 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boosting ship detection in SAR images with complementary pretraining techniques
Mar 15, 2021
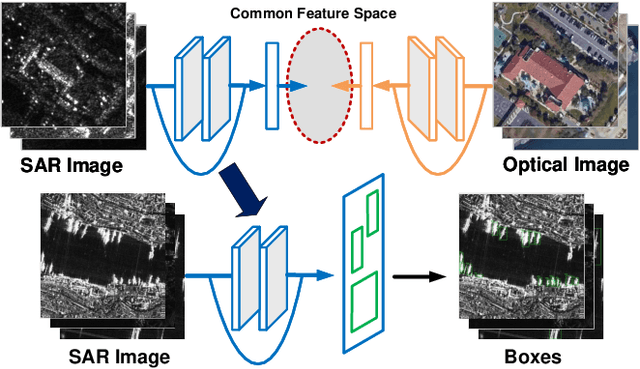
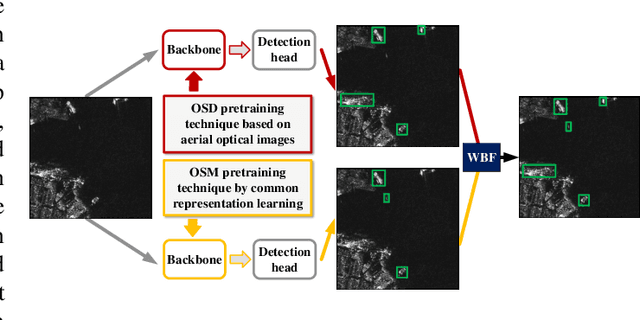
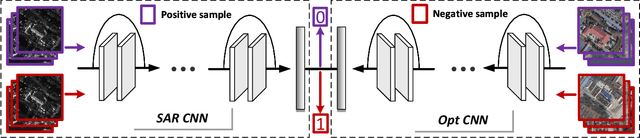
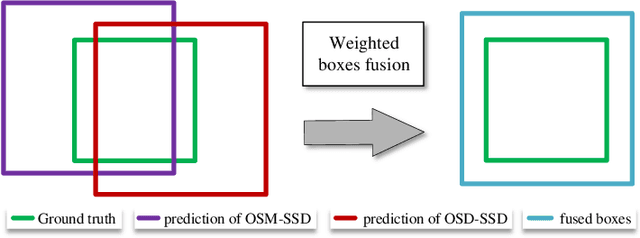
Deep learning methods have made significant progress in ship detection in synthetic aperture radar (SAR) images. The pretraining technique is usually adopted to support deep neural networks-based SAR ship detectors due to the scarce labeled SAR images. However, directly leveraging ImageNet pretraining is hardly to obtain a good ship detector because of different imaging perspective and geometry. In this paper, to resolve the problem of inconsistent imaging perspective between ImageNet and earth observations, we propose an optical ship detector (OSD) pretraining technique, which transfers the characteristics of ships in earth observations to SAR images from a large-scale aerial image dataset. On the other hand, to handle the problem of different imaging geometry between optical and SAR images, we propose an optical-SAR matching (OSM) pretraining technique, which transfers plentiful texture features from optical images to SAR images by common representation learning on the optical-SAR matching task. Finally, observing that the OSD pretraining based SAR ship detector has a better recall on sea area while the OSM pretraining based SAR ship detector can reduce false alarms on land area, we combine the predictions of the two detectors through weighted boxes fusion to further improve detection results. Extensive experiments on four SAR ship detection datasets and two representative CNN-based detection benchmarks are conducted to show the effectiveness and complementarity of the two proposed detectors, and the state-of-the-art performance of the combination of the two detectors. The proposed method won the sixth place of ship detection in SAR images in 2020 Gaofen challenge.
