 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Perceptually Weighted Rank Correlation Indicator for Objective Image Quality Assessment
May 15, 2017
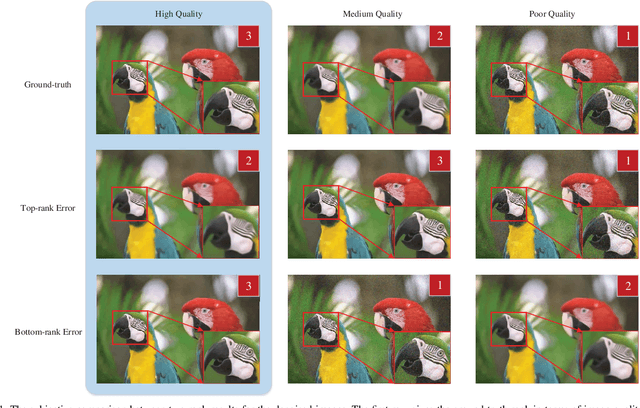

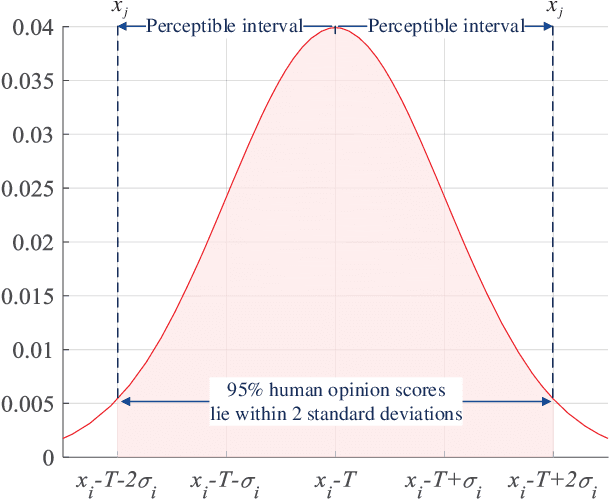
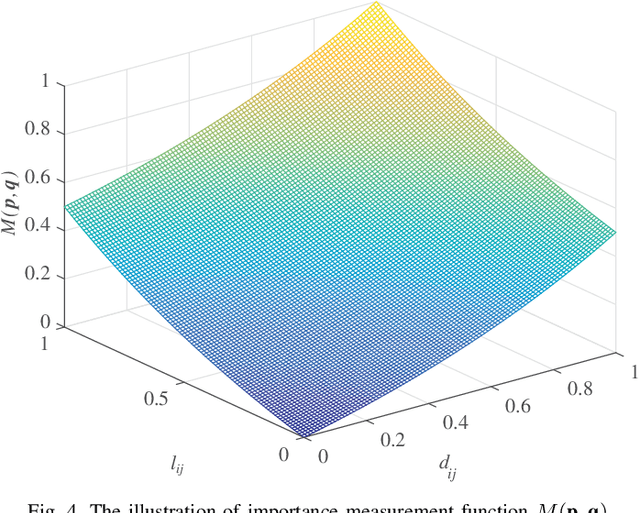
In the field of objective image quality assessment (IQA), the Spearman's $\rho$ and Kendall's $\tau$ are two most popular rank correlation indicators, which straightforwardly assign uniform weight to all quality levels and assume each pair of images are sortable. They are successful for measuring the average accuracy of an IQA metric in ranking multiple processed images. However, two important perceptual properties are ignored by them as well. Firstly, the sorting accuracy (SA) of high quality images are usually more important than the poor quality ones in many real world applications, where only the top-ranked images would be pushed to the users. Secondly, due to the subjective uncertainty in making judgement, two perceptually similar images are usually hardly sortable, whose ranks do not contribute to the evaluation of an IQA metric. To more accurately compare different IQA algorithms, we explore a perceptually weighted rank correlation indicator in this paper, which rewards the capability of correctly ranking high quality images, and suppresses the attention towards insensitive rank mistakes. More specifically, we focus on activating `valid' pairwise comparison towards image quality, whose difference exceeds a given sensory threshold (ST). Meanwhile, each image pair is assigned an unique weight, which is determined by both the quality level and rank deviation. By modifying the perception threshold, we can illustrate the sorting accuracy with a more sophisticated SA-ST curve, rather than a single rank correlation coefficient. The proposed indicator offers a new insight for interpreting visual perception behaviors. Furthermore, the applicability of our indicator is validated in recommending robust IQA metrics for both the degraded and enhanced image data.
