 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D Object Detection and Pose Estimation of Unseen Objects in Color Images with Local Surface Embeddings
Oct 08, 2020
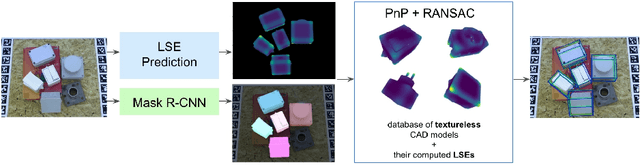

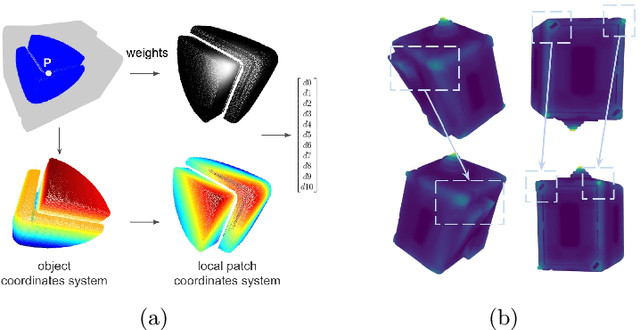

We present an approach for detecting and estimating the 3D poses of objects in images that requires only an untextured CAD model and no training phase for new objects. Our approach combines Deep Learning and 3D geometry: It relies on an embedding of local 3D geometry to match the CAD models to the input images. For points at the surface of objects, this embedding can be computed directly from the CAD model; for image locations, we learn to predict it from the image itself. This establishes correspondences between 3D points on the CAD model and 2D locations of the input images. However, many of these correspondences are ambiguous as many points may have similar local geometries. We show that we can use Mask-RCNN in a class-agnostic way to detect the new objects without retraining and thus drastically limit the number of possible correspondences. We can then robustly estimate a 3D pose from these discriminative correspondences using a RANSAC- like algorithm. We demonstrate the performance of this approach on the T-LESS dataset, by using a small number of objects to learn the embedding and testing it on the other objects. Our experiments show that our method is on par or better than previous methods.
Improving Deep-learning-based Semi-supervised Audio Tagging with Mixup
Feb 16, 2021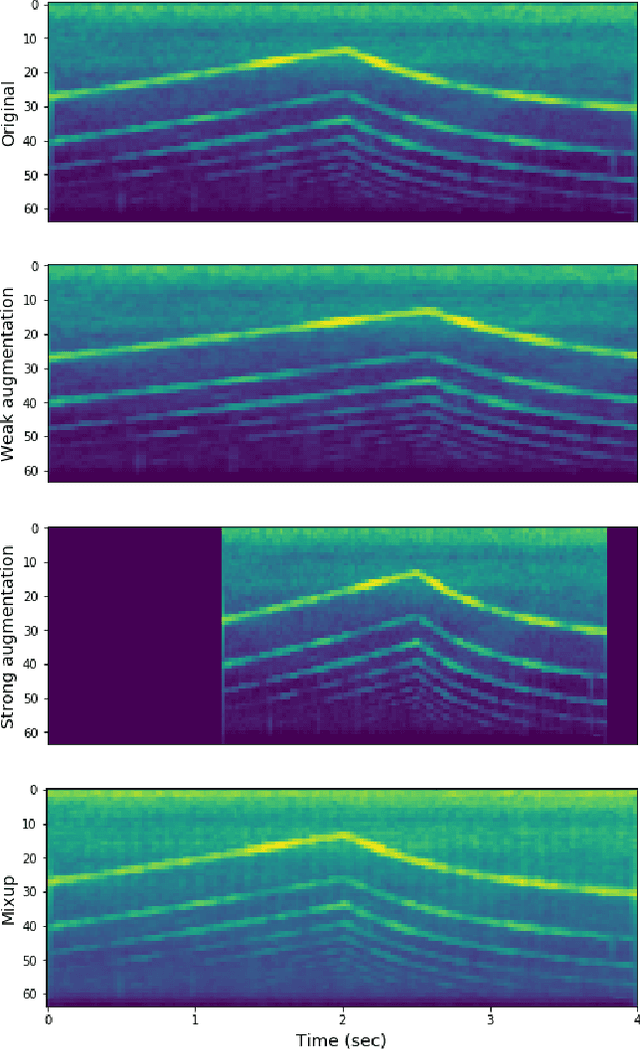
