 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepFN: Towards Generalizable Facial Action Unit Recognition with Deep Face Normalization
Mar 03, 2021
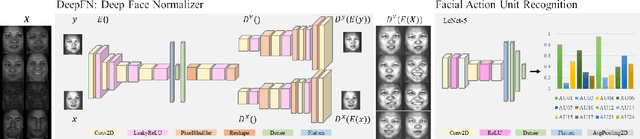
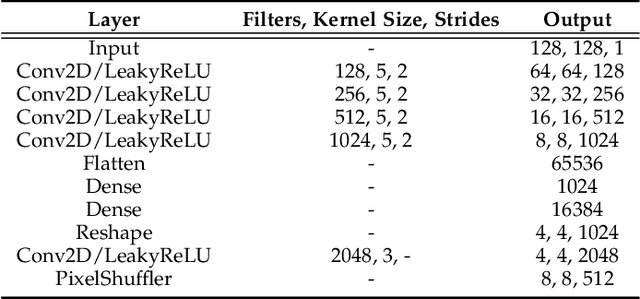
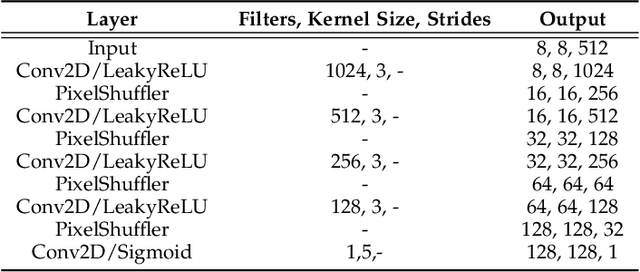
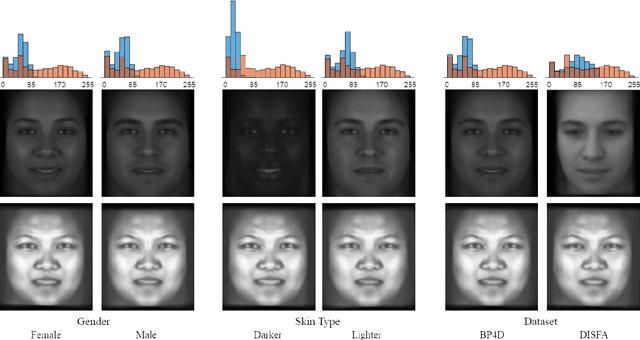
Facial action unit recognition has many applications from market research to psychotherapy and from image captioning to entertainment. Despite its recent progress, deployment of these models has been impeded due to their limited generalization to unseen people and demographics. This work conducts an in-depth analysis of performance across several dimensions: individuals(40 subjects), genders (male and female), skin types (darker and lighter), and databases (BP4D and DISFA). To help suppress the variance in data, we use the notion of self-supervised denoising autoencoders to design a method for deep face normalization(DeepFN) that transfers facial expressions of different people onto a common facial template which is then used to train and evaluate facial action recognition models. We show that person-independent models yield significantly lower performance (55% average F1 and accuracy across 40 subjects) than person-dependent models (60.3%), leading to a generalization gap of 5.3%. However, normalizing the data with the newly introduced DeepFN significantly increased the performance of person-independent models (59.6%), effectively reducing the gap. Similarly, we observed generalization gaps when considering gender (2.4%), skin type (5.3%), and dataset (9.4%), which were significantly reduced with the use of DeepFN. These findings represent an important step towards the creation of more generalizable facial action unit recognition systems.