SafeNet: An Assistive Solution to Assess Incoming Threats for Premises
Jan 27, 2020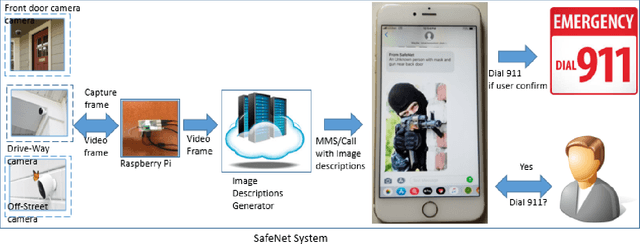
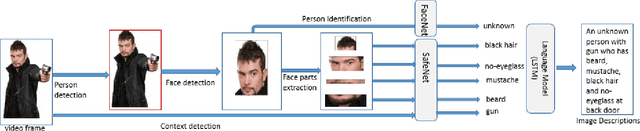
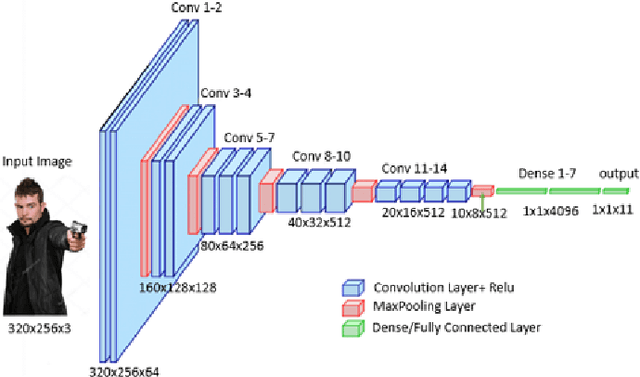
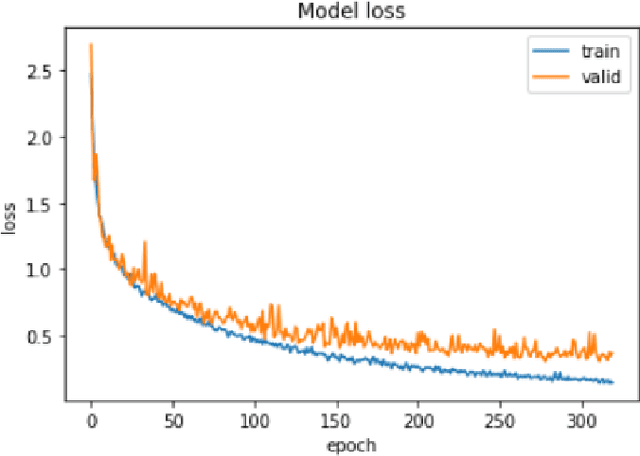
An assistive solution to assess incoming threats (e.g., robbery, burglary, gun violence) for homes will enhance the safety of the people with or without disabilities. This paper presents "SafeNet"- an integrated assistive system to generate context-oriented image descriptions to assess incoming threats. The key functionality of the system includes the detection and identification of human and generating image descriptions from the real-time video streams obtained from the cameras placed in strategic locations around the house. In this paper, we focus on developing a robust model called "SafeNet" to generate image descriptions. To interact with the system, we implemented a dialog enabled interface for creating a personalized profile from face images or videos of friends/families. To improve computational efficiency, we apply change detection to filter out frames that do not have any activity and use Faster-RCNN to detect the human presence and extract faces using Multitask Cascaded Convolutional Networks (MTCNN). Subsequently, we apply LBP/FaceNet to identify a person. SafeNet sends image descriptions to the users with an MMS containing a person's name if any match found or as "Unknown", scene image, facial description, and contextual information. SafeNet identifies friends/families/caregiver versus intruders/unknown with an average F-score 0.97 and generates image descriptions from 10 classes with an average F-measure 0.97.
