 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Soft Tissue Sarcoma Co-Segmentation in Combined MRI and PET/CT Data
Aug 28, 2020
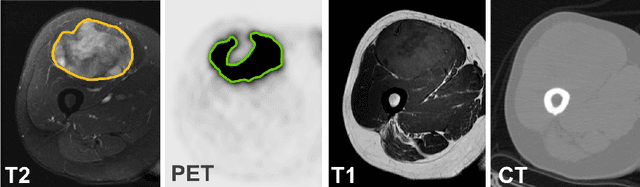
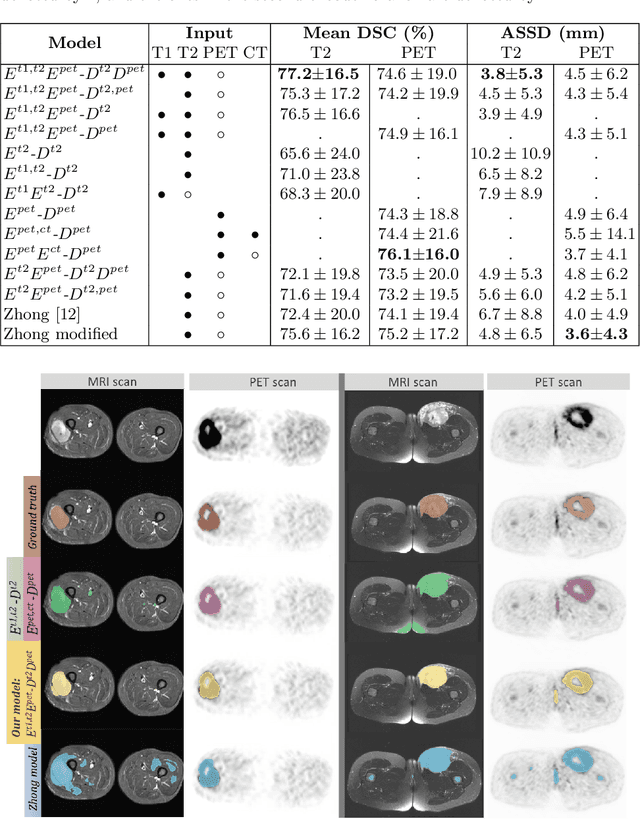
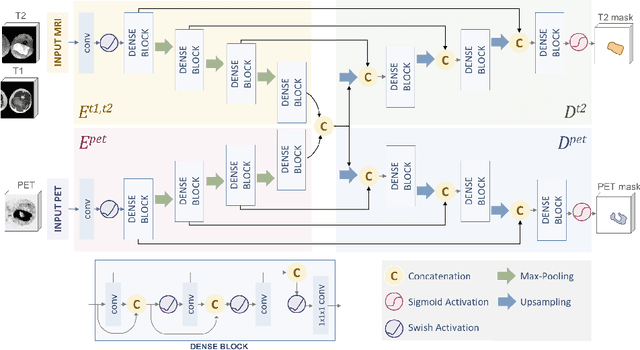
Tumor segmentation in multimodal medical images has seen a growing trend towards deep learning based methods. Typically, studies dealing with this topic fuse multimodal image data to improve the tumor segmentation contour for a single imaging modality. However, they do not take into account that tumor characteristics are emphasized differently by each modality, which affects the tumor delineation. Thus, the tumor segmentation is modality- and task-dependent. This is especially the case for soft tissue sarcomas, where, due to necrotic tumor tissue, the segmentation differs vastly. Closing this gap, we develop a modalityspecific sarcoma segmentation model that utilizes multimodal image data to improve the tumor delineation on each individual modality. We propose a simultaneous co-segmentation method, which enables multimodal feature learning through modality-specific encoder and decoder branches, and the use of resource-effcient densely connected convolutional layers. We further conduct experiments to analyze how different input modalities and encoder-decoder fusion strategies affect the segmentation result. We demonstrate the effectiveness of our approach on public soft tissue sarcoma data, which comprises MRI (T1 and T2 sequence) and PET/CT scans. The results show that our multimodal co-segmentation model provides better modality-specific tumor segmentation than models using only the PET or MRI (T1 and T2) scan as input.
