 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Loss Function for Generative Neural Networks Based on Watson's Perceptual Model
Jun 26, 2020




To train Variational Autoencoders (VAEs) to generate realistic imagery requires a loss function that reflects human perception of image similarity. We propose such a loss function based on Watson's perceptual model, which computes a weighted distance in frequency space and accounts for luminance and contrast masking. We extend the model to color images, increase its robustness to translation by using the Fourier Transform, remove artifacts due to splitting the image into blocks, and make it differentiable. In experiments, VAEs trained with the new loss function generated realistic, high-quality image samples. Compared to using the Euclidean distance and the Structural Similarity Index, the images were less blurry; compared to deep neural network based losses, the new approach required less computational resources and generated images with less artifacts.
Locally orderless tensor networks for classifying two- and three-dimensional medical images
Sep 25, 2020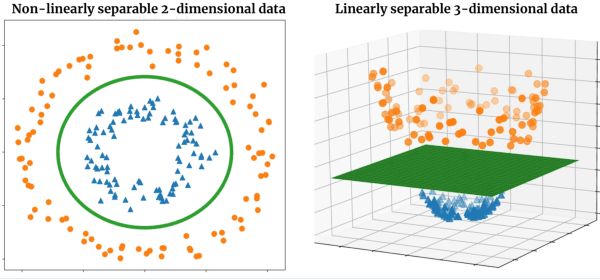

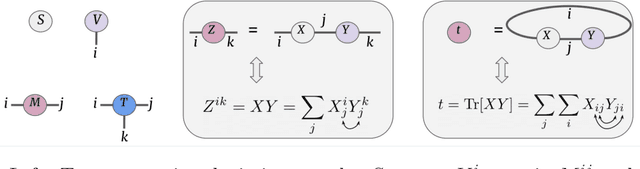
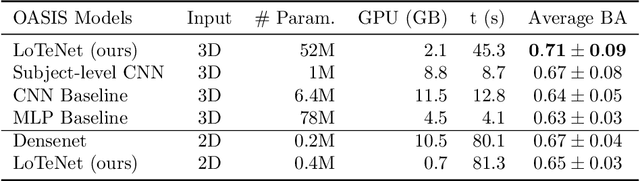
Tensor networks are factorisations of high rank tensors into networks of lower rank tensors and have primarily been used to analyse quantum many-body problems. Tensor networks have seen a recent surge of interest in relation to supervised learning tasks with a focus on image classification. In this work, we improve upon the matrix product state (MPS) tensor networks that can operate on one-dimensional vectors to be useful for working with 2D and 3D medical images. We treat small image regions as orderless, squeeze their spatial information into feature dimensions and then perform MPS operations on these locally orderless regions. These local representations are then aggregated in a hierarchical manner to retain global structure. The proposed locally orderless tensor network (LoTeNet) is compared with relevant methods on three datasets. The architecture of LoTeNet is fixed in all experiments and we show it requires lesser computational resources to attain performance on par or superior to the compared methods.