Derivate-based Component-Trees for Multi-Channel Image Segmentation
Apr 19, 2018
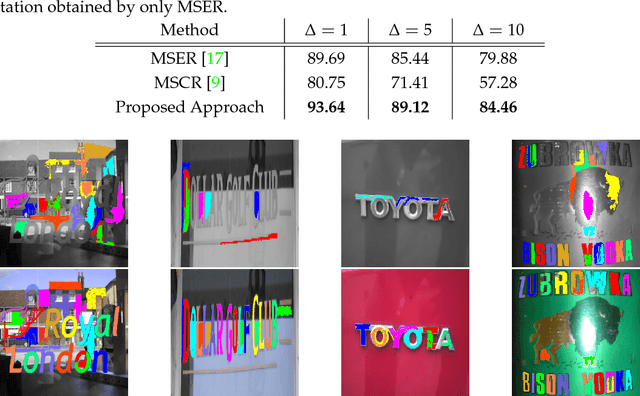
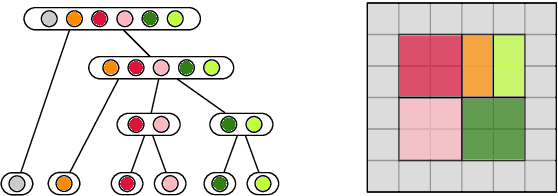
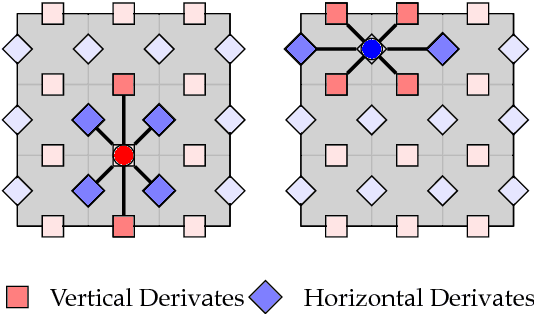
We introduce the concept of derivate-based component-trees for images with an arbitrary number of channels. The approach is a natural extension of the classical component-tree devoted to gray-scale images. The similar structure enables the translation of many gray-level image processing techniques based on the component-tree to hyperspectral and color images. As an example application, we present an image segmentation approach that extracts Maximally Stable Homogeneous Regions (MSHR). The approach very similar to MSER but can be applied to images with an arbitrary number of channels. As opposed to MSER, our approach implicitly segments regions with are both lighter and darker than their background for gray-scale images and can be used in OCR applications where MSER will fail. We introduce a local flooding-based immersion for the derivate-based component-tree construction which is linear in the number of pixels. In the experiments, we show that the runtime scales favorably with an increasing number of channels and may improve algorithms which build on MSER.
Fusion of Real Time Thermal Image and 1D/2D/3D Depth Laser Readings for Remote Thermal Sensing in Industrial Plants by Means of UAVs and/or Robots
Jun 01, 2020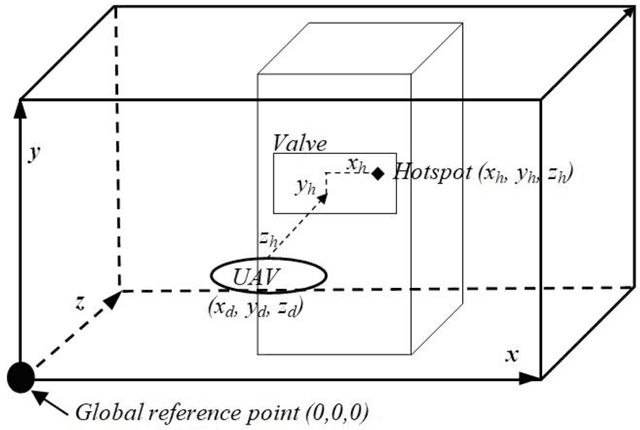


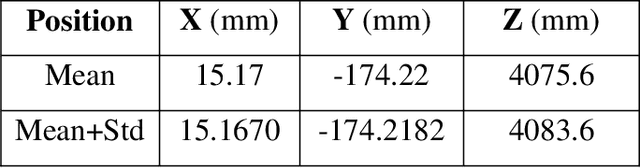
This paper presents fast procedures for thermal infrared remote sensing in dark, GPS-denied environments, such as those found in industrial plants such as in High-Voltage Direct Current (HVDC) converter stations. These procedures are based on the combination of the depth estimation obtained from either a 1-Dimensional LIDAR laser or a 2-Dimensional Hokuyo laser or a 3D MultiSense SLB laser sensor and the visible and thermal cameras from a FLIR Duo R dual-sensor thermal camera. The combination of these sensors/cameras is suitable to be mounted on Unmanned Aerial Vehicles (UAVs) and/or robots in order to provide reliable information about the potential malfunctions, which can be found within the hazardous environment. For example, the capabilities of the developed software and hardware system corresponding to the combination of the 1-D LIDAR sensor and the FLIR Duo R dual-sensor thermal camera is assessed from the point of the accuracy of results and the required computational times: the obtained computational times are under 10 ms, with a maximum localization error of 8 mm and an average standard deviation for the measured temperatures of 1.11 degree Celsius, which results are obtained for a number of test cases. The paper is structured as follows: the description of the system used for identification and localization of hotspots in industrial plants is presented in section II. In section III, the method for faults identification and localization in plants by using a 1-Dimensional LIDAR laser sensor and thermal images is described together with results. In section IV the real time thermal image processing is presented. Fusion of the 2-Dimensional depth laser Hokuyo and the thermal images is described in section V. In section VI the combination of the 3D MultiSense SLB laser and thermal images is described. In section VII a discussion and several conclusions are drawn.