Rotation Invariant Deep CBIR
Jun 21, 2020
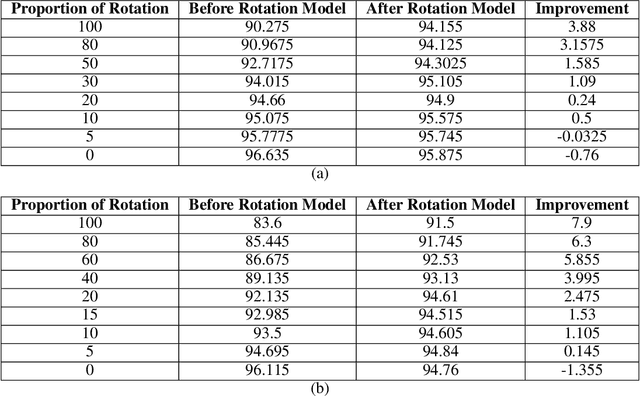
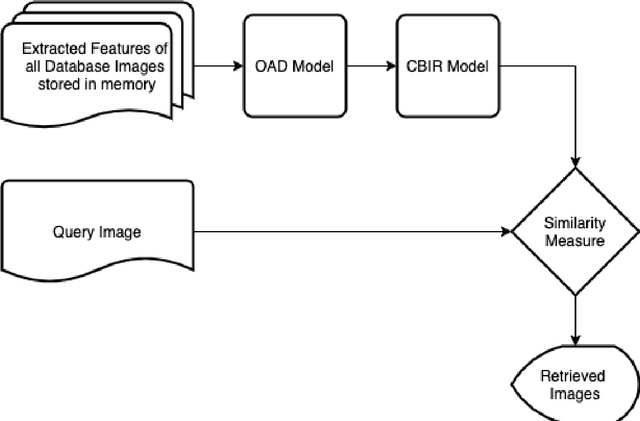

Introduction of Convolutional Neural Networks has improved results on almost every image-based problem and Content-Based Image Retrieval is not an exception. But the CNN features, being rotation invariant, creates problems to build a rotation-invariant CBIR system. Though rotation-invariant features can be hand-engineered, the retrieval accuracy is very low because by hand engineering only low-level features can be created, unlike deep learning models that create high-level features along with low-level features. This paper shows a novel method to build a rotational invariant CBIR system by introducing a deep learning orientation angle detection model along with the CBIR feature extraction model. This paper also highlights that this rotation invariant deep CBIR can retrieve images from a large dataset in real-time.
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization
Jun 29, 2020
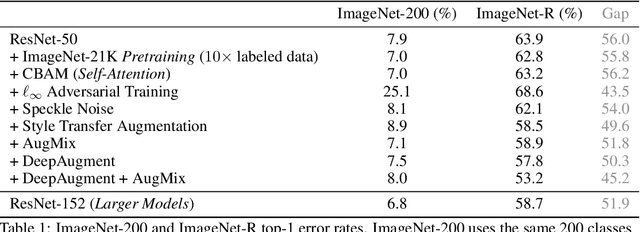

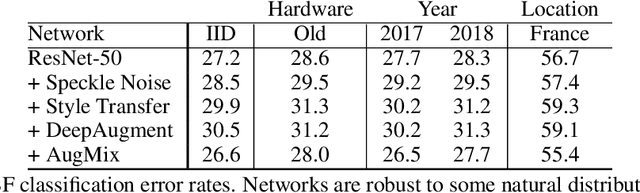
We introduce three new robustness benchmarks consisting of naturally occurring distribution changes in image style, geographic location, camera operation, and more. Using our benchmarks, we take stock of previously proposed hypotheses for out-of-distribution robustness and put them to the test. We find that using larger models and synthetic data augmentation can improve robustness on real-world distribution shifts, contrary to claims in prior work. Motivated by this, we introduce a new data augmentation method which advances the state-of-the-art and outperforms models pretrained with 1000x more labeled data. We find that some methods consistently help with distribution shifts in texture and local image statistics, but these methods do not help with some other distribution shifts like geographic changes. We conclude that future research must study multiple distribution shifts simultaneously.