How Faithful is your Synthetic Data? Sample-level Metrics for Evaluating and Auditing Generative Models
Feb 17, 2021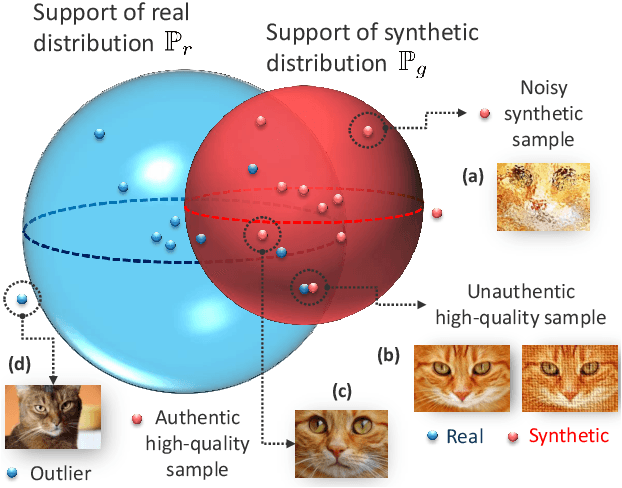

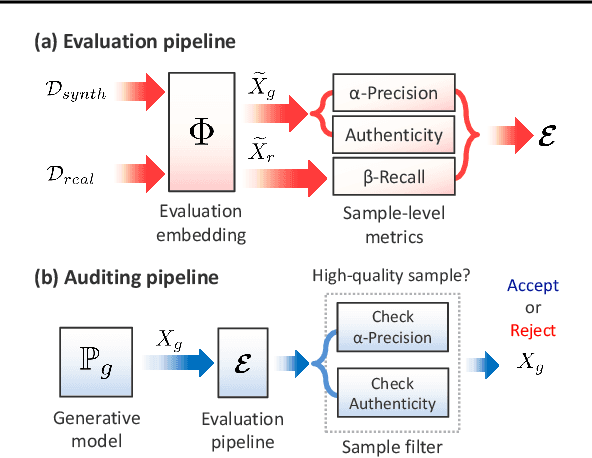
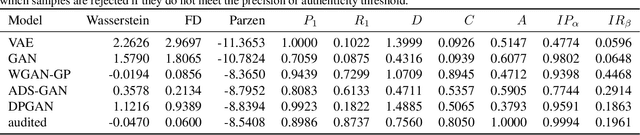
Devising domain- and model-agnostic evaluation metrics for generative models is an important and as yet unresolved problem. Most existing metrics, which were tailored solely to the image synthesis setup, exhibit a limited capacity for diagnosing the different modes of failure of generative models across broader application domains. In this paper, we introduce a 3-dimensional evaluation metric, ($\alpha$-Precision, $\beta$-Recall, Authenticity), that characterizes the fidelity, diversity and generalization performance of any generative model in a domain-agnostic fashion. Our metric unifies statistical divergence measures with precision-recall analysis, enabling sample- and distribution-level diagnoses of model fidelity and diversity. We introduce generalization as an additional, independent dimension (to the fidelity-diversity trade-off) that quantifies the extent to which a model copies training data -- a crucial performance indicator when modeling sensitive data with requirements on privacy. The three metric components correspond to (interpretable) probabilistic quantities, and are estimated via sample-level binary classification. The sample-level nature of our metric inspires a novel use case which we call model auditing, wherein we judge the quality of individual samples generated by a (black-box) model, discarding low-quality samples and hence improving the overall model performance in a post-hoc manner.
Adaptive Importance Learning for Improving Lightweight Image Super-resolution Network
Jun 05, 2018
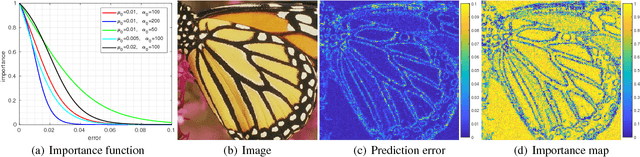
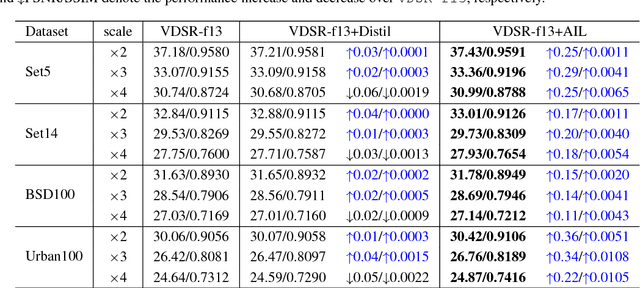
Deep neural networks have achieved remarkable success in single image super-resolution (SISR). The computing and memory requirements of these methods have hindered their application to broad classes of real devices with limited computing power, however. One approach to this problem has been lightweight network architectures that bal- ance the super-resolution performance and the computation burden. In this study, we revisit this problem from an orthog- onal view, and propose a novel learning strategy to maxi- mize the pixel-wise fitting capacity of a given lightweight network architecture. Considering that the initial capacity of the lightweight network is very limited, we present an adaptive importance learning scheme for SISR that trains the network with an easy-to-complex paradigm by dynam- ically updating the importance of image pixels on the basis of the training loss. Specifically, we formulate the network training and the importance learning into a joint optimization problem. With a carefully designed importance penalty function, the importance of individual pixels can be gradu- ally increased through solving a convex optimization problem. The training process thus begins with pixels that are easy to reconstruct, and gradually proceeds to more complex pixels as fitting improves.