Using GANs to Synthesise Minimum Training Data for Deepfake Generation
Nov 10, 2020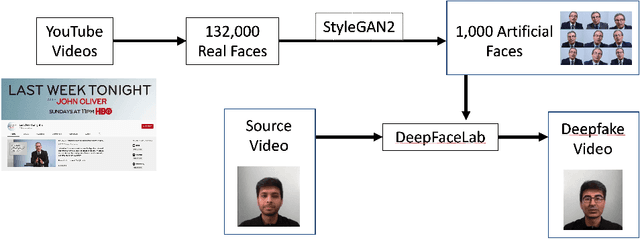
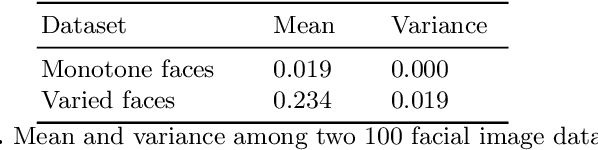
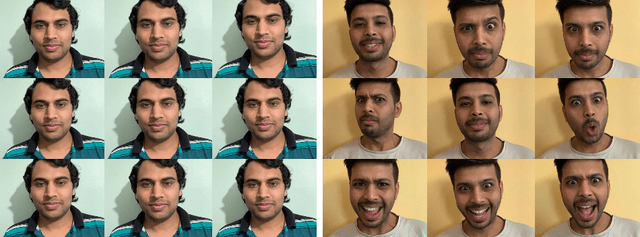
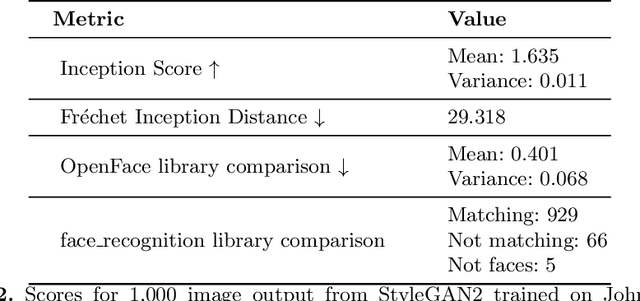
There are many applications of Generative Adversarial Networks (GANs) in fields like computer vision, natural language processing, speech synthesis, and more. Undoubtedly the most notable results have been in the area of image synthesis and in particular in the generation of deepfake videos. While deepfakes have received much negative media coverage, they can be a useful technology in applications like entertainment, customer relations, or even assistive care. One problem with generating deepfakes is the requirement for a lot of image training data of the subject which is not an issue if the subject is a celebrity for whom many images already exist. If there are only a small number of training images then the quality of the deepfake will be poor. Some media reports have indicated that a good deepfake can be produced with as few as 500 images but in practice, quality deepfakes require many thousands of images, one of the reasons why deepfakes of celebrities and politicians have become so popular. In this study, we exploit the property of a GAN to produce images of an individual with variable facial expressions which we then use to generate a deepfake. We observe that with such variability in facial expressions of synthetic GAN-generated training images and a reduced quantity of them, we can produce a near-realistic deepfake videos.
Deploying machine learning to assist digital humanitarians: making image annotation in OpenStreetMap more efficient
Sep 17, 2020

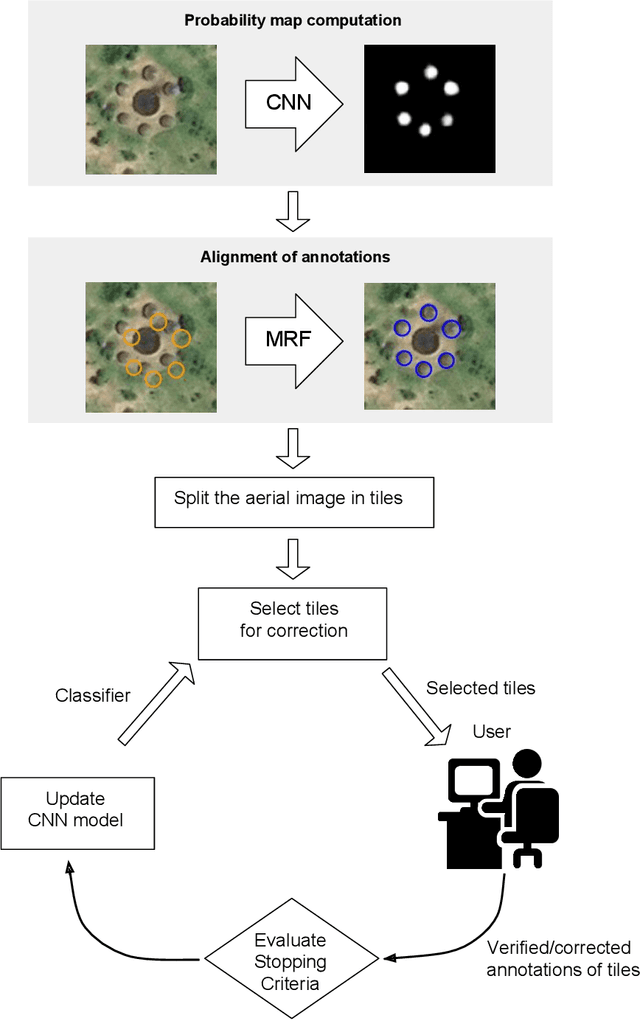
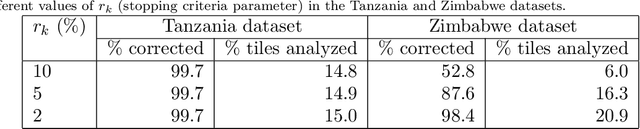
Locating populations in rural areas of developing countries has attracted the attention of humanitarian mapping projects since it is important to plan actions that affect vulnerable areas. Recent efforts have tackled this problem as the detection of buildings in aerial images. However, the quality and the amount of rural building annotated data in open mapping services like OpenStreetMap (OSM) is not sufficient for training accurate models for such detection. Although these methods have the potential of aiding in the update of rural building information, they are not accurate enough to automatically update the rural building maps. In this paper, we explore a human-computer interaction approach and propose an interactive method to support and optimize the work of volunteers in OSM. The user is asked to verify/correct the annotation of selected tiles during several iterations and therefore improving the model with the new annotated data. The experimental results, with simulated and real user annotation corrections, show that the proposed method greatly reduces the amount of data that the volunteers of OSM need to verify/correct. The proposed methodology could benefit humanitarian mapping projects, not only by making more efficient the process of annotation but also by improving the engagement of volunteers.