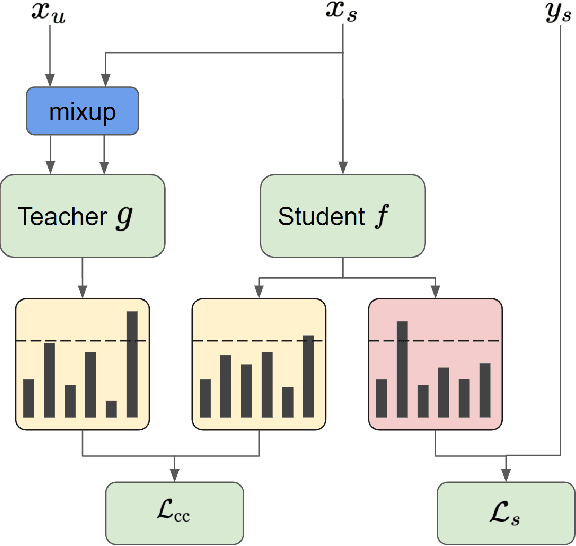
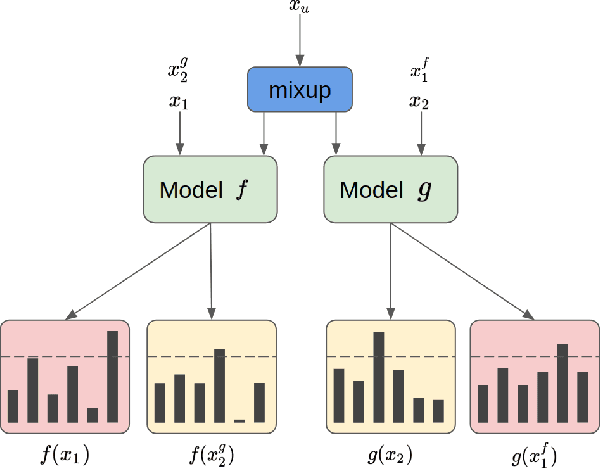
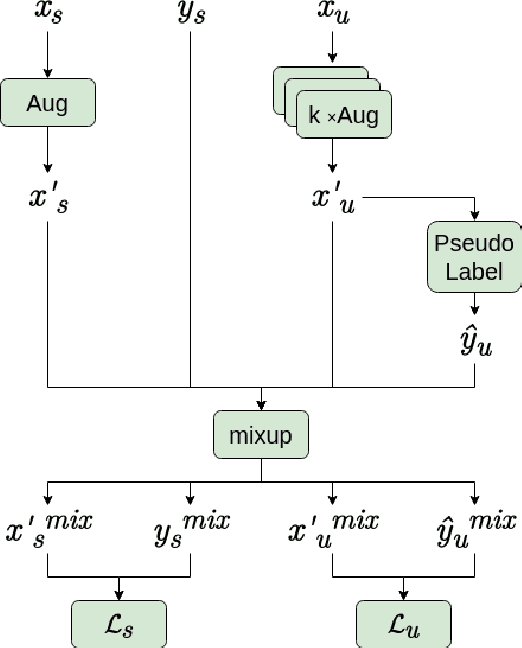
Recently, semi-supervised learning (SSL) methods, in the framework of deep learning (DL), have been shown to provide state-of-the-art results on image datasets by exploiting unlabeled data. Most of the time tested on object recognition tasks in images, these algorithms are rarely compared when applied to audio tasks. In this article, we adapted four recent SSL methods to the task of audio tagging. The first two methods, namely Deep Co-Training (DCT) and Mean Teacher (MT) involve two collaborative neural networks. The two other algorithms, called MixMatch (MM) and FixMatch (FM), are single-model methods that rely primarily on data augmentation strategies. Using the Wide ResNet 28-2 architecture in all our experiments, 10% of labeled data and the remaining 90\% as unlabeled, we first compare the four methods' accuracy on three standard benchmark audio event datasets: Environmental Sound Classification (ESC-10), UrbanSound8K (UBS8K), and Google Speech Commands (GSC). MM and FM outperformed MT and DCT significantly, MM being the best method in most experiments. On UBS8K and GSC, in particular, MM achieved 18.02% and 3.25% error rates (ER), outperforming models trained with 100% of the available labeled data, which reached 23.29% and 4.94% ER, respectively. Second, we explored the benefits of using the mixup augmentation in the four algorithms. In almost all cases, mixup brought significant gains. For instance, on GSC, FM reached 4.44% and 3.31% ER without and with mixup.