A Review and Comparative Study on Probabilistic Object Detection in Autonomous Driving
Nov 20, 2020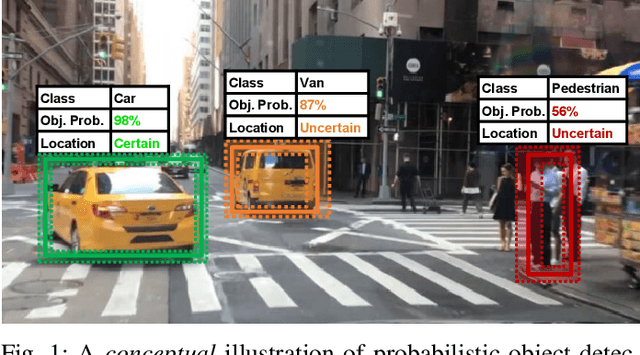
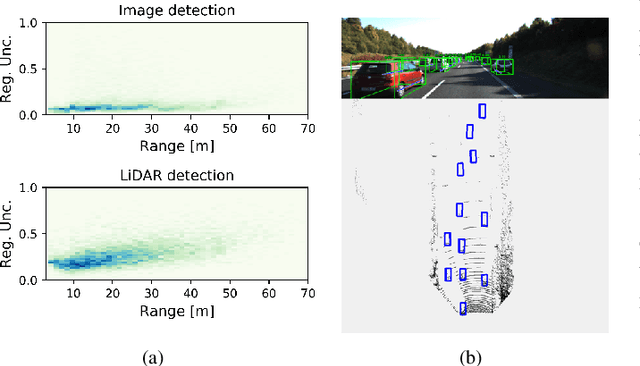
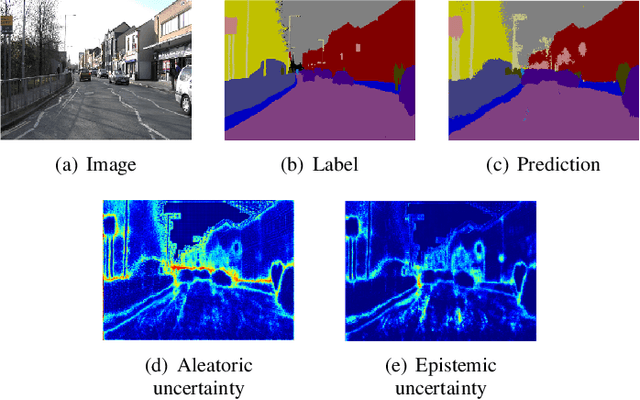
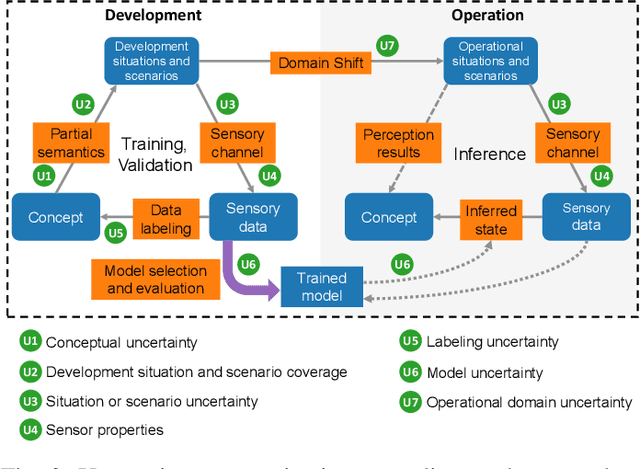
Capturing uncertainty in object detection is indispensable for safe autonomous driving. In recent years, deep learning has become the de-facto approach for object detection, and many probabilistic object detectors have been proposed. However, there is no summary on uncertainty estimation in deep object detection, and existing methods are not only built with different network architectures and uncertainty estimation methods, but also evaluated on different datasets with a wide range of evaluation metrics. As a result, a comparison among methods remains challenging, as does the selection of a model that best suits a particular application. This paper aims to alleviate this problem by providing a review and comparative study on existing probabilistic object detection methods for autonomous driving applications. First, we provide an overview of generic uncertainty estimation in deep learning, and then systematically survey existing methods and evaluation metrics for probabilistic object detection. Next, we present a strict comparative study for probabilistic object detection based on an image detector and three public autonomous driving datasets. Finally, we present a discussion of the remaining challenges and future works. Code has been made available at https://github.com/asharakeh/pod_compare.git