Adversarial Imaging Pipelines
Feb 19, 2021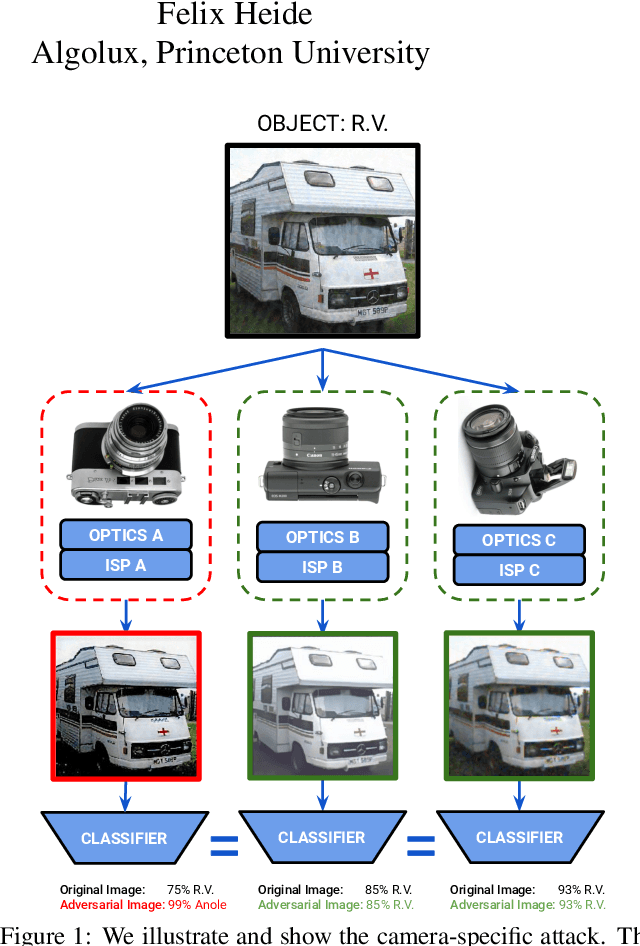
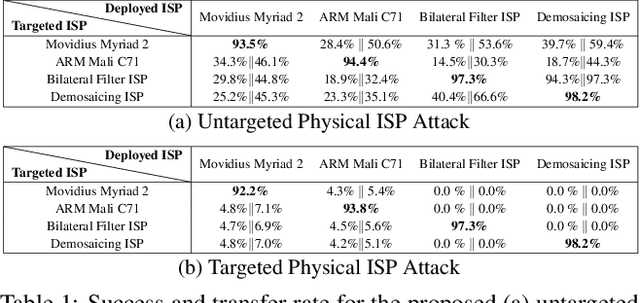
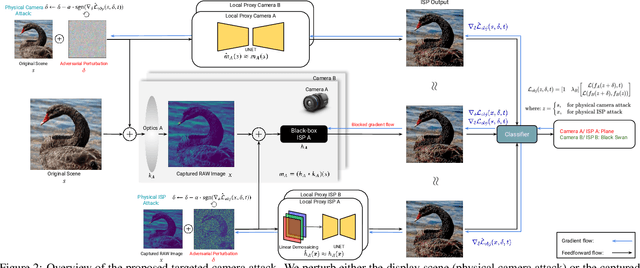
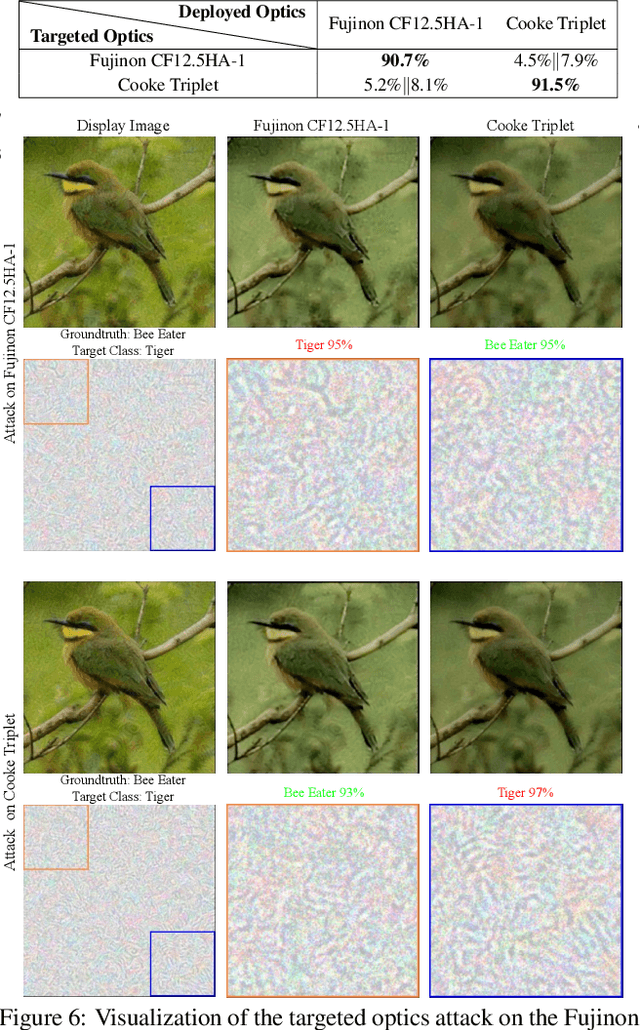
Adversarial attacks play an essential role in understanding deep neural network predictions and improving their robustness. Existing attack methods aim to deceive convolutional neural network (CNN)-based classifiers by manipulating RGB images that are fed directly to the classifiers. However, these approaches typically neglect the influence of the camera optics and image processing pipeline (ISP) that produce the network inputs. ISPs transform RAW measurements to RGB images and traditionally are assumed to preserve adversarial patterns. However, these low-level pipelines can, in fact, destroy, introduce or amplify adversarial patterns that can deceive a downstream detector. As a result, optimized patterns can become adversarial for the classifier after being transformed by a certain camera ISP and optic but not for others. In this work, we examine and develop such an attack that deceives a specific camera ISP while leaving others intact, using the same down-stream classifier. We frame camera-specific attacks as a multi-task optimization problem, relying on a differentiable approximation for the ISP itself. We validate the proposed method using recent state-of-the-art automotive hardware ISPs, achieving 92% fooling rate when attacking a specific ISP. We demonstrate physical optics attacks with 90% fooling rate for a specific camera lenses.
Transformers with Competitive Ensembles of Independent Mechanisms
Feb 27, 2021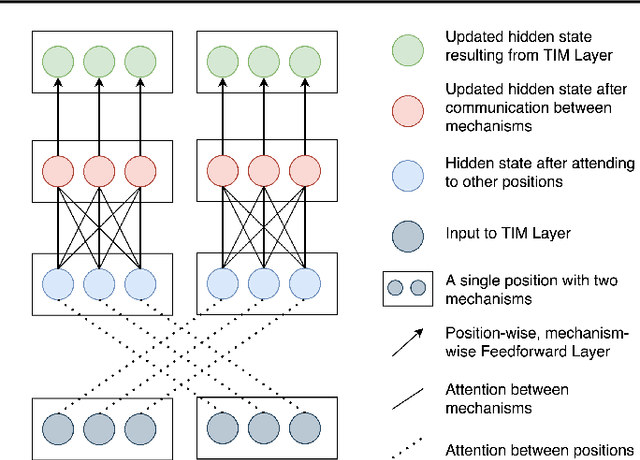
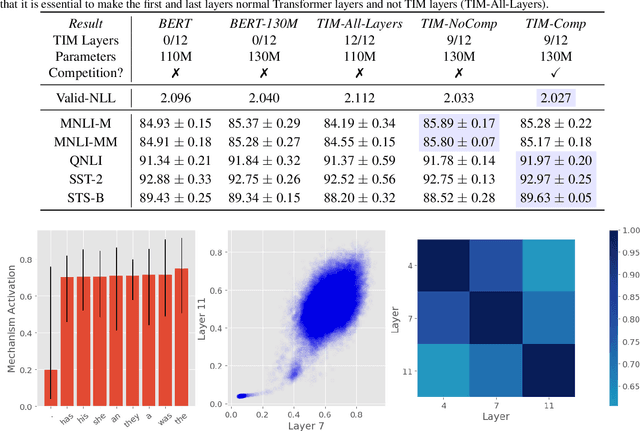
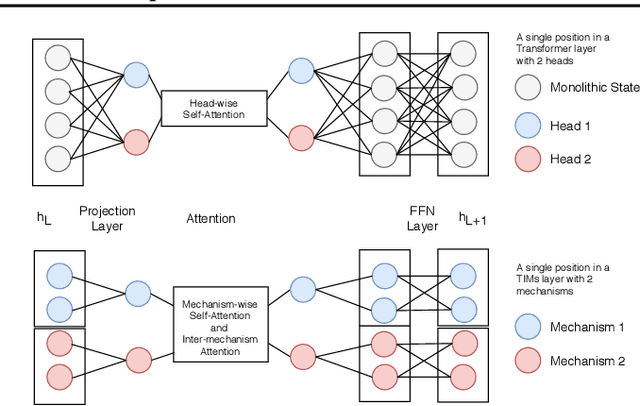
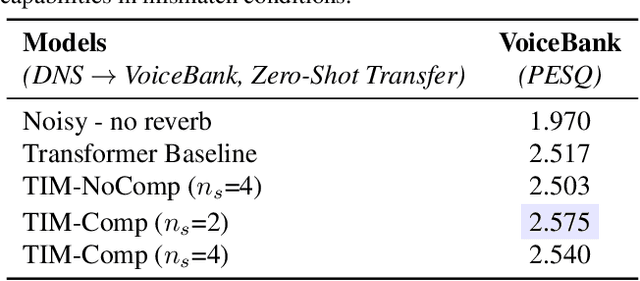