Multimedia Respiratory Database (RespiratoryDatabase@TR): Auscultation Sounds and Chest X-rays
Jan 21, 2021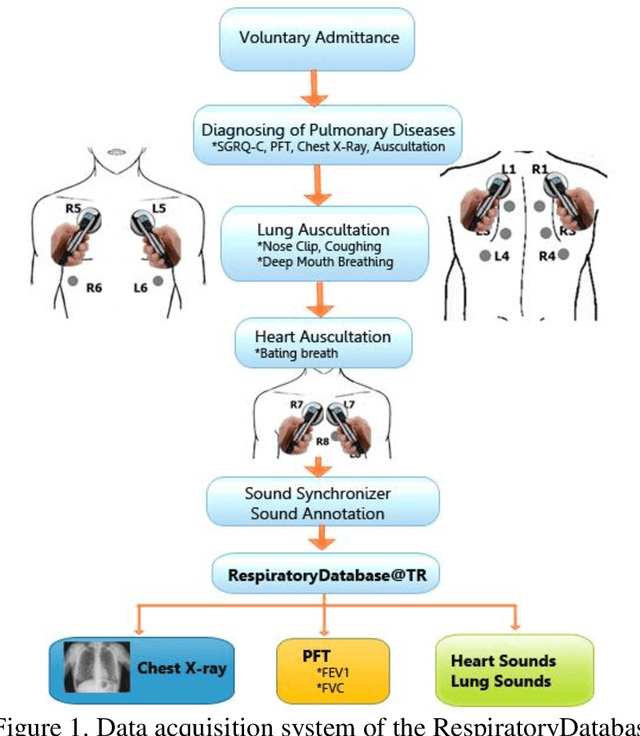
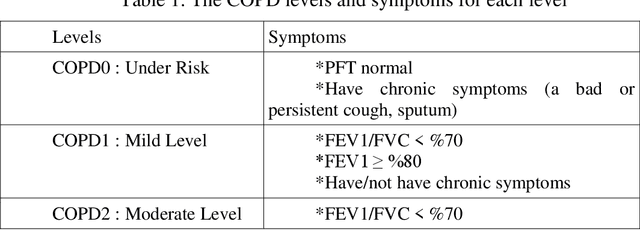
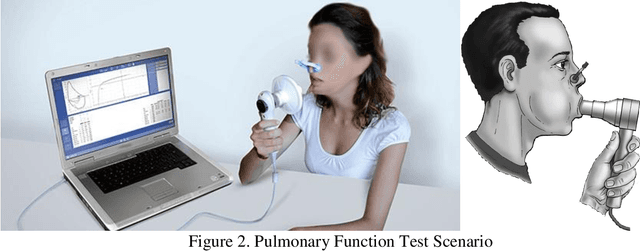
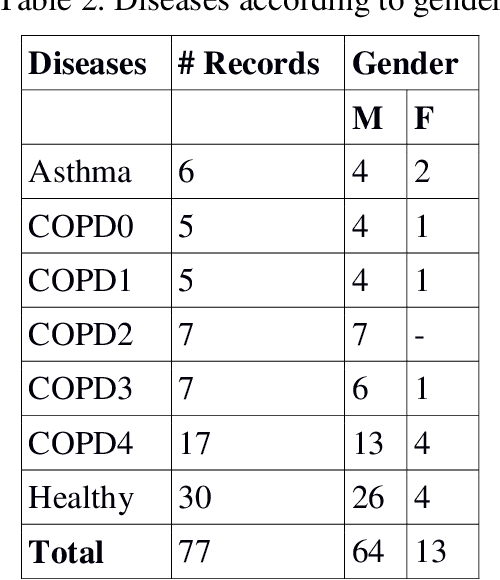
Auscultation is a method for diagnosis of especially internal medicine diseases such as cardiac, pulmonary and cardio-pulmonary by listening the internal sounds from the body parts. It is the simplest and the most common physical examination in the assessment processes of the clinical skills. In this study, the lung and heart sounds are recorded synchronously from left and right sides of posterior and anterior chest wall and back using two digital stethoscopes in Antakya State Hospital. The chest X-rays and the pulmonary function test variables and spirometric curves, the St. George respiratory questionnaire (SGRQ-C) are collected as multimedia and clinical functional analysis variables of the patients. The 4 channels of heart sounds are focused on aortic, pulmonary, tricuspid and mitral areas. The 12 channels of lung sounds are focused on upper lung, middle lung, lower lung and costophrenic angle areas of posterior and anterior sides of the chest. The recordings are validated and labelled by two pulmonologists evaluating the collected chest x-ray, PFT and auscultation sounds of the subjects. The database consists of 30 healthy subjects and 45 subjects with pulmonary diseases such as asthma, chronic obstructive pulmonary disease, bronchitis. The novelties of the database are the combination ability between auscultation sound results, chest X-ray and PFT; synchronously assessment capability of the lungs sounds; image processing based computerized analysis of the respiratory using chest X-ray and providing opportunity for improving analysis of both lung sounds and heart sounds on pulmonary and cardiac diseases.