Compressing Images by Encoding Their Latent Representations with Relative Entropy Coding
Oct 27, 2020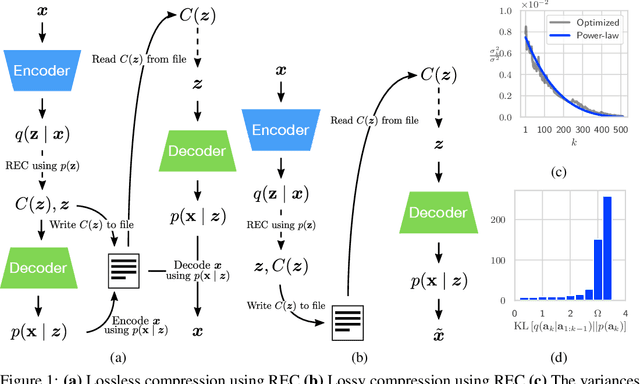
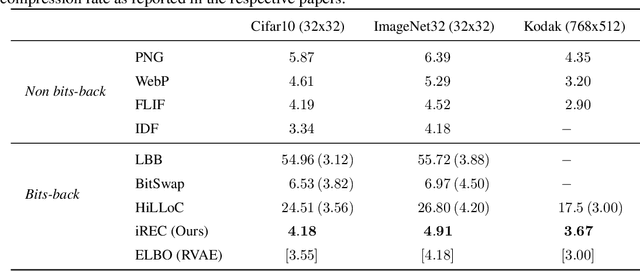
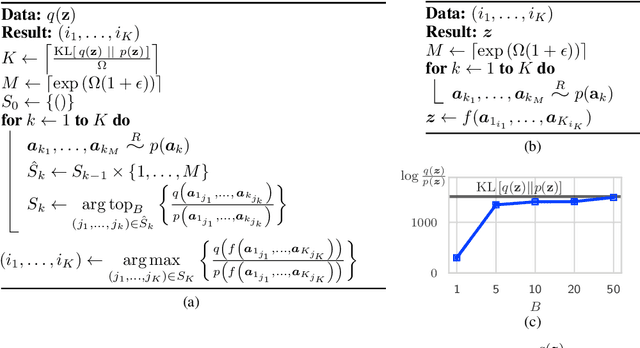
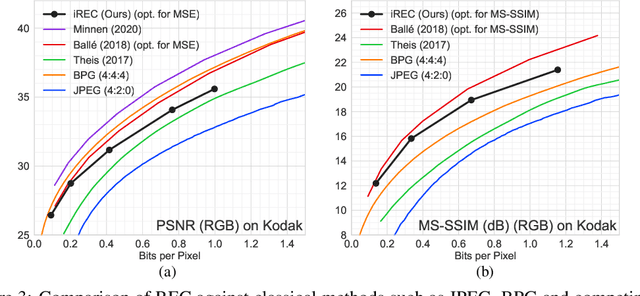
Variational Autoencoders (VAEs) have seen widespread use in learned image compression. They are used to learn expressive latent representations on which downstream compression methods can operate with high efficiency. Recently proposed 'bits-back' methods can indirectly encode the latent representation of images with codelength close to the relative entropy between the latent posterior and the prior. However, due to the underlying algorithm, these methods can only be used for lossless compression, and they only achieve their nominal efficiency when compressing multiple images simultaneously; they are inefficient for compressing single images. As an alternative, we propose a novel method, Relative Entropy Coding (REC), that can directly encode the latent representation with codelength close to the relative entropy for single images, supported by our empirical results obtained on the Cifar10, ImageNet32 and Kodak datasets. Moreover, unlike previous bits-back methods, REC is immediately applicable to lossy compression, where it is competitive with the state-of-the-art on the Kodak dataset.