Boosting of Image Denoising Algorithms
Mar 12, 2015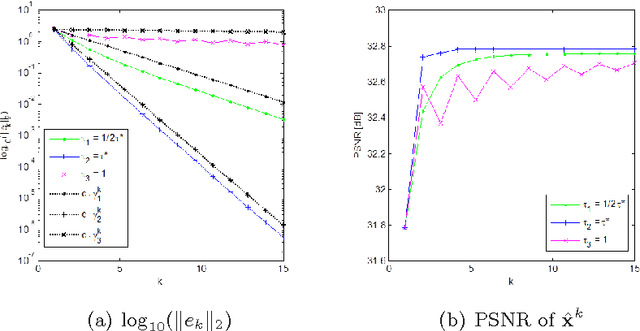


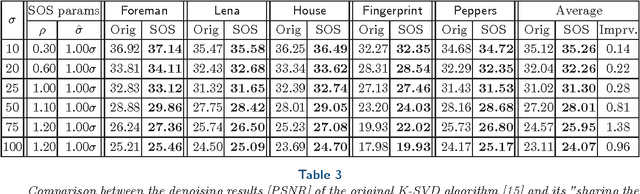
In this paper we propose a generic recursive algorithm for improving image denoising methods. Given the initial denoised image, we suggest repeating the following "SOS" procedure: (i) (S)trengthen the signal by adding the previous denoised image to the degraded input image, (ii) (O)perate the denoising method on the strengthened image, and (iii) (S)ubtract the previous denoised image from the restored signal-strengthened outcome. The convergence of this process is studied for the K-SVD image denoising and related algorithms. Still in the context of K-SVD image denoising, we introduce an interesting interpretation of the SOS algorithm as a technique for closing the gap between the local patch-modeling and the global restoration task, thereby leading to improved performance. In a quest for the theoretical origin of the SOS algorithm, we provide a graph-based interpretation of our method, where the SOS recursive update effectively minimizes a penalty function that aims to denoise the image, while being regularized by the graph Laplacian. We demonstrate the SOS boosting algorithm for several leading denoising methods (K-SVD, NLM, BM3D, and EPLL), showing tendency to further improve denoising performance.
Image Inpainting using Block-wise Procedural Training with Annealed Adversarial Counterpart
Mar 28, 2018

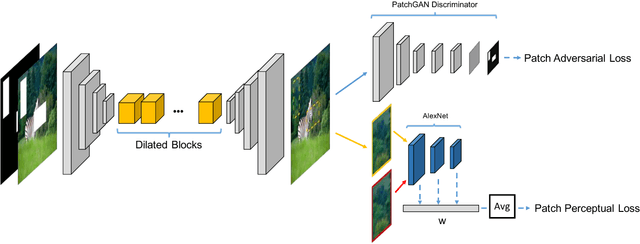
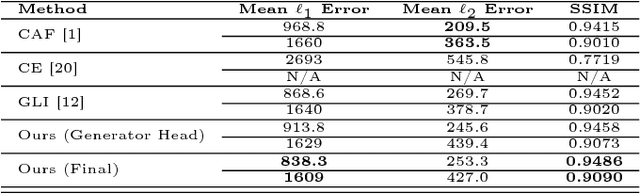
Recent advances in deep generative models have shown promising potential in image inpanting, which refers to the task of predicting missing pixel values of an incomplete image using the known context. However, existing methods can be slow or generate unsatisfying results with easily detectable flaws. In addition, there is often perceivable discontinuity near the holes and require further post-processing to blend the results. We present a new approach to address the difficulty of training a very deep generative model to synthesize high-quality photo-realistic inpainting. Our model uses conditional generative adversarial networks (conditional GANs) as the backbone, and we introduce a novel block-wise procedural training scheme to stabilize the training while we increase the network depth. We also propose a new strategy called adversarial loss annealing to reduce the artifacts. We further describe several losses specifically designed for inpainting and show their effectiveness. Extensive experiments and user-study show that our approach outperforms existing methods in several tasks such as inpainting, face completion and image harmonization. Finally, we show our framework can be easily used as a tool for interactive guided inpainting, demonstrating its practical value to solve common real-world challenges.