An important development in deep learning from the earliest MLPs has been a move towards architectures with structural inductive biases which enable the model to keep distinct sources of information and routes of processing well-separated. This structure is linked to the notion of independent mechanisms from the causality literature, in which a mechanism is able to retain the same processing as irrelevant aspects of the world are changed. For example, convnets enable separation over positions, while attention-based architectures (especially Transformers) learn which combination of positions to process dynamically. In this work we explore a way in which the Transformer architecture is deficient: it represents each position with a large monolithic hidden representation and a single set of parameters which are applied over the entire hidden representation. This potentially throws unrelated sources of information together, and limits the Transformer's ability to capture independent mechanisms. To address this, we propose Transformers with Independent Mechanisms (TIM), a new Transformer layer which divides the hidden representation and parameters into multiple mechanisms, which only exchange information through attention. Additionally, we propose a competition mechanism which encourages these mechanisms to specialize over time steps, and thus be more independent. We study TIM on a large-scale BERT model, on the Image Transformer, and on speech enhancement and find evidence for semantically meaningful specialization as well as improved performance.
Precise Synthetic Image and LiDAR (PreSIL) Dataset for Autonomous Vehicle Perception
May 07, 2019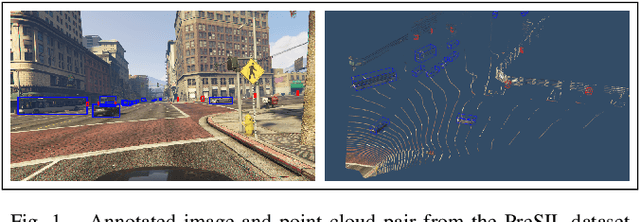


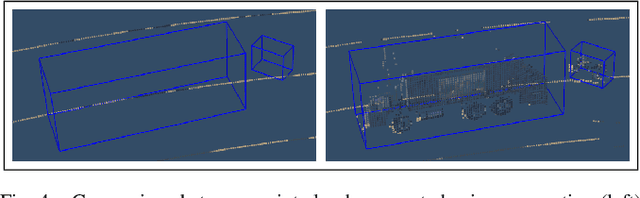