PRVNet: Variational Autoencoders for Massive MIMO CSI Feedback
Nov 09, 2020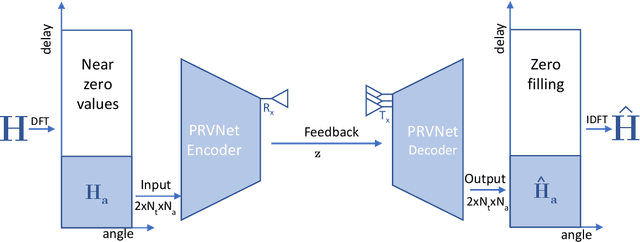
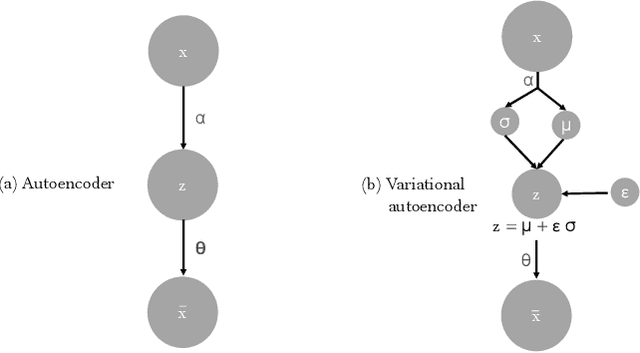
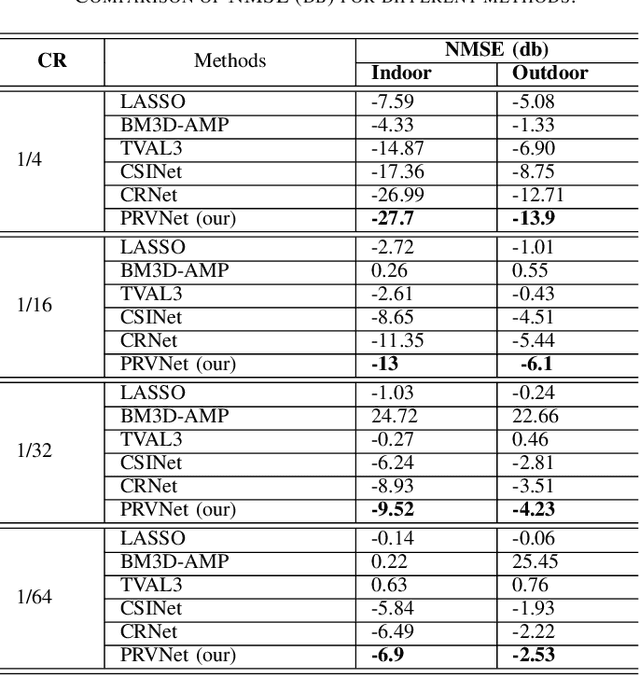

In a frequency division duplexing multiple-input multiple-output (FDD-MIMO) system, the user equipment (UE) send the downlink channel state information (CSI) to the base station for performance improvement. However, with the growing complexity of MIMO systems, this feedback becomes expensive and has a negative impact on the bandwidth. Although this problem has been largely studied in the literature, the noisy nature of the feedback channel is less considered. In this paper, we introduce PRVNet, a neural architecture based on variational autoencoders (VAE). VAE gained large attention in many fields (e.g., image processing, language models, or recommendation system). However, it received less attention in the communication domain generally and in CSI feedback problem specifically. We also introduce a different regularization parameter for the learning objective, which proved to be crucial for achieving competitive performance. In addition, we provide an efficient way to tune this parameter using KL-annealing. Empirically, we show that the proposed model significantly outperforms state-of-the-art, including two neural network approaches. The proposed model is also proved to be more robust against different levels of noise.