Image Stitching by Line-guided Local Warping with Global Similarity Constraint
Oct 30, 2017

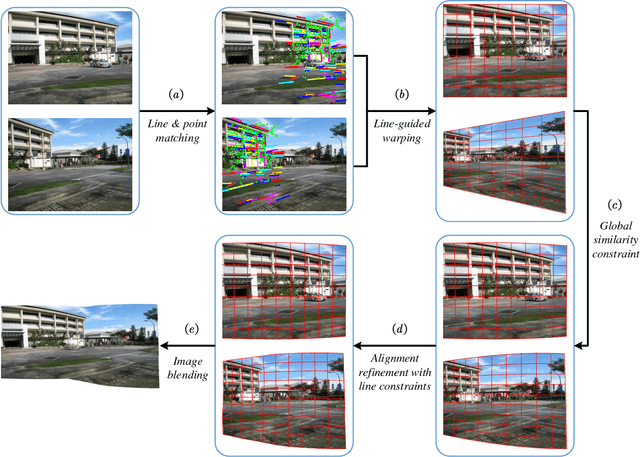
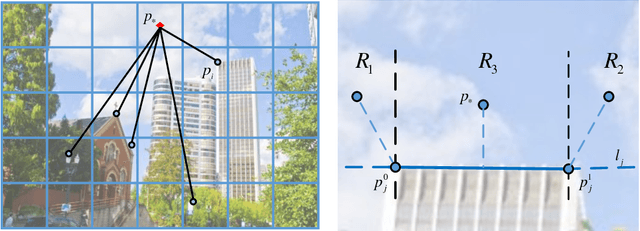
Low-textured image stitching remains a challenging problem. It is difficult to achieve good alignment and it is easy to break image structures due to insufficient and unreliable point correspondences. Moreover, because of the viewpoint variations between multiple images, the stitched images suffer from projective distortions. To solve these problems, this paper presents a line-guided local warping method with a global similarity constraint for image stitching. Line features which serve well for geometric descriptions and scene constraints, are employed to guide image stitching accurately. On one hand, the line features are integrated into a local warping model through a designed weight function. On the other hand, line features are adopted to impose strong geometric constraints, including line correspondence and line colinearity, to improve the stitching performance through mesh optimization. To mitigate projective distortions, we adopt a global similarity constraint, which is integrated with the projective warps via a designed weight strategy. This constraint causes the final warp to slowly change from a projective to a similarity transformation across the image. Finally, the images undergo a two-stage alignment scheme that provides accurate alignment and reduces projective distortion. We evaluate our method on a series of images and compare it with several other methods. The experimental results demonstrate that the proposed method provides a convincing stitching performance and that it outperforms other state-of-the-art methods.
On the effectiveness of adversarial training against common corruptions
Mar 03, 2021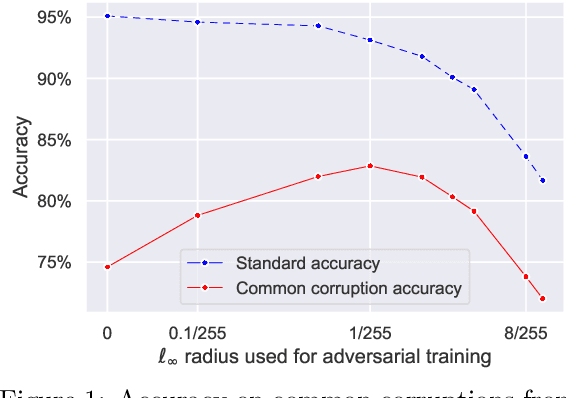

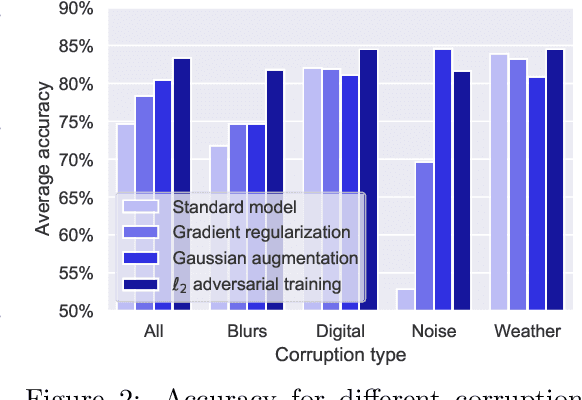