We introduce the Precise Synthetic Image and LiDAR (PreSIL) dataset for autonomous vehicle perception. Grand Theft Auto V (GTA V), a commercial video game, has a large detailed world with realistic graphics, which provides a diverse data collection environment. Existing works creating synthetic LiDAR data for autonomous driving with GTA V have not released their datasets, rely on an in-game raycasting function which represents people as cylinders, and can fail to capture vehicles past 30 metres. Our work creates a precise LiDAR simulator within GTA V which collides with detailed models for all entities no matter the type or position. The PreSIL dataset consists of over 50,000 frames and includes high-definition images with full resolution depth information, semantic segmentation (images), point-wise segmentation (point clouds), and detailed annotations for all vehicles and people. Collecting additional data with our framework is entirely automatic and requires no human annotation of any kind. We demonstrate the effectiveness of our dataset by showing an improvement of up to 5% average precision on the KITTI 3D Object Detection benchmark challenge when state-of-the-art 3D object detection networks are pre-trained with our data. The data and code are available at https://tinyurl.com/y3tb9sxy
Difficulty in estimating visual information from randomly sampled images
Dec 16, 2020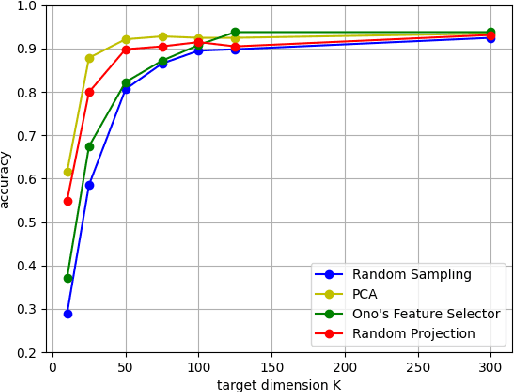
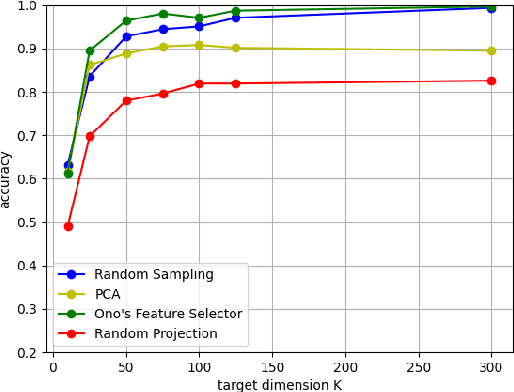
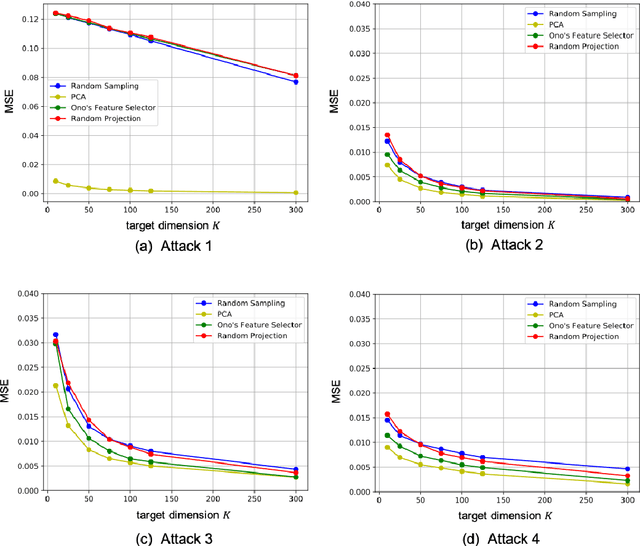
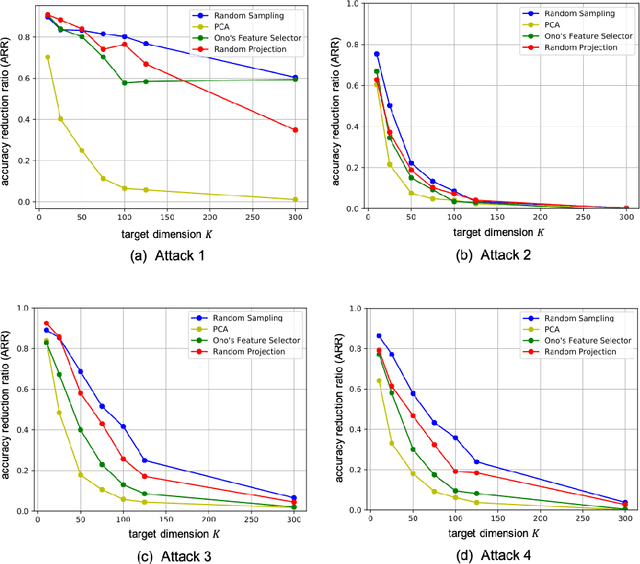
In this paper, we evaluate dimensionality reduction methods in terms of difficulty in estimating visual information on original images from dimensionally reduced ones. Recently, dimensionality reduction has been receiving attention as the process of not only reducing the number of random variables, but also protecting visual information for privacy-preserving machine learning. For such a reason, difficulty in estimating visual