Deblurring using Analysis-Synthesis Networks Pair
Apr 06, 2020
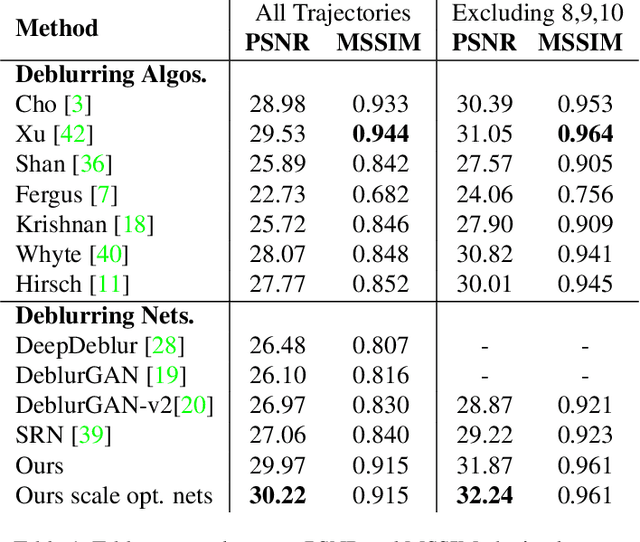
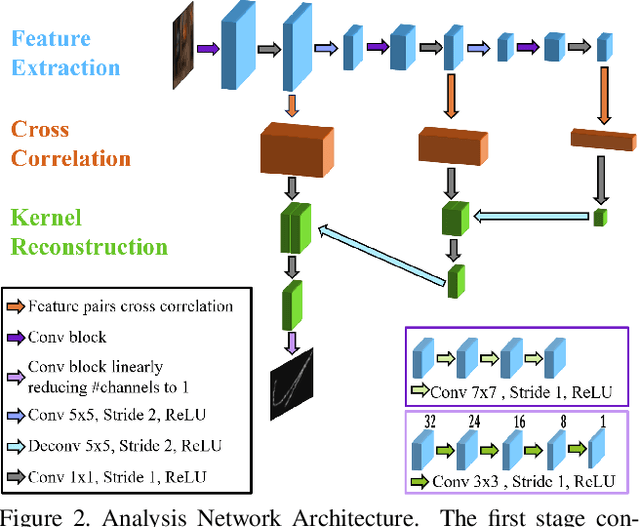
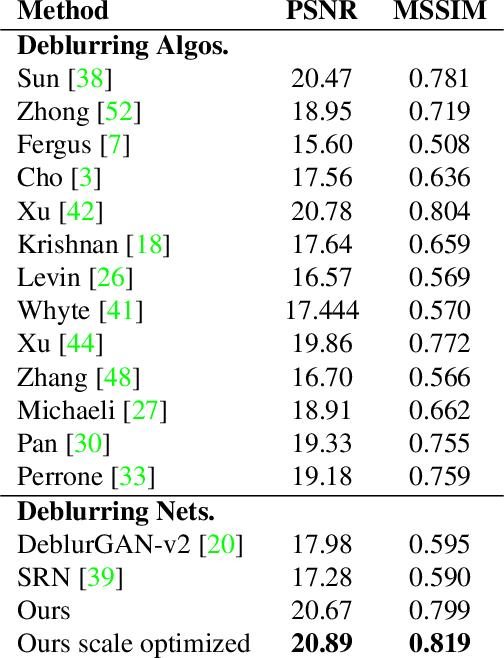
Blind image deblurring remains a challenging problem for modern artificial neural networks. Unlike other image restoration problems, deblurring networks fail behind the performance of existing deblurring algorithms in case of uniform and 3D blur models. This follows from the diverse and profound effect that the unknown blur-kernel has on the deblurring operator. We propose a new architecture which breaks the deblurring network into an analysis network which estimates the blur, and a synthesis network that uses this kernel to deblur the image. Unlike existing deblurring networks, this design allows us to explicitly incorporate the blur-kernel in the network's training. In addition, we introduce new cross-correlation layers that allow better blur estimations, as well as unique components that allow the estimate blur to control the action of the synthesis deblurring action. Evaluating the new approach over established benchmark datasets shows its ability to achieve state-of-the-art deblurring accuracy on various tests, as well as offer a major speedup in runtime.
A New Multifocus Image Fusion Method Using Contourlet Transform