* 14 pages, 7 figures, Natural and Engineering Sciences
BézierSketch: A generative model for scalable vector sketches
Jul 14, 2020
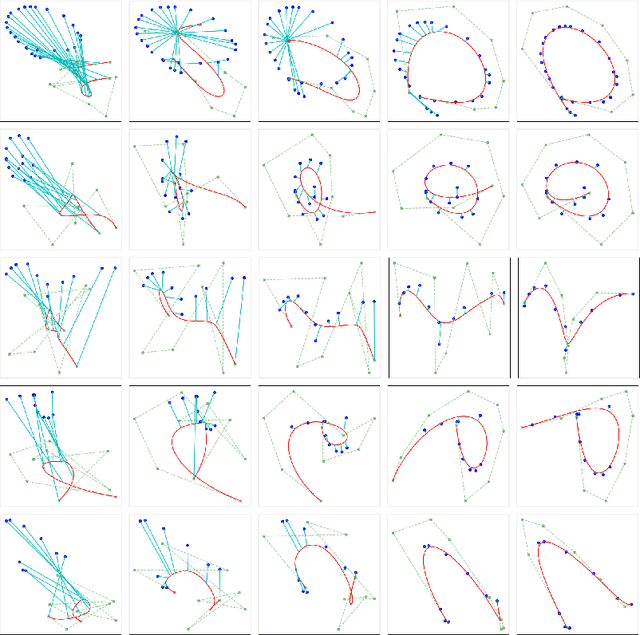
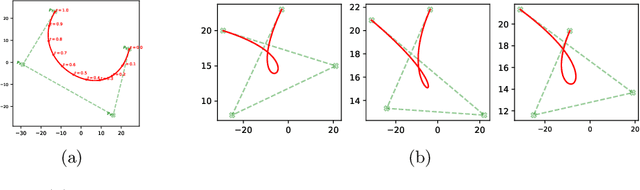
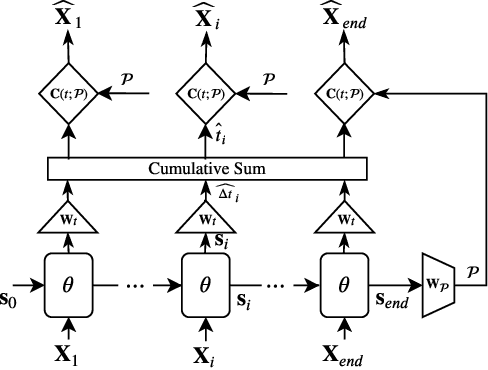
The study of neural generative models of human sketches is a fascinating contemporary modeling problem due to the links between sketch image generation and the human drawing process. The landmark SketchRNN provided breakthrough by sequentially generating sketches as a sequence of waypoints. However this leads to low-resolution image generation, and failure to model long sketches. In this paper we present B\'ezierSketch, a novel generative model for fully vector sketches that are automatically scalable and high-resolution. To this end, we first introduce a novel inverse graphics approach to stroke embedding that trains an encoder to embed each stroke to its best fit B\'ezier curve. This enables us to treat sketches as short sequences of paramaterized strokes and thus train a recurrent sketch generator with greater capacity for longer sketches, while producing scalable high-resolution results. We report qualitative and quantitative results on the Quick, Draw! benchmark.