Robust and Natural Physical Adversarial Examples for Object Detectors
Nov 27, 2020Recently, many studies show that deep neural networks (DNNs) are susceptible to adversarial examples. However, in order to convince that adversarial examples are real threats in real physical world, it is necessary to study and evaluate the adversarial examples in real-world scenarios. In this paper, we propose a robust and natural physical adversarial example attack method targeting object detectors under real-world conditions, which is more challenging than targeting image classifiers. The generated adversarial examples are robust to various physical constraints and visually look similar to the original images, thus these adversarial examples are natural to humans and will not cause any suspicions. First, to ensure the robustness of the adversarial examples in real-world conditions, the proposed method exploits different image transformation functions (Distance, Angle, Illumination, Printing and Photographing), to simulate various physical changes during the iterative optimization of the adversarial examples generation. Second, to construct natural adversarial examples, the proposed method uses an adaptive mask to constrain the area and intensities of added perturbations, and utilizes the real-world perturbation score (RPS) to make the perturbations be similar to those real noises in physical world. Compared with existing studies, our generated adversarial examples can achieve a high success rate with less conspicuous perturbations. Experimental results demonstrate that, the generated adversarial examples are robust under various indoor and outdoor physical conditions. Finally, the proposed physical adversarial attack method is universal and can work in black-box scenarios. The generated adversarial examples generalize well between different models.
Improving Model Accuracy for Imbalanced Image Classification Tasks by Adding a Final Batch Normalization Layer: An Empirical Study
Nov 12, 2020
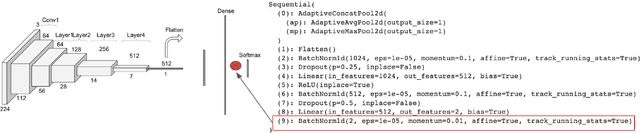
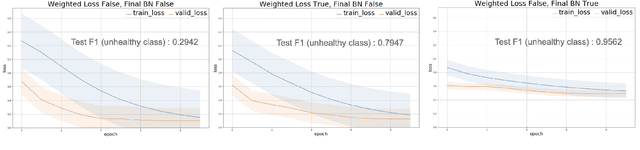
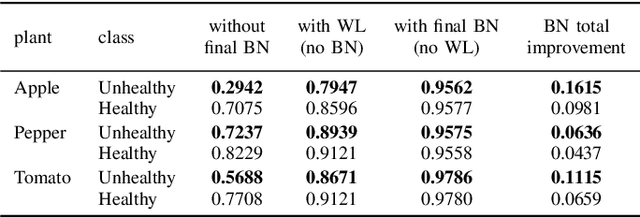
Some real-world domains, such as Agriculture and Healthcare, comprise early-stage disease indications whose recording constitutes a rare event, and yet, whose precise detection at that stage is critical. In this type of highly imbalanced classification problems, which encompass complex features, deep learning (DL) is much needed because of its strong detection capabilities. At the same time, DL is observed in practice to favor majority over minority classes and consequently suffer from inaccurate detection of the targeted early-stage indications. To simulate such scenarios, we artificially generate skewness (99% vs. 1%) for certain plant types out of the PlantVillage dataset as a basis for classification of scarce visual cues through transfer learning. By randomly and unevenly picking healthy and unhealthy samples from certain plant types to form a training set, we consider a base experiment as fine-tuning ResNet34 and VGG19 architectures and then testing the model performance on a balanced dataset of healthy and unhealthy images. We empirically observe that the initial F1 test score jumps from 0.29 to 0.95 for the minority class upon adding a final Batch Normalization (BN) layer just before the output layer in VGG19. We demonstrate that utilizing an additional BN layer before the output layer in modern CNN architectures has a considerable impact in terms of minimizing the training time and testing error for minority classes in highly imbalanced data sets. Moreover, when the final BN is employed, minimizing the loss function may not be the best way to assure a high F1 test score for minority classes in such problems. That is, the network might perform better even if it is not confident enough while making a prediction; leading to another discussion about why softmax output is not a good uncertainty measure for DL models.
ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
Mar 06, 2021
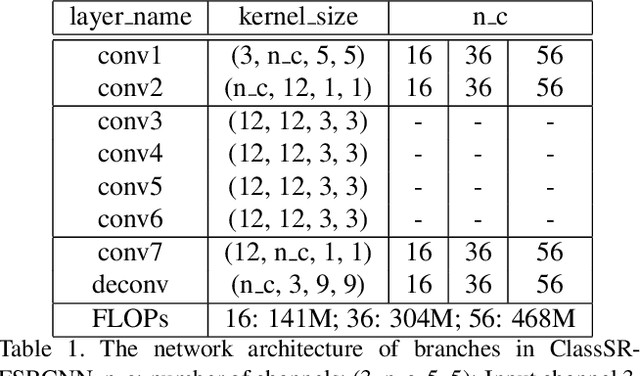
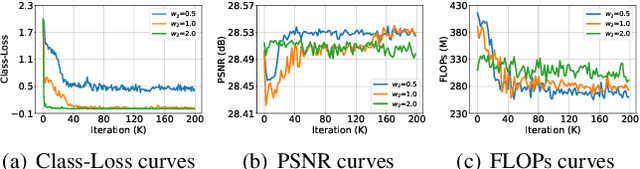
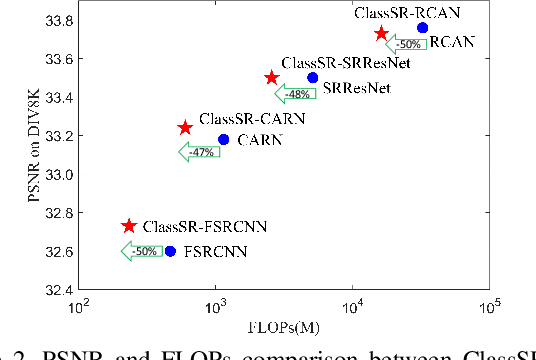
We aim at accelerating super-resolution (SR) networks on large images (2K-8K). The large images are usually decomposed into small sub-images in practical usages. Based on this processing, we found that different image regions have different restoration difficulties and can be processed by networks with different capacities. Intuitively, smooth areas are easier to super-solve than complex textures. To utilize this property, we can adopt appropriate SR networks to process different sub-images after the decomposition. On this basis, we propose a new solution pipeline -- ClassSR that combines classification and SR in a unified framework. In particular, it first uses a Class-Module to classify the sub-images into different classes according to restoration difficulties, then applies an SR-Module to perform SR for different classes. The Class-Module is a conventional classification network, while the SR-Module is a network container that consists of the to-be-accelerated SR network and its simplified versions. We further introduce a new classification method with two losses -- Class-Loss and Average-Loss to produce the classification results. After joint training, a majority of sub-images will pass through smaller networks, thus the computational cost can be significantly reduced. Experiments show that our ClassSR can help most existing methods (e.g., FSRCNN, CARN, SRResNet, RCAN) save up to 50% FLOPs on DIV8K datasets. This general framework can also be applied in other low-level vision tasks.