Latent Neural Differential Equations for Video Generation
Nov 07, 2020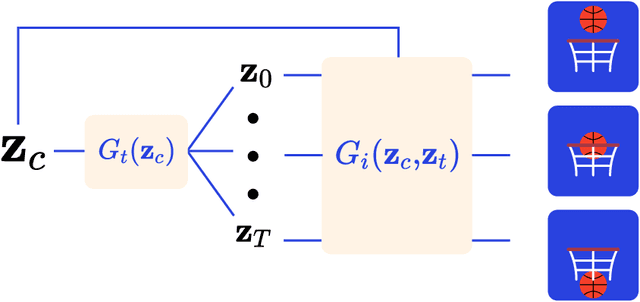
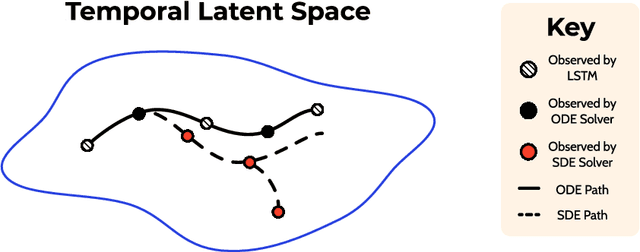
Generative Adversarial Networks have recently shown promise for video generation, building off of the success of image generation while also addressing a new challenge: time. Although time was analyzed in some early work, the literature has not adequately grown with temporal modeling developments. We propose studying the effects of Neural Differential Equations to model the temporal dynamics of video generation. The paradigm of Neural Differential Equations presents many theoretical strengths including the first continuous representation of time within video generation. In order to address the effects of Neural Differential Equations, we will investigate how changes in temporal models affect generated video quality.
Alignment & joint recovery of multi-slice dynamic MRI using deep generative manifold model
Jan 20, 2021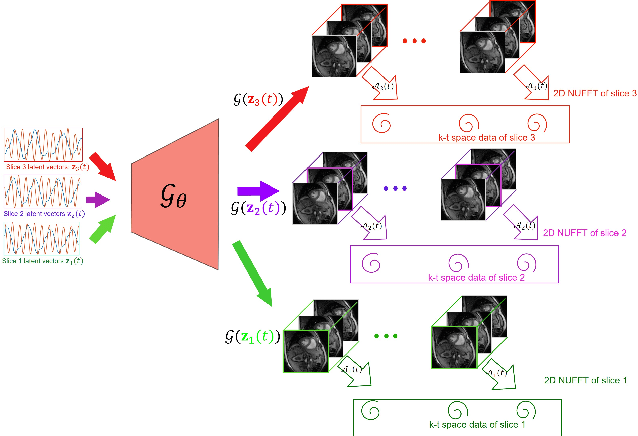
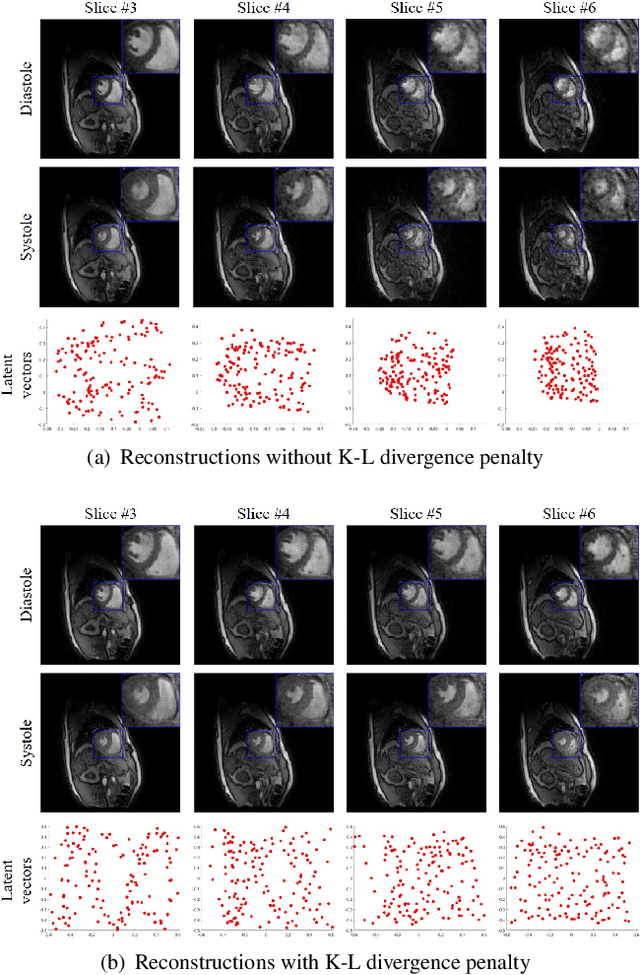
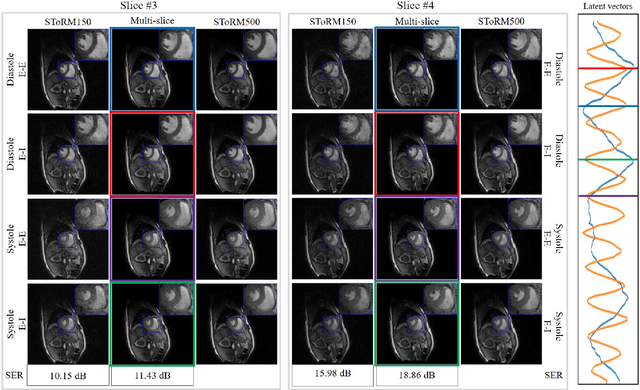
We introduce a novel unsupervised deep generative manifold model for the recovery of multi-slice free-breathing and ungated cardiac MRI from highly undersampled measurements. The proposed scheme represents the multi-slice volume at each time point as the output of a deep convolutional neural network (CNN) generator, which is driven by latent vectors that capture the cardiac and respiratory phase at the specific time point. The main difference between the proposed method and the traditional CNN approaches is that the proposed scheme learns the network parameters from only the highly undersampled data rather than the extensive fully-sampled training data. We also learn the latent codes from the undersampled data using the stochastic gradient descent. Regularizations on the network and the latent codes are introduced to encourage the learning of smooth image manifold and the latent codes for each slice have the same distribution. The main benefits of the proposed scheme are (a) the ability to align multi-slice data and capitalize on the redundancy between the slices; (b) the ability to estimate the gating information directly from the k-t space data; and (c) the unsupervised learning strategy that eliminates the need for extensive training data.