Sep 13, 2017A new multifocus image fusion approach is presented in this paper. First the contourlet transform is used to decompose the source images into different components. Then, some salient features are extracted from components. In order to extract salient features, spatial frequency is used. Subsequently, the best coefficients from the components are selected by the maximum selection rule. Finally, the inverse contourlet transform is applied to the selected coefficients. Experiments show the superiority of the proposed method.
Lung Segmentation from Chest X-rays using Variational Data Imputation
May 20, 2020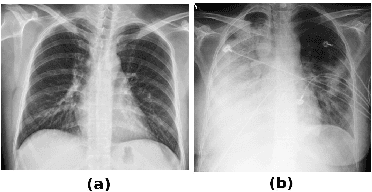
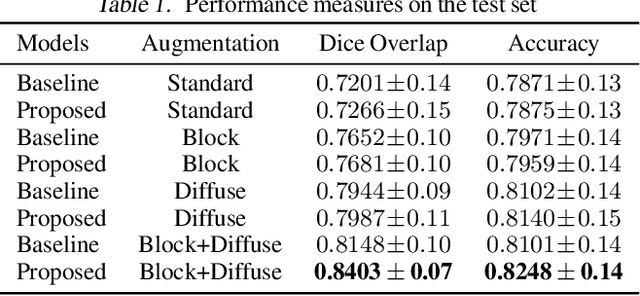
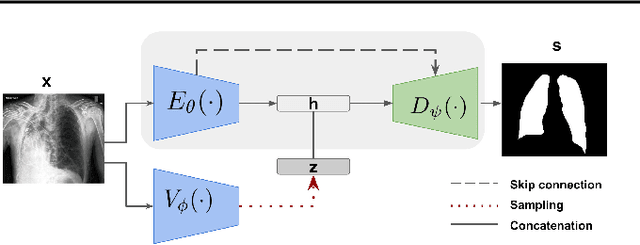
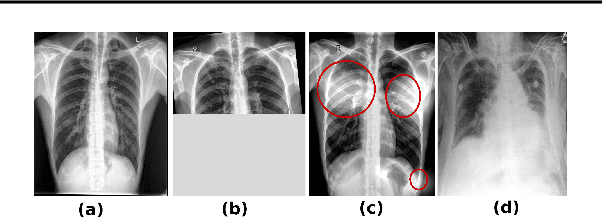
Pulmonary opacification is the inflammation in the lungs caused by many respiratory ailments, including the novel corona virus disease 2019 (COVID-19). Chest X-rays (CXRs) with such opacifications render regions of lungs imperceptible, making it difficult to perform automated image analysis on them. In this work, we focus on segmenting lungs from such abnormal CXRs as part of a pipeline aimed at automated risk scoring of COVID-19 from CXRs. We treat the high opacity regions as missing data and present a modified CNN-based image segmentation network that utilizes a deep generative model for data imputation. We train this model on normal CXRs with extensive data augmentation and demonstrate the usefulness of this model to extend to cases with extreme abnormalities.
