 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Human-Object Interaction Recognition via Affordance Graphs
Sep 02, 2020

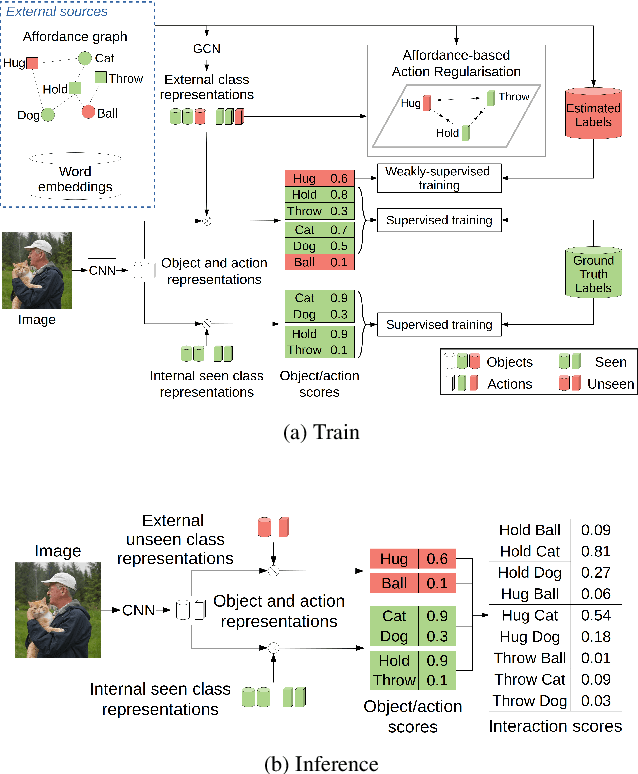
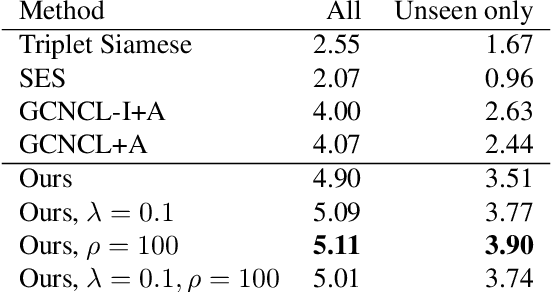
We propose a new approach for Zero-Shot Human-Object Interaction Recognition in the challenging setting that involves interactions with unseen actions (as opposed to just unseen combinations of seen actions and objects). Our approach makes use of knowledge external to the image content in the form of a graph that models affordance relations between actions and objects, i.e., whether an action can be performed on the given object or not. We propose a loss function with the aim of distilling the knowledge contained in the graph into the model, while also using the graph to regularise learnt representations by imposing a local structure on the latent space. We evaluate our approach on several datasets (including the popular HICO and HICO-DET) and show that it outperforms the current state of the art.
On Class Imbalance and Background Filtering in Visual Relationship Detection
Mar 21, 2019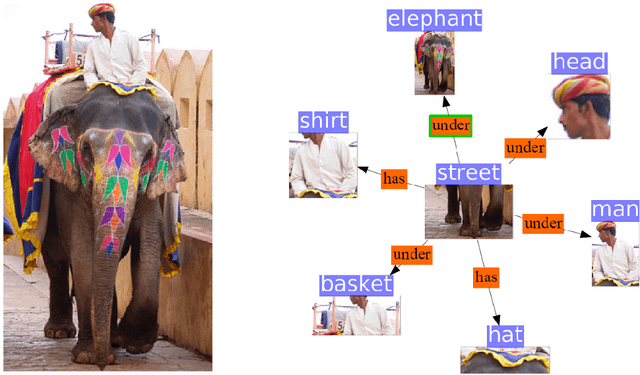
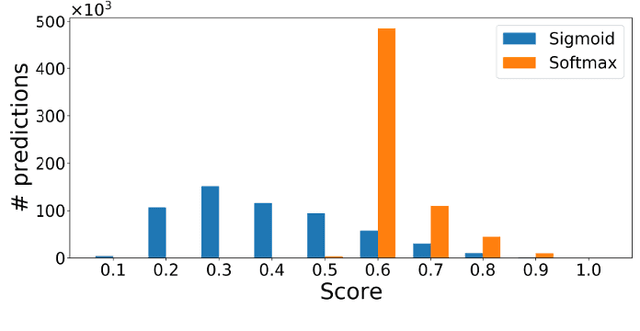
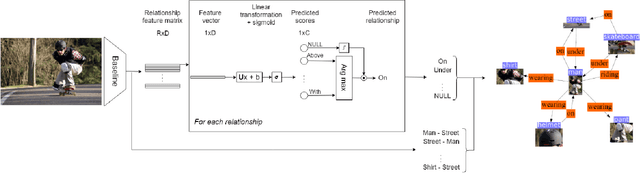
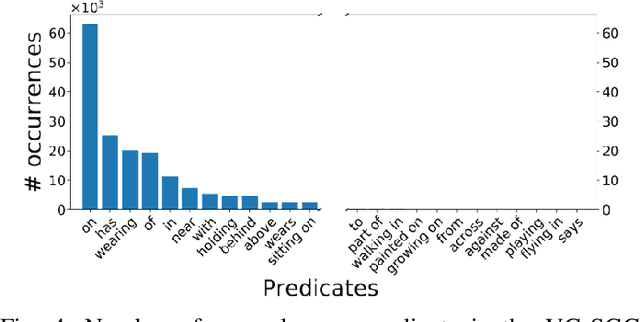
In this paper we investigate the problems of class imbalance and irrelevant relationships in Visual Relationship Detection (VRD). State-of-the-art deep VRD models still struggle to predict uncommon classes, limiting their applicability. Moreover, many methods are incapable of properly filtering out background relationships while predicting relevant ones. Although these problems are very apparent, they have both been overlooked so far. We analyse why this is the case and propose modifications to both model and training to alleviate the aforementioned issues, as well as suggesting new measures to complement existing ones and give a more holistic picture of the efficacy of a model.