Recurrently Exploring Class-wise Attention in A Hybrid Convolutional and Bidirectional LSTM Network for Multi-label Aerial Image Classification
Jul 30, 2018
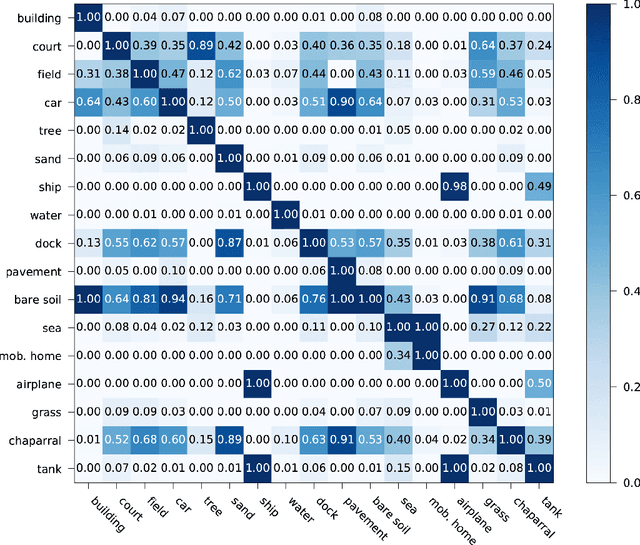
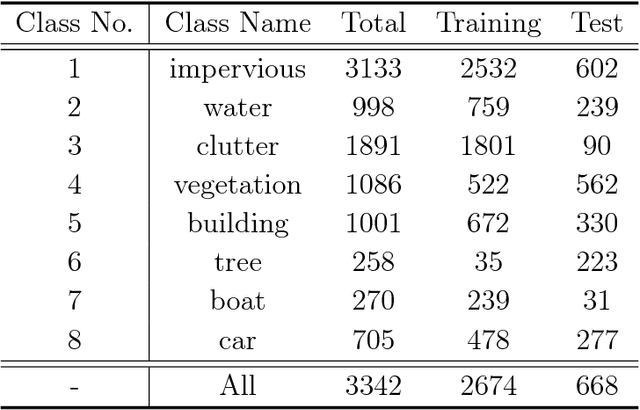
Aerial image classification is of great significance in remote sensing community, and many researches have been conducted over the past few years. Among these studies, most of them focus on categorizing an image into one semantic label, while in the real world, an aerial image is often associated with multiple labels, e.g., multiple object-level labels in our case. Besides, a comprehensive picture of present objects in a given high resolution aerial image can provide more in-depth understanding of the studied region. For these reasons, aerial image multi-label classification has been attracting increasing attention. However, one common limitation shared by existing methods in the community is that the co-occurrence relationship of various classes, so called class dependency, is underexplored and leads to an inconsiderate decision. In this paper, we propose a novel end-to-end network, namely class-wise attention-based convolutional and bidirectional LSTM network (CA-Conv-BiLSTM), for this task. The proposed network consists of three indispensable components: 1) a feature extraction module, 2) a class attention learning layer, and 3) a bidirectional LSTM-based sub-network. Particularly, the feature extraction module is designed for extracting fine-grained semantic feature maps, while the class attention learning layer aims at capturing discriminative class-specific features. As the most important part, the bidirectional LSTM-based sub-network models the underlying class dependency in both directions and produce structured multiple object labels. Experimental results on UCM multi-label dataset and DFC15 multi-label dataset validate the effectiveness of our model quantitatively and qualitatively.
NITES: A Non-Parametric Interpretable Texture Synthesis Method
Sep 02, 2020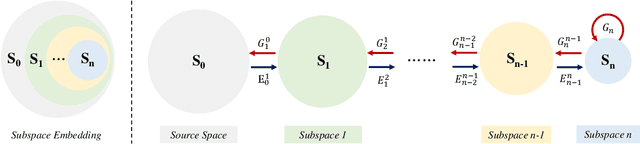

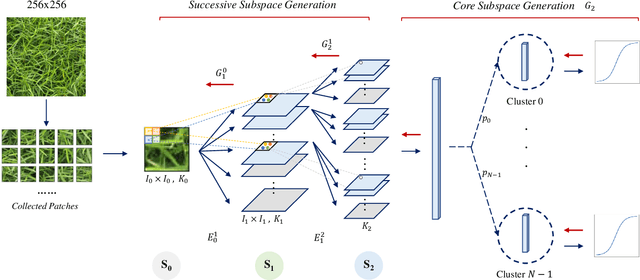

A non-parametric interpretable texture synthesis method, called the NITES method, is proposed in this work. Although automatic synthesis of visually pleasant texture can be achieved by deep neural networks nowadays, the associated generation models are mathematically intractable and their training demands higher computational cost. NITES offers a new texture synthesis solution to address these shortcomings. NITES is mathematically transparent and efficient in training and inference. The input is a single exemplary texture image. The NITES method crops out patches from the input and analyzes the statistical properties of these texture patches to obtain their joint spatial-spectral representations. Then, the probabilistic distributions of samples in the joint spatial-spectral spaces are characterized. Finally, numerous texture images that are visually similar to the exemplary texture image can be generated automatically. Experimental results are provided to show the superior quality of generated texture images and efficiency of the proposed NITES method in terms of both training and inference time.