Fast Constraint Propagation for Image Segmentation
Feb 05, 2015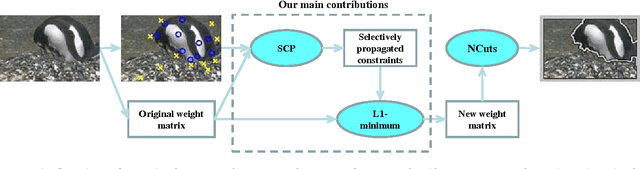



This paper presents a novel selective constraint propagation method for constrained image segmentation. In the literature, many pairwise constraint propagation methods have been developed to exploit pairwise constraints for cluster analysis. However, since most of these methods have a polynomial time complexity, they are not much suitable for segmentation of images even with a moderate size, which is actually equivalent to cluster analysis with a large data size. Considering the local homogeneousness of a natural image, we choose to perform pairwise constraint propagation only over a selected subset of pixels, but not over the whole image. Such a selective constraint propagation problem is then solved by an efficient graph-based learning algorithm. To further speed up our selective constraint propagation, we also discard those less important propagated constraints during graph-based learning. Finally, the selectively propagated constraints are exploited based on $L_1$-minimization for normalized cuts over the whole image. The experimental results demonstrate the promising performance of the proposed method for segmentation with selectively propagated constraints.
Price Suggestion for Online Second-hand Items with Texts and Images
Dec 10, 2020
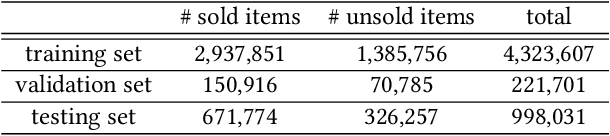

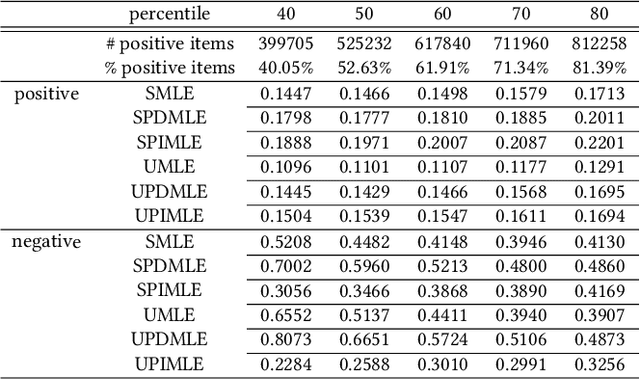
This paper presents an intelligent price suggestion system for online second-hand listings based on their uploaded images and text descriptions. The goal of price prediction is to help sellers set effective and reasonable prices for their second-hand items with the images and text descriptions uploaded to the online platforms. Specifically, we design a multi-modal price suggestion system which takes as input the extracted visual and textual features along with some statistical item features collected from the second-hand item shopping platform to determine whether the image and text of an uploaded second-hand item are qualified for reasonable price suggestion with a binary classification model, and provide price suggestions for second-hand items with qualified images and text descriptions with a regression model. To satisfy different demands, two different constraints are added into the joint training of the classification model and the regression model. Moreover, a customized loss function is designed for optimizing the regression model to provide price suggestions for second-hand items, which can not only maximize the gain of the sellers but also facilitate the online transaction. We also derive a set of metrics to better evaluate the proposed price suggestion system. Extensive experiments on a large real-world dataset demonstrate the effectiveness of the proposed multi-modal price suggestion system.