information is discussed. In particular, the random sampling method that was proposed for privacy-preserving machine learning, is compared with typical dimensionality reduction methods. In an image classification experiment, the random sampling method is demonstrated not only to have high difficulty, but also to be comparable to other dimensionality reduction methods, while maintaining the property of spatial information invariant.
Geometric Style Transfer
Jul 10, 2020
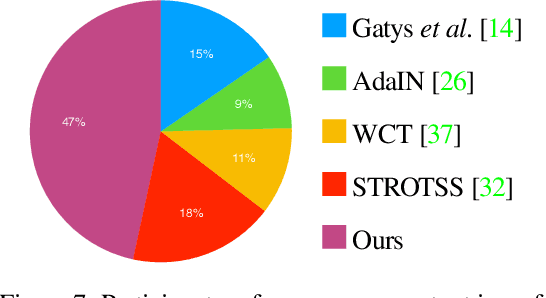
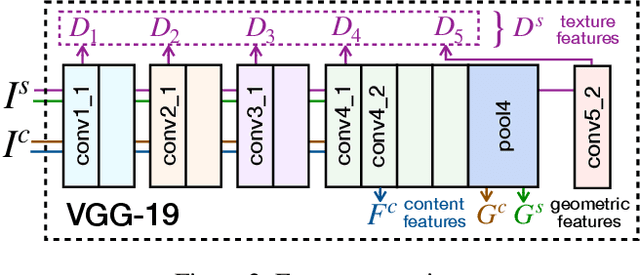
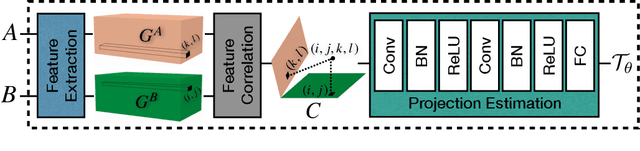
Neural style transfer (NST), where an input image is rendered in the style of another image, has been a topic of considerable progress in recent years. Research over that time has been dominated by transferring aspects of color and texture, yet these factors are only one component of style. Other factors of style include composition, the projection system used, and the way in which artists warp and bend objects. Our contribution is to introduce a neural architecture that supports transfer of geometric style. Unlike recent work in this area, we are unique in being general in that we are not restricted by semantic content. This new architecture runs prior to a network that transfers texture style, enabling us to transfer texture to a warped image. This form of network supports a second novelty: we extend the NST input paradigm. Users can input content/style pair as is common, or they can chose to input a content/texture-style/geometry-style triple. This three image input paradigm divides style into two parts and so provides significantly greater versatility to the output we can produce. We provide user studies that show the quality of our output, and quantify the importance of geometric style transfer to style recognition by humans.