The literature on robustness towards common corruptions shows no consensus on whether adversarial training can improve the performance in this setting. First, we show that, when used with an appropriately selected perturbation radius, $\ell_p$ adversarial training can serve as a strong baseline against common corruptions. Then we explain why adversarial training performs better than data augmentation with simple Gaussian noise which has been observed to be a meaningful baseline on common corruptions. Related to this, we identify the $\sigma$-overfitting phenomenon when Gaussian augmentation overfits to a particular standard deviation used for training which has a significant detrimental effect on common corruption accuracy. We discuss how to alleviate this problem and then how to further enhance $\ell_p$ adversarial training by introducing an efficient relaxation of adversarial training with learned perceptual image patch similarity as the distance metric. Through experiments on CIFAR-10 and ImageNet-100, we show that our approach does not only improve the $\ell_p$ adversarial training baseline but also has cumulative gains with data augmentation methods such as AugMix, ANT, and SIN leading to state-of-the-art performance on common corruptions. The code of our experiments is publicly available at https://github.com/tml-epfl/adv-training-corruptions.
The ND-IRIS-0405 Iris Image Dataset
Jun 15, 2016
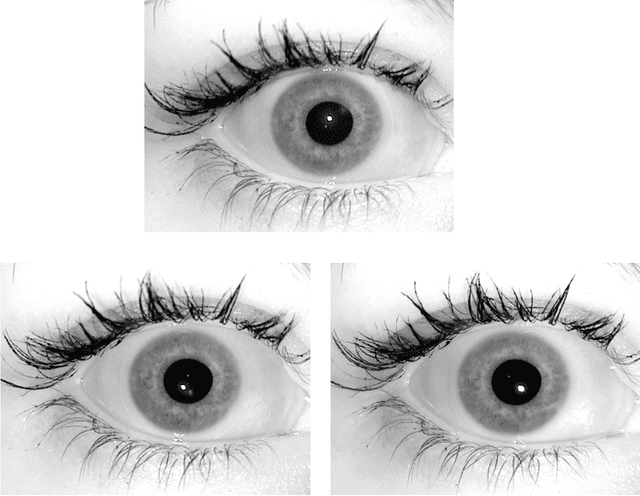
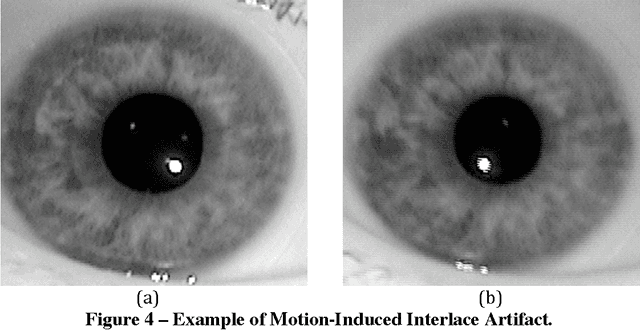
The Computer Vision Research Lab at the University of Notre Dame began collecting iris images in the spring semester of 2004. The initial data collections used an LG 2200 iris imaging system for image acquisition. Image datasets acquired in 2004-2005 at Notre Dame with this LG 2200 have been used in the ICE 2005 and ICE 2006 iris biometric evaluations. The ICE 2005 iris image dataset has been distributed to over 100 research groups around the world. The purpose of this document is to describe the content of the ND-IRIS-0405 iris image dataset. This dataset is a superset of the iris image datasets used in ICE 2005 and ICE 2006. The ND 2004-2005 iris image dataset contains 64,980 images corresponding to 356 unique subjects, and 712 unique irises. The age range of the subjects is 18 to 75 years old. 158 of the subjects are female, and 198 are male. 250 of the subjects are Caucasian, 82 are Asian, and 24 are other ethnicities.