Efficient Subsampling for Generating High-Quality Images from Conditional Generative Adversarial Networks
Mar 20, 2021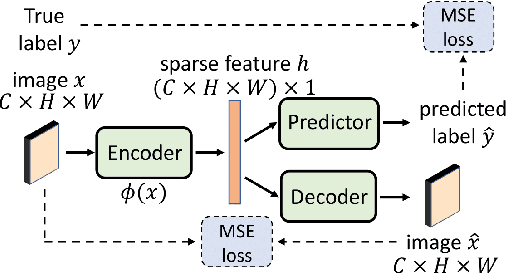
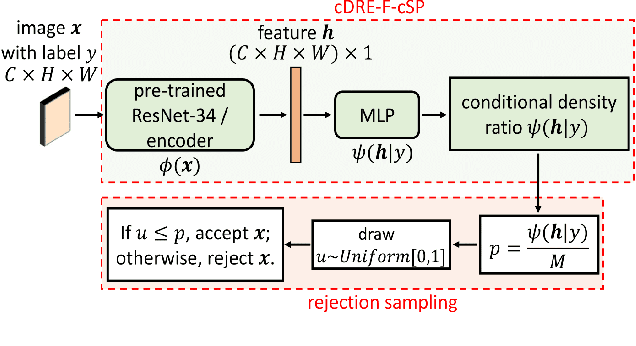
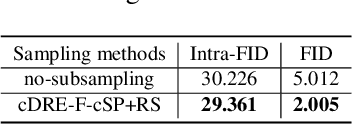
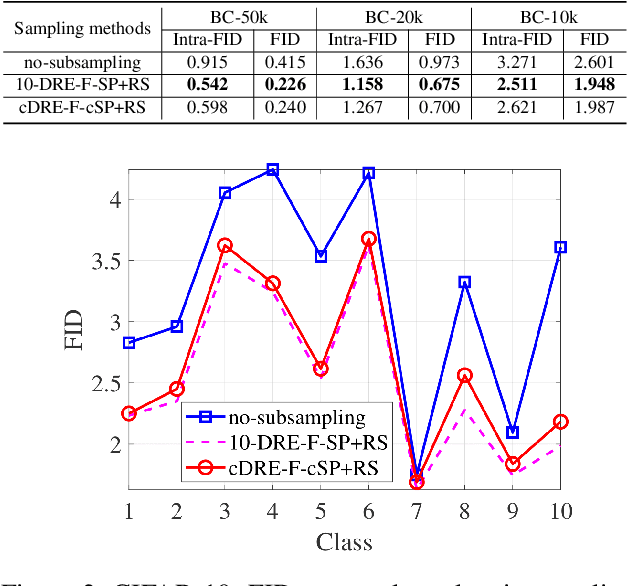
Subsampling unconditional generative adversarial networks (GANs) to improve the overall image quality has been studied recently. However, these methods often require high training costs (e.g., storage space, parameter tuning) and may be inefficient or even inapplicable for subsampling conditional GANs, such as class-conditional GANs and continuous conditional GANs (CcGANs), when the condition has many distinct values. In this paper, we propose an efficient method called conditional density ratio estimation in feature space with conditional Softplus loss (cDRE-F-cSP). With cDRE-F-cSP, we estimate an image's conditional density ratio based on a novel conditional Softplus (cSP) loss in the feature space learned by a specially designed ResNet-34 or sparse autoencoder. We then derive the error bound of a conditional density ratio model trained with the proposed cSP loss. Finally, we propose a rejection sampling scheme, termed cDRE-F-cSP+RS, which can subsample both class-conditional GANs and CcGANs efficiently. An extra filtering scheme is also developed for CcGANs to increase the label consistency. Experiments on CIFAR-10 and Tiny-ImageNet datasets show that cDRE-F-cSP+RS can substantially improve the Intra-FID and FID scores of BigGAN. Experiments on RC-49 and UTKFace datasets demonstrate that cDRE-F-cSP+RS also improves Intra-FID, Diversity, and Label Score of CcGANs. Moreover, to show the high efficiency of cDRE-F-cSP+RS, we compare it with the state-of-the-art unconditional subsampling method (i.e., DRE-F-SP+RS). With comparable or even better performance, cDRE-F-cSP+RS only requires about \textbf{10}\% and \textbf{1.7}\% of the training costs spent respectively on CIFAR-10 and UTKFace by DRE-F-SP+RS.