Image De-raining Using a Conditional Generative Adversarial Network
Feb 04, 2017
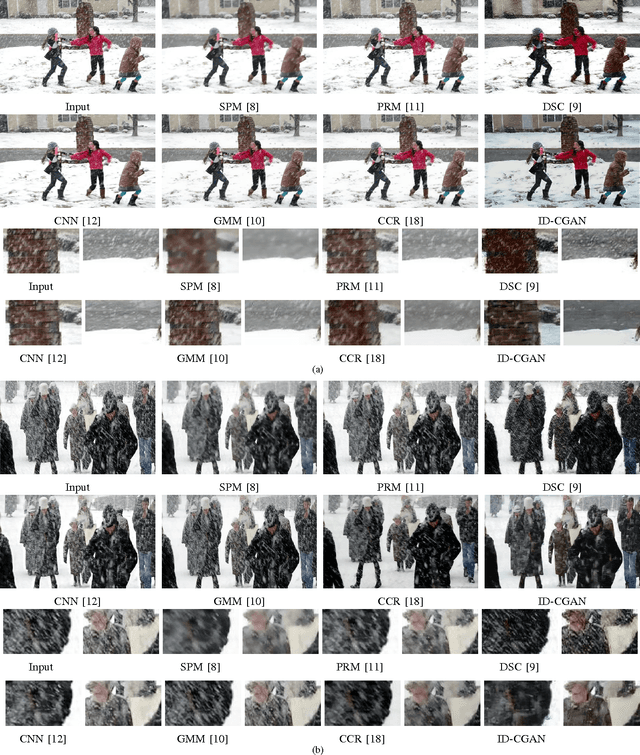

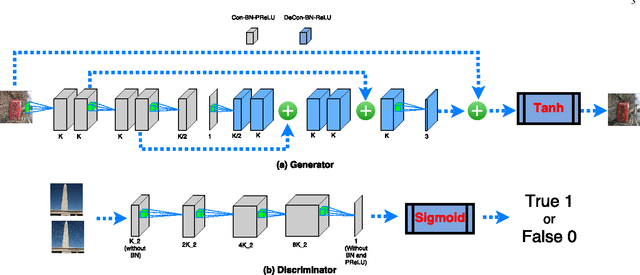
Severe weather conditions such as rain and snow adversely affect the visual quality of images captured under such conditions thus rendering them useless for further usage and sharing. In addition, such degraded images drastically affect performance of vision systems. Hence, it is important to solve the problem of single image de-raining/de-snowing. However, this is a difficult problem to solve due to its inherent ill-posed nature. Existing approaches attempt to introduce prior information to convert it into a well-posed problem. In this paper, we investigate a new point of view in addressing the single image de-raining problem. Instead of focusing only on deciding what is a good prior or a good framework to achieve good quantitative and qualitative performance, we also ensure that the de-rained image itself does not degrade the performance of a given computer vision algorithm such as detection and classification. In other words, the de-rained result should be indistinguishable from its corresponding clear image to a given discriminator. This criterion can be directly incorporated into the optimization framework by using the recently introduced conditional generative adversarial networks (GANs). To minimize artifacts introduced by GANs and ensure better visual quality, a new refined loss function is introduced. Based on this, we propose a novel single image de-raining method called Image De-raining Conditional General Adversarial Network (ID-CGAN), which considers quantitative, visual and also discriminative performance into the objective function. Experiments evaluated on synthetic images and real images show that the proposed method outperforms many recent state-of-the-art single image de-raining methods in terms of quantitative and visual performance.