Multi-view metric learning for multi-instance image classification
Oct 21, 2016
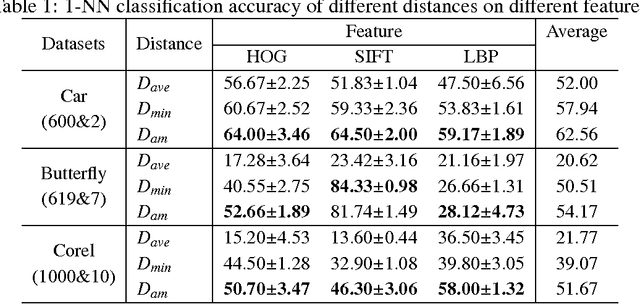
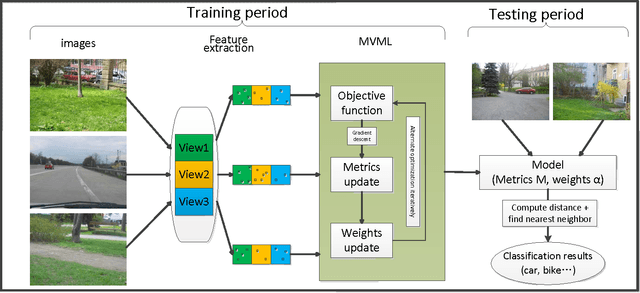
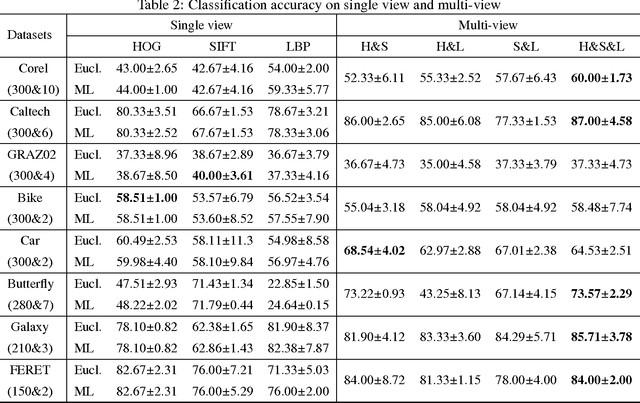
It is critical and meaningful to make image classification since it can help human in image retrieval and recognition, object detection, etc. In this paper, three-sides efforts are made to accomplish the task. First, visual features with bag-of-words representation, not single vector, are extracted to characterize the image. To improve the performance, the idea of multi-view learning is implemented and three kinds of features are provided, each one corresponds to a single view. The information from three views is complementary to each other, which can be unified together. Then a new distance function is designed for bags by computing the weighted sum of the distances between instances. The technique of metric learning is explored to construct a data-dependent distance metric to measure the relationships between instances, meanwhile between bags and images, more accurately. Last, a novel approach, called MVML, is proposed, which optimizes the joint probability that every image is similar with its nearest image. MVML learns multiple distance metrics, each one models a single view, to unifies the information from multiple views. The method can be solved by alternate optimization iteratively. Gradient ascent and positive semi-definite projection are utilized in the iterations. Distance comparisons verified that the new bag distance function is prior to previous functions. In model evaluation, numerical experiments show that MVML with multiple views performs better than single view condition, which demonstrates that our model can assemble the complementary information efficiently and measure the distance between images more precisely. Experiments on influence of parameters and instance number validate the consistency of the method.
Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
Apr 11, 2019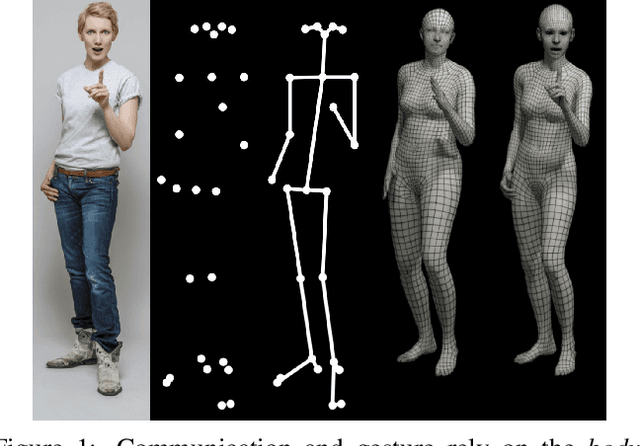

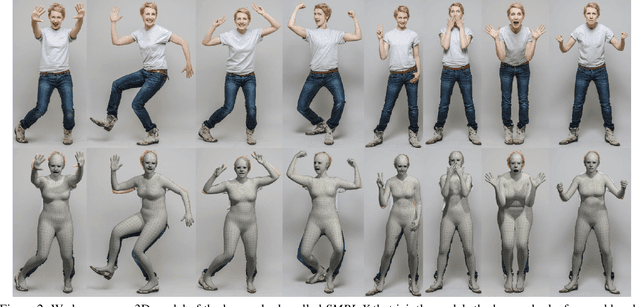

To facilitate the analysis of human actions, interactions and emotions, we compute a 3D model of human body pose, hand pose, and facial expression from a single monocular image. To achieve this, we use thousands of 3D scans to train a new, unified, 3D model of the human body, SMPL-X, that extends SMPL with fully articulated hands and an expressive face. Learning to regress the parameters of SMPL-X directly from images is challenging without paired images and 3D ground truth. Consequently, we follow the approach of SMPLify, which estimates 2D features and then optimizes model parameters to fit the features. We improve on SMPLify in several significant ways: (1) we detect 2D features corresponding to the face, hands, and feet and fit the full SMPL-X model to these; (2) we train a new neural network pose prior using a large MoCap dataset; (3) we define a new interpenetration penalty that is both fast and accurate; (4) we automatically detect gender and the appropriate body models (male, female, or neutral); (5) our PyTorch implementation achieves a speedup of more than 8x over Chumpy. We use the new method, SMPLify-X, to fit SMPL-X to both controlled images and images in the wild. We evaluate 3D accuracy on a new curated dataset comprising 100 images with pseudo ground-truth. This is a step towards automatic expressive human capture from monocular RGB data. The models, code, and data are available for research purposes at https://smpl-x.is.tue.mpg.de.
Time series classification for predictive maintenance on event logs
Nov 22, 2020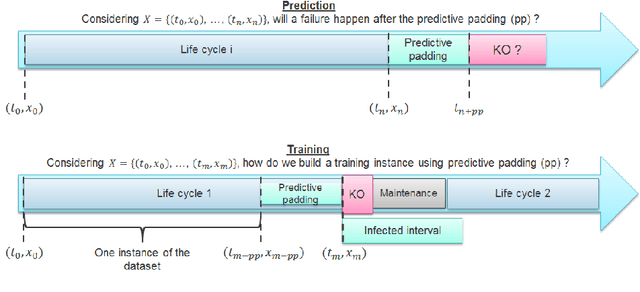
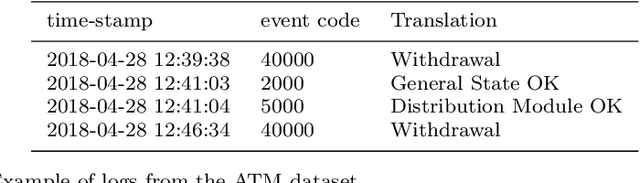
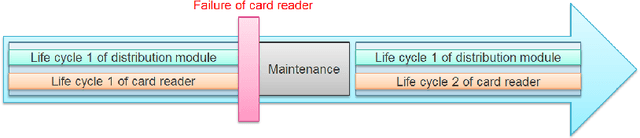
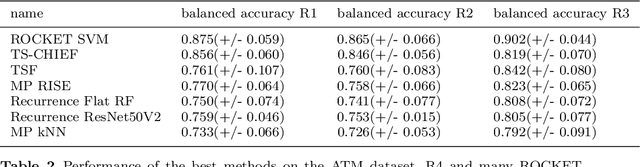
Time series classification (TSC) gained a lot of attention in the pastdecade and number of methods for representing and classifying time series havebeen proposed. Nowadays, methods based on convolutional networks and ensembletechniques represent the state of the art for time series classification. Techniquestransforming time series to image or text also provide reliable ways to extractmeaningful features or representations of time series. We compare the state-of-the-art representation and classification methods on a specific application, thatis predictive maintenance from sequences of event logs. The contributions of thispaper are twofold: introducing a new data set for predictive maintenance on auto-mated teller machines (ATMs) log data and comparing the performance of differentrepresentation methods for predicting the occurrence of a breakdown. The prob-lem is difficult since unlike the classic case of predictive maintenance via signalsfrom sensors, we have sequences of discrete event logs occurring at any time andthe lengths of the sequences, corresponding to life cycles, vary a lot.