Learning Synthetic to Real Transfer for Localization and Navigational Tasks
Nov 23, 2020



Autonomous navigation consists in an agent being able to navigate without human intervention or supervision, it affects both high level planning and low level control. Navigation is at the crossroad of multiple disciplines, it combines notions of computer vision, robotics and control. This work aimed at creating, in a simulation, a navigation pipeline whose transfer to the real world could be done with as few efforts as possible. Given the limited time and the wide range of problematic to be tackled, absolute navigation performances while important was not the main objective. The emphasis was rather put on studying the sim2real gap which is one the major bottlenecks of modern robotics and autonomous navigation. To design the navigation pipeline four main challenges arise; environment, localization, navigation and planning. The iGibson simulator is picked for its photo-realistic textures and physics engine. A topological approach to tackle space representation was picked over metric approaches because they generalize better to new environments and are less sensitive to change of conditions. The navigation pipeline is decomposed as a localization module, a planning module and a local navigation module. These modules utilize three different networks, an image representation extractor, a passage detector and a local policy. The laters are trained on specifically tailored tasks with some associated datasets created for those specific tasks. Localization is the ability for the agent to localize itself against a specific space representation. It must be reliable, repeatable and robust to a wide variety of transformations. Localization is tackled as an image retrieval task using a deep neural network trained on an auxiliary task as a feature descriptor extractor. The local policy is trained with behavioral cloning from expert trajectories gathered with ROS navigation stack.
Active MR k-space Sampling with Reinforcement Learning
Jul 20, 2020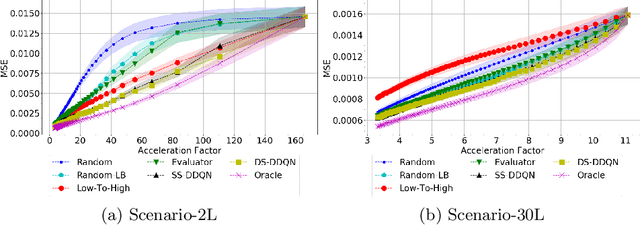
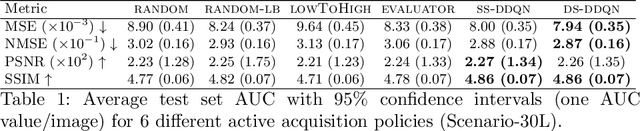
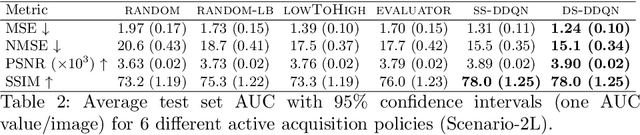
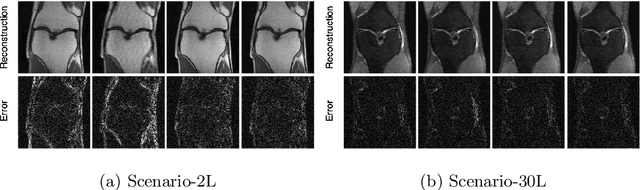
Deep learning approaches have recently shown great promise in accelerating magnetic resonance image (MRI) acquisition. The majority of existing work have focused on designing better reconstruction models given a pre-determined acquisition trajectory, ignoring the question of trajectory optimization. In this paper, we focus on learning acquisition trajectories given a fixed image reconstruction model. We formulate the problem as a sequential decision process and propose the use of reinforcement learning to solve it. Experiments on a large scale public MRI dataset of knees show that our proposed models significantly outperform the state-of-the-art in active MRI acquisition, over a large range of acceleration factors.
Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections
Aug 30, 2016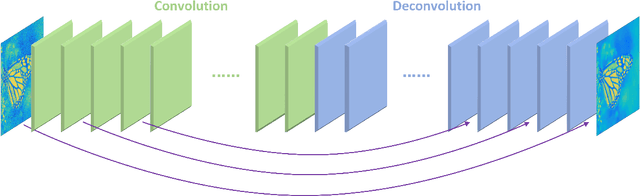
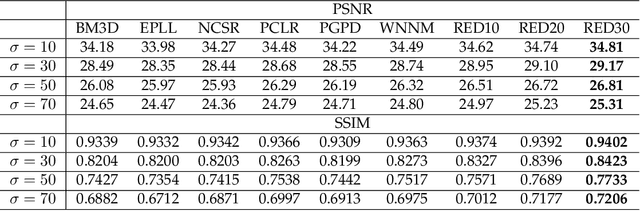
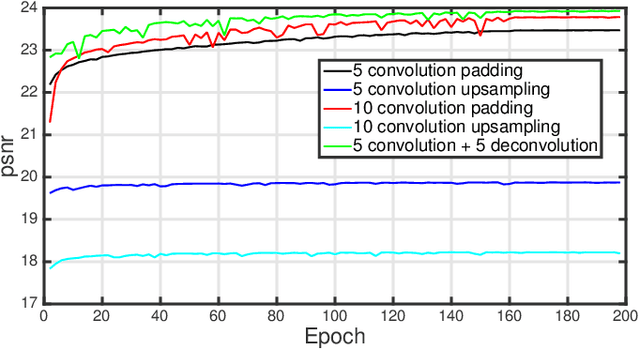
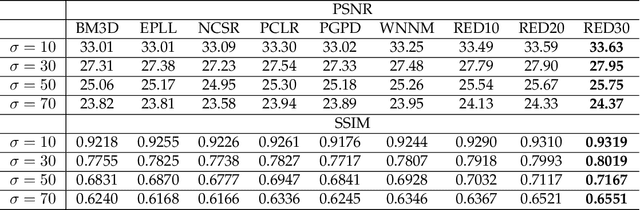
Image restoration, including image denoising, super resolution, inpainting, and so on, is a well-studied problem in computer vision and image processing, as well as a test bed for low-level image modeling algorithms. In this work, we propose a very deep fully convolutional auto-encoder network for image restoration, which is a encoding-decoding framework with symmetric convolutional-deconvolutional layers. In other words, the network is composed of multiple layers of convolution and de-convolution operators, learning end-to-end mappings from corrupted images to the original ones. The convolutional layers capture the abstraction of image contents while eliminating corruptions. Deconvolutional layers have the capability to upsample the feature maps and recover the image details. To deal with the problem that deeper networks tend to be more difficult to train, we propose to symmetrically link convolutional and deconvolutional layers with skip-layer connections, with which the training converges much faster and attains better results.
FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing Imagery
Mar 09, 2021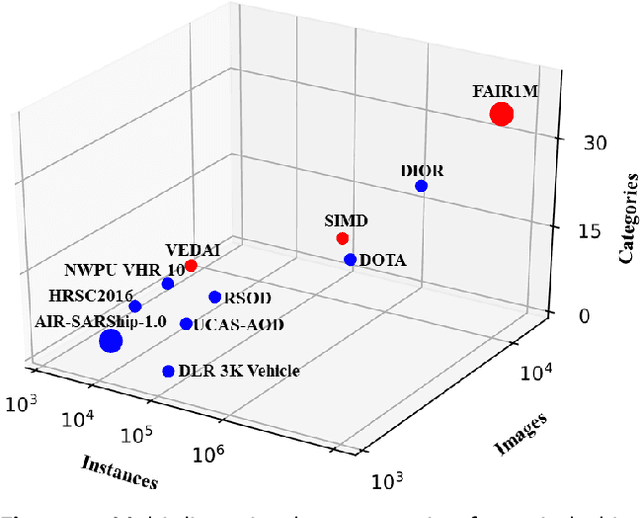
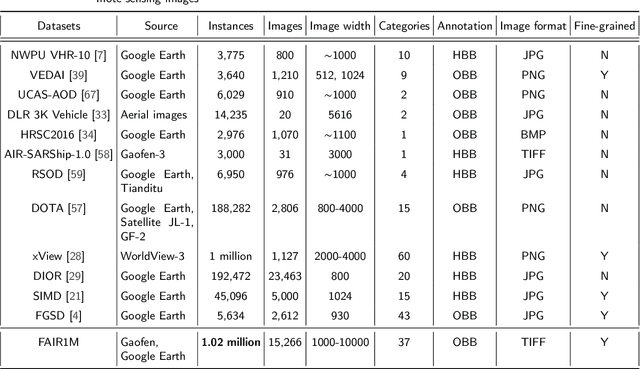
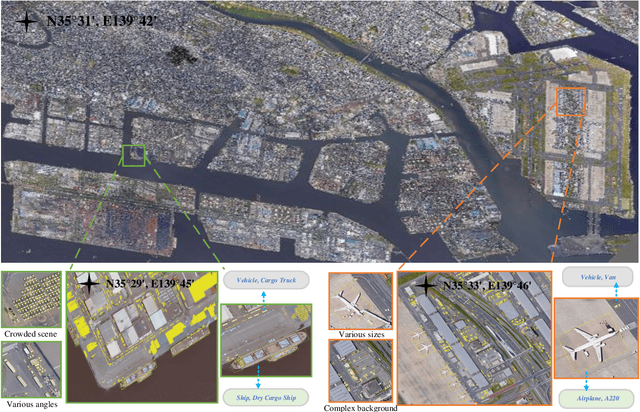
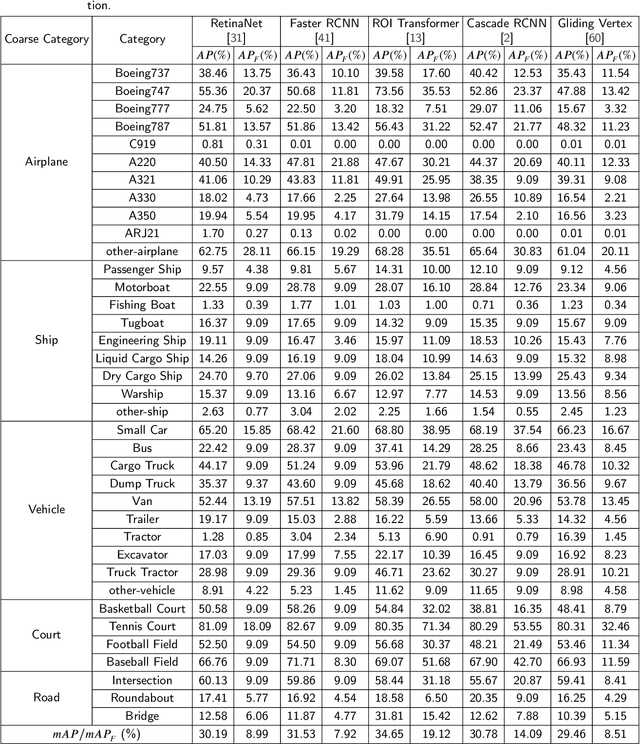
