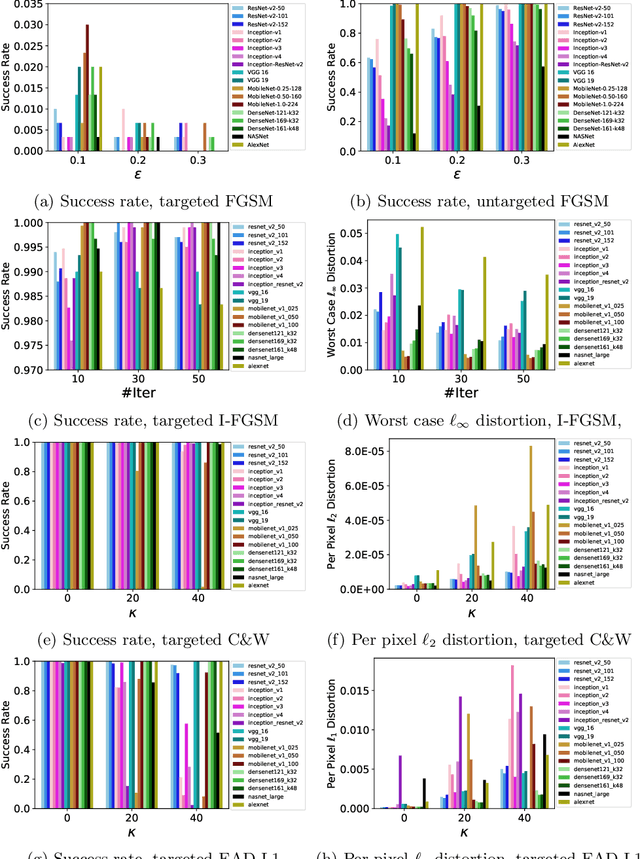
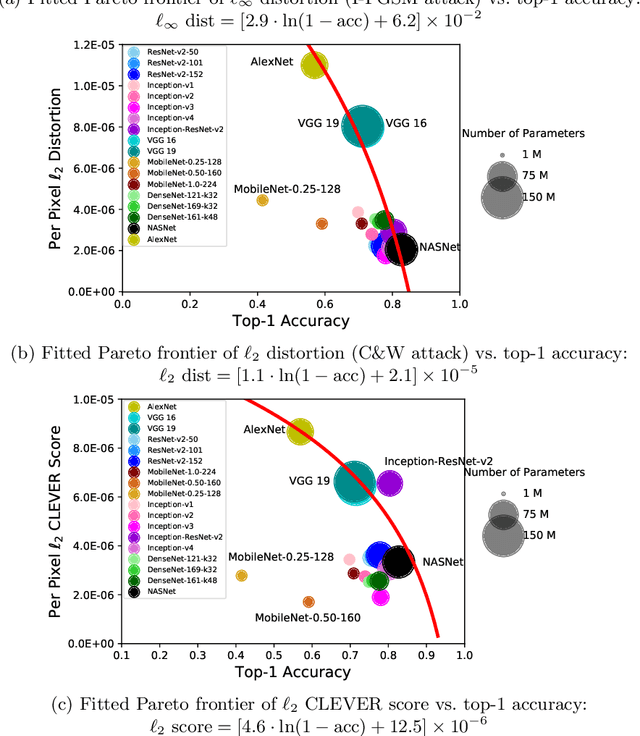
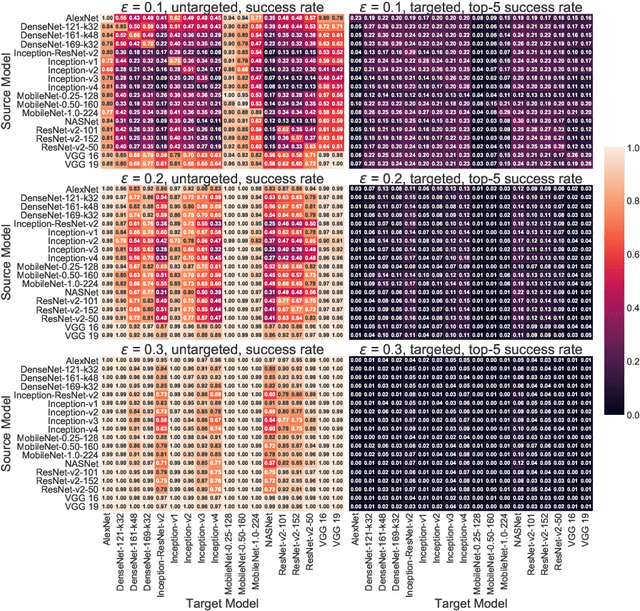
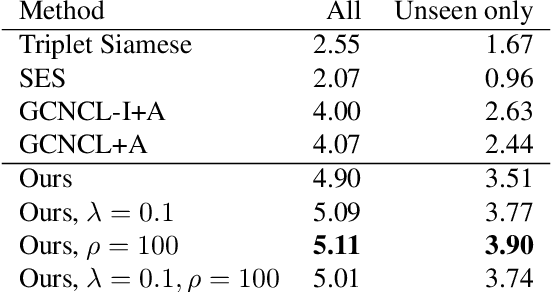
The prediction accuracy has been the long-lasting and sole standard for comparing the performance of different image classification models, including the ImageNet competition. However, recent studies have highlighted the lack of robustness in well-trained deep neural networks to adversarial examples. Visually imperceptible perturbations to natural images can easily be crafted and mislead the image classifiers towards misclassification. To demystify the trade-offs between robustness and accuracy, in this paper we thoroughly benchmark 18 ImageNet models using multiple robustness metrics, including the distortion, success rate and transferability of adversarial examples between 306 pairs of models. Our extensive experimental results reveal several new insights: (1) linear scaling law - the empirical $\ell_2$ and $\ell_\infty$ distortion metrics scale linearly with the logarithm of classification error; (2) model architecture is a more critical factor to robustness than model size, and the disclosed accuracy-robustness Pareto frontier can be used as an evaluation criterion for ImageNet model designers; (3) for a similar network architecture, increasing network depth slightly improves robustness in $\ell_\infty$ distortion; (4) there exist models (in VGG family) that exhibit high adversarial transferability, while most adversarial examples crafted from one model can only be transferred within the same family. Experiment code is publicly available at \url{https://github.com/huanzhang12/Adversarial_Survey}.