QReLU and m-QReLU: Two novel quantum activation functions to aid medical diagnostics
Oct 15, 2020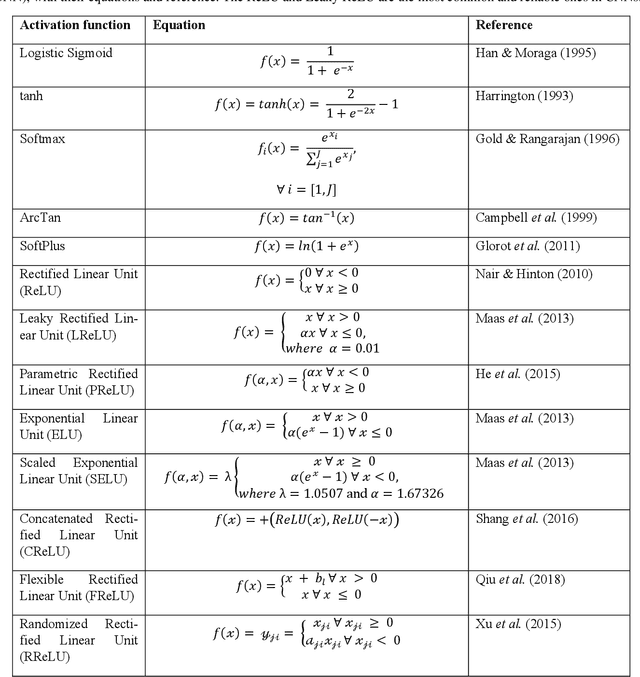
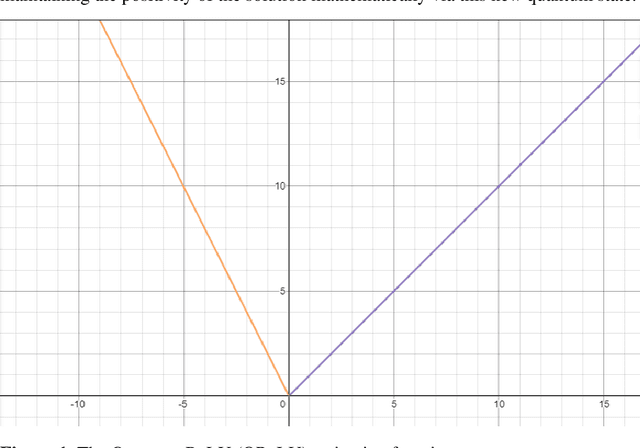
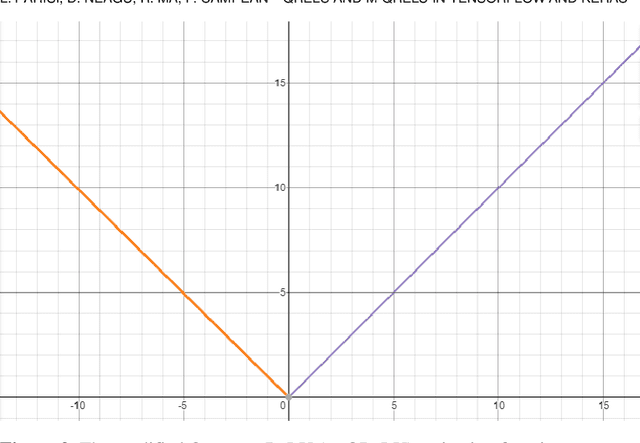
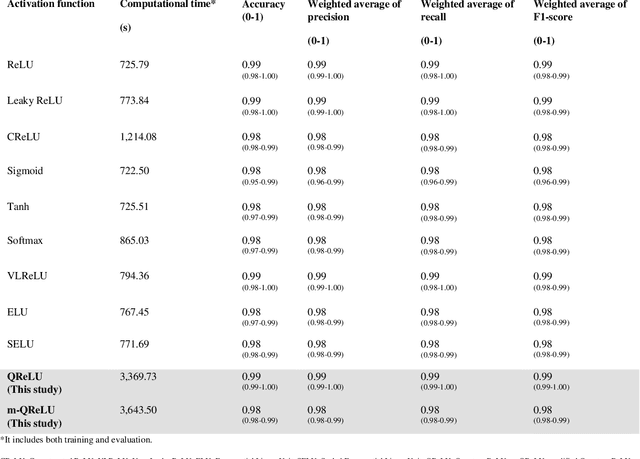
The ReLU activation function (AF) has been extensively applied in deep neural networks, in particular Convolutional Neural Networks (CNN), for image classification despite its unresolved dying ReLU problem, which poses challenges to reliable applications. This issue has obvious important implications for critical applications, such as those in healthcare. Recent approaches are just proposing variations of the activation function within the same unresolved dying ReLU challenge. This contribution reports a different research direction by investigating the development of an innovative quantum approach to the ReLU AF that avoids the dying ReLU problem by disruptive design. The Leaky ReLU was leveraged as a baseline on which the two quantum principles of entanglement and superposition were applied to derive the proposed Quantum ReLU (QReLU) and the modified-QReLU (m-QReLU) activation functions. Both QReLU and m-QReLU are implemented and made freely available in TensorFlow and Keras. This original approach is effective and validated extensively in case studies that facilitate the detection of COVID-19 and Parkinson Disease (PD) from medical images. The two novel AFs were evaluated in a two-layered CNN against nine ReLU-based AFs on seven benchmark datasets, including images of spiral drawings taken via graphic tablets from patients with Parkinson Disease and healthy subjects, and point-of-care ultrasound images on the lungs of patients with COVID-19, those with pneumonia and healthy controls. Despite a higher computational cost, results