Unsupervised Vehicle Re-Identification via Self-supervised Metric Learning using Feature Dictionary
Mar 03, 2021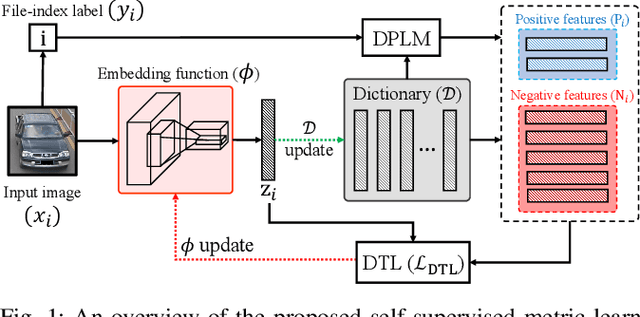
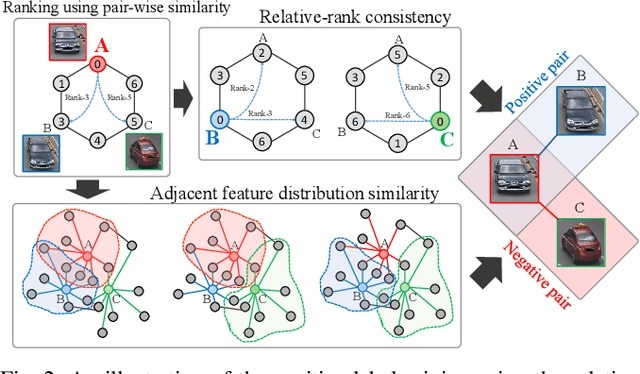
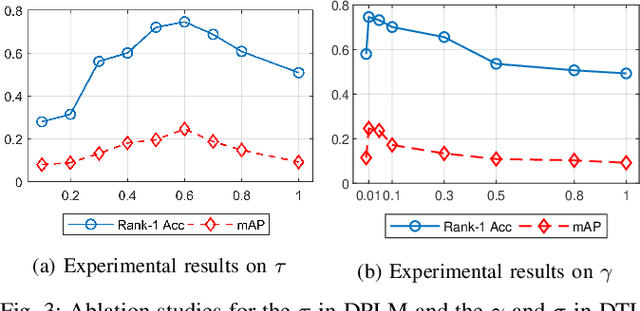
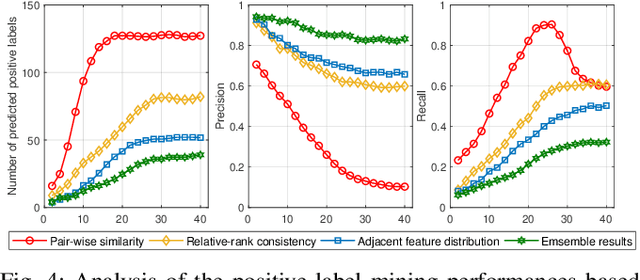
The key challenge of unsupervised vehicle re-identification (Re-ID) is learning discriminative features from unlabelled vehicle images. Numerous methods using domain adaptation have achieved outstanding performance, but those methods still need a labelled dataset as a source domain. This paper addresses an unsupervised vehicle Re-ID method, which no need any types of a labelled dataset, through a Self-supervised Metric Learning (SSML) based on a feature dictionary. Our method initially extracts features from vehicle images and stores them in a dictionary. Thereafter, based on the dictionary, the proposed method conducts dictionary-based positive label mining (DPLM) to search for positive labels. Pair-wise similarity, relative-rank consistency, and adjacent feature distribution similarity are jointly considered to find images that may belong to the same vehicle of a given probe image. The results of DPLM are applied to dictionary-based triplet loss (DTL) to improve the discriminativeness of learnt features and to refine the quality of the results of DPLM progressively. The iterative process with DPLM and DTL boosts the performance of unsupervised vehicle Re-ID. Experimental results demonstrate the effectiveness of the proposed method by producing promising vehicle Re-ID performance without a pre-labelled dataset. The source code for this paper is publicly available on `https://github.com/andreYoo/VeRI_SSML_FD.git'.