Improving High Resolution Histology Image Classification with Deep Spatial Fusion Network
Jul 27, 2018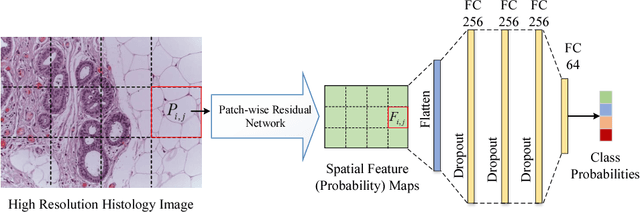
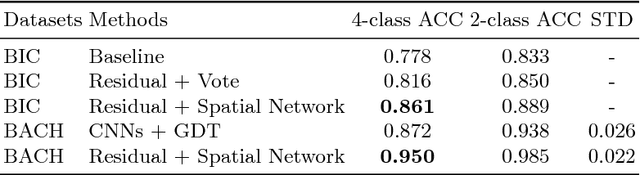
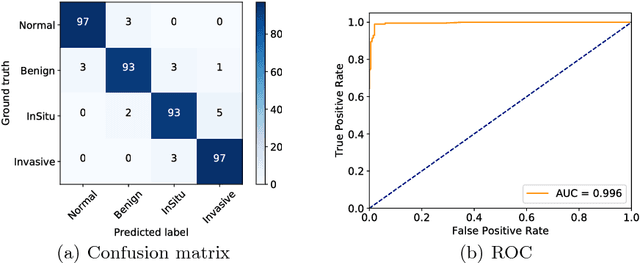
Histology imaging is an essential diagnosis method to finalize the grade and stage of cancer of different tissues, especially for breast cancer diagnosis. Specialists often disagree on the final diagnosis on biopsy tissue due to the complex morphological variety. Although convolutional neural networks (CNN) have advantages in extracting discriminative features in image classification, directly training a CNN on high resolution histology images is computationally infeasible currently. Besides, inconsistent discriminative features often distribute over the whole histology image, which incurs challenges in patch-based CNN classification method. In this paper, we propose a novel architecture for automatic classification of high resolution histology images. First, an adapted residual network is employed to explore hierarchical features without attenuation. Second, we develop a robust deep fusion network to utilize the spatial relationship between patches and learn to correct the prediction bias generated from inconsistent discriminative feature distribution. The proposed method is evaluated using 10-fold cross-validation on 400 high resolution breast histology images with balanced labels and reports 95% accuracy on 4-class classification and 98.5% accuracy, 99.6% AUC on 2-class classification (carcinoma and non-carcinoma), which substantially outperforms previous methods and close to pathologist performance.
Keep it Simple: Data-efficient Learning for Controlling Complex Systems with Simple Models
Feb 17, 2021
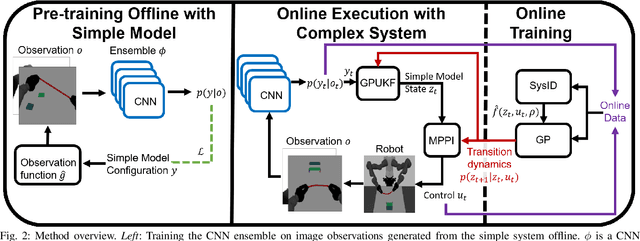


When manipulating a novel object with complex dynamics, a state representation is not always available, for example for deformable objects. Learning both a representation and dynamics from observations requires large amounts of data. We propose Learned Visual Similarity Predictive Control (LVSPC), a novel method for data-efficient learning to control systems with complex dynamics and high-dimensional state spaces from images. LVSPC leverages a given simple model approximation from which image observations can be generated. We use these images to train a perception model that estimates the simple model state from observations of the complex system online. We then use data from the complex system to fit the parameters of the simple model and learn where this model is inaccurate, also online. Finally, we use Model Predictive Control and bias the controller away from regions where the simple model is inaccurate and thus where the controller is less reliable. We evaluate LVSPC on two tasks; manipulating a tethered mass and a rope. We find that our method performs comparably to state-of-the-art reinforcement learning methods with an order of magnitude less data. LVSPC also completes the rope manipulation task on a real robot with 80% success rate after only 10 trials, despite using a perception system trained only on images from simulation.