indicated an overall higher classification accuracy, precision, recall and F1-score brought about by either quantum AFs on five of the seven bench-mark datasets, thus demonstrating its potential to be the new benchmark or gold standard AF in CNNs and aid image classification tasks involved in critical applications, such as medical diagnoses of COVID-19 and PD.
Robust and On-the-fly Dataset Denoising for Image Classification
Apr 09, 2020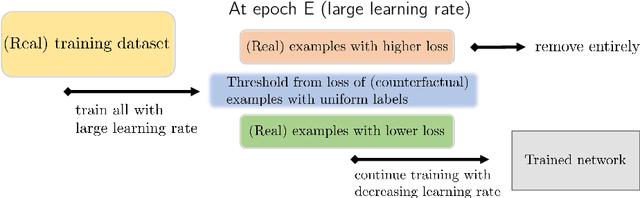
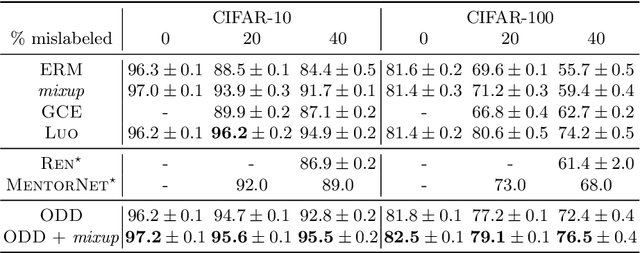

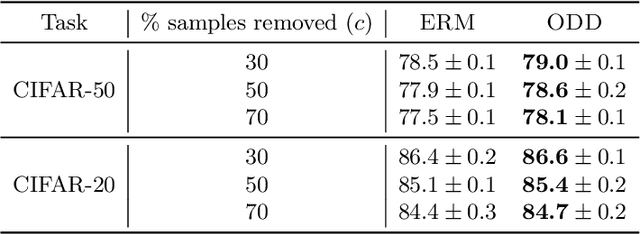
Memorization in over-parameterized neural networks could severely hurt generalization in the presence of mislabeled examples. However, mislabeled examples are hard to avoid in extremely large datasets collected with weak supervision. We address this problem by reasoning counterfactually about the loss distribution of examples with uniform random labels had they were trained with the real examples, and use this information to remove noisy examples from the training set. First, we observe that examples with uniform random labels have higher losses when trained with stochastic gradient descent under large learning rates. Then, we propose to model the loss distribution of the counterfactual examples using only the network parameters, which is able to model such examples with remarkable success. Finally, we propose to remove examples whose loss exceeds a certain quantile of the modeled loss distribution. This leads to On-the-fly Data Denoising (ODD), a simple yet effective algorithm that is robust to mislabeled examples, while introducing almost zero computational overhead compared to standard training. ODD is able to achieve state-of-the-art results on a wide range of datasets including real-world ones such as WebVision and Clothing1M.