Deep Label Fusion: A 3D End-to-End Hybrid Multi-Atlas Segmentation and Deep Learning Pipeline
Mar 19, 2021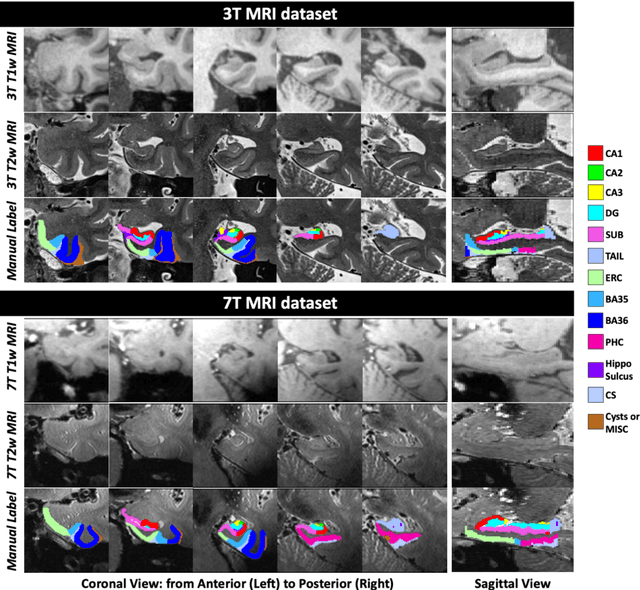
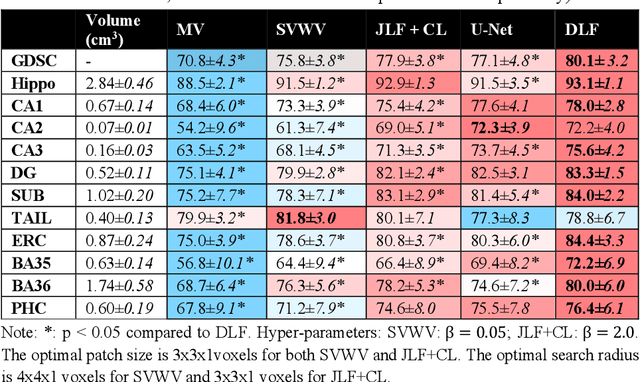
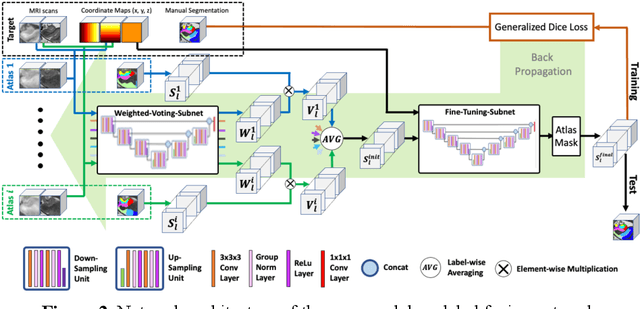
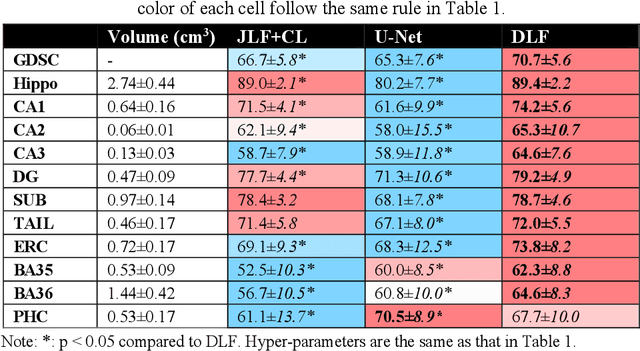
Deep learning (DL) is the state-of-the-art methodology in various medical image segmentation tasks. However, it requires relatively large amounts of manually labeled training data, which may be infeasible to generate in some applications. In addition, DL methods have relatively poor generalizability to out-of-sample data. Multi-atlas segmentation (MAS), on the other hand, has promising performance using limited amounts of training data and good generalizability. A hybrid method that integrates the high accuracy of DL and good generalizability of MAS is highly desired and could play an important role in segmentation problems where manually labeled data is hard to generate. Most of the prior work focuses on improving single components of MAS using DL rather than directly optimizing the final segmentation accuracy via an end-to-end pipeline. Only one study explored this idea in binary segmentation of 2D images, but it remains unknown whether it generalizes well to multi-class 3D segmentation problems. In this study, we propose a 3D end-to-end hybrid pipeline, named deep label fusion (DLF), that takes advantage of the strengths of MAS and DL. Experimental results demonstrate that DLF yields significant improvements over conventional label fusion methods and U-Net, a direct DL approach, in the context of segmenting medial temporal lobe subregions using 3T T1-weighted and T2-weighted MRI. Further, when applied to an unseen similar dataset acquired in 7T, DLF maintains its superior performance, which demonstrates its good generalizability.