With the rapid development of deep learning, many deep learning based approaches have made great achievements in object detection task. It is generally known that deep learning is a data-driven method. Data directly impact the performance of object detectors to some extent. Although existing datasets have included common objects in remote sensing images, they still have some limitations in terms of scale, categories, and images. Therefore, there is a strong requirement for establishing a large-scale benchmark on object detection in high-resolution remote sensing images. In this paper, we propose a novel benchmark dataset with more than 1 million instances and more than 15,000 images for Fine-grAined object recognItion in high-Resolution remote sensing imagery which is named as FAIR1M. All objects in the FAIR1M dataset are annotated with respect to 5 categories and 37 sub-categories by oriented bounding boxes. Compared with existing detection datasets dedicated to object detection, the FAIR1M dataset has 4 particular characteristics: (1) it is much larger than other existing object detection datasets both in terms of the quantity of instances and the quantity of images, (2) it provides more rich fine-grained category information for objects in remote sensing images, (3) it contains geographic information such as latitude, longitude and resolution, (4) it provides better image quality owing to a careful data cleaning procedure. To establish a baseline for fine-grained object recognition, we propose a novel evaluation method and benchmark fine-grained object detection tasks and a visual classification task using several State-Of-The-Art (SOTA) deep learning based models on our FAIR1M dataset. Experimental results strongly indicate that the FAIR1M dataset is closer to practical application and it is considerably more challenging than existing datasets.