Deep correction of breathing-related artifacts in MR-thermometry
Nov 10, 2020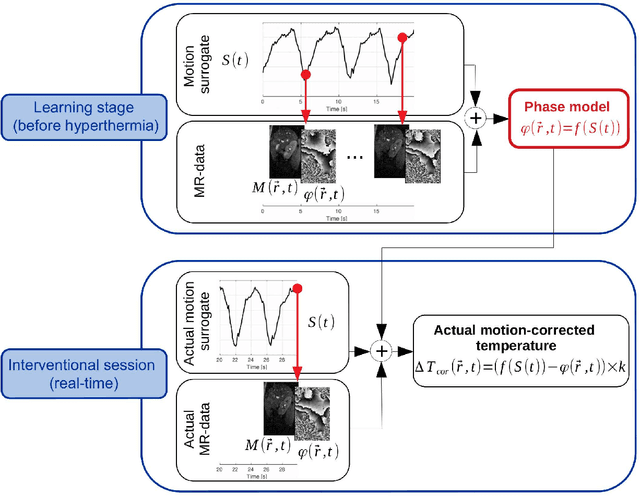
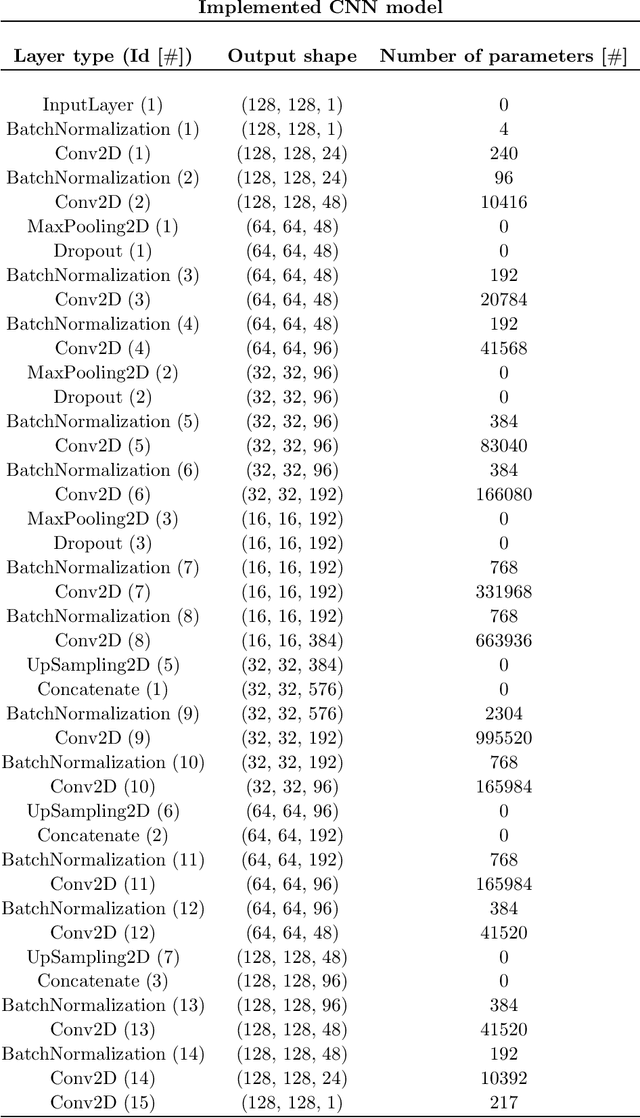
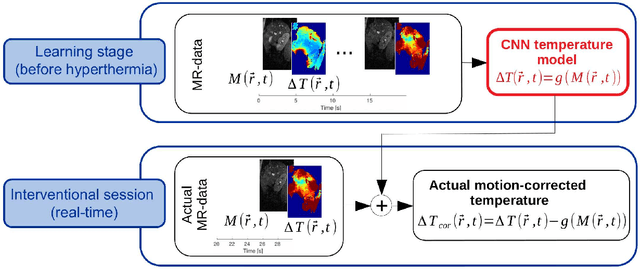
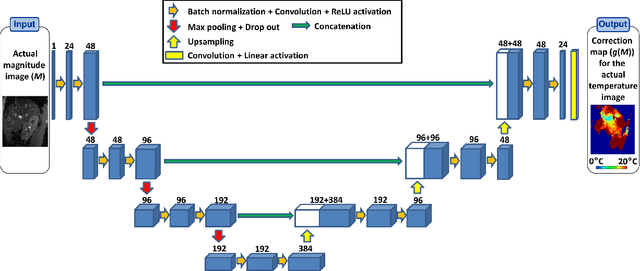
Real-time MR-imaging has been clinically adapted for monitoring thermal therapies since it can provide on-the-fly temperature maps simultaneously with anatomical information. However, proton resonance frequency based thermometry of moving targets remains challenging since temperature artifacts are induced by the respiratory as well as physiological motion. If left uncorrected, these artifacts lead to severe errors in temperature estimates and impair therapy guidance. In this study, we evaluated deep learning for on-line correction of motion related errors in abdominal MR-thermometry. For this, a convolutional neural network (CNN) was designed to learn the apparent temperature perturbation from images acquired during a preparative learning stage prior to hyperthermia. The input of the designed CNN is the most recent magnitude image and no surrogate of motion is needed. During the subsequent hyperthermia procedure, the recent magnitude image is used as an input for the CNN-model in order to generate an on-line correction for the current temperature map. The method's artifact suppression performance was evaluated on 12 free breathing volunteers and was found robust and artifact-free in all examined cases. Furthermore, thermometric precision and accuracy was assessed for in vivo ablation using high intensity focused ultrasound. All calculations involved at the different stages of the proposed workflow were designed to be compatible with the clinical time constraints of a